文章目录
- 一、优先级队列
- 1.概念
- 二、优先级队列的模拟
- 1.堆的概念
- 2.堆的存储方式
- 3.堆的创建
- 1、堆向下调整
- 2、堆的创建代码实现
- 3、建堆的时间复杂度
- 2.堆的插入与删除
- 1、堆的插入
- 2、堆的删除
- 3、完整的堆代码
- 4、练习
- 一、PriorityQueue常用接口介绍
- 1.PriorityQueue的特性
- 2.PriorityQueue的源码
- 1、成员变量
- 2、构造方法
- 3、PriorityQueue的部分源码
- 插入源码(offer)
- 扩容源码(grow)
- 最小k个数
- 3.堆的应用
- 1、堆排序
一、优先级队列
1.概念
队列是一种先进先出(FIFO)的数据结构,但有些情况下,操作的数据可能带有优先级,一般出队列时,可能需要优先级高的元素先出队列,该中场景下,使用队列显然不合适,数据结构应该提供两个最基本的操作,一个是返回最高优先级对象,一个是添加新的对象。这种数据结构就是优先级队列(Priority Queue)。
二、优先级队列的模拟
JDK1.8中的PriorityQueue底层使用了堆这种数据结构,而堆实际就是在完全二叉树的基础上进行了一些调整。
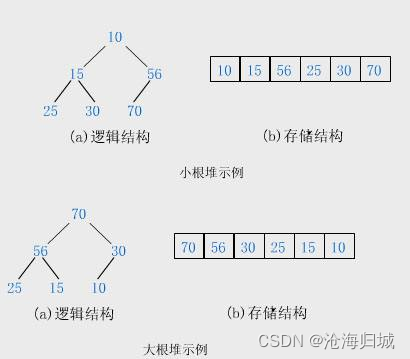
1.堆的概念
如果有一个关键码的集合K = {k0,k1, k2,…,kn-1},把它的所有元素按完全二叉树的顺序存储方式存储 在一个一维数组中,并满足:Ki <= K2i+1 且 Ki<= K2i+2 (Ki >= K2i+1 且 Ki >= K2i+2) i = 0,1,2…,则称为 小堆(或大堆)。将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。
堆的性质:
1.堆中某个节点的值总是不大于或不小于其父节点的值。
2.堆总是一棵完全二叉树。
2.堆的存储方式
从堆的概念可知,堆是一棵完全二叉树,因此可以将层序遍历结果,用顺序的方式来高效存储,
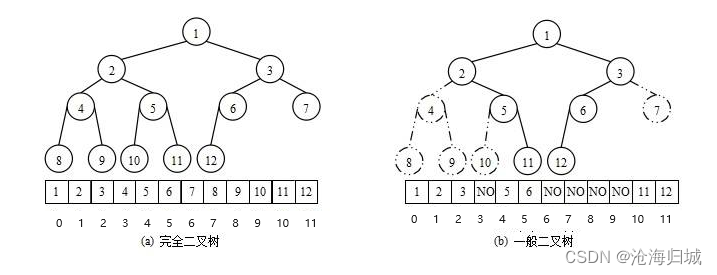
注意:对于非完全二叉树,则不适合使用顺序方式(数组)进行存储,因为为了能够还原二叉树,空间中必须要存储空节点,就会导致空间利用率比较低。
将元素存储到数组中后,可以根据二叉树的性质对树进行还原。假设i为节点在数组中的下标,则有:
如果i为0,则i表示的节点为根节点,否则i节点的双亲节点为 (i - 1)/2
如果2 * i + 1 小于节点个数,则节点i的左孩子下标为2 * i + 1,否则没有左孩子
如果2 * i + 2 小于节点个数,则节点i的右孩子下标为2 * i + 2,否则没有右孩子
3.堆的创建
1、堆向下调整
对于集合{ 27,15,19,18,28,34,65,49,25,37 }中的数据,如果将其创建成大堆呢?
