本地快速部署谷歌开放模型Gemma教程(基于WasmEdge)
- 一、介绍 Gemma
- 二、部署 Gemma
- 2.1 部署工具
- 2.1 部署步骤
- 三、构建超轻量级 AI 代理
- 四、总结
一、介绍 Gemma

Gemma是一系列轻量级、最先进的开放式模型,采用与创建Gemini模型相同的研究和技术而构建。可以直接运行在本地的电脑上,无GPU也可以运行,只用CPU即可,只不过速度慢点。
二、部署 Gemma
2.1 部署工具
使用 Linux 环境 + WasmEdge 一个工具部署Gemma,WasmEdge 用来运行模型。
WasmEdge:https://github.com/wasmedge/wasmedge
🤩 WasmEdge 是在您自己的设备上运行 LLM 的最简单、最快的方法。🤩
WasmEdge 是一个轻量级、高性能且可扩展的 WebAssembly 运行时。它是当今最快的 Wasm 虚拟机。WasmEdge 是CNCF主办的官方沙箱项目。其用例包括现代 Web 应用程序架构(同构和 Jamstack 应用程序)、边缘云上的微服务、无服务器 SaaS API、嵌入式功能、智能合约和智能设备。

2.1 部署步骤
- 安装具有 LLM 支持的 WasmEdge
可以从一行命令开始安装 WasmEdge 运行时,并提供 LLM 支持。
curl -sSf https://raw.githubusercontent.com/WasmEdge/WasmEdge/master/utils/install.sh | bash -s -- --plugins wasmedge_rustls wasi_nn-ggml
使用选项传递插件列表--plugins,安装wasmedge_rustls和wasi_nn-ggml插件。wasmedge_rustls插件以启用 TLS 和 HTTPS 网络,为启动API服务提供支持。wasi_nn-ggml使 WasmEdge 能够在大型语言模型(例如LMMs的 gemma)上运行人工智能推理程序。
安装完成后执行source /home/server/.bashrc,使wasmedge命令立即生效。
或者可以按照此处的安装指南手动下载并复制 WasmEdge 安装文件。
- 在 Wasm 中下载 LLM 聊天应用程序
接下来,获取超小型 2MB 跨平台二进制文件 - LLM 聊天应用程序,该应用程序允许您在命令行上与模型聊天。它证明了效率,不需要其他依赖项并提供跨各种环境的无缝操作,这个 2M 的小 Wasm 文件是从 Rust 编译而来的。
curl -LO https://github.com/LlamaEdge/LlamaEdge/releases/latest/download/llama-chat.wasm
- 下载Gemma-7b-it 模型 GGUF 文件,由于模型大小为5.88G,下载可能需要一段时间。
curl -LO https://huggingface.co/second-state/Gemma-7b-it-GGUF/resolve/main/gemma-7b-it-Q5_0.gguf
模型下载汇总:https://github.com/LlamaEdge/LlamaEdge/blob/main/models.md
