前言
2021年5月,OpenAI发表了《扩散模型超越GANs》的文章,标志着扩散模型(Diffusion Models,DM)在图像生成领域开始超越传统的GAN模型,进一步推动了DM的应用。
然而,早期的DM直接作用于像素空间,这意味着要优化一个强大的DM通常需要数百个GPU天,而推理成本也很高,因为需要多次迭代。为了在有效的计算资源上训练DM,并保持其质量和灵活性,作者提出将DM应用于强大的预训练自动编码器的潜空间(Latent Space),这也是为什么提出的模型叫LDM的原因。与以往的方法相比,这种方式首次实现了在降低复杂性和保留细节之间的平衡,并显著提高了视觉逼真度。
此外,作者还在模型中引入了交叉注意力层,使得可以轻松地将文本、边界框等条件引入到模型中,将DM转化为强大而灵活的生成器,实现高分辨率的生成。作者提出的LDM模型在图像修复、条件生成等任务中表现良好,并且与基于像素空间的扩散模型相比,大大降低了计算要求。在Stable Diffusion(LDM)的基础上,SDXL将U-Net主干扩大了三倍:主要是使用了第二个文本编码器,因此还使用了更多的注意力块和交叉注意力上下文。此外,作者设计了多分辨率训练方案,训练了具有不同长宽比的图像。他们还引入了一个细化模型,以进一步提高生成图像的视觉逼真度。结果表明,与之前的Stable Diffusion版本相比,SDXL的性能有了显著提升,并且取得了与其他非开源模型相当的效果。这个模型和代码都是完全开源的。
在SDXL的基础上,作者提出了对抗性扩散蒸馏技术(Adversarial Diffusion Distillation,ADD),将扩散模型的步数减少到1-4步,同时保持很高的图像质量。结果表明,这个模型在1步生成方面明显优于现有的几步生成方法,并且仅用4步就超越了最先进的SDXL性能。这个训练出的模型被称为SDXL-Turbo。
Latent Diffusion Model(LDM)
LDM 和其他扩散生成模型的结构类似,其结构包括自编码器、条件部分和降噪 U-Net,总体上包括三个主要组件:
-
自编码器(Auto Encoder):
- 编码器(Encoder):将输入图像编码为低维度的表示,通常称为隐变量或隐向量。这一步的目的是将输入数据压缩到一个更紧凑的表示,捕捉输入数据的主要特征。
- 解码器(Decoder):将编码后的低维表示解码为原始图像。解码器的作用是从隐变量中重建输入数据,使得重建图像尽可能地接近原始输入。
-
条件部分(Conditioning):
- 用于对各种条件信息进行编码,以辅助生成过程。这些条件信息可以是多样化的,比如文本描述、图像修复或分割条件等。
- 不同类型的条件需要不同的编码器模型,以便将它们转换为嵌入向量。这些嵌入向量将会被整合到生成过程中。
- 在生成过程中,这些条件信息可以通过连接(Concatenation)或注意力机制与噪声或隐变量相结合,以影响生成图像的特征。
-
降噪 U-Net(Denoising U-Net):
- 用于从随机噪声中生成隐变量,并通过多步迭代的方式逐渐改进这些隐变量,以便生成最终的图像。
- 这个过程通常涉及到 U-Net 结构,它是一种常见的用于图像生成和修复的神经网络结构,具有编码器-解码器的形式,并且在中间包含跨层连接,以帮助保留图像的细节信息。
