文章目录
- 关于 cohere
- 公司介绍
- 目标:构建大模型基础设施
- 产品
- 商业模式
- API 使用
- 基于 Cohere AI 实现语义搜索
关于 cohere
- PYPI : https://pypi.org/project/cohere
- 官网 : https://cohere.com
- github : https://github.com/cohere-ai/cohere-python
- 文档:https://docs.cohere.com
文章/教程
-
硅谷科技评论:Cohere,为企业提供大模型
https://mp.weixin.qq.com/s/H-FNecz6rhfVkWg_ayoKKg -
如何使用 Cohere AI 文本嵌入技术实现语义搜索
https://mp.weixin.qq.com/s/wWeYopgO3t6vyjHlA85sBQ -
每个人都能做NLP开发:cohere及开源平替测试
https://www.bilibili.com/video/BV1ov4y1U7Au/
公司介绍
Aidan Gomez(首席执行官)、Nick Frosst 和 Ivan Zhu 于 2019 年创立了 Cohere。
其中 Aidan Gomez 于 2017 年 6 月与人合著论文《Attention Is All You Need》,这个的分量大家都知道,在此不赘述。
2023 年初,YouTube 前首席财务官 Martin Kon(总裁兼首席运营官)加入团队。
目标:构建大模型基础设施
Gomes : “刚开始时,我们并不真正知道我们想要构建什么产品…我们只是专注于构建基础设施,以使用我们可以获得的任何计算在超级计算机上训练大型语言模型。很快在我们启动 Cohere 后,GPT-3 出现了,这是一个巨大的突破时刻,非常有效,并给了我们[一个指示],表明我们正在走上正确的道路。”
产品
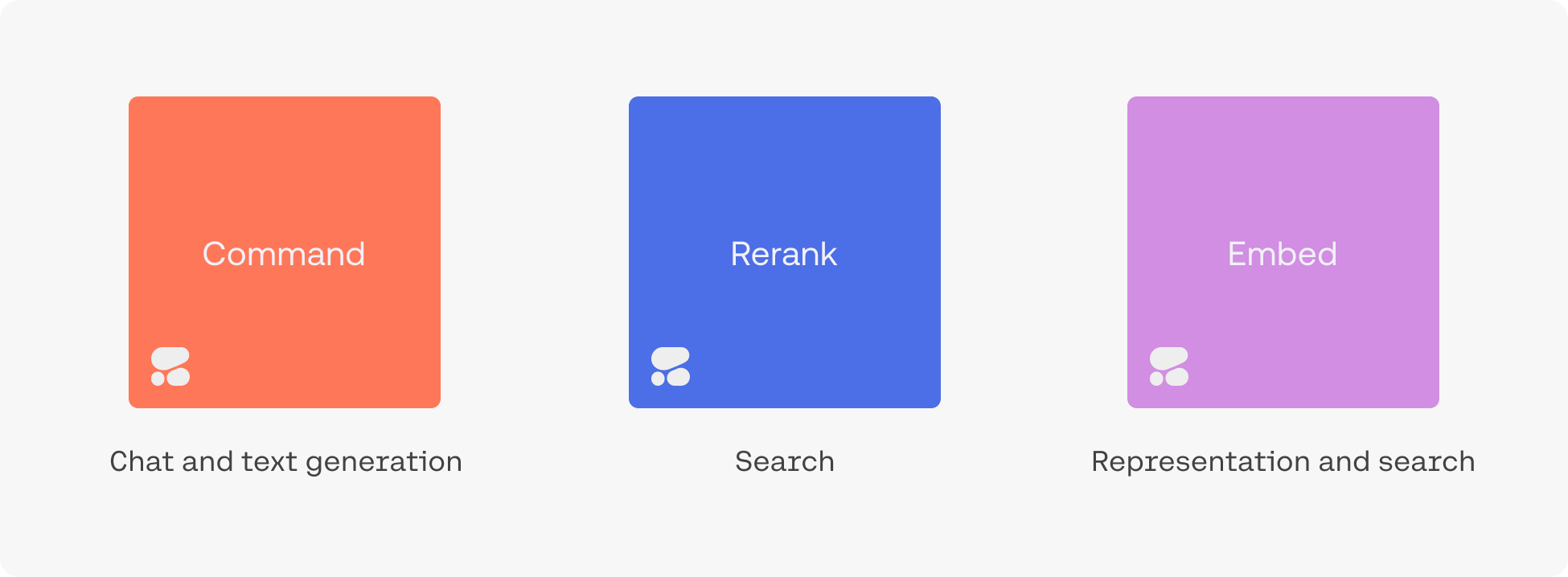
Cohere 为各种阅读和写作任务训练大型语言模型 (LLMs),例如摘要、内容创建和情感分析。
其语言模型针对三个主要用例进行了优化:
- 检索文本(retrieving text)
- Embed(嵌入)
- Semantic Search(语义搜索)
- Rerank(重新排名)
- 生成文本(generating text)
- Summarize(总结)
- Generate(生成)
- Command Model:遵循业务应用程序的用户命令
- 分类文本(classifying text)
根据您的隐私/安全要求,有多种方式可以访问Cohere:
- Cohere的API:这是最简单的选择,只需从仪表板中获取一个API键,并开始使用Cohere托管的模型。
- 云人工智能平台:此选项提供了易用性和安全性的平衡。您可以在各种云人工智能平台上访问Cohere,如Oracle的GenAI服务、AWS的Bedrock和Sagemaker平台、谷歌云和Azure的AML服务。
- 私有云部署:Cohere的模型可以在大多数虚拟私有云(VPC)环境中进行私有部署,提供增强的安全性和最高程度的定制。有关信息,请联系销售人员。

商业模式
Cohere 承担着构建每个模型的大量前期成本和持续的推理成本。
它通过基于使用量的定价来收回成本,并提供三种不同的定价等级:
- 免费:访问所有 Cohere API 端点,并限速使用,用于学习和原型设计。
- 产品:增加对所有 Coheres API 端点的访问速率限制、增强客户支持以及根据提供的数据训练自定义模型的能力。
Cohere 根据其所有 API 端点的Token数量(Token基本上是数字、字母或符号)进行收费,端点的价格各不相同,从每个Token 0.0000004 美元(嵌入)到 0.001 美元(重新排序)不等。 - 企业:专用模型实例、最高级别的支持和自定义部署选项。企业级的定价未公开。
API 使用
准备
1、安装库
pip install cohere
2、获取 秘钥
https://dashboard.cohere.ai/
基于 Cohere AI 实现语义搜索
import cohere
import numpy as np
import re
import pandas as pd
from tqdm import tqdm
from datasets import load_dataset
