对比度保持连贯性损失 CCPL
- 提出背景
- 解法:对比度保持连贯性损失(CCPL)
- 对比学习:在无需标签的情况下有效学习区分特征
- 应用CCPL的步骤 - 高层次描述
- 应用CCPL的步骤 - 技术细节
- 简单协方差变换(SCT)的详细过程
- 逻辑链条
提出背景
论文:https://arxiv.org/pdf/2207.04808.pdf
代码:https://github.com/JarrentWu1031/CCPL
如果你能将心爱的照片转换成梵高或毕加索的画作风格,又或者让一段视频流畅地展现出古典油画的韵味,这一切听起来是不是很神奇?
近年来,一项名为“风格转换”的技术正让这种想象成为现实。
把一种图像的风格应用到另一张图像上,但要做得好却非常复杂。
特别是在处理视频时,我们希望转换后的每一帧都能够保持风格的一致性,同时又不失原有的动态效果。
过去的技术往往在保持这种一致性上遇到困难,导致视频在播放时会出现闪烁或是帧与帧之间不连贯的现象。
研究人员提出了一种新的方法,名为“对比度保持连贯性损失”(CCPL)。
方法创新: 与传统的风格转换技术不同,CCPL通过对比学习框架最大化正样本对的互信息来保持局部连贯性,同时避免了与风格化目标的直接矛盾,即避免了生成图像简单复制内容图像的问题。
CCPL通过专注于图像的局部细节,而不是整体,来确保风格转换的连贯性和一致性。
就是让图片的每一小块都进行独立的风格转换,但又能保证整体上的和谐统一。
- CCPL引入的邻域调节策略显著减少了图像的局部失真问题。这意味着在风格转换过程中,生成的图像在细节上更加准确,同时在视觉质量上得到了显著提升。
除此之外,为了更好地融合不同的风格特征,研究团队还提出了一个名为“简单协方差变换”(SCT)的技术。
通过这种方法,可以更精确地将一个风格的特点融入到另一张图片中,从而达到更自然、更贴近原作风格的转换效果。
这项技术的美妙之处在于,它不仅适用于艺术风格的转换,也同样适用于视频和照片级真实感的风格转换。
对于解决图像和视频风格转换中的帧间连贯性和局部一致性问题。
CCPL的核心思想在于通过一种对比学习的框架来维持内容的连贯性,同时允许风格的灵活转换。
这种方法特别适用于处理视频风格转换,其中需要在连续帧之间保持高度的连贯性,以避免产生闪烁或其他视觉不一致的现象。
解法:对比度保持连贯性损失(CCPL)
CCPL 过程:
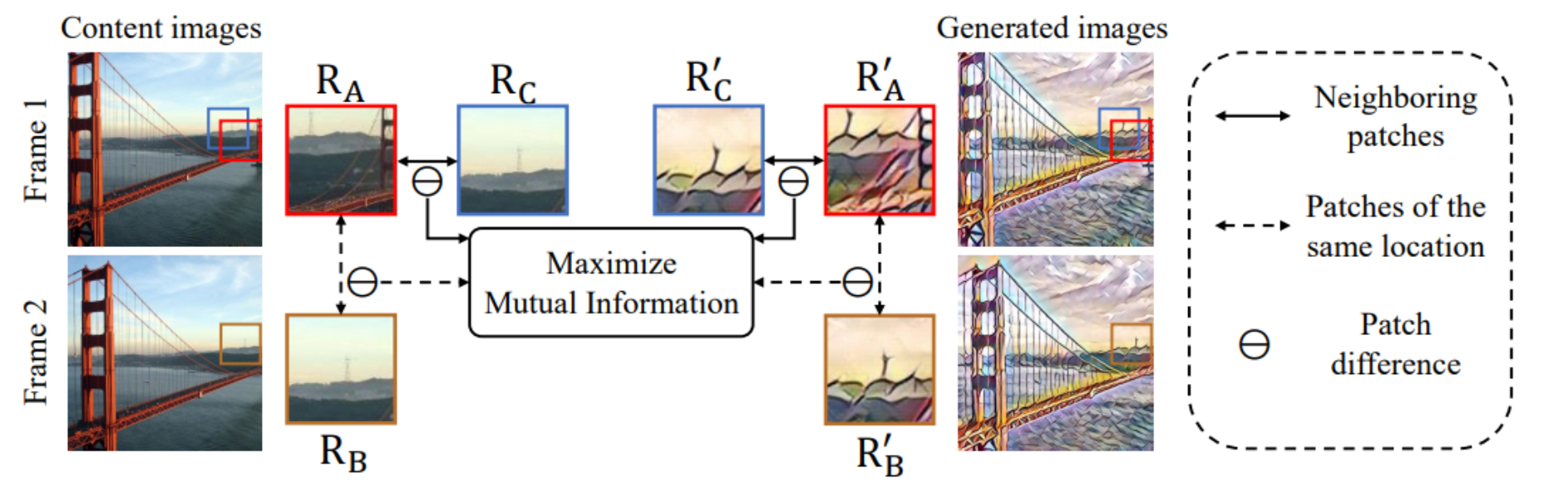