- 在生成过程中,各种条件信息通过交叉注意力机制与隐变量相结合,以确保生成的图像能够与条件信息匹配。
在AutoEncoder中,Encoder用于对图像进行压缩,生成latent code。假设输入图像的分辨率为HxW,则压缩率为f时,对应的latent code大小为H/f x W/f。举例来说,如果图像分辨率为512x512,那么f=4时的压缩率对应的latent code大小为64x64,即z的大小为64x64。
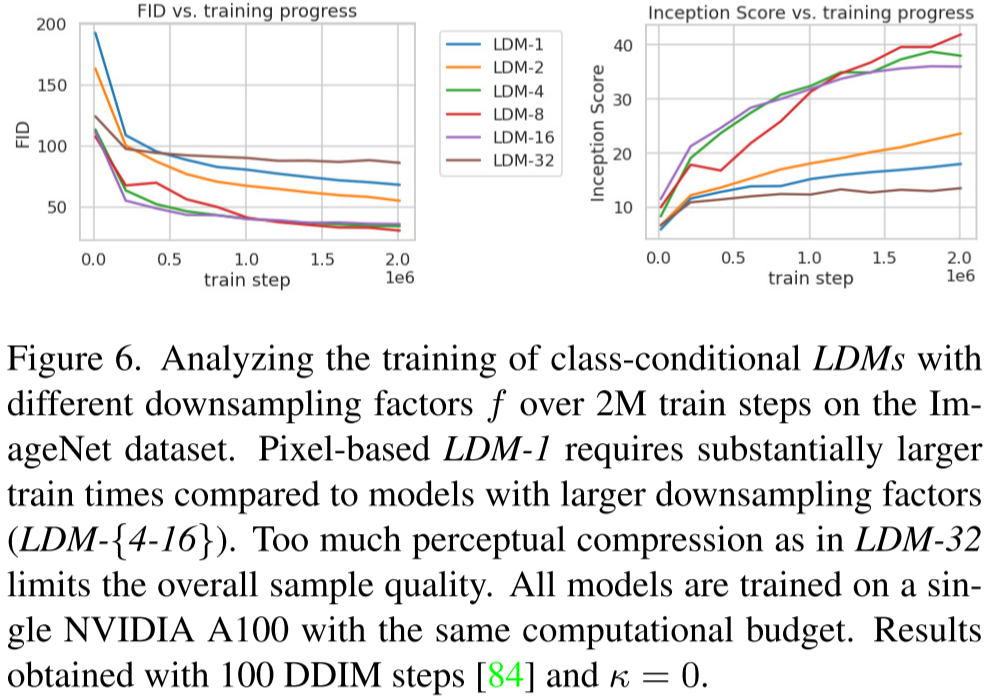
作者进行了一系列实验,探究不同压缩率下的模型性能,对应的模型命名为LDM-{f},包括LDM-1、LDM-2、LDM-4、LDM-8、LDM-16和LDM-32。在这个命名规则下,LDM-1相当于没有压缩,直接作用于像素空间;而LDM-32则是压缩率最高的情况,512x512分辨率的图像对应的latent code大小只有16x16。
实验结果显示,在压缩率为4、8和16时,模型获得了最佳平衡点,这意味着在生成图像质量和模型复杂度之间找到了一个合适的折中点。然而,当压缩率为32时,生成图像的质量下降,这可能是因为压缩率太高,导致信息丢失,latent code无法捕捉到足够多的图像信息,从而影响了生成图像的质量。
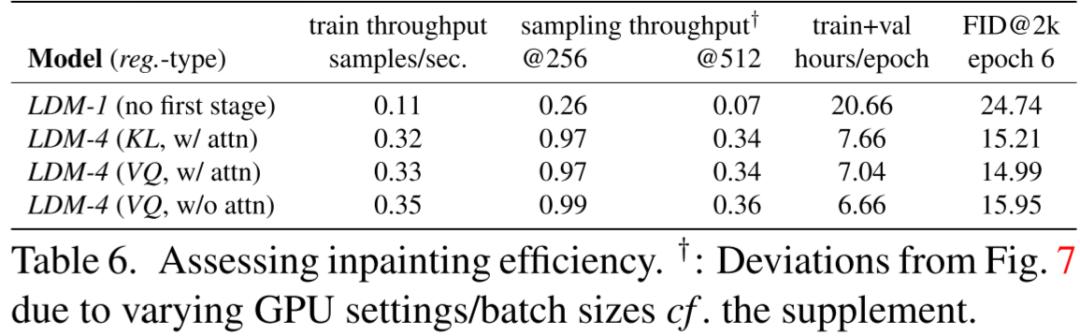
如下图 Table 6 所示,作者同样在图像修复任务上验证了不同压缩率、Cross Attention 的影响,可以看出 LDM-4 的训练、推理吞吐相比 LDM-1 有明显提升,并且 Attention 对吞吐的影响也不大。同时 LDM-4 还获得更好的效果(更低的 FID):
3.3. Latent Diffusion Models
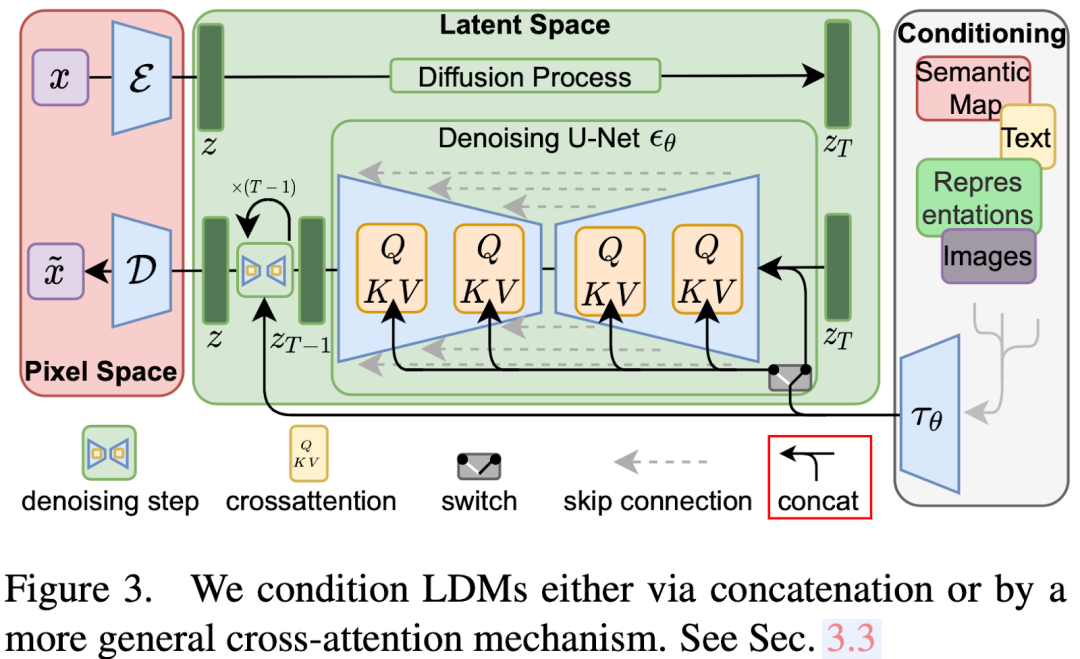
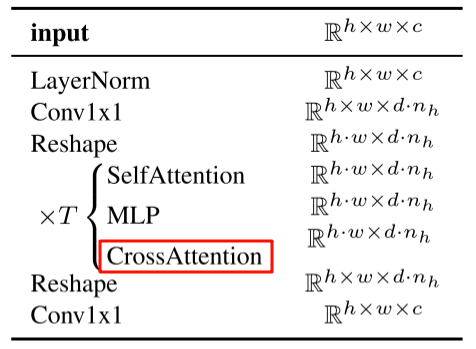
本文中作者使用的 U-Net 模型是基于 OpenAI Diffusion Models Beat GANs 中的 Ablated U-Net 修改而来,具体来说是将其中的 Self-Attention 替换为 T 个 Transformer block,每个 block 中包含一个 Self-Attention,一个 MLP 和一个 Cross-Attention,如下图所示,其中的 Cross Attention 就是用于和其他条件的 embedding 进行交叉融合:
3.4. Conditioning 机制
LDM 支持多种条件类型,比如类别条件、文本条件、分割图条件、边界框条件等。
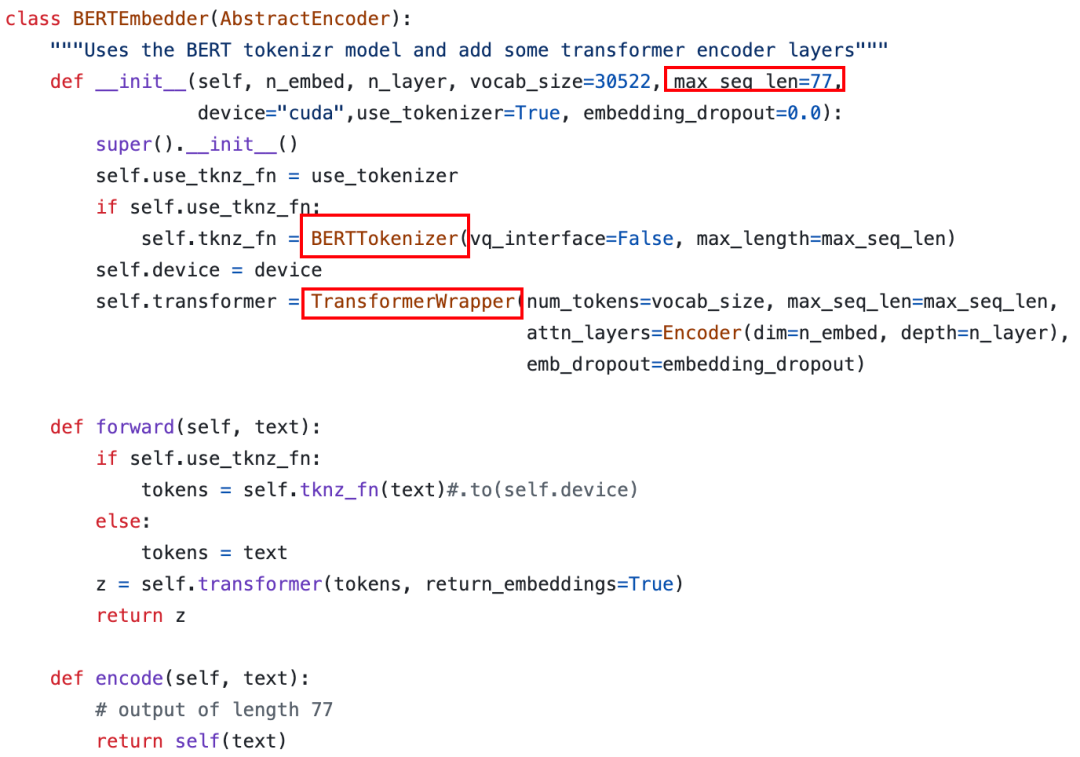
对于文本条件,可以使用常用的文本 Encoder,比如 Bert 模型,或者 CLIP 的 Text Encoder,其首先将文本转换为 Token,然后经过模型后每个 Token 都会对应一个 Token embedding,所以文本条件编码后变为一个 Token embedding 序列。
