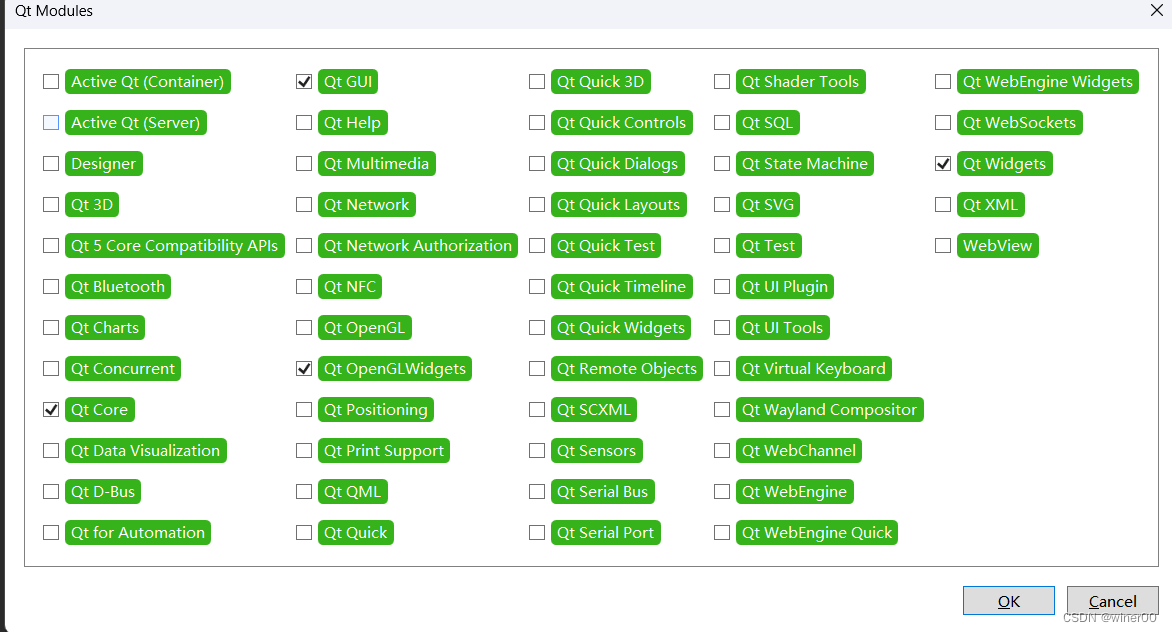
背景
作为网络摄像头拉流客户端,或者其他类型的流媒体播放而言,低延迟总是我们追求的重点性能要素。有一些低延迟方法可以在推流端设置,但倘若像摄像头这种场景,根本就无法控制摄像头端的自身延迟,只能从接收端动手。
常见的低延迟方法一种是通过设置ffmpeg低延迟参数:
比如:
AVDictionary *options = NULL;av_dict_set(&options, "rtsp_transport", "tcp", 0);av_dict_set(&options, "fflags", "nobuffer", 0);av_dict_set(&options, "flags", "low_delay", 0);
另一种方法是使用摄像头的官方SDK,比如海康摄像头提供的SDK(不支持arm平台,且不是所有的摄像头厂商都有SDK,比如国产摄像头-创世之星)。
经过我实际的对比测试后,发现延迟还是达不到理想的状态。假设使用海康摄像头,编码参数设置H264 1080P@25fps的视频, ffmpeg设置低延迟,局域网环境下,端到端的延迟在130ms。另从网络上了解到,使用海康SDK,端到端延迟在200ms内。
那我们是否还有其他办法来降低拉流延迟吗?