import umap
import altair as alt
from sklearn.metrics.pairwise import cosine_similarity
from annoy import AnnoyIndex
import warnings
warnings.filterwarnings('ignore')
pd.set_option('display.max_colwidth', None)
api_key = ''co = cohere.Client(api_key)
获取问题分类数据集
这里将使用trec数据集来演示,trec数据集由问题及其类别组成。
# 获取数据集
dataset = load_dataset("trec", split="train")# 将其导入到pandas的dataframe中,只取前1000行
df = pd.DataFrame(dataset)[:1000]# 预览数据以确保已正确加载
df.head(10)
文档嵌入
可以使用Cohere对问题文本进行嵌入。
使用Cohere库的embed函数对问题进行嵌入。生成一千个这样长度的嵌入大约需要15秒钟。
# 获取嵌入
embeds = co.embed(texts=list(df['text']),model="large",truncate="RIGHT").embeddings# 检查嵌入的维度
embeds = np.array(embeds)
embeds.shape
使用索引和最近邻搜索进行搜索
使用annoy库的AnnoyIndex函数,一种优化快速搜索的方式存储嵌入。
在给定集合中找到距离给定点最近(或最相似)的点的优化问题被称为最近邻搜索。
这种方法适用于大量的文本(其他选项包括Faiss、ScaNN和PyNNDescent)。
构建索引后,我们可以使用它来检索现有问题的最近邻,或者嵌入新问题并找到它们的最近邻。
# 创建搜索索引,传入嵌入的大小
search_index = AnnoyIndex(embeds.shape[1], 'angular')
# 将所有向量添加到搜索索引中
for i in range(len(embeds)):search_index.add_item(i, embeds[i])search_index.build(10) # 10 trees
search_index.save('test.ann')
查找数据集中示例的邻居
如果我们只对数据集中的问题之间的距离感兴趣(没有外部查询),一种简单的方法是计算我们拥有的每对嵌入之间的相似性。
# 选择一个示例(我们将检索与之相似的其他示例)
example_id = 7# 检索最近的邻居
similar_item_ids = search_index.get_nns_by_item(example_id,10,include_distances=True)
# 格式化并打印文本和距离
results = pd.DataFrame(data={'texts': df.iloc[similar_item_ids[0]]['text'], 'distance': similar_item_ids[1]}).drop(example_id)print(f"问题:'{df.iloc[example_id]['text']}'\n最近的邻居:")
results
查找用户查询的邻居
我们可以使用诸如嵌入之类的技术来找到用户查询的最近邻居。
通过嵌入查询,我们可以衡量它与数据集中项目的相似性,并确定最近的邻居。
query = "世界上最高的山是什么?"# 获取查询的嵌入
query_embed = co.embed(texts=[query],model="large",truncate="RIGHT").embeddings# 检索最近的邻居
similar_item_ids = search_index.get_nns_by_vector(query_embed[0],10,include_distances=True)
# 格式化结果
results = pd.DataFrame(data={'texts': df.iloc[similar_item_ids[0]]['text'], 'distance': similar_item_ids[1]})print(f"问题:'{query}'\n最近的邻居:")
results
伊织 2024-03-04(周一)