对于 layout 条件,比如常见的边界框,每个边界框都会以(l,b,c)的方式编码,其中 l 表示左上坐标,b 表示右下坐标,c 表示类别信息。
对于类别条件,每个类别都会以一个可学习的 512 维向量表示,同样通过 Cross-Attention 机制融合。
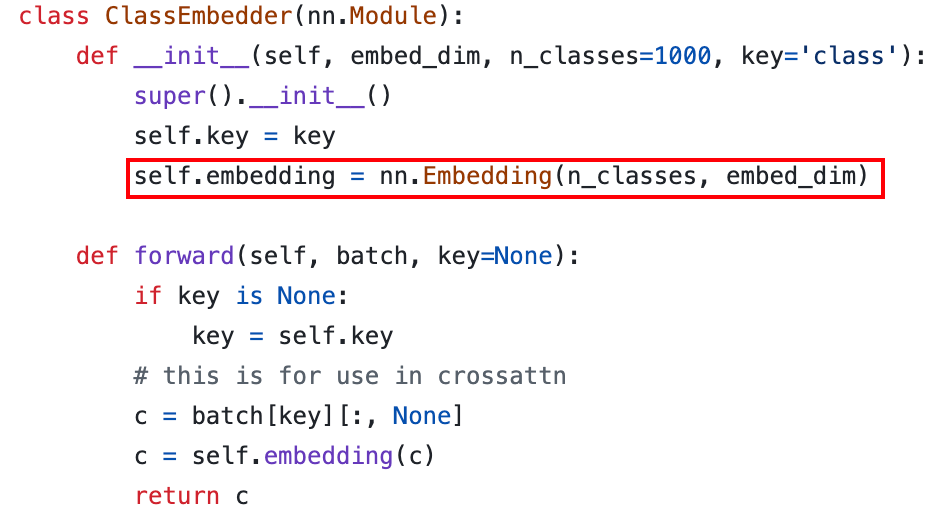
对于分割图条件,可以将图像插值、卷积后编码为 feature map,然后作为条件。



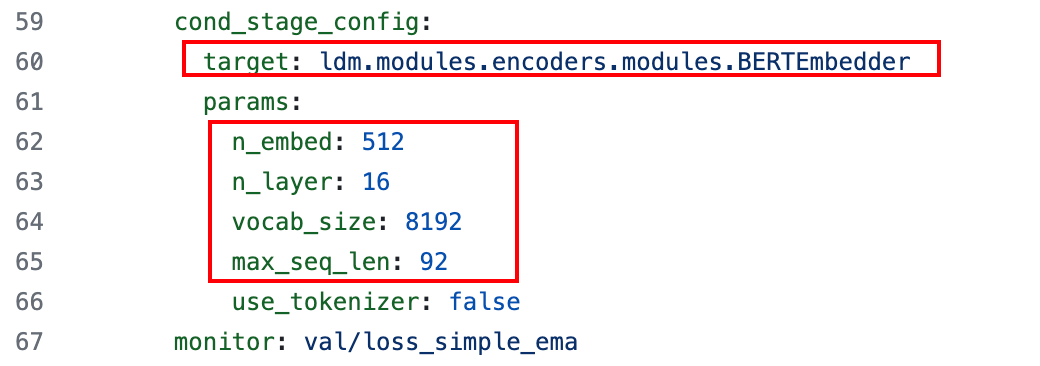
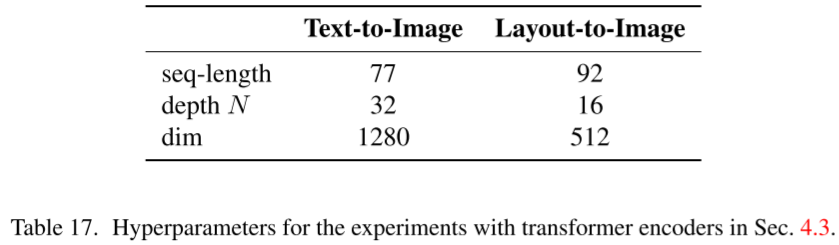
其中文本条件和 layout 条件都通过 Transformer Encoder 编码,对应的超参如下图 Table 17 所示,也就是文本最多只能编码为 77 个 Token,Layout 最多编码为 92 个 Token:
所谓的 layout-to-image 生成如下图所示,给定多个边界框,每个边界框有个类别信息,生成的图像要在对应的位置生成对应的目标:

3.5. 实验结果
3.5.1. 无条件生成
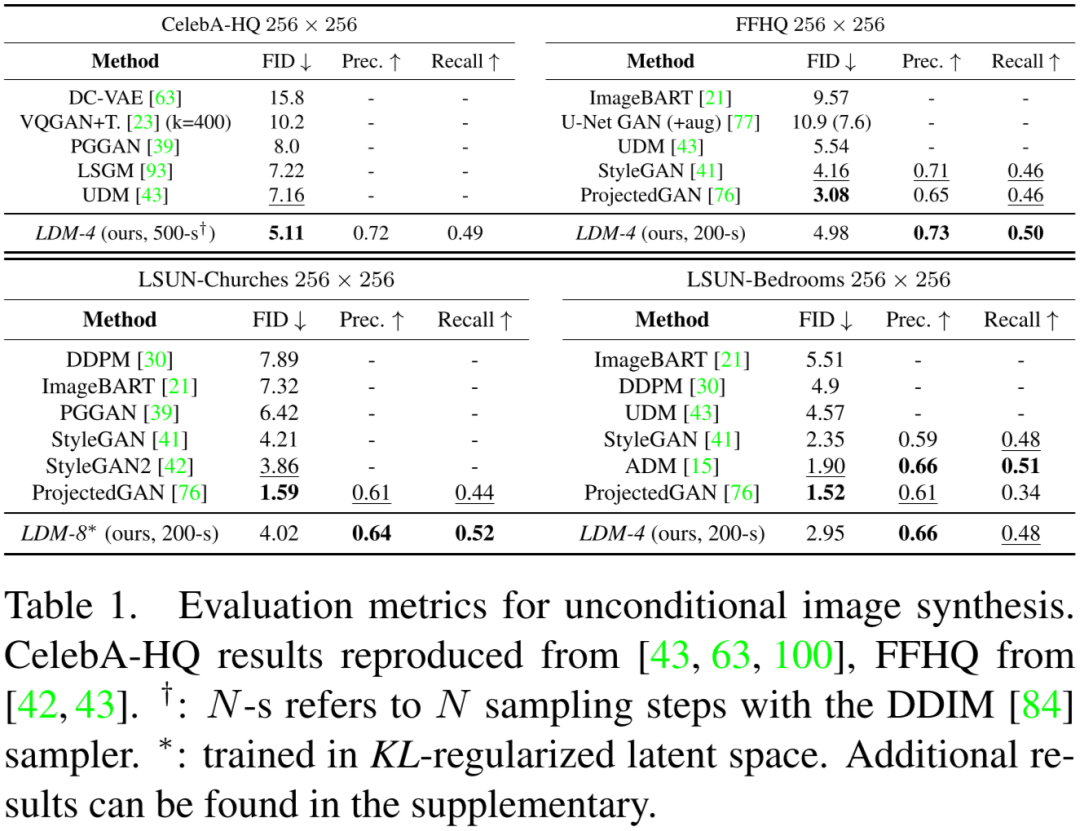
如下图 Table 1 所示,作者在多个任务上评估了 LDM-4 和 LDM-8 的无条件图像生成效果,可以看出,在大部分任务上都获得了很不错的结果:
3.5.2. 类别条件生成
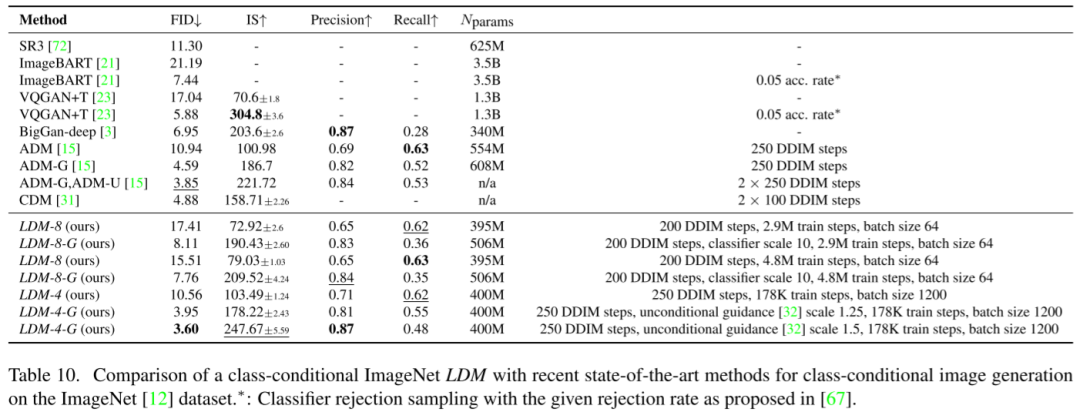
如下图 Table 3 所示,作者同样在 ImageNet 上与 ADM(Diffusion Model Beat GANs)等模型进行了类别条件图像生成对比,可见在 FID 和 IS 指标上获得了最优或次优的结果:
3.5.3. LDM-BSR
作者同样将 BSR-degradation 应用到超分模型的训练,获得了更好的效果,BSR degradation Pipeline 包含 JPEG 压缩噪声、相机传感器噪声、针对下采样的不同图像插值方法,高斯模糊核以及高斯噪声,并以随机顺序应用于图像(具体可参考代码 https://github.com/CompVis/stable-diffusion/blob/main/ldm/modules/image_degradation/bsrgan_light.py),最终获得了不错的效果:

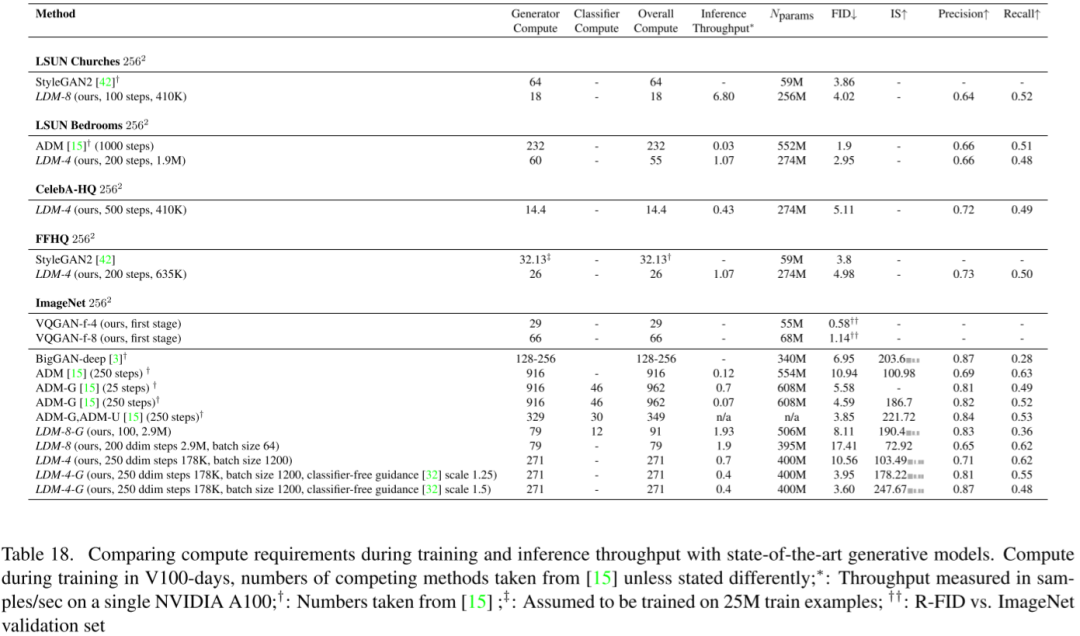
3.6. 计算需求
作者与其他模型对比了训练和推理的计算需求和相关的参数量、FID、IS 等指标,提出的模型在更小的代价下获得更好的效果:
四、SDXL
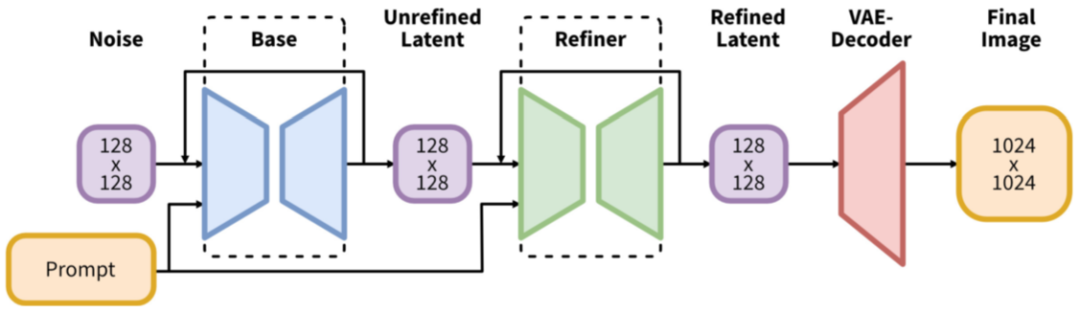
4.1. SDXL 模型概览
如下图所示,SDXL 相比 SD 主要的修改包括(模型总共 2.6B 参数量,其中 text encoder 817M 参数量):
增加一个 Refiner 模型,用于对图像进一步地精细化
使用 CLIP ViT-L 和 OpenCLIP ViT-bigG 两个 text encoder
基于 OpenCLIP 的 text embedding 增加了一个 pooled text embedding