这个过程涉及两帧内容图像(Frame 1 和 Frame 2),它们分别包含了一些局部区域(RA,RB和RC)。
在这两帧中,相同颜色的框代表相同的位置,但可能由于相机移动或物体移动,内容有所不同。
目标是使生成的风格化图像中相对应的区域(R’A,R’B和R’C)之间的变化与内容图像的相应区域之间的变化尽可能一致。
这样可以保持内容的连贯性,并且通过最大化相同位置的补丁之间的互信息来实现这一点。
-
子特征1:局部一致性假设
- 描述:CCPL出发点是一个相对温和的假设,即全局的不一致性主要由局部的不一致性引起。
- 这意味着通过专注于图像或视频的小区域(局部补丁),我们可以更有效地维护整体的连贯性。
- 原因:这个假设允许算法在没有牺牲整体风格转换效果的情况下,精细控制局部区域的连贯性和风格一致性。
-
子特征2:对比学习机制
- 描述:CCPL采用对比学习机制,通过最大化正样本对的相似性(即相同区域的局部补丁)和最小化负样本对的相似性(即不同区域的局部补丁),来保持内容的连贯性。
- 原因:对比学习机制有效地利用了无标签数据,通过区分相似和不相似的局部特征,强化了模型对风格和内容连贯性的理解,从而在不直接依赖于成对的训练样本的情况下实现风格迁移。
-
子特征3:邻域调节策略
- 描述:CCPL引入了一种邻域调节策略,通过调整相邻补丁间的相互作用,减少了局部失真并提升了视觉质量。
- 原因:这种策略通过确保相邻补丁之间的风格转换连贯性,减少了风格转换过程中可能出现的突兀变化,特别是在视频帧间,这种方法显著提升了视觉连贯性和整体观感。
通过局部一致性的假设,对比学习的应用,以及邻域调节策略的实施,CCPL能够在保持内容连贯性的同时实现风格的高度自由转换,从而在不牺牲风格化效果的前提下,显著提升了转换后图像和视频的视觉质量。
这使得CCPL成为一个强大的工具,适用于各种风格转换任务,包括艺术化转换、照片级真实感转换和视频风格转换。
对比学习:在无需标签的情况下有效学习区分特征
子解法: 对比学习
子特征: 正负特征对的互信息最大化。
通过最大化正样本对的互信息同时最小化负样本对的互信息,学习良好的特征表示。
之所以采用对比学习,是因为在无需标签的情况下,可以有效学习区分特征,为图像到图像的转换提供强大的特征表示基础。
我们有一组风景照片和一组著名画家的画作。
我们的目标是学习一个模型,使得我们可以将画家的风格应用到风景照片上,创建出新的、风格化的图像。
在没有对比学习的情况下,我们可能需要大量的 “风景照片-风格化照片” 对作为训练数据,这在现实中是很难获得的。
