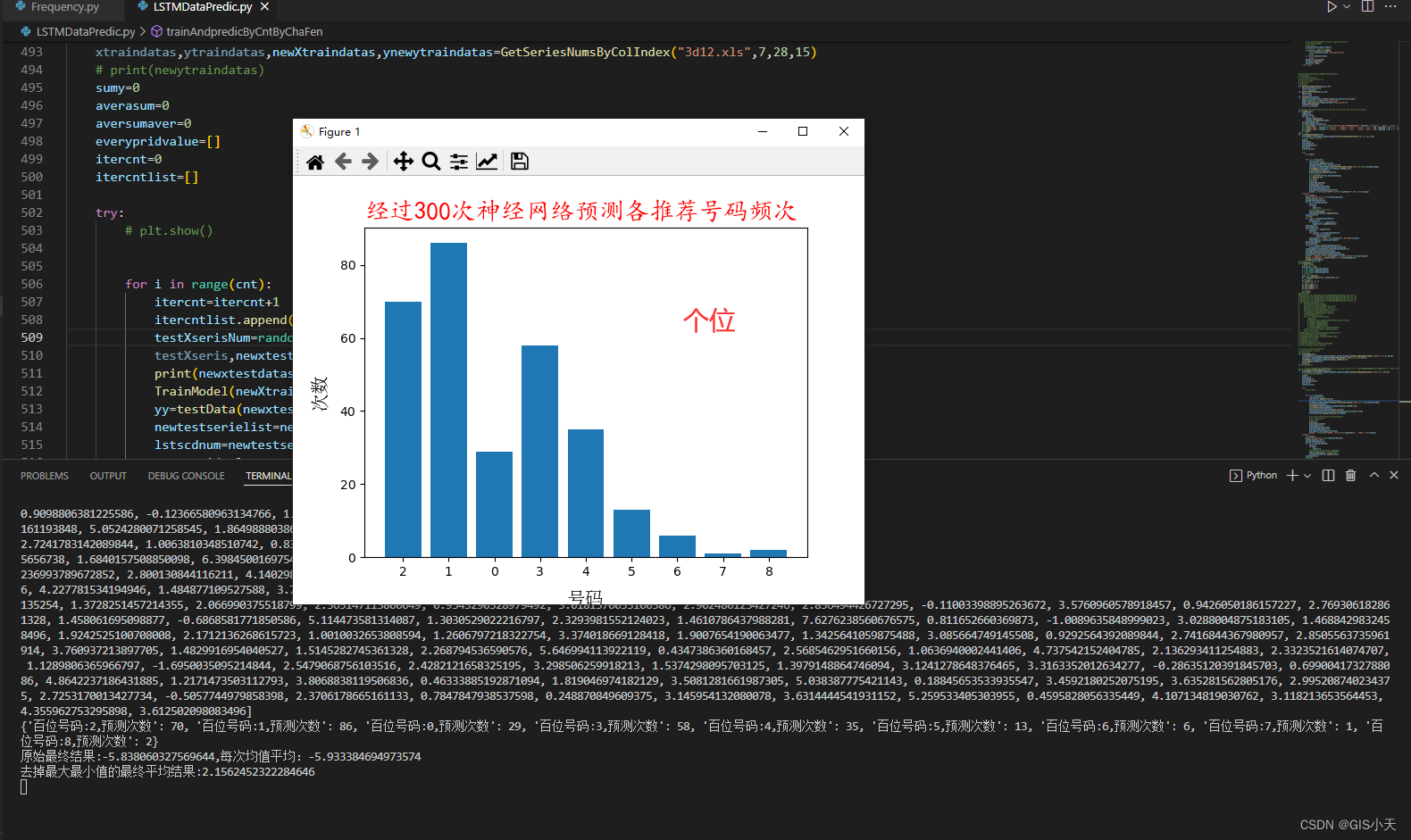
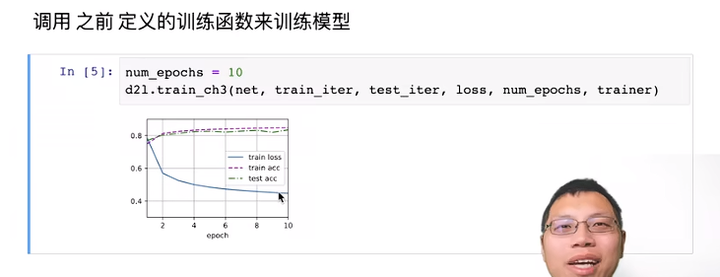
我们如何获取我们想要的数据,这里我们通过 leafmap python软件包实现NASA数据种全球超过9000+的数据集产品的接入和使用。这里我们使用在线的colab来实现处理,因为这里我们可以很好的应用已经在线配置好的colab环境来实现,省去了安装过程的繁琐。
要下载和访问数据,您需要创建一个 Earthdata 登录。在这个过程中我们首先要通过Earthdata Login网址去进行注册,然后邮箱验证,确保你有一个账户的接口来接入NASA这个平台中。
搜索和下载美国国家航空航天局地球科学数据产品
Leafmap 基于 earthaccess Python 软件包,用于搜索和下载 NASA 地球科学数据产品,使数据产品的足迹可视化和交互式下载变得更加容易。
安装leafmap
!pip install leafmap
!pip install pandas导入安装包
import leafmap
import pandas as pd载入nasa接口
leafmap.nasa_data_login()这里当我们接入的时候会提示我们输入我们的用户名称:

这里我们会发现我们出现了错误,错误的主要原因在于我们需要在NASA官网上进行token的获取,只有产生了这个东西,这里才能通过colab进行接入。按照下面的操作来进行。在网站上登录后选择GenerateToken->Generate a Bearer Token即可。
用户令牌是 EDL 的一项新功能,并非所有 EDL 集成应用程序都支持。
您可以为联盟令牌访问共享生成一个不记名令牌。并非所有 EDL 应用程序都支持联合令牌访问共享。
您最多可同时拥有 2 个活动令牌。
然后,可以使用授权(Authorization)将令牌传入应用程序:承载器标头
令牌只对符合 EDL 标准且没有未经批准的 EULA 的应用程序进行授权
 成功后我们再次运行上面那条命令就欧克了。
成功后我们再次运行上面那条命令就欧克了。

数据检索
您可以按短名、doi、概念 ID 等搜索数据。您可以从 NASA-Earth-Data repo 中找到 NASA 地球科学数据产品列表。下面的示例展示了如何显示 9000 多个 NASA 地球科学数据产品的元数据。 因为nasa是在github上存放的数据集,这里我们可以直接接入这个链接来进行是读取和查看。
数据列表加载和展示
url = "https://github.com/opengeos/NASA-Earth-Data/raw/main/nasa_earth_data.tsv"
df = pd.read_csv(url, sep="\t")
df这里pd读取CSV的源代码:
def read_csv(filepath_or_buffer: FilePath | ReadCsvBuffer[bytes] | ReadCsvBuffer[str],sep: str | None | lib.NoDefault = lib.no_default,delimiter: str | None | lib.NoDefault = None,# Column and Index Locations and Namesheader: int | Sequence[int] | None | Literal["infer"] = "infer",names: Sequence[Hashable] | None | lib.NoDefault = lib.no_default,index_col: IndexLabel | Literal[False] | None = None,usecols=None,squeeze: bool | None = None,prefix: str | lib.NoDefault = lib.no_default,mangle_dupe_cols: bool = True,# General Parsing Configurationdtype: DtypeArg | None = None,engine: CSVEngine | None = None,converters=None,true_values=None,false_values=None,skipinitialspace: bool = False,skiprows=None,skipfooter: int = 0,nrows: int | None = None,# NA and Missing Data Handlingna_values=None,keep_default_na: bool = True,na_filter: bool = True,verbose: bool = False,skip_blank_lines: bool = True,# Datetime Handlingparse_dates=None,infer_datetime_format: bool = False,keep_date_col: bool = False,date_parser=None,dayfirst: bool = False,cache_dates: bool = True,# Iterationiterator: bool = False,chunksize: int | None = None,# Quoting, Compression, and File Formatcompression: CompressionOptions = "infer",thousands: str | None = None,decimal: str &#