技术介绍
当然有。从摄像头相关领域专业人员了解到,目前端到端网络摄像头的延迟基本为90ms左右。而本文使用的技术方法就可以让延迟降低到稳定的90ms内。
首先我们来分析下摄像头从拉流到渲染出来的链路,然后我们预估一个耗时情况。

从上图可以看到,假设我们是30fps的摄像头,则端到端的理论延迟数据应该在80ms左右。虽然这只只是一个粗估值,但至少让我们知道底线在哪里。
蓝色框的处理是摄像头本身的处理耗时,我们无法干预。绿色框我们可以干预一部分,比如优化网络,优化rtsp接收。棕色框我们也可以优化,比如使用硬解码,使用更快的渲染送显方式。橙色框是垂直同步信号的固定周期,我们也无法控制。
接下来我们就想办法如何达到这个理论延迟值。
一 rtsp 接收部分
如果想要最低延迟,我们就不能使用ffmpeg了。因为ffmpeg内部有一些队列、缓冲等处理机制,哪怕设置了低延迟,但总之封装度越高,效率越低肯定没错。不使用ffmpeg我们而是直接使用live555。但只是在流媒体接收这块不使用ffmpeg,对于后面的硬解码还是需要ffmpeg的。
关于live555的使用其实很简单,官网源码有例子 http://www.live555.com/liveMedia/
,具体见源码中 testRTSPClient.cpp。live555中 rtsp协议的握手流程比较固定,主要是这几步:
1.openURL() 打开url,请求和服务端建立连接
2.创建RTSPClient() 每个流都会有一个RTSPClient对象
3.env->taskScheduler().doEventLoop(&eventLoopWatchVariable) 开启live内部事件循环(在事件循环内部,live会帮助我们异步回调握手节点和之后接收的每一帧数据)
4.开始真正的握手:客户端->>服务器:DESCRIBE服务器->>客户端: 200 OK (SDP)客户端->>服务器:SETUP服务器->>客户端: 200 OK (SETUP阶段,我们就可以得到此流媒体的编码格式、视频宽高、通道数、FPS等信息,同时也可以在这个阶段创建我们之后接收帧数据所需要的DummySink类了,每个DummySink类都和一个创建RTSPClient相关联)客户端->>服务器:PLAY服务器->>客户端: (RTP包)
了解流程后,我们需要将live555代码集成到我们的项目中,用法照抄testRTSPClient.cpp中的代码即可。
接下来我们需要重点关注 DummySink 的 afterGettingFrame函数,当收到服务端推过来的流后,LIVE会帮助我们将其组成完整的一帧,然后此函数将被LIVE的事件循环调用,一个完整的“帧”(对于H.264,这将是一个“NAL单元”)将被设置到DummySink的“fReceiveBuffer”变量中。
以H264为例,收到数据后,我们可以判断是视频数据还是音频数据(本文中我们只关心视频数据):
bool isVideo = (strcmp(fSubsession.mediumName(), "video") == 0);
也可以通过fSubsession.codecName()得到流媒体是H264还是H265编码格式。
以上内容即我们如何使用live555接收到rtsp流媒体数据。接收到数据之后,下一步要做的就是准备解码了。
但假如此时我们直接将收到的数据交给ffmpeg进行解码,就会看到播放时遇到每个关键帧都会卡顿一下(比如每秒30帧的流媒体,GOP设置60,则每2S就是一个关键帧),然后发现ffmpeg在解码h264时每遇到一个关键帧都会报错:
no frame!
Invalid data found when processing input
Got unexpected packet after EOF
这就会导致一个问题,频繁的卡顿导致帧率不稳定,导致观察延迟会存在很大的误差,根本无法统计延迟数据。
究其原因是因为live收到的流媒体数据缺少ffmpeg解码h264所需要的sps和pps信息。所以接下来第二部分让我们看下当收到一帧数据后如何将数据处理能被ffmpeg正确解码。
二 H264和H265组帧
参考: 用live555接收实时摄像头的RTSP流,视频编码为H264,如何用FFMPEG解码?