这时,对比学习就派上用场了。
我们不需要精确的“对”作为训练数据,而是可以使用无标签的图像来学习区分特征。具体来说,对比学习通过以下方式工作:
-
正样本对的选择:我们从著名画家的画作中选取一个局部特征(比如一小块画布上的纹理),并从风景照片中选取一个相似的局部特征作为正样本对。
这两个特征在视觉上是相似的,我们希望模型学会识别和保持这种相似性。
-
负样本对的选择:同时,我们还从同一幅风景照片或其他画作中选取与上述特征明显不同的局部特征作为负样本对。
这些特征在视觉上与选定的特征有显著差异,我们希望模型学会区分这些差异。
-
互信息最大化:模型通过最大化正样本对之间的互信息(即使模型能够识别和强调这些特征之间的相似性)和最小化负样本对之间的互信息(即使模型能够区分不相关的特征),来学习区分这些特征。
这个过程不需要标签,因为它是基于特征相似性和差异性的内在属性。
例如,如果我们正在学习梵高的风格,正样本对可能是一小块表现出梵高特有笔触的画布特征和一张风景照片中相似纹理的部分。
负样本对可能是同一风景照片中的一块平滑无纹理的天空区域。
通过这种方式,对比学习使模型能够学习到如何将梵高的笔触应用到风景照片的相应部分,同时避免在不适合的区域(如平滑的天空)应用这种风格,从而实现更加准确和自然的风格转换效果。
这个过程不依赖于成对的训练样本,而是依赖于模型能够从大量无标签的数据中学习区分和应用风格的能力。
应用CCPL的步骤 - 高层次描述
假设我们有一段城市风景的视频,我们希望将梵高的绘画风格应用于这个视频,同时确保视频中的每一帧都能够在视觉上保持连贯,避免出现闪烁或者风格不一致的问题。
应用CCPL的步骤
-
局部一致性假设:
- 我们首先将视频分解为一系列帧,然后将每一帧进一步分割成小的局部区域(或称为补丁)。
- 这样做的目的是将全局风格转换问题转化为多个局部问题,每个局部问题关注于如何将梵高的风格应用于一个小区域内。
-
对比学习机制:
- 接下来,对于视频中的每一个局部补丁,CCPL算法会在梵高的画作中寻找风格上最接近的补丁作为正样本对,同时也会寻找风格差异显著的补丁作为负样本对。
- 通过这种方式,算法学习在保持原有内容结构的前提下,如何将梵高的风格特征融入到城市风景的每个局部补丁中,同时确保与周围补丁在视觉上的连贯性。
-
邻域调节策略:
- 在风格转换过程中,CCPL还会考虑每个局部补丁与其相邻补丁之间的关系,确保相邻补丁之间的风格转换是连贯的。
- 这一步是通过调整相邻补丁间的相互作用来实现的,比如通过最小化相邻补丁间风格特征的差异。