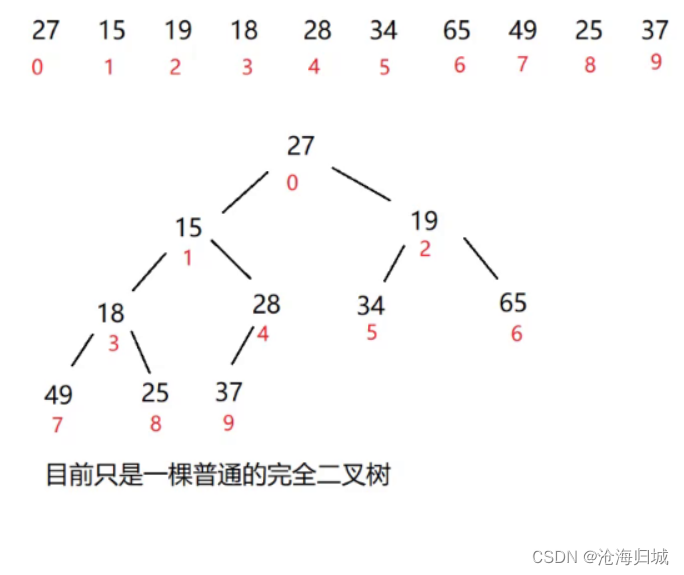
如何调整大堆?
找左右孩子的最大值,让最大值和根比较,如果孩子的最大值大,就交换孩子最大节点和根节点。
下面调整了下标为4,9的,4的左右孩子最大值为37,而37比根大,就交换。
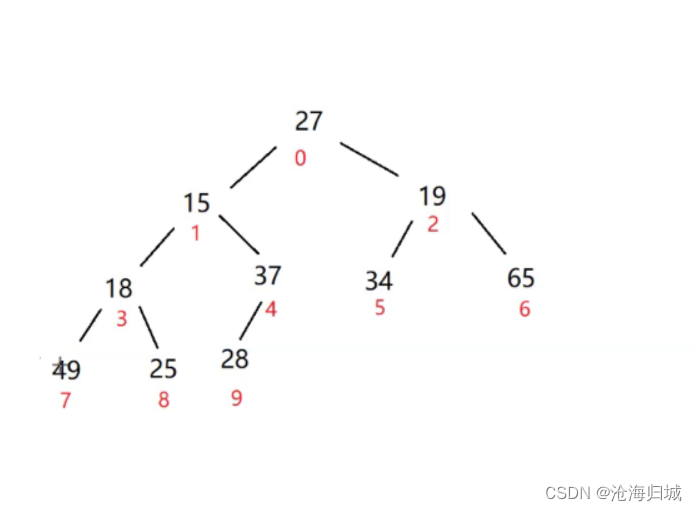
接下来看刚刚看过根下标-1的子树:3,7,8
左右孩子最大值为49,与根比较,49较大交换。
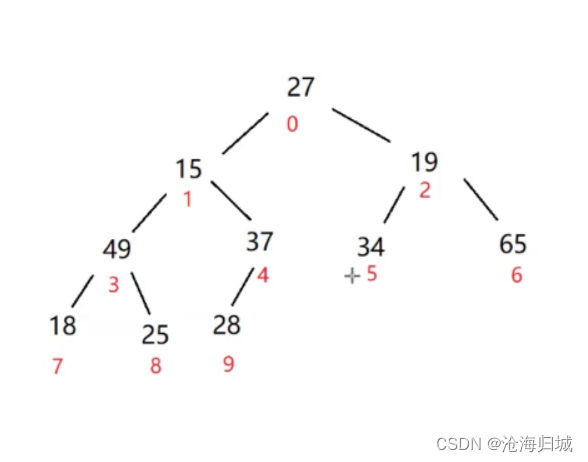
接的看下标为2的子树:2,5,6
左右孩子的最大值为65,与根比较,65较大,交换
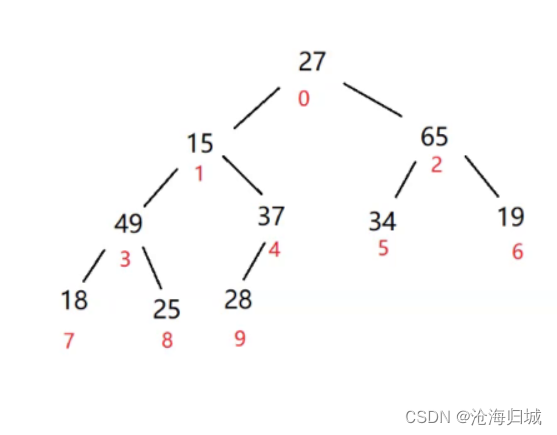
接下来看下标为1的子树:1,3,4
左右孩子的最大值为49,与根比较,49较大,交换
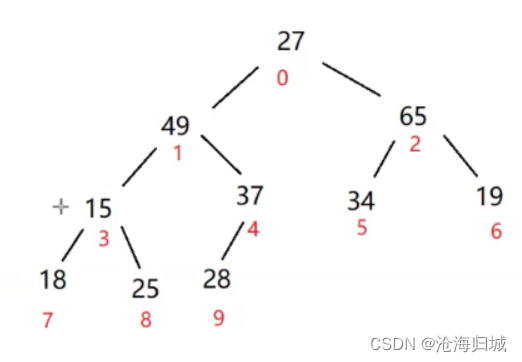
注意:此时49与15交换后,下标为3,7,8不符合大堆了,就需要调整
左右孩子最大值为25,与根的15比较,25较大交换。
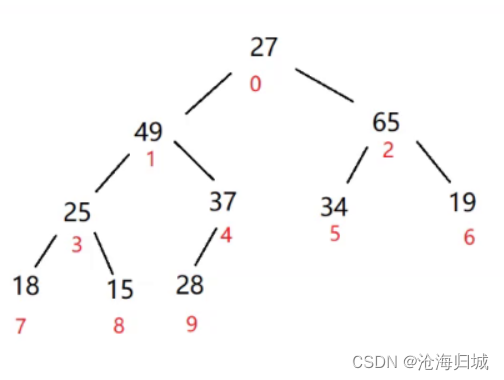
接的看下标为:0,1,2的子树
65和27交换。
后再向下调整看下标为2,5,6的子树
27与34交换
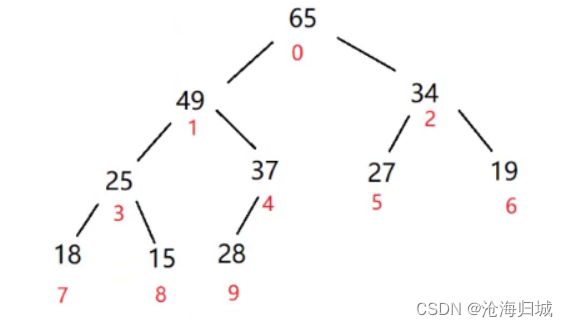
总结一下调整的过程:
1.从最后一棵子树开始调整的
2.找到左右孩子的最大值和根节点进行比较,如果比根节点大,那么就交换
3.如果能够知道子树的根节点下标,那么下一棵子树就是当前根节点下标-1
4.一直调整到0下标这棵树停止
问题:
1.每棵子树调整的时候结束的位置怎么定?
如果算到孩子节点下标大于等于节点的个数就意味着结束了
2.最后一棵子树的根节点下标怎么定?
可以通过最后孩子下标推出根节点下标:
最后根节点下标为:(i-1)/2
i = len -1
向下调整的一次时间复杂度为:log2N
2、堆的创建代码实现
package demo1;public class TestHeap {public int [] elem;public int usedSize; //记录当前堆当中有效数据个数public TestHeap(){this.elem = new int[10];}//初始化elem数组的public void initElem(int [] array){for(int i = 0;i<array.length;i++){elem[i] =array[i];usedSize++;}}//创建大根堆的代码public void createHeap(){for(int parent = (usedSize-1-1)/2;parent>=0;parent--){//向下调整siftDown(parent,usedSize);}}public void siftDown(int parent,int len){int child = 2*parent+1;while(child<len){//左孩子和右孩子比较大小 如果右孩子的值大 那么child就取右孩子位置if(child+1<len&&elem[child]<elem[child+1]){child = child+1;}if(elem[child]>elem[parent]){int temp = elem[parent];elem[parent] = elem[child];elem[child] =temp;parent = child;child = parent*2+1;}else {break;}}}