WasmEdge 还支持 Llama2、CodeLlama、Codeshell、Mistrial、MiscialLite、TinyLlama、Baichuan、BELLE、Alpaca、Vicuna、OpenChat、Starcoder、OpenBuddy 等等!
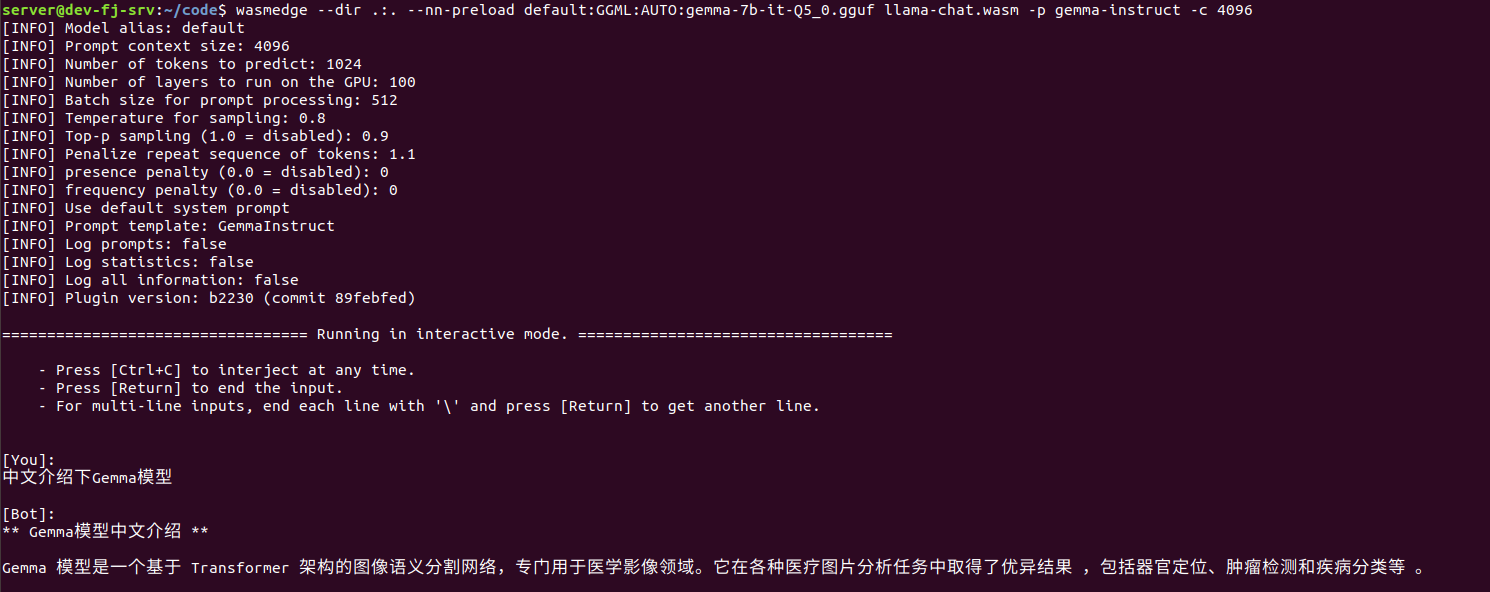
- 在 CLI 上与 Llama2 7b 模型聊天
现在您已完成所有设置,您可以开始使用命令行与 Llama2 7b 聊天支持的 LLM 聊天。
wasmedge --dir .:. --nn-preload default:GGML:AUTO:gemma-7b-it-Q5_0.gguf llama-chat.wasm -p gemma-instruct -c 4096
便携式 Wasm 应用程序会自动利用我设备上的硬件加速器(例如 GPU)。
[You]:
Create JSON for the following: There are 3 people, two males, One is named Mark. Another is named Joe. And a third person, who is a woman, is named Sam. The women is age 30 and the two men are both 19.[Bot]:
json
{"people": [{"name": "Mark","age": 19},{"name": "Joe","age": 19},{"name": "Sam","age": 30}]
}
您可以使用同一llama-chat.wasm文件来运行其他 LLM,例如 OpenChat、CodeLlama、Mistral 等。
三、构建超轻量级 AI 代理
- 创建兼容OpenAI的API服务
当您使用领域知识或自托管 LLama2 模型微调模型时,仅使用 CLI 运行模型是不够的。接下来,我们为开源模型设置兼容 OpenAI 的 API 服务,然后我们可以将微调后的模型集成到其他工作流程中。
假设您已经安装了带有 ggml 插件的 WasmEdge 并下载了您需要的模型。
首先,通过终端下载Wasm文件来构建API服务器,它也是一个跨平台的便携式 Wasm 应用程序,可以在许多 CPU 和 GPU 设备上运行。
curl -LO https://github.com/LlamaEdge/LlamaEdge/releases/latest/download/llama-api-server.wasm
- 下载聊天机器人 Web UI,以通过聊天机器人 UI 与模型进行交互。
curl -LO https://github.com/LlamaEdge/chatbot-ui/releases/latest/download/chatbot-ui.tar.gz
tar xzf chatbot-ui.tar.gz
rm chatbot-ui.tar.gz
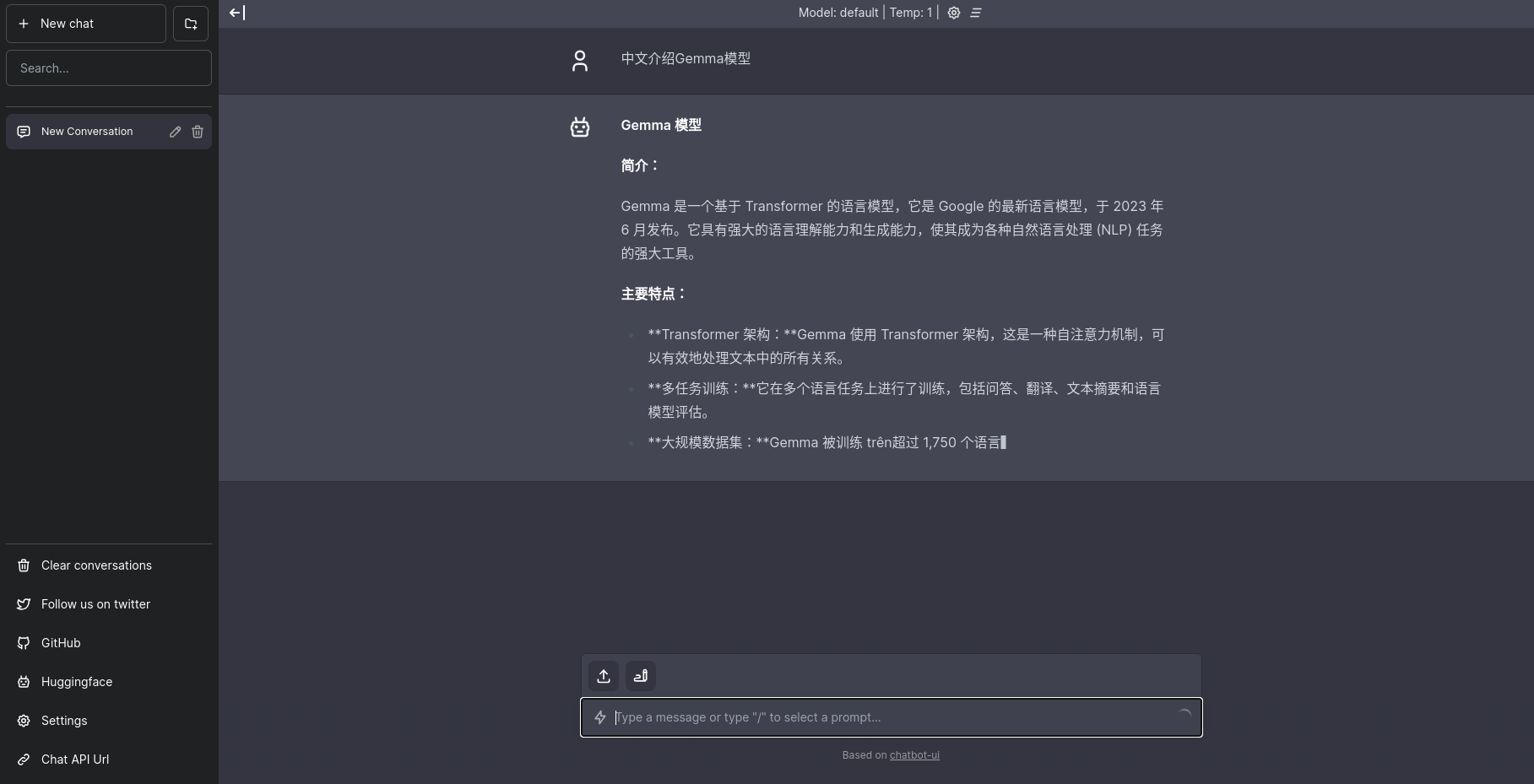
- 使用以下命令行启动模型的 API 服务器。
wasmedge --dir .:. --nn-preload default:GGML:AUTO:gemma-7b-it-Q5_0.gguf llama-api-server.wasm -p gemma-instruct -c 4096