4.2 微条件(Micro-Conditioning)
4.2.1. 以图像大小作为条件
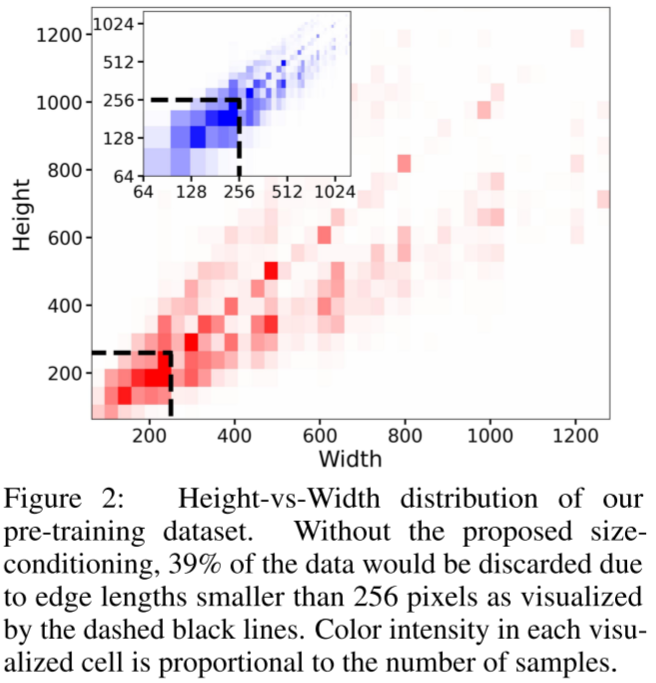
在 SD 的训练范式中有个明显的缺陷,对图像大小有最小长宽的要求。针对这个问题有两种方案:
丢弃分辨率过小的图像(例如,SD 1.4/1.5 丢弃了小于 512 像素的图像)。但是这可能导致丢弃过多数据,如下图 Figure 2 所示为预训练数据集中图像的长、宽分布,如果丢弃 256x256 分辨率的图像,将导致 39% 的数据被丢弃。
另一种方式是放大图像,但是可能会导致生成的样本比较模糊。
针对这种情况,作者提出将原始图像分辨率作用于 U-Net 模型,并提供图像的原始长和宽(csize = (h, w))作为附加条件。并使用傅里叶特征编码,然后会拼接为一个向量,把它扩充到时间步长 embedding 中并一起输入模型。
如下图所示,在推理时指定不同的长宽即可生成相应的图像,(64,64)的图像最模糊,(512, 512)的图像最清晰:

4.2.2. 以裁剪参数作为条件
此外,以前的 SD 模型存在一个比较典型的问题:生成的物体不完整,像是被裁剪过的,如下图 SD1.5 和 SD 2.1 的结果。作者猜测这可能和训练阶段的随机裁剪有关,考虑到这个因素,作者将裁剪的左上坐标(top, left)作为条件输入模型,和 size 类似。如下图 Figure 4 中 SDXL 的结果,其生成结果都更加完整:

如下图 Figure 5 所示,在推理阶段也可以通过裁剪坐标来控制位置关系:

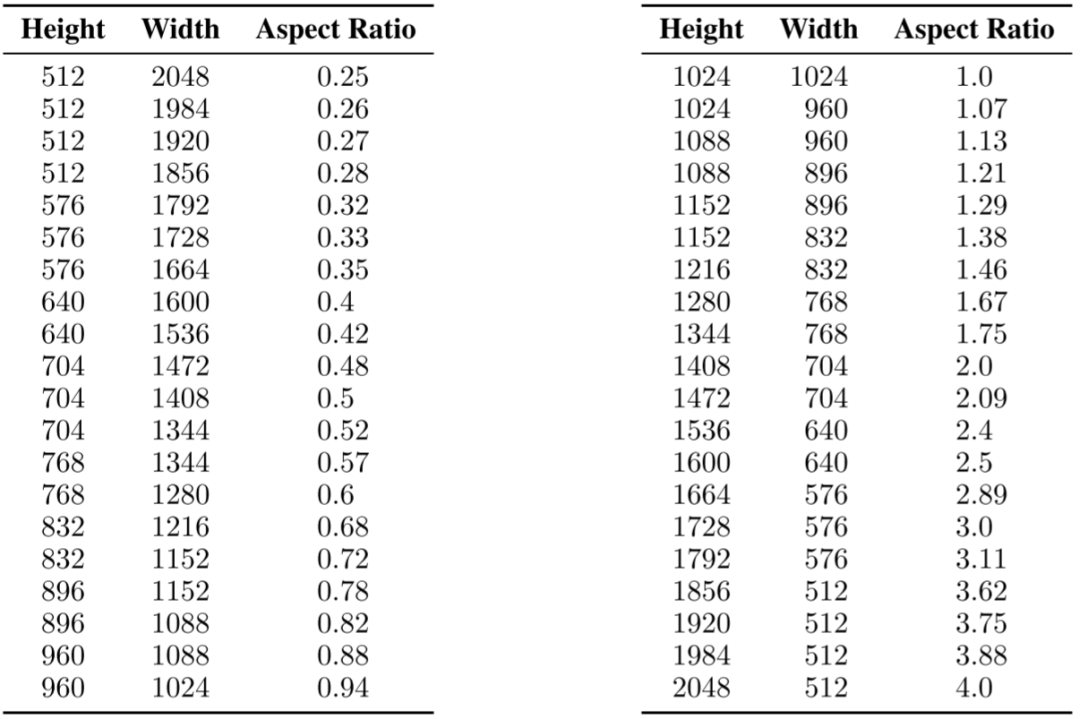
4.3 多分辨率训练
真实世界的图像会包含不同的大小和长宽比,而文本到模型生成的图像分辨率通常为 512x512 或 1024x1024,作者认为这不是一个自然的选择。受此启发,作者以不同的长宽比来微调模型:首先将数据划分为不同长宽比的桶,其中尽可能保证总像素数接近 1024x1024 个,同时以 64 的整数倍来调整高度和宽度。如下图所示为作者使用的宽度和高度。在训练过程中,每次都从同样的桶中选择一个 batch,并在不同的桶间交替。此外,和之前的 size 类似,作者会将桶的高度和宽度 (h, w)作为条件,经傅里叶特征编码后添加到时间步 embedding 中:
4.4. 训练
SDXL 模型的训练包含多个步骤:
基于内部数据集,以 256x256 分辨率预训练 6,000,000 step,batch size 为 2048。使用了 size 和 crop 条件。
继续以 512x512 分辨率训练 200,000 step。
最后使用多分辨率(近似 1024x1024)训练。
根据以往的经验,作者发现所得到的的模型有时偶尔会生成局部质量比较差的图像,为了解决这个问题,作者在同一隐空间训练了一个独立的 LDM(Refiner),该 LDM 专门用于高质量、高分辨率的数据。在推理阶段,直接基于 Base SDXL 生成的 Latent code 继续生成,并使用相同的文本条件(当然,此步骤是可选的),实验证明可以提高背景细节以及人脸的生成质量。
4.5. 实验结果
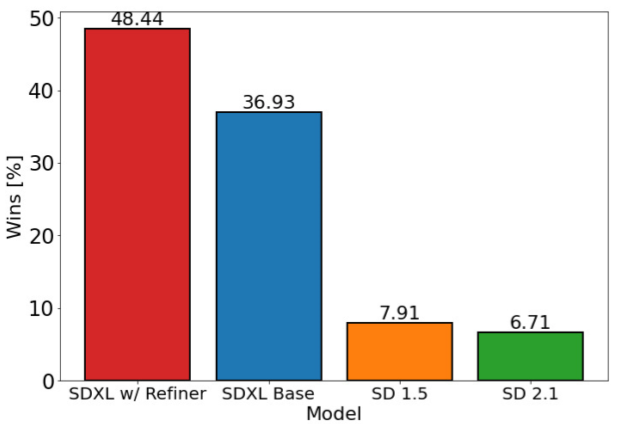