}3、建堆的时间复杂度
因为堆是完全二叉树,而满二叉树也是完全二叉树,此处为了简化使用满二叉树来证明(时间复杂度本来看的就是近似值,多几个节点不影响最终结果):
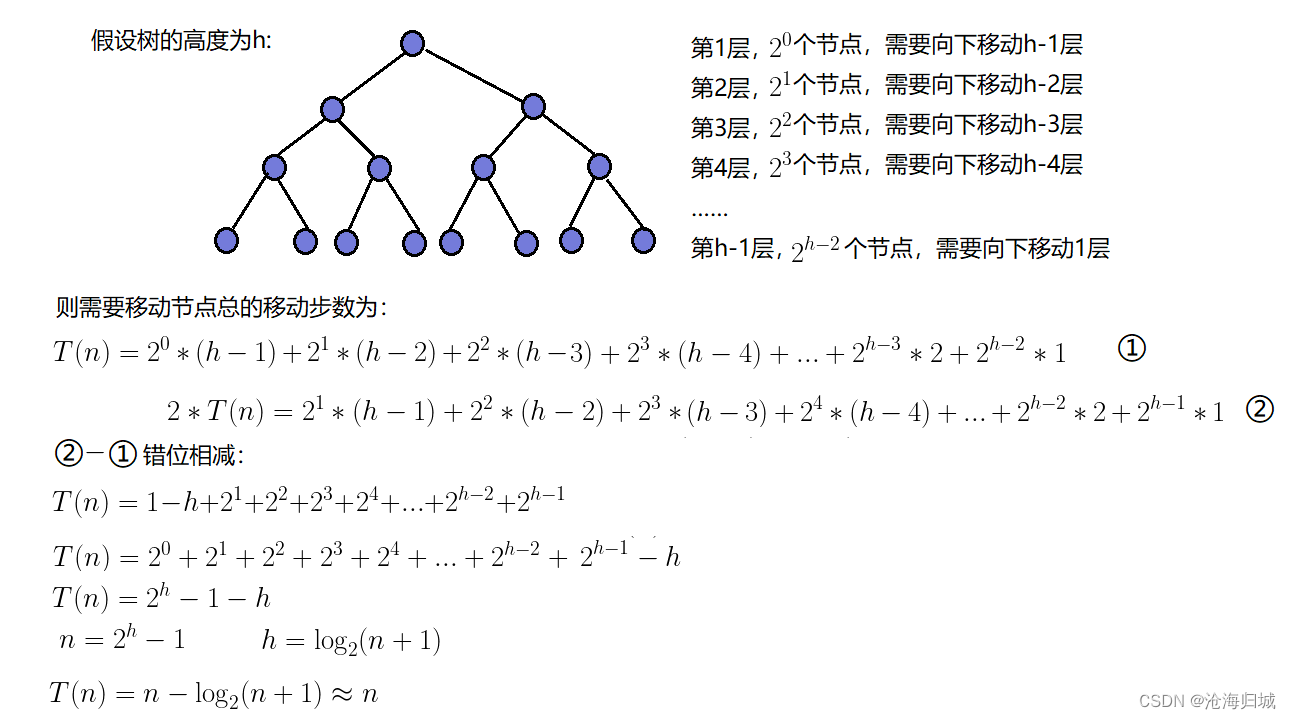
因此:建堆的时间复杂度为O(N)。
2.堆的插入与删除
1、堆的插入
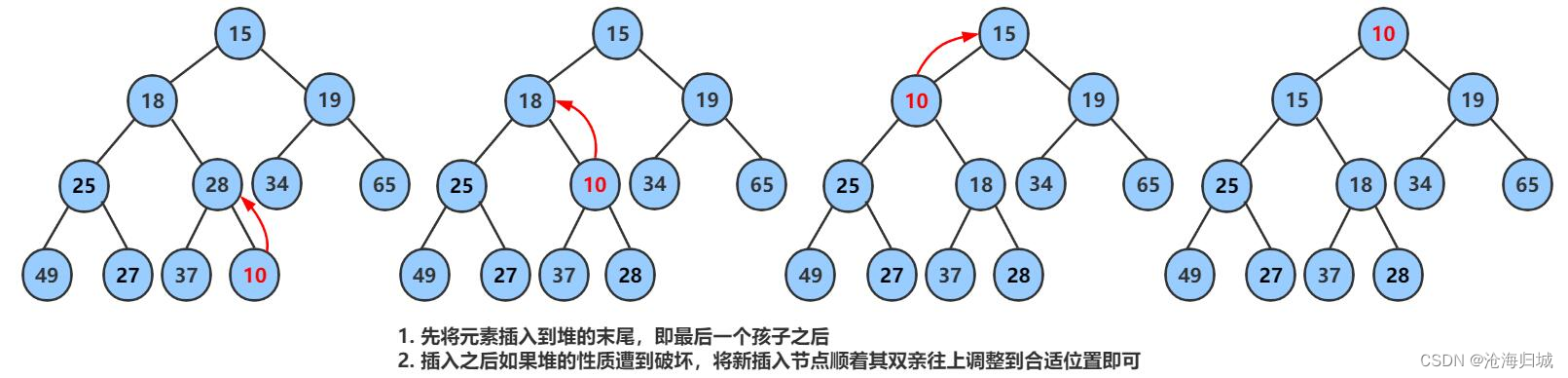
堆的插入总共需要两个步骤:
- 先将元素放入到底层空间中(注意:空间不够时需要扩容)
- 将最后新插入的节点向上调整,直到满足堆的性质
插入代码实现:
public void shiftUp(int child){int parent = (child-1)/2;while(parent>=0){if(elem[parent]<elem[child]){int temp = elem[parent];elem[parent] = elem[child];elem[child] =temp;}child = parent;parent = (child-1)/2;}}public void push(int val){if(isFull()){elem = Arrays.copyOf(elem,elem.length*2);}elem[usedSize] =val;shiftUp(usedSize);usedSize++;}public boolean isFull(){return usedSize==elem.length;}问题:
是否可以采用向上调整方式建堆?
时间复杂度会比较大(NLog2n)
2、堆的删除
注意:堆的删除一定删除的是堆顶元素。具体如下:
- 将堆顶元素对堆中最后一个元素交换
- 将堆中有效数据个数减少一个
- 对堆顶元素进行向下调整

删除代码实现:
public void swap(int i ,int j){int temp = elem[i];elem[i] = elem[j];elem[j] =temp;}public boolean empty(){return usedSize==0;}public int pop(){if(empty()){return -1;}int oldVal = elem[0];swap(0,usedSize-1);usedSize--;siftDown(0,usedSize);return oldVal;}3、完整的堆代码
package demo1;import com.sun.scenario.effect.impl.prism.ps.PPSBlend_ADDPeer;import java.util.Arrays;public class TestHeap {public int [] elem;public int usedSize; //记录当前堆当中有效数据个数public TestHeap(){this.elem = new