然后,看到连接已建立后,打开浏览器访问http://0.0.0.0:8080/即可使用可视化操作页面聊天。
server@dev-fj-srv:~/code$ wasmedge --dir .:. --nn-preload default:GGML:AUTO:gemma-2b-it-Q5_0.gguf llama-api-server.wasm -p gemma-instruct -c 4096
[2024-03-01 09:46:45.391] [error] instantiation failed: module name conflict, Code: 0x60
[2024-03-01 09:46:45.391] [error] At AST node: module
[INFO] Socket address: 0.0.0.0:8080
[INFO] Model name: default
[INFO] Model alias: default
[INFO] Prompt context size: 4096
[INFO] Number of tokens to predict: 1024
[INFO] Number of layers to run on the GPU: 100
[INFO] Batch size for prompt processing: 512
[INFO] Temperature for sampling: 1
[INFO] Top-p sampling (1.0 = disabled): 1
[INFO] Penalize repeat sequence of tokens: 1.1
[INFO] Presence penalty (0.0 = disabled): 0
[INFO] Frequency penalty (0.0 = disabled): 0
[INFO] Prompt template: GemmaInstruct
[INFO] Log prompts: false
[INFO] Log statistics: false
[INFO] Log all information: false
[INFO] Starting server ...
[INFO] Plugin version: b2230 (commit 89febfed)
[INFO] Listening on http://0.0.0.0:8080
您可以使用以下命令行来尝试您的模型。
curl -X POST http://localhost:8080/v1/chat/completions \-H 'accept: application/json' \-H 'Content-Type: application/json' \-d '{"messages":[{"role":"system", "content": "You are a helpful assistant. Answer each question in one sentence."}, {"role":"user", "content": "Who is Robert Oppenheimer?"}], "model":"llama-2-chat"}'
四、总结
此教程用于基于 WasmEdge 系统的部署,可根据自身需求定制部署环境,灵活调整配置参数,满足个性化需求。对模型和数据拥有完全控制权,可自由进行二次开发和扩展。