首先需要知道的基本概念:
- NALU:H264编码数据存储或传输的基本单元,一般H264码流最开始的两个NALU是SPS和PPS,第三个NALU是IDR。SPS、PPS、SEI这三种NALU不属于帧的范畴。
- SPS(Sequence Parameter Sets):序列参数集,作用于一系列连续的编码图像。
- PPS(Picture Parameter Set):图像参数集,作用于编码视频序列中一个或多个独立的图像。
H264
如果摄像头端是h264编码,则收到的前两个nalu即为sps和pps:
/*H264*///SPS header & 0X1F == 7 0x67//PPS header & 0X1F == 8 0x68//SEI header & 0X1F == 6 一般没有SEI//I帧 header & 0X1F == 5 SPS和PPS之后紧接着就是I帧数据//P帧 header & 0X1F == 1 I帧往后就是P帧
我们可以用上面的方法判断当前收到的nalu是否是sps或者pps,比如下面的完整代码演示了如何判断sps和pps:
bool isIDR = false;//H264if(fSubsession.codecName() == "H264"){if ((fReceiveBuffer[0] & 0x1F) == 7) {//缓存SPS,等I帧到来把 缓存的SPS加到I帧之前,并穿插00000001spsBufferLength = frameSize + 4;char codec_header[4] = {00, 00, 00, 01};memcpy(spsBuffer, codec_header, 4);memcpy(spsBuffer + 4, fReceiveBuffer, frameSize);continuePlaying();return;}else if ((fReceiveBuffer[0] & 0x1F) == 8) {char codec_header[4] = {00, 00, 00, 01};//缓存PPS,等I帧到来把 缓存的PPS加到I帧之前,并穿插00000001ppsBufferLength = frameSize+ 4;memcpy(ppsBuffer, codec_header, 4);memcpy(ppsBuffer + 4, fReceiveBuffer, frameSize);continuePlaying();return;}else if ((fReceiveBuffer[0] & 0x1F) == 5) {isIDR = true;}}
判断出sps和pps之后,我们需要将其暂时缓存起来,等收到idr帧之后,将之前的sps和pps添加到idr帧的前面,满足下面这样的格式:
0x00 0x00 0x00 0x01 + SPS + 0x00 0x00 0x00 0x01 + PPS + 0x00 0x00 0x00 0x01 + IDR帧
这样组成的一个buffer,FFMPEG的H264解码器才能成功解码。
H265
如果摄像头端是h265编码,则收到的前三个nalu为vps、sps和pps:
/*H265//VPS header & 0X1F == 32 0x40//SPS header & 0X1F == 33 0x42//PPS header & 0X1F == 34 0x44//SEI header & 0X1F == 39 0x27 一般没有SEI//I帧 header & 0X1F == 19 0x26 SPS和PPS之后紧接着就是I帧数据//P帧 header & 0X1F == 1 0x02 I帧往后就是P帧
但特殊的,对于H265来说,不特殊处理VPS SPS PPS,ffmpeg解码也不会报错,所以可以兼容也可以不处理。
以下代码演示了如何判断vps、sps和pps:
bool isIDR = false;//H265if(fSubsession.codecName() == "H265"){if((fReceiveBuffer[0] & 0x7E) >> 1 == 32) {//缓存VPS SPS和PPS,等I帧到来把 缓存的VPS SPS 和PPS加到I帧之前,穿插00000001vpsBufferLength = frameSize + 4;char codec_header[4] = {00, 00, 00, 01};memcpy(vpsBuffer, codec_header, 4);memcpy(vpsBuffer + 4, fReceiveBuffer, frameSize);continuePlaying();return;}else