int[10];}//初始化elem数组的public void initElem(int [] array){for(int i = 0;i<array.length;i++){elem[i] =array[i];usedSize++;}}//创建大根堆的代码public void createHeap(){for(int parent = (usedSize-1-1)/2;parent>=0;parent--){siftDown(parent,usedSize);//向下调整}}public void siftDown(int parent,int len){int child = 2*parent+1;while(child<len){//左孩子和右孩子比较大小 如果右孩子的值大 那么child就取右孩子位置if(child+1<len&&elem[child]<elem[child+1]){child = child+1;}if(elem[child]>elem[parent]){int temp = elem[parent];elem[parent] = elem[child];elem[child] =temp;parent = child;child = parent*2+1;}else {break;}}}public void shiftUp(int child){int parent = (child-1)/2;while(parent>=0){if(elem[parent]<elem[child]){int temp = elem[parent];elem[parent] = elem[child];elem[child] =temp;child = parent;parent = (child-1)/2;}else{break;}}}public void push(int val){if(isFull()){elem = Arrays.copyOf(elem,elem.length*2);}elem[usedSize] =val;shiftUp(usedSize);usedSize++;}public boolean isFull(){return usedSize==elem.length;}public void swap(int i ,int j){int temp = elem[i];elem[i] = elem[j];elem[j] =temp;}public boolean empty(){return usedSize==0;}public int pop(){if(empty()){return -1;}int oldVal = elem[0];swap(0,usedSize-1);usedSize--;siftDown(0,usedSize);return oldVal;}}测试代码:
package demo1;public class Test {public static void main(String[] args) {TestHeap testHeap = new TestHeap();int [] arr = {65,49,34,25,37,27,19,18,15,28};testHeap.initElem(arr);testHeap.createHeap();testHeap.push(80);System.out.println(testHeap.pop());System.out.println(testHeap.pop());System.out.println();}