如下图所示,作者基于用户评估,最终带有 Refiner 的 SDXL 获得了最高分,并且 SDXL 结果明显优于 SD 1.5 和 SD 2.1。
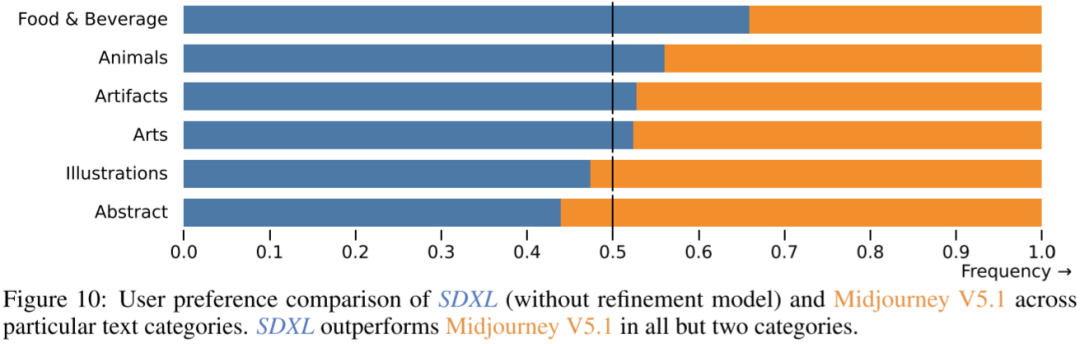
如下图 Figure 10 所示为 SDXL(没有 Refiner) 和 Midjourney 5.1 的对比结果,可见 SDXL 的结果略胜一筹:
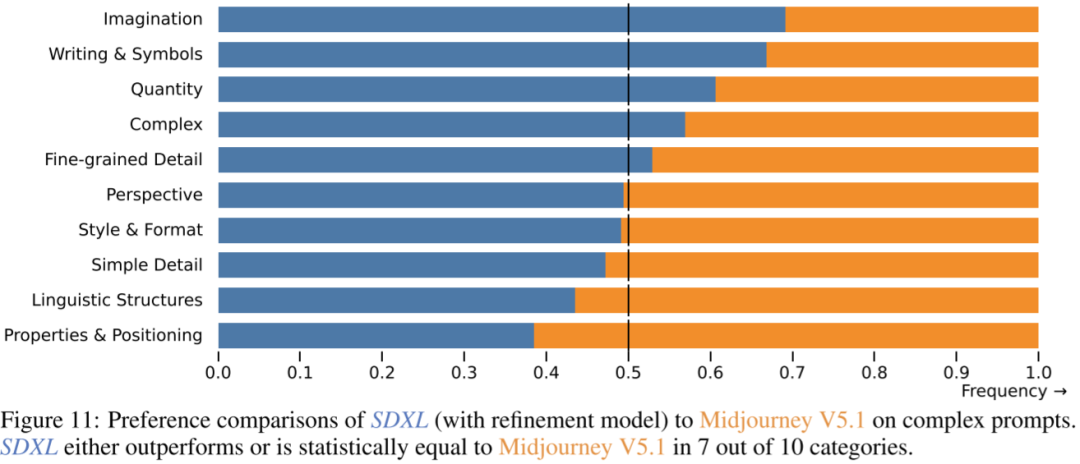
如下图 Figure 11 所示为 SDXL(带有 Refiner) 和 Midjourney 5.1 的对比结果,可见 SDXL 的结果同样略胜一筹:
五、SDXL-Turbo
5.1. SDXL-Turbo 方法
SDXL-Turbo 在模型上没有什么修改,主要是引入蒸馏技术,以便减少 LDM 的生成步数,提升生成速度。大致的流程为:
从 Tstudent 中采样步长 s,对于原始图像 x0 进行 s 步的前向扩散过程,生成加噪图像 xs。
使用学生模型 ADD-student 对 xs 进行去噪,生成去噪图像 xθ。
基于原始图像 x0 和去噪图像 xθ 计算对抗损失(adversarial loss)。
从 Tteacher 中采样步长 t,对去噪后的图像 xθ 进行 t 步的前向扩散过程,生成 xθ,t。
使用教师模型 DM-student 对 xθ,t 进行去噪,生成去噪图像 xψ。
基于学生模型去噪图像 xθ 和教师模型去噪图像 xψ 计算蒸馏损失(distillation)。
根据损失进行反向传播(注意,教师模型不更新,因此会 stop 梯度)。
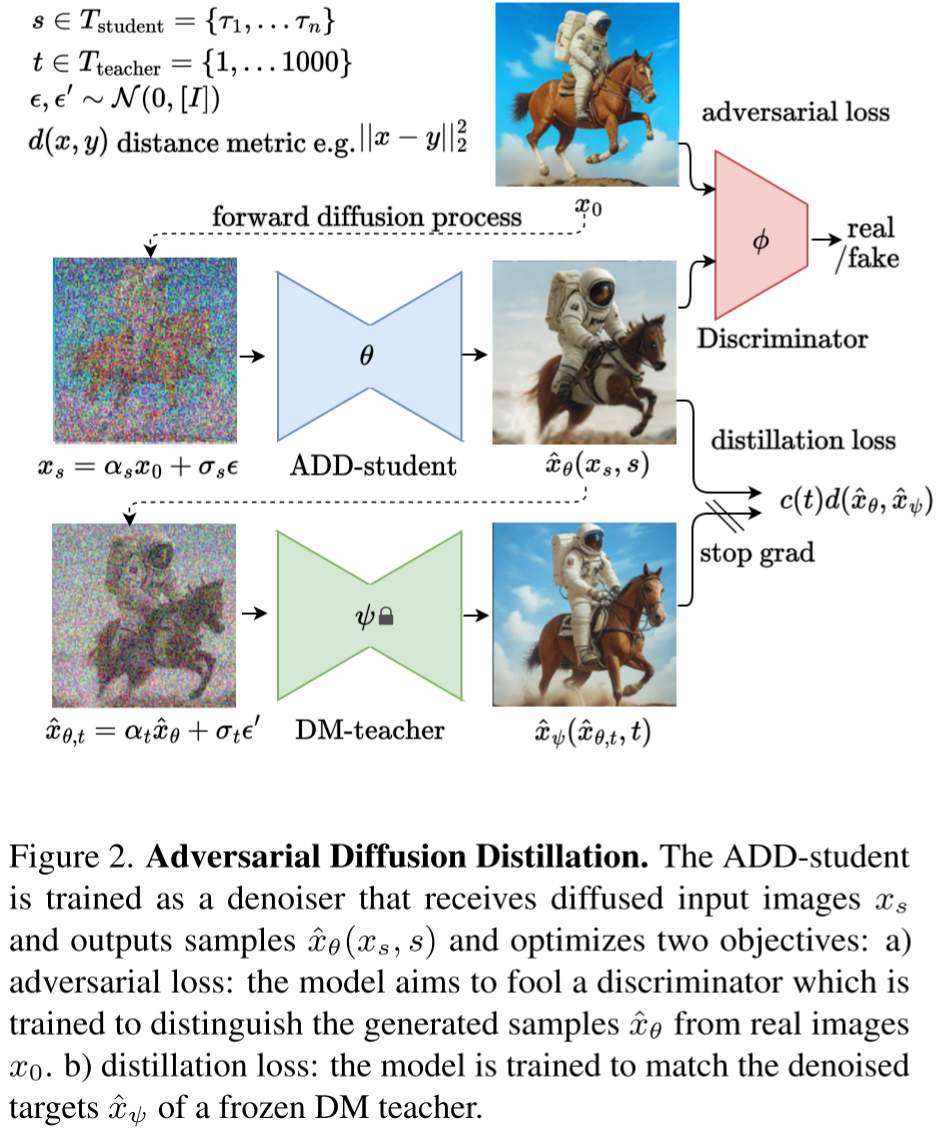
需要说明的是,通常 ADD-student 模型需要预训练过程,然后再蒸馏。此外,Tstudent 的 N 比较小,作者设置为 4,而 Tteacher 的 N 比较大,为 1000。也就是学生模型可能只加噪 1,2,3,4 步,而教师模型可能加噪 1-1000 步。
此外,作者在训练中还用了其他技巧,比如使用了 zero-terminal SNR;教师模型不是直接作用于原始图像 x0,而是作用于学生模型恢复出的图像 xθ,否则会出现 OOD(out of distribution) 问题;作者还应用了 Score Distillation Loss,并且与最新的 noise-free score distillation 进行了对比。
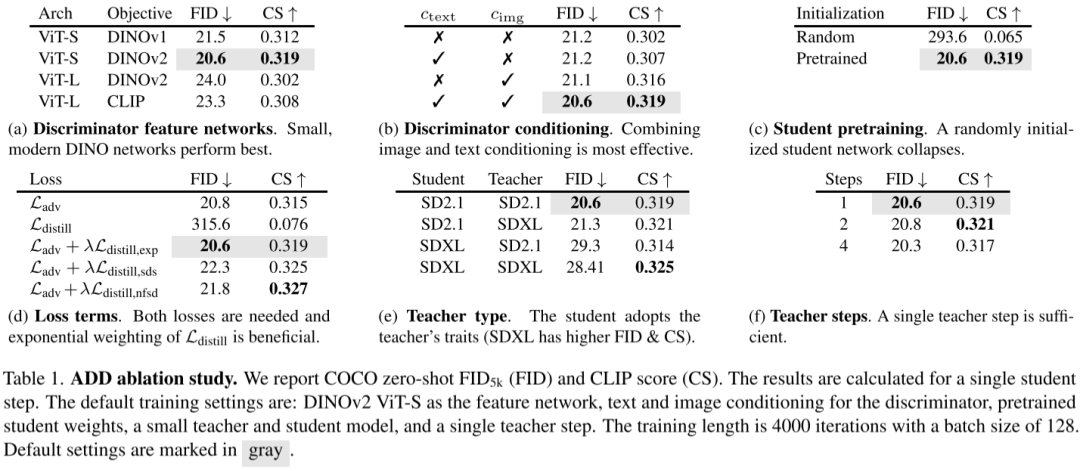
5.2. 消融实验
作者进行了一系列的消融实验:
(a) 在判别器(Discriminator)中使用不同模型的结果。
(b) 在判别器中使用不同条件的效果,可见使用文本+图像条件获得最好结果。
© 学生模型使用预训练的结果,使用预训练效果明显提升。
(d) 不同损失的影响。
(e) 不同学生模型和教师模型的影响。
(f) 教师 step 的影响。
5.3. 实验结果
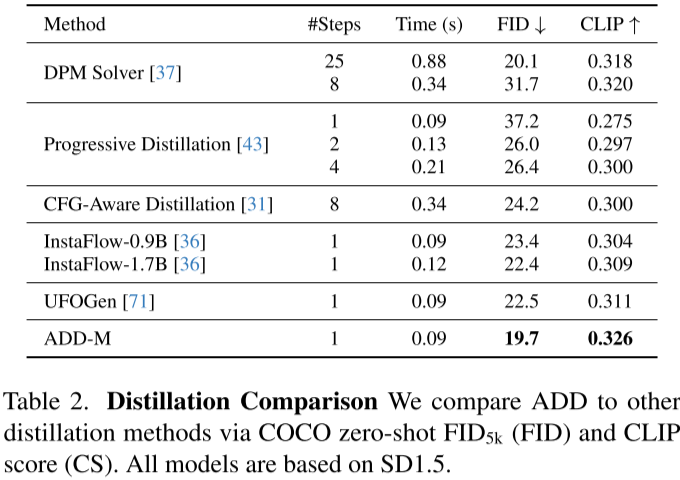