- 这样,即使是动态变化的视频场景,每一帧内的风格转换也能够保持自然和连贯,避免了因风格突变导致的视觉闪烁问题。
通过应用CCPL,最终生成的视频不仅成功地将梵高的绘画风格融入到城市风景中,而且每一帧之间都能保持高度的视觉连贯性,使得整个视频看起来既自然又具有艺术感。
观众可以清晰地看到梵高笔触下的城市景象,同时享受到流畅连贯的视觉体验。
这个例子展示了CCPL在实现高质量风格转换,尤其是在处理视频内容时的强大能力。
通过局部一致性假设、对比学习机制和邻域调节策略的结合,CCPL能够有效解决风格转换过程中的视觉不一致问题,提供了一种既实用又高效的解决方案。
应用CCPL的步骤 - 技术细节
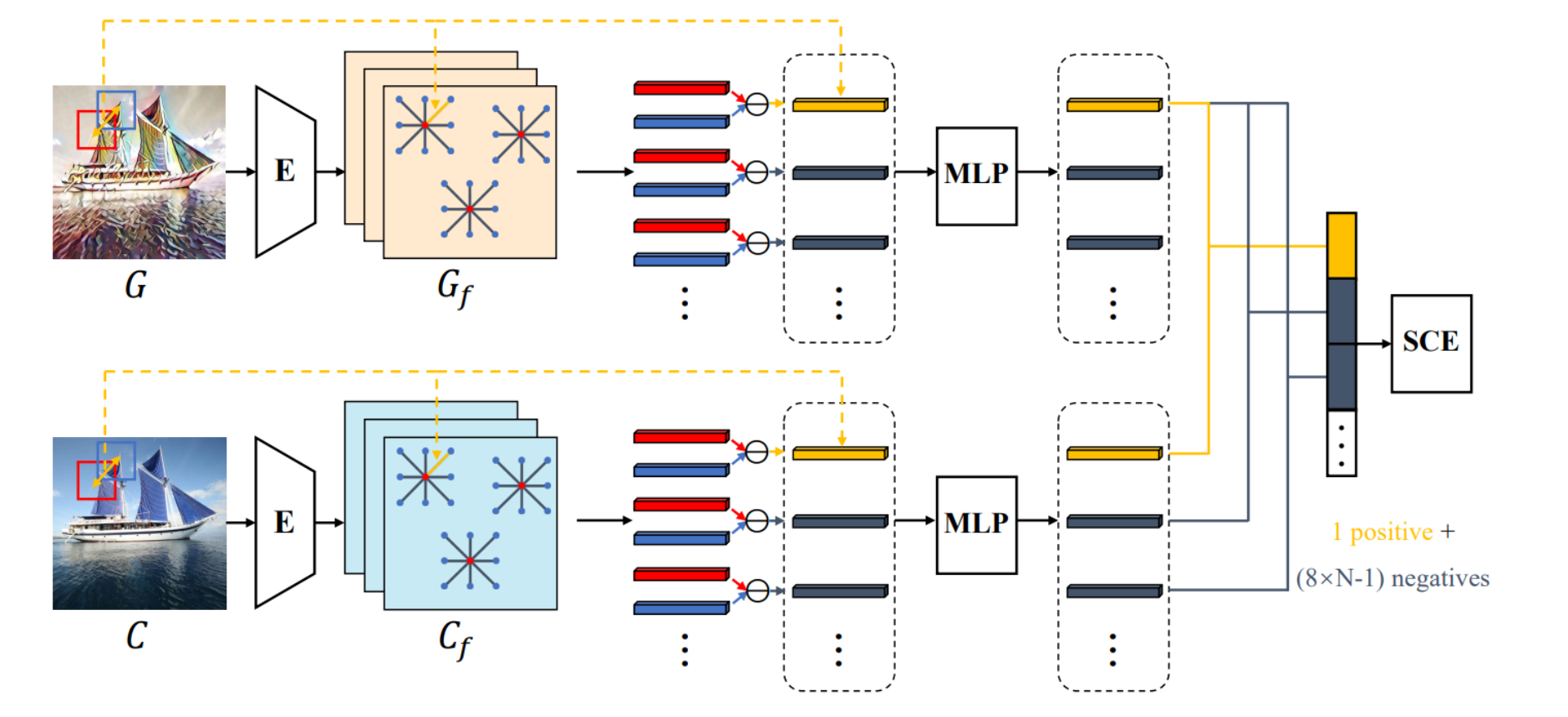
首先,内容图像C和生成图像G通过固定的图像编码器E,得到特定层的特征图Cf和Gf。
然后,从Gf中随机采样N个向量(红点),并从Cf中采样相同位置的向量。这些向量之间的差异通过向量减法得到,并通过多层感知机(MLP)映射和归一化,然后计算InfoNCE损失。
这一过程有助于在不同帧间保持图像的时间连贯性。
-
特征图提取:
- 首先,生成的图像G和其对应的内容输入C被送入一个固定的图像编码器E。这个编码器是预先训练好的,能够提取图像的深层特征。在这个过程中,我们从特定层得到了生成图像G和内容图像C的特征图,分别表示为Gf和Cf。
- 这一步骤的目的是将图像转换为更高维的特征表示,这些特征表示更加丰富,能够捕捉到图像的重要视觉属性。
-
随机采样和邻域选择:
- 接着,从Gf中随机采样N个向量(表示为红点),每个向量代表了生成图像在特定区域的特征表示。这些向量被表示为Gx_a,其中x=1,…,N。
- 对于每个采样的向量Gx_a,选择其八个最近的邻域向量(表示为蓝点),表示为Gx,y_n,其中y=1,…,8代表邻域索引。
- 同样地,也从Cf中在相同位置采样,获取对应的内容特征向量Cx_a和其邻域向量Cx,y_n。
-
差异向量的计算:
- 对于每对向量及其邻域,计算差异向量d_g^x,y = G_a^x ⊖ G_nx,y和d_cx,y = C_a^x ⊖ C_n^x,y,其中⊖代表向量减法。
- 这些差异向量代表了局部区域内特征之间的变化,是CCPL尝试保持一致的关键量。
-
对比学习与互信息最大化:
- 为了实现互信息最大化,CCPL尝试让正样本对(即来自相同位置的差异向量对)之间的差异尽可能相似,而让负样本对(即来自不同位置的差异向量对)之间的差异尽可能不同。
