导 读
如今图数据集正在以惊人的速度出现,所有化学分子、社交网络和推荐系统主要以图数据结构的形式存储数据

有需要的朋友关注公众号【小Z的科研日常】,获取更多内容。
01、如何转换CSV文件至图形数据结构
确定图形数据所需的基本信息
-
节点(物品、人物、地点、汽车……)
-
边缘(连接、交互、相似性……)
-
节点特征(属性)
-
标签(节点级、边级、图级)
以及可选:
-
边权重(连接强度、交互次数……)
-
边缘特征(描述边缘的附加(多维)属性)
检查是否有同质(相同类型)(节点,边)或异构(不同类型)(节点,边)
同质(节点、边)
对于用例,我们将使用FIFA 21 评级数据集(足球运动员的数据集)。
import pandas as pdas pd!wget -q https://raw.githubusercontent.com/batuhan-demirci/fifa21_dataset/master/data/tbl_player.csv
!wget -q https://raw.githubusercontent.com/batuhan-demirci/fifa21_dataset/master/data/tbl_player_skill.csv
!wget -q https://raw.githubusercontent.com/batuhan-demirci/fifa21_dataset/master/data/tbl_team.csv# 加载数据
player_df = pd.read_csv("tbl_player.csv")
skill_df = pd.read_csv("tbl_player_skill.csv")
team_df = pd.read_csv("tbl_team.csv")# 提取子集
player_df = player_df[["int_player_id", "str_player_name", "str_positions", "int_overall_rating", "int_team_id"]]
skill_df = skill_df[["int_player_id", "int_long_passing", "int_ball_control", "int_dribbling"]]
team_df = team_df[["int_team_id", "str_team_name", "int_overall"]]# 合并数据
player_df = player_df.merge(skill_df, on='int_player_id')
fifa_df = player_df.merge(team_df, on='int_team_id')# 数据帧排序
fifa_df = fifa_df.sort_values(by="int_overall_rating", ascending=False)
print("Players: ", fifa_df.shape[0])
fifa_df.head()输出:

首先确定我们需要的特定于图的东西:
-
Nodes- 足球运动员(按 ID) -
Edges- 如果他们为同一支球队或不同球队效力 -
Node Features- 足球运动员的位置、专长、控球…… -
Labels- 足球运动员的总体评分(节点级回归任务)
节点通常很容易识别——这里我们甚至有 ID。如果没有唯一标识符,则需要一个,因为我们需要知道哪些节点之间存在连接。
最具挑战性的任务通常是通过边以某种方式链接这些节点。在这里,我们根据团队分配定义边缘。
通过这个数据集,我们可以预测当一名球员转投新球队或观察到一名新球员时的预期评分。因此,我们期望通过团队分配产生关系效应。当然,还有许多其他的可能性来定义边缘,例如:
-
两名玩家一起玩的次数(边缘权重)→ 协同作用
-
一名玩家赢/输了多少次 1:1 决斗(边缘权重)
-
在同一足球俱乐部开始职业生涯
-
时间边缘:“过去两周一起玩过”
-
……
关于如何组合数据框中的实例有很多选择。我们将继续采用最简单的方法,即根据他们的团队任务将他们联系起来。
max(fifa_df["int_player_id"].value_counts())每个足球运动员 ID 在我们的数据集中仅出现一次。
如果单个节点 ID 在数据集中出现多次,则有不同的选项:
-
有多个可以包含同一节点的图。在这种情况下,需要迭代数据框的每个子集(属于一个单独的图)并对该子集进行计算
-
必须将多行聚合为一行。例如,如果有交易数据(如付款历史记录),则需要以某种方式将其汇总为一个特征向量,例如# payments、付款金额……
提取节点特征
节点特征通常以(num_nodes, node_feature_dim)形状的矩阵表示。
对于每个足球运动员,我们简单地提取他们的属性。因为每个玩家ID都是唯一的,所以我们可以根据原始数据框轻松做到这一点。
# 排序来定义节点的顺序来定义节点的顺序
sorted_df = fifa_df.sort_values(by="int_player_id")
#选择节点特征
node_features = sorted_df[["str_positions", "int_long_passing", "int_ball_control", "int_dribbling"]]
# 转换非数字列
pd.set_option('mode.chained_assignment', None)
positions = node_features["str_positions"].str.split(",", expand=True)
node_features["first_position"] = positions[0]
# One-hot 编码
node_features = pd.concat([node_features, pd.get_dummies(node_features["first_position"])], axis=1, join='inner')
node_features.drop(["str_positions", "first_position"], axis=1, inplace=True)
node_features.head() 输出:

这已经是我们的节点特征矩阵。节点的数量和顺序由它们的形状隐式定义。每一行对应于最终图中的一个节点。
x = node_features.to_numpy()
x.shape # [num_nodes x num_features]输出:

提取边缘
这可能是表格数据集最棘手的部分。我们需要考虑一种合理的方式来连接节点。如前所述,我们将在这里使用团队分配。
注意:有很多方法可以连接数据集中的实体,但这种方法非常简单。如果我想从这个数据集构建一个真实的模型,我可能会寻找一种更复杂的方式来连接玩家。对于我对边缘建模的方式来说,使用 GNN 有点大材小用。
我们现在需要找到分配到同一团队的成对球员。我们首先检查一下我们每队有多少名球员。
# 重新映射球员 ID
fifa_df["int_player_id"] = fifa_df.reset_index().index
# 这将告诉我们每队需要连接多少名球员
fifa_df["str_team_name"].value_counts()我们现在需要在一支球队内构建这些球员的所有排列,这对应于每个球队子组内的完全连接图。我们使用 int_player_id 列作为边的索引。例如,如果边索引中有[0, 1],则意味着第一和第二节点(关于先前定义的节点特征矩阵)是连接的。
import itertools
import numpy as npteams = fifa_df["str_team_name"].unique()"str_team_name"].unique()
all_edges = np.array([], dtype=np.int32).reshape((0, 2))
for team in teams:team_df = fifa_df[fifa_df["str_team_name"] == team]players = team_df["int_player_id"].values# Build all combinations, as all players are connectedpermutations = list(itertools.combinations(players, 2))edges_source = [e[0] for e in permutations]edges_target = [e[1] for e in permutations]team_edges = np.column_stack([edges_source, edges_target])all_edges = np.vstack([all_edges, team_edges])
# Convert to Pytorch Geometric format
edge_index = all_edges.transpose()
edge_index # [2, num_edges]
array([[ 0, 0, 0, ..., 18704, 18704, 18719],[[ 0, 0, 0, ..., 18704, 18704, 18719],[ 7, 32, 45, ..., 18719, 18751, 18751]])e = torch.tensor(edge_index, dtype=torch.long)
print(e)edge_index1 = e.t().clone().detach()
edge_index1
# output tensor([[ 0, 7],[ 0, 32],[ 0, 45],...,[18704, 18719],[18704, 18751],[18719, 18751]])建立图结构数据:
使用 networkx 来完成此任务:我们将 Pytorch 几何图转换为 NetworkX 图
from torch_geometric.data import Datadata import Data
data = Data(x=x, edge_index=edge_index1.t().contiguous(), y=y)from torch_geometric.data import Data
from torch_geometric.utils import to_networkx
networkX_graph = to_networkx(data)import networkx as nx
nx.draw(networkX_graph)输出:

它看起来有点令人困惑,因为我们有很多节点和很多边。但是当我们尝试可视化该图的子图时,这对我们来说可能是有意义的。
异构(节点或边)
推荐系统是一个典型的例子,因此我选择了动漫推荐数据库(电影推荐数据集)。
加载数据集
import pandas as pd# Download data (quietly)
!wget -q https://raw.githubusercontent.com/Mayank-Bhatia/Anime-Recommender/master/data/anime.csv
!wget -q https://raw.githubusercontent.com/Mayank-Bhatia/Anime-Recommender/master/data/rating.csvanime = pd.read_csv("anime.csv")
rating = pd.read_csv("rating.csv")输出:

就像之前一样,我们首先确定我们需要的图实体。
-
Nodes- 用户和动漫(具有不同特征的两种节点类型=异构) -
Edges- 如果用户对电影进行了评分/评分(边缘权重) -
Node Features- 电影属性和用户,我们没有明确的特征,所以我们必须稍后再弄清楚 -
Labels- 电影的评级(链接预测回归任务)
该数据集就像Example 1生成一个包含所有节点和边的图一样。给定一对节点和动漫电影,我们将能够预测用户是否/如何喜欢这部电影。
要将其建模为图表,我们必须支持两种节点类型:电影和用户。这是因为它们具有不同的节点特征(和形状),不适合一个联合节点特征矩阵。
提取节点特征
每部电影在动漫数据框中只出现一次,因此我们可以直接从中提取特征。如果数据框中的每个节点(电影 ID)有多个条目。
我们将提取具有特定属性的列并将它们转换为数字特征......
对于动漫电影...
-
首先,我们需要重新映射 ID。这是因为它们不是以 0 开头,而且并非所有 ID 都存在。但这很重要,因为edge_index始终引用节点特征矩阵中的索引
-
我们将存储此映射,稍后需要它
# 排序定义节点的顺序
sorted_df = anime.sort_values(by="anime_id").set_index("anime_id")# 映射 ID 从 0 开始
sorted_df = sorted_df.reset_index(drop=False)
movie_id_mapping = sorted_df["anime_id"]#挑选特征
node_features = sorted_df[["type", "genre", "episodes"]]
# Convert non-numeric columns
pd.set_option('mode.chained_assignment', None)# 为简单起见,我在这里只选择第一个流派,而忽略其他流派
genres = node_features["genre"].str.split(",", expand=True)
node_features["main_genre"] = genres[0]anime_node_features = pd.concat([node_features, pd.get_dummies(node_features["main_genre"])], axis=1, join='inner')
anime_node_features = pd.concat([anime_node_features, pd.get_dummies(anime_node_features["type"])], axis=1, join='inner')
anime_node_features.drop(["genre", "main_genre"], axis=1, inplace=True)
anime_node_features.head(10)输出:

# 排序定义节点的顺序
x = anime_node_features.to_numpy()
x.shape # [num_movie_nodes x movie_node_feature_dim]对于用户...
这里我们缺少一个描述每个用户属性的数据框。作为解决方法,我们有不同的选择:
-
要么我们插入虚拟值(例如 0 到 1 之间的随机值,如 [0, 0.5, 0.1, 1]),然后通过消息传递进行更新
-
或者我们计算一些有关用户的统计数据,例如平均评分、评分数量……(基于评分数据框)
-
或者我们使用每个节点的典型特征作为特征(度、邻域、甚至 Node2Vec 嵌入)
我们将在这里选择第二个选项。
# 了解每个用户的平均评分和评分数
mean_rating = rating.groupby("user_id")["rating"].mean().rename("mean")
num_rating = rating.groupby("user_id")["rating"].count().rename("count")
user_node_features = pd.concat([mean_rating, num_rating], axis=1)# 重新映射用户 ID(从 0 开始)
user_node_features = user_node_features.reset_index(drop=False)
user_id_mapping = user_node_features["user_id"]# 只保留功能
user_node_features = user_node_features[["mean", "count"]]
user_node_features.head()
# Convert to numpy
x = user_node_features.to_numpy()
x.shape # [num_user_nodes x user_node_feature_dim]这些已经是我们的节点特征矩阵。当然,我们也可以将值标准化为 (0,1) 范围内。
对于电影,我们有明确的属性来描述每个节点。对于用户,我们计算了一些基本属性,提供有关评级行为的信息。
节点的数量和顺序由它们的形状隐式定义。每一行对应于最终图中的一个节点。
提取标签
在这个例子中,我们有一个链接预测/回归问题,因此标签就是边缘。下图显示了评分的分布。稍后的任务将是预测用户和电影之间的评分。
与现在的标签不同的Example 1是,标签等于边的数量。
rating.head()# Outputuser_id anime_id rating
0 1 20 -1
1 1 24 -1
2 1 79 -1
3 1 226 -1
4 1 241 -1#-1 means the user watched but didn't assign a weight
rating["rating"].hist()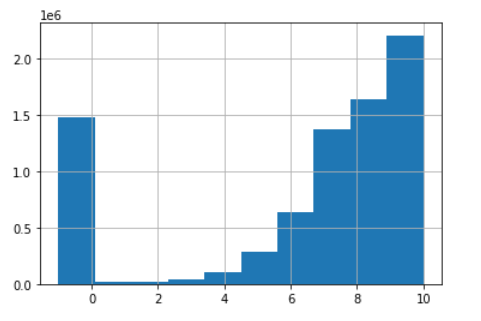
正如您所看到的(如下),我们并没有在评级表中包含所有电影(这很自然,因为我们通常没有所有项目的评级)。这意味着我们没有所有用户-项目对的标签,而只有一个子集。
为了在损失计算中考虑这一点,我们可以简单地存储可用索引的掩码。之前我也快速讨论过节点级预测情况下的掩模。这里完全相同——我们只想对有标签的实体进行预测。
由于我们这里有一个边缘预测问题,我们已经隐式地将这个掩码存储为edge_index。对于每条边,我们知道标签,因此我们只需根据我们知道的边计算损失。稍后在推理时,我们还可以预测其他节点对的边属性(标签)。
# Movies that are part of our rating matrix
rating["anime_id"].unique()# Output
array([ 20, 24, 79, ..., 29481, 34412, 30738])# All movie IDs (e.g. no rating above for 1, 5, 6...)
anime["anime_id"].sort_values().unique()# Output
array([ 1, 5, 6, ..., 34522, 34525, 34527])# We can also see that there are some movies in the rating matrix, for which we have no features (we will drop them here)
print(set(rating["anime_id"].unique()) - set(anime["anime_id"].unique()))
rating = rating[~rating["anime_id"].isin([30913, 30924, 20261])]# Output
{30913, 30924, 20261}提取标签
labels = rating["rating"]
labels.tail()
y = labels.to_numpy()
y.shape构建数据集
现在我们拥有为 Pytorch Geometric 或 DGL 等库构建图形所需的所有组件。我不会在这里安装这些库,因为这会使笔记本变得太大,但这里有一些最后步骤的代码片段。
对于异构图,我们需要将各个矩阵存储在HeteroData对象中,该对象可以保存多个节点/边矩阵。
from torch_geometric.data import HeteroDatadata import HeteroData
data = HeteroData()
data['user'].x = user_node_features
data['movie'].x = anime_node_features如果节点之间有不同的边类型,也可以在此考虑。在上面的示例中,我们只有一种类型,因此 edge_index 是这样的(三连串):
data['user', 'rating', movie'].edge_index = edge_index最后,我们可以像这样添加链接预测设置的标签。在异构图中,不同实体之间也可以有不同的标签,但这里我们只有一种类型。如果您专门构建推荐系统,那么您可能还会发现本关于二部图的教程很有帮助。
data['user', 'movie'].y = y![LeetCode 刷题 [C++] 第108题.将有序数组转换为二叉搜索树](https://img-blog.csdnimg.cn/direct/317f1a14272545969f0d1e53351510a0.png)