如下图所示,作者与不同的蒸馏方案进行了对比,本文提出的方案只需一步就能获得最优的 FID 和 CLIP 分数:
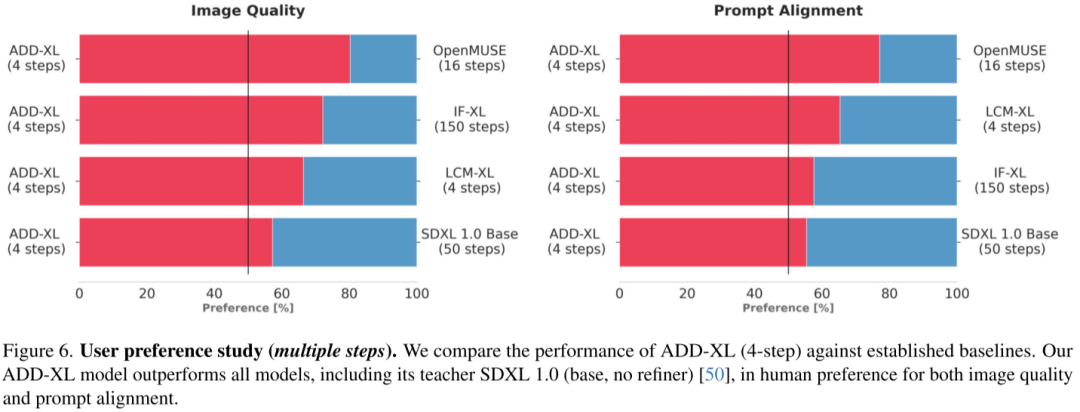
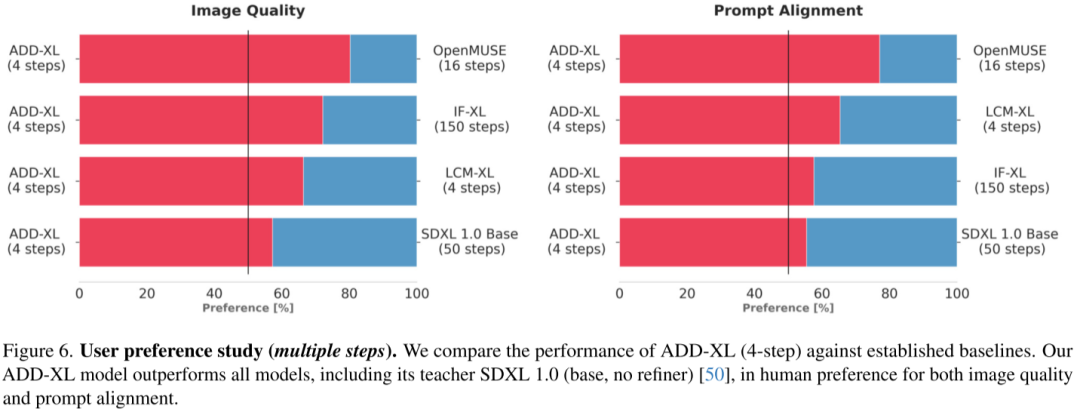
如下图 Figure 5 和 Figure 6 所示为性能和速度的对比,ADD-XL 1 步比 LCM-XL 4 步的效果更好,同时 ADD-XL 4 步可以超越 SDXL 50 步的结果,总之,ADD-XL 获得了最佳性能:
六、演进
6.1. Latent Diffusion
Stable Diffusion 之前的版本,对应的正是论文的开源版本,位于代码库 High-Resolution Image Synthesis with Latent Diffusion Models 中。
该版本发布于 2022 年 4 月,主要包含三个模型:
文生图模型:基于 LAION-400M 数据集训练,包含 1.45B 参数。
图像修复模型:指定区域进行擦除。
基于 ImageNet 的类别生成模型:在 ImageNet 上训练,指定类别条件生成,获得了 3.6 的 FID 分数。使用了 Classifier Free Guidance 技术。
代码实现参考了 OpenAI 的 Diffusion Models Beat GANs 代码实现。
6.2. Stable Diffusion V1
Stable Diffusion 的第一个版本,特指文生图扩散模型,位于代码库 GitHub - CompVis/stable-diffusion: A latent text-to-image diffusion model 中。
该版本发布于 2022 年 8 月,该模型包含 2 个子模型:
AutoEncoder 模型:U-Net,8 倍下采样,包含 860M 参数。
Text Encoder 模型:使用 CLIP ViT-L/14 中的 Text encoder。
模型首先在 256x256 的分辨率下训练,然后在 512x512 的分辨率下微调。总共包含 4 个子版本:
sd-v1-1.ckpt:
在 LAION-2B-en 数据集上以 256x256 分辨率训练 237k step。
在 LAION-high-resolution(LAION-5B 中超过 1024x1024 分辨率的 170M 样本)上以 512x512 分辨率继续训练 194k step。
sd-v1-2.ckpt:
复用 sd-v1-1.ckpt,在 LAION-aesthetics v2 5+(LAION-2B-en 中美观度分数大于 5.0 的子集) 上以 512x512 分辨率继续训练 515k step。
sd-v1-3.ckpt:
复用 sd-v1-2.ckpt,在 LAION-aesthetics v2 5+ 上以 512x512 分辨率继续训练 195k step,使用了 Classifier Free Guidance 技术,以 10% 概率删除文本条件。
sd-v1-4.ckpt:
复用 sd-v1-2.ckpt,在 LAION-aesthetics v2 5+ 上以 512x512 分辨率继续训练 225k step,使用了 Classifier Free Guidance 技术,以 10% 概率删除文本条件。