if ((fReceiveBuffer[0] & 0x7E) >> 1 == 33) {spsBufferLength = frameSize + 4;char codec_header[4] = {00, 00, 00, 01};memcpy(spsBuffer, codec_header, 4);memcpy(spsBuffer + 4, fReceiveBuffer, frameSize);continuePlaying();return;}else if ((fReceiveBuffer[0] & 0x7E) >> 1 == 34) {char codec_header[4] = {00, 00, 00, 01};ppsBufferLength = frameSize+ 4;memcpy(ppsBuffer, codec_header, 4);memcpy(ppsBuffer + 4, fReceiveBuffer, frameSize);continuePlaying();return;}else if ((fReceiveBuffer[0] & 0x7E) >> 1 == 19) {isIDR = true;}}
将vps、sps和pps缓存之后,在接下来当收到idr帧,我们可以进行格式拼装了:
// 0x00 0x00 0x00 0x01 + VPS + 0x00 0x00 0x00 0x01 + SPS + 0x00 0x00 0x00 0x01 + PPS + 0x00 0x00 0x00 0x01 + IDR帧char codec_header[4] = {00, 00, 00, 01};
std::vector<uint8_t> fReceiveBuffer_vec(vpsBufferLength + spsBufferLength + ppsBufferLength + frameSize + 4);
if(isIDR)
{if(nullptr != vpsBuffer){memcpy(fReceiveBuffer_vec.data(), vpsBuffer, vpsBufferLength);}memcpy(fReceiveBuffer_vec.data()+vpsBufferLength, spsBuffer, spsBufferLength);memcpy(fReceiveBuffer_vec.data()+vpsBufferLength+spsBufferLength, ppsBuffer, ppsBufferLength);memcpy(fReceiveBufferWithHeader, codec_header, 4);memcpy(fReceiveBuffer_vec.data()+vpsBufferLength+spsBufferLength+ppsBufferLength, fReceiveBufferWithHeader, 4);memcpy(fReceiveBuffer_vec.data()+vpsBufferLength+spsBufferLength+ppsBufferLength+ 4, fReceiveBuffer, frameSize);if(nullptr != vpsBuffer){memset(vpsBuffer,0,vpsBufferLength);vpsBufferLength = 0;}memset(ppsBuffer,0,ppsBufferLength);memset(ppsBuffer,0,ppsBufferLength);spsBufferLength = 0;ppsBufferLength = 0;fillSPSOver = true;
}else
{memcpy(fReceiveBuffer_vec.data(), fReceiveBufferWithHeader, 4);memcpy(fReceiveBuffer_vec.data() + 4, fReceiveBuffer, frameSize);
}这步做完之后,就可以将组装好的数据交给ffmpeg进行解码了。一般情况下,我们使用ffmpeg解码都是使用av_read_frame解封装得到一个AVPacket进行解码,那对于自己拼装的帧如何解码呢?
三 解码
很简单,我们可以自己构造一个AVPacket,如果需要给AVPacket填充更多的信息,可以从rtsp握手的SETUP阶段去拿到想要的信息。就单纯的解码而言,经过测试发现不需要其他额外的信息。
AVPacket packet;
av_init_packet(&packet);
packet.data = fReceiveBuffer_vec.data();