}
4、练习
1.下列关键字序列为堆的是:()
A: 100,60,70,50,32,65
B: 60,70,65,50,32,100
C: 65,100,70,32,50,60
D: 70,65,100,32,50,60
E: 32,50,100,70,65,60
F: 50,100,70,65,60,32
2.已知小根堆为8,15,10,21,34,16,12,删除关键字8之后需重建堆,在此过程中,关键字之间的比较次数是()
A: 1
B: 2
C: 3
D: 4
3.最小堆[0,3,2,5,7,4,6,8],在删除堆顶元素0之后,其结果是()
A: [3,2,5,7,4,6,8]
B: [2,3,5,7,4,6,8]
C: [2,3,4,5,7,8,6]
D: [2,3,4,5,6,7,8]
答案:
1.A
2.C
3.C
一、PriorityQueue常用接口介绍
1.PriorityQueue的特性
- 使用时必须导入PriorityQueue所在的包,即:
import java.util.PriorityQueue;
- PriorityQueue中放置的元素必须要能够比较大小,不能插入无法比较大小的对象,否则会抛出ClassCastException异常
- 不能插入null对象,否则会抛出NullPointerException
- 没有容量限制,可以插入任意多个元素,其内部可以自动扩容
- 插入和删除元素的时间复杂度为(long2N)
- PriorityQueue底层使用了堆数据结构
- PriorityQueue默认情况下是小堆—即每次获取到的元素都是最小的元素
2.PriorityQueue的源码
1、成员变量
//默认的初始容量
private static final int DEFAULT_INITIAL_CAPACITY = 11;
//数组引用将来用来储存数据`在这里插入代码片`transient Object[] queue;
//当前队列当中的有效数据的个数
private int size = 0;
//比较器 默认为null
private final Comparator<? super E> comparator;
2、构造方法
无参数构造,默认容量是11,且没有比较器
public PriorityQueue() {this(DEFAULT_INITIAL_CAPACITY, null);}
public PriorityQueue(int initialCapacity,Comparator<? super E> comparator) {// Note: This restriction of at least one is not actually needed,// but continues for 1.5 compatibilityif (initialCapacity < 1)throw new IllegalArgumentException();this.queue = new Object[initialCapacity];this.comparator = comparator;}