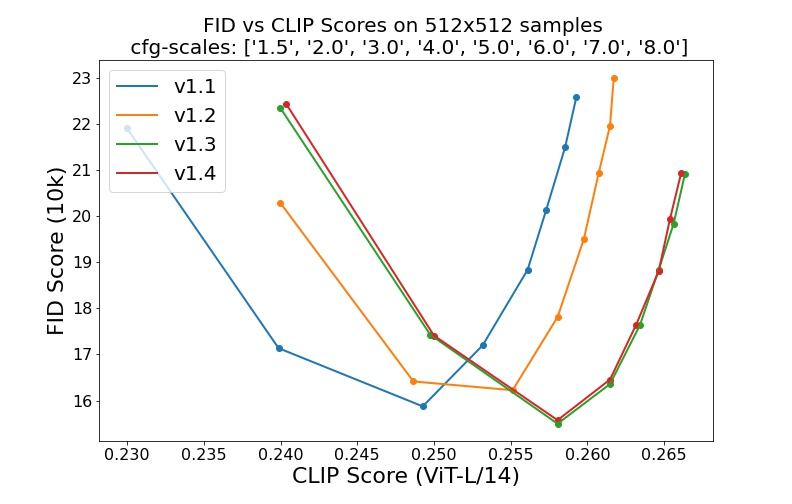
对应的 FID 和 CLIP 分数如下图所示,可见从 v1-1 到 v1-2,再到 v1-3 提升都很明显,v1-3 和 v1-4 差距不大:
6.3. Stable Diffusion V1.5
Stable Diffusion 的 V1.5 版本,由 runway 发布,位于代码库 GitHub - runwayml/stable-diffusion: Latent Text-to-Image Diffusion 中。
该版本发布于 2022 年 10 月,主要包含两个模型:
sd-v1-5.ckpt:
复用 sd-v1-2.ckpt,在 LAION-aesthetics v2 5+ 上以 512x512 分辨率继续训练 595k step,使用了 Classifier Free Guidance 技术,以 10% 概率删除文本条件。
sd-v1-5-inpainting.ckpt:
复用 sd-v1-5.ckpt,在 LAION-aesthetics v2 5+ 上以 512x512 分辨率以 inpainting 训练了 440k step,使用 Classifier Free Guidance 技术,以 10% 概率删除文本条件。在 U-Net 的输入中额外加了 5 个 channel,4 个用于 masked 的图像,1 个用于 mask 本身。
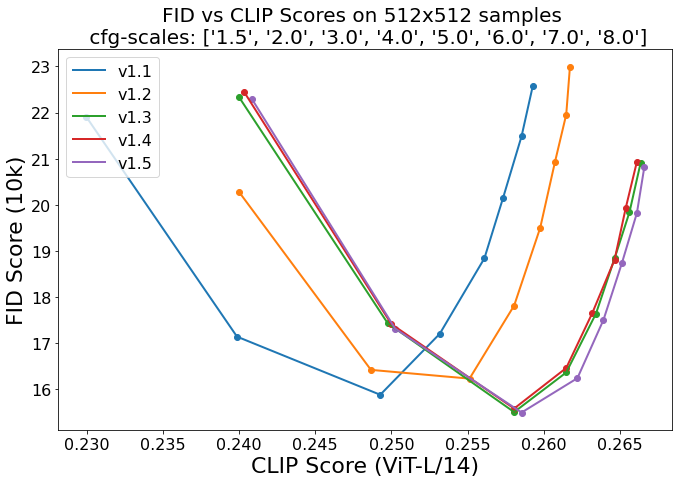
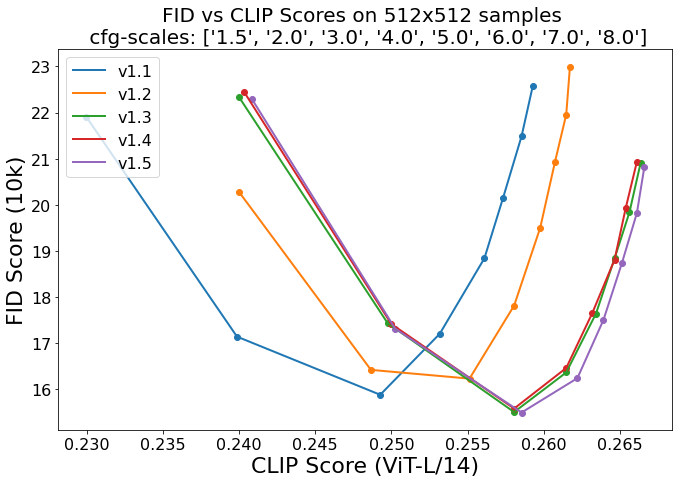
对应的 FID 和 CLIP 分数如下图所示,可以看出,v1.5 相比 v1.4 的提升也不是很明显:
6.3. Stable Diffusion V1.5
Stable Diffusion 的 V1.5 版本,由 runway 发布,位于代码库 GitHub - runwayml/stable-diffusion: Latent Text-to-Image Diffusion 中。
该版本发布于 2022 年 10 月,主要包含两个模型:
sd-v1-5.ckpt:
复用 sd-v1-2.ckpt,在 LAION-aesthetics v2 5+ 上以 512x512 分辨率继续训练 595k step,使用了 Classifier Free Guidance 技术,以 10% 概率删除文本条件。
sd-v1-5-inpainting.ckpt:
复用 sd-v1-5.ckpt,在 LAION-aesthetics v2 5+ 上以 512x512 分辨率以 inpainting 训练了 440k step,使用 Classifier Free Guidance 技术,以 10% 概率删除文本条件。在 U-Net 的输入中额外加了 5 个 channel,4 个用于 masked 的图像,1 个用于 mask 本身。
对应的 FID 和 CLIP 分数如下图所示,可以看出,v1.5 相比 v1.4 的提升也不是很明显:
如下图所示为图像修复的示例:
6.3. Stable Diffusion V2