packet.size = fReceiveBuffer_vec.size();avcodec_decode_video2(avctx, frame, got_frame_ptr, &packet);
然后,调用avcodec_decode_video2进行解码即可。
四 渲染问题
在硬解码后进行渲染时,发现无论是使用X11方式还是EGL+OPENGL方式,当摄像头推流帧率为60帧时,渲染函数耗时总是需要十几ms。而当摄像头推流帧率是30帧时,渲染函数耗时只需要1-2ms。
经过交叉验证还发现和此问题相关的结论:
- 只有60帧的流媒体存在此问题,渲染60帧的视频没有此问题。
- 不用摄像头流,使用vlc在本地推流进行验证,也存在同样的问题。
- 使用类似于glxgears的opengl测试程序,发现当帧率一旦超过60FPS,则渲染提交函数(glswapbuffers、vaputsurface)耗时=17ms - 渲染循环间隔时间。
最终怀疑是流媒体推流不稳定,经常出现小于17ms间隔的推流,渲染线程也就同样的频繁低于17ms间隔进行渲染,真实渲染帧率已经大于60fps了,导致渲染函数被垂直同步周期限制。因为显示器是60fps的刷新率,所以垂直同步信号是16.67ms一次,如果上屏的间隔小于16.67ms,则会被block住,直到时间到达,显卡才允许下一次提交。
为了验证猜想,使用vblank_mode=0关闭垂直同步,再次测试发现问题消失,渲染函数每次耗时恢复到1-2ms。
五 延迟观测和统计方法纠偏
为了让我们的延迟统计更加准确,防止不必要的误差引入导致数据失真。尤其是在摄像头低于60fps推流配置下,比如25fps、30fps,如果使用常规的观测方法可能会出现下述的误差问题。因此我们对方法进行review后发现确实存在多余的误差引入。
常规的延迟统计方法:
假设摄像头配置30fps(市面上大多数摄像头只支持到最大30fps)
电脑上(显示器设置不小于60fps的刷新率)启动一个16ms刷新一次的毫秒级计时器程序。然后用摄像头对准计时器,电脑屏幕上渲染出当前摄像头录制到的计时器画面。
此时用另外一个手机(按60fps录制)对电脑画面进行录制,录制一段时间后,在电脑上用比如potplayer或者其他支持逐帧查看的视频播放器进行逐帧回放,对比手机上的计时器时间戳和程序渲染出摄像头的时间戳,差值即是延迟,多次随机采样后得出差值的平均值、极差、众数等数据。
上述方法的问题:

以上图为例,当我们用摄像头对着显示器录制视频时,A区域显示摄像头的视频流(里面包含了B区域的计时器“投影”),B区域显示毫秒计时器。我们用手机录制1080P@60FPS的视频,并在电脑上用potplayer 16ms步进一次逐帧观察。
我们以A区域的渲染画面变化为基准,当A定格在某一帧时,它将会持续停留33ms。在这33ms内,此时B区域可能会刷新2帧(33/16.67=2)。
我们之前的统计方法是随机采样,意味着A区域定格的画面,B区域可能在第一帧,或者第二帧,所以之前的采样方法可能踩到了第一帧,也可能是第二帧。这就会导致我们在采样数据中引入了平均16.67ms的误差。其实通过potplayer可以看到,每16.67ms步进时,A区域变化一帧,B区域总是不稳定的变化1-3帧。
所以正确的采样方法应该是:
当A区域一旦变化到新的一帧,采样此时此刻的B区域画面,然后比较两个画面的时间差,切勿采样到B区域的第二帧画面。
用下面三张图举例验证:
当A区域的毫秒时间是459时,第一张图的B区域时间是526,第二张图是543,第三张图是559,那我们到底用哪张图来代表延迟呢?
根据上面的理论分析,肯定是用第一张,如果用第三张就会白白带入33ms的延迟误差。

总结
经过实测,这样“接近原始”的方法延迟最低可以控制在90ms以内,当然不同的摄像头因为性能原因可能存在差异,我用的是海康的DS-IPC-T12HV3-IA球形摄像头。
另外一些可能增加延迟的节点:
- 因为RTSP网络包的单次传输大小是有限的,一个I帧数据包在网络中要分成几十包传输,等最后一包数据到达,整个传输过程在网络中平均需要6-10ms(见下图抓包数据,mark代表I帧:t2-t1=6ms),所以在每个I帧时,就会增加对应时间的时间损耗。

- 因为摄像头推流的速率虽然说是按照帧率来的,比如每秒30帧的流媒体,理论上应该每33ms到达一帧,并保证在33ms这个时间戳之前,所有分包数据都到达,且最后一包必须在33ms的时间戳上到达。但实际上,抓包分析后发现摄像头推流速率并不稳定,有时20ms就到达了,有时候50ms才到达(见下图)。所以这个因素也是引起延迟跳变的原因之一。


关注公众号 QTShared 获取源码。