public PriorityQueue(Comparator<? super E> comparator) {this(DEFAULT_INITIAL_CAPACITY, comparator);
}
3、PriorityQueue的部分源码
插入源码(offer)
public boolean offer(E e) {if (e == null)throw new NullPointerException();modCount++;int i = size;if (i >= queue.length)grow(i + 1);size = i + 1;if (i == 0)queue[0] = e;elsesiftUp(i, e);return true;}
grow是扩容方法
siftUp是向上调整方法
以下是没有传比较器的:
private void siftUp(int k, E x) {if (comparator != null)siftUpUsingComparator(k, x);elsesiftUpComparable(k, x);}private void siftUpComparable(int k, E x) {Comparable<? super E> key = (Comparable<? super E>) x;while (k > 0) {int parent = (k - 1) >>> 1;Object e = queue[parent];if (key.compareTo((E) e) >= 0)break;queue[k] = e;k = parent;}queue[k] = key;}
假设E位Integer
public int compareTo(Integer anotherInteger) {return compare(this.value, anotherInteger.value);}public static int compare(int x, int y) {return (x < y) ? -1 : ((x == y) ? 0 : 1);}
如果传的值比根节点的值大,就会传>=0的返回值从而跳出向下调整,可以得知是小根堆。
以下是传比较器的:
private void siftUp(int k, E x) {if (comparator != null)siftUpUsingComparator(k, x);elsesiftUpComparable(k, x);}private void siftUpUsingComparator(int k, E x) {while (k > 0) {int parent = (k - 1) >>> 1;Object e = queue[parent];if (comparator.compare(x, (E) e) >= 0)break;queue[k] = e;k = parent;}queue[k] = x;}
和上面类似。
传入比较器,变成大根堆。
class Imp implements Comparator<Integer> {@Overridepublic int compare(Integer o1, Integer o2) {return o2.compareTo(o1);}