Stable Diffusion 的 V2 版本,由 Stability-AI 发布,位于代码库 GitHub - Stability-AI/stablediffusion: High-Resolution Image Synthesis with Latent Diffusion Models 中。
V2 包含三个子版本,分别为 v2.0,v2.1 和 Stable UnCLIP 2.1:
v2.0:
发布于 2022 年 11 月,U-Net 模型和 V1.5 相同,Text encoder 模型换成了 OpenCLIP-ViT/H 中的 text encoder。
SD 2.0-base:分别率为 512x512
SD 2.0-v:基于 2.0-base 微调,分辨率提升到 768x768,同时利用 [2202.00512] Progressive Distillation for Fast Sampling of Diffusion Models 提出的技术大幅降低 Diffusion 的步数。
发布了一个文本引导的 4 倍超分模型。
基于 2.0-base 微调了一个深度信息引导的生成模型。
基于 2.0-base 微调了一个文本信息引导的修复模型。
v2.1:
发布于 2022 年 12 月,模型结构和参数量都和 v2.0 相同。并在 v2.0 的基础上使用 LAION 5B 数据集(较低的 NSFW 过滤约束)微调。同样包含 512x512 分辨率的 v2.1-base 和 768x768 分辨率的 v2.1-v。
Stable UnCLIP 2.1:
发布于 2023 年 3 月,基于 v2.1-v(768x768 分辨率) 微调,参考 OpenAI 的 DALL-E 2(也就是 UnCLIP),可以更好的实现和其他模型的联合,同样提供基于 CLIP ViT-L 的 Stable unCLIP-L 和基于 CLIP ViT-H 的 Stable unCLIP-H。
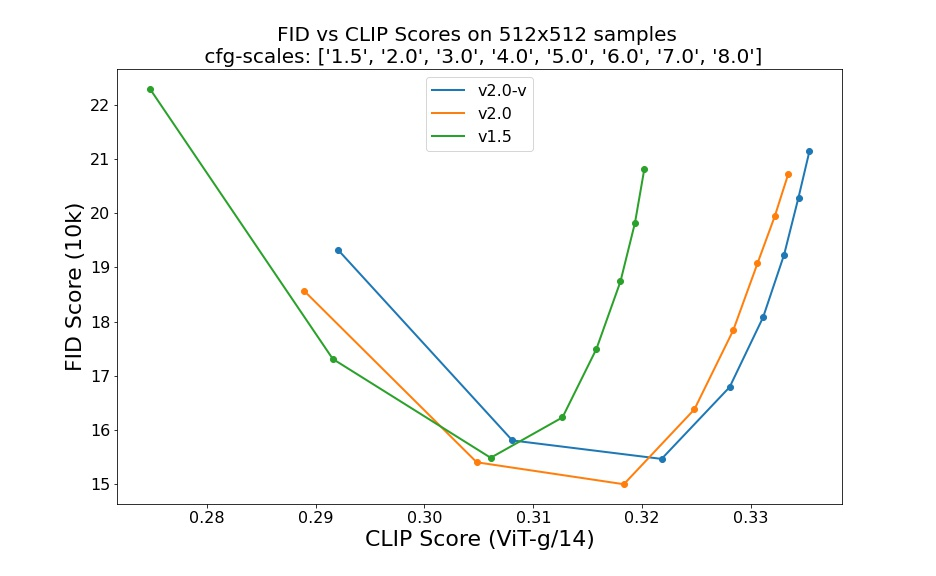
如下图所示为 v2.0 和 v2.0-v 与 v1.5 的对比,可见其都有明显提升:
6.4. Stable Diffusion XL
Stable Diffusion 的 XL 版本,由 Stability-AI 发布,位于代码库 Generative Models by Stability AI。
该版本发布于 2023 年 06 月,主要包含两个模型:
SDXL-base-0.9:基于多尺度分辨率训练,最大分辨率 1024x1024,包含两个 Text encoder,分别为 OpenCLIP-ViT/G 和 CLIP-ViT/L。
SDXL-refiner-0.9:用来生成更高质量的图像,不应直接使用,此外文本条件只使用 OpenCLIP 中的 Text encoder。
2023 年 07 月发布 1.0 版本,同样对应两个模型:
SDXL-base-1.0:基于 SDXL-base-0.9 改进。
SDXL-refiner-1.0:基于 SDXL-refiner-0.9 改进。
2023 年 11 月发表 SDXL-Trubo 版本,也就是优化加速的版本。