- 通过使用多层感知机(MLP)将差异向量映射到单位球面上,并计算InfoNCE损失,CCPL能够有效地实现这一目标。这种方法不仅强化了生成图像的时间连贯性,而且避免了直接使生成图像G类似于内容图像C的问题,从而不会与风格迁移的目的相矛盾。
简单协方差变换(SCT)的详细过程

上图是SCT模块的具体结构,以及它如何与其他类似算法(如AdaIN和Linear)进行比较。
SCT模块通过首先对内容特征fc和风格特征fs进行标准化处理,然后通过减少通道维数来降低计算成本,接着计算风格特征的协方差矩阵,最后通过矩阵乘法融合内容特征和风格特征。
这个过程不仅保留了风格特征之间的相关性,而且也简化了网络结构,使其更加轻量和快速。
通过这种方式,SCT模块能够有效地将风格化特征与内容特征融合,生成富有艺术风格的图像。
逻辑链条
对比度保持连贯性损失(CCPL)这样的复杂技术时,子特征之间的逻辑关系可以被视为一个“链条”模型,每个环节都是有序连接的,每一步骤的输出都作为下一步骤的输入。
阶段 1:目标设定
- 目标:将梵高的风格应用到城市风景视频中,并保持帧间连贯性。
阶段 2:特征图提取(子特征1)
- 操作:使用编码器E从内容图像C和生成图像G提取特征图Cf和Gf。
- 逻辑链条:这是链条的起始点,我们需要转换图像到一个可以更好地表征风格和内容的特征空间。
阶段 3:随机采样和邻域选择(子特征2)
- 操作:从特征图中随机选择特定数量的向量(代表局部区域)及其邻域。
- 逻辑链条:建立在特征图提取的基础上,这一步骤为后续的对比学习准备了输入数据。
阶段 4:差异向量的计算(子特征3)
- 操作:计算选定向量与邻域向量之间的差异。
- 逻辑链条:计算差异向量是为了量化邻域内的风格变化,这对于保持风格连贯性至关重要。
阶段 5:对比学习与互信息最大化(子特征4)
- 操作:应用对比学习机制,最大化正样本对的互信息,最小化负样本对的互信息。
- 逻辑链条:这是链条中的关键环节,它利用前面计算出的差异向量来训练模型,使得模型能够在保持内容连贯性的同时实现风格转换。
阶段 6:损失函数优化(子特征5)
- 操作:通过结合内容损失、风格损失和CCPL,进行模型训练。
- 逻辑链条:这个阶段整合了所有先前的子特征,并通过优化损失函数来调整模型参数,以达到最佳的风格转换效果。
阶段 7:输出评估(子特征6)
- 操作:评估生成视频的风格连贯性和视觉效果。
- 逻辑链条:这是链条的最终环节,它确保了所有先前步骤的有效性,并指导未来的优化方向。