}
public class Test {public static void main(String[] args) {Imp imp = new Imp();PriorityQueue<Integer> priorityQueue =new PriorityQueue<>(imp);priorityQueue.offer(10);priorityQueue.offer(5);priorityQueue.offer(6);System.out.println(priorityQueue.peek());}
扩容源码(grow)
private void grow(int minCapacity) {int oldCapacity = queue.length;// Double size if small; else grow by 50%int newCapacity = oldCapacity + ((oldCapacity < 64) ?(oldCapacity + 2) :(oldCapacity >> 1));// overflow-conscious codeif (newCapacity - MAX_ARRAY_SIZE > 0)newCapacity = hugeCapacity(minCapacity);queue = Arrays.copyOf(queue, newCapacity);}private static int hugeCapacity(int minCapacity) {if (minCapacity < 0) // overflowthrow new OutOfMemoryError();return (minCapacity > MAX_ARRAY_SIZE) ?Integer.MAX_VALUE :MAX_ARRAY_SIZE;}优先级队列的扩容说明:
如果容量小于64时,是按照oldCapacity的2倍方式扩容的
如果容量大于等于64,是按照oldCapacity的1.5倍方式扩容的
如果容量超过MAX_ARRAY_SIZE,按照MAX_ARRAY_SIZE来进行扩容
最小k个数
最小k个数
class Solution {public int[] smallestK(int[] arr, int k) {PriorityQueue<Integer> priorityQueue = new PriorityQueue<>();for(int e : arr){priorityQueue.offer(e);}int [] ret = new int [k];for(int i = 0;i<k;i++){ret[i] = priorityQueue.poll();}return ret;}
}
3.堆的应用
1、堆排序
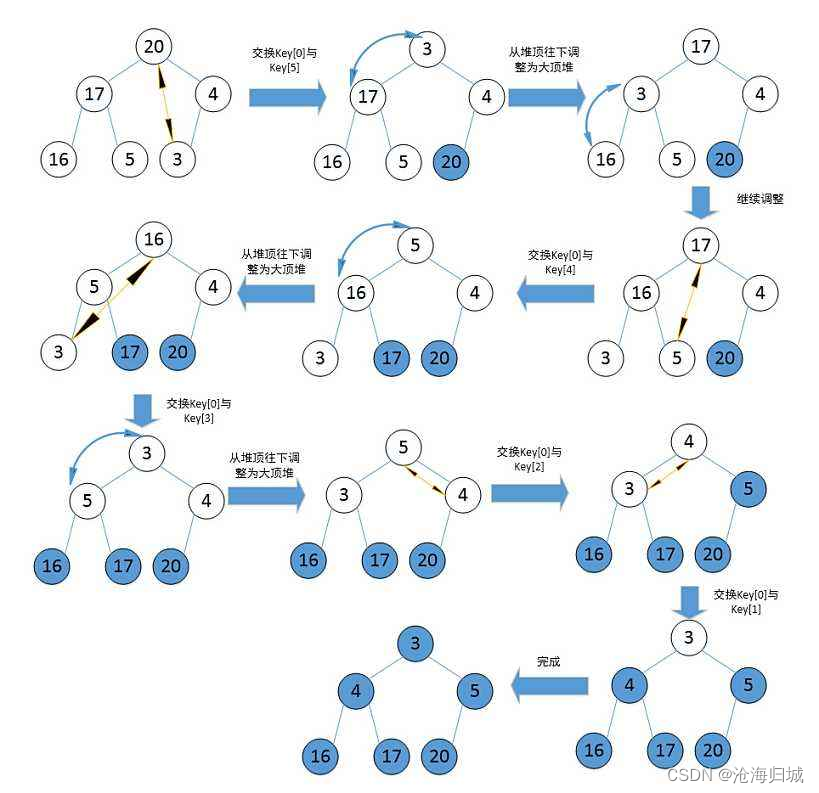
堆排序即利用堆的思想来进行排序,总共分为两个步骤:
- 建堆
升序:建大堆
降序:建小堆 - 利用堆删除思想来进行排序

![更改Linux系统(我的是centOS7)[root@localhost ~]$的字体颜色样式](https://img-blog.csdnimg.cn/direct/4f21bcc823094efea2d5d6b47ea0530c.png)