一、算子列表
| 编号 | 名称 |
| 1 | map算子 |
| 2 | flatMap算子 |
| 3 | filter算子 |
| 4 | mapPartitions算子 |
| 5 | mapPartitionsWithIndex算子 |
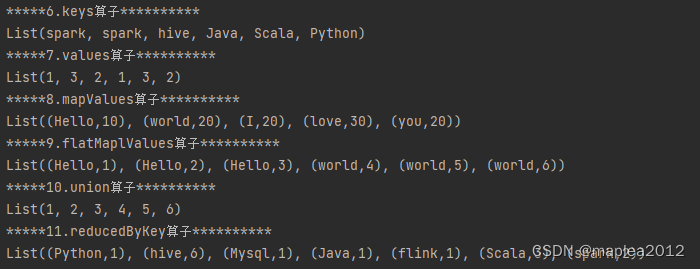
| 6 | keys算子 |
| 7 | values算子 |
| 8 | mapValues算子 |
| 9 | flatMaplValues算子 |
| 10 | union算子 |
| 11 | reducedByKey算子 |
| 12 | combineByKey算子 |
| 13 | groupByKey算子 |
| 14 | foldByKey算子 |
| 15 | aggregateByKey算子 |
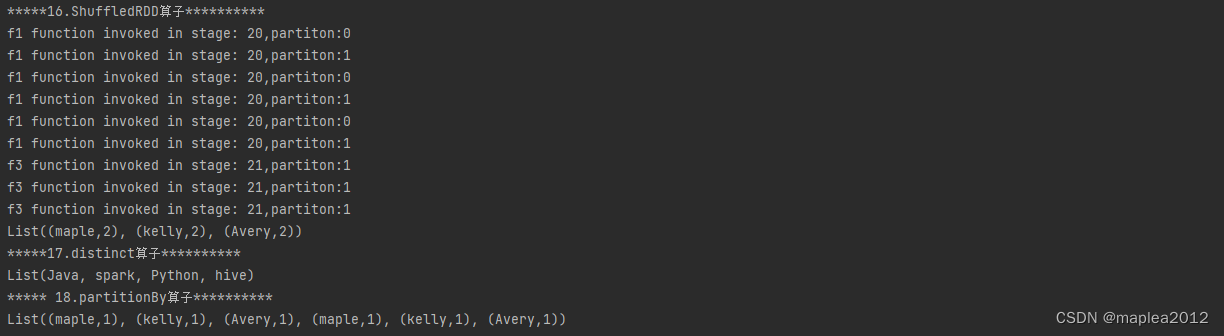
| 16 | ShuffledRDD算子 |
| 17 | distinct算子 |
| 18 | partitionBy算子 |
二、代码示例
package sparkCoreimport org.apache.hadoop.mapreduce.task.reduce.Shuffle
import org.apache.log4j.{Level, Logger}
import org.apache.spark.rdd.{RDD, ShuffledRDD}
import org.apache.spark.rdd.RDD.rddToPairRDDFunctions
import org.apache.spark.{Aggregator, HashPartitioner, SparkConf, SparkContext, TaskContext}/*** spark基本算子*/object basi_transform_02 {def main(args: Array[String]): Unit = {val conf: SparkConf = new SparkConf().setAppName("transform").setMaster("local[*]")val sc: SparkContext = new SparkContext(conf)sc.setLogLevel("WARN")//1. map算子val rdd1: RDD[Int] = sc.parallelize(List(1, 2, 3, 4, 5, 6, 7),2)val map_rdd: RDD[Int] = rdd1.map(_ * 2)println("*****1. map算子************")map_rdd.foreach(println(_))//2.flatMap算子println("*****2.flatMap算子************")val arr: Array[String] = Array("Hive python spark","Java Hello Word")val rdd2: RDD[String] = sc.makeRDD(arr, 2)val flatMap_rdd: RDD[String] = rdd2.flatMap(_.split(" "))flatMap_rdd.foreach(println(_))//3.filter算子println("*****3.filter算子***********")val rdd3: RDD[Int] = sc.parallelize(List(1, 2, 3, 4, 4, 5, 4, 4, 3, 10))val filter_rdd :RDD[Int]= rdd3.filter(_ % 2 == 0)filter_rdd.foreach(println(_))//4. mapPartitions算子:将数据以分区的形式返回,进行map操作,一个分区对应一个迭代器// 应用场景: 比如在进行数据库操作时,在操作数据之前,需要通过JDBC方式连接数据库,如果使用map,那每条数据处理之前// 都需要连接一次数据库,效率显然很低.如果使用mapPartitions,则每个分区连接一次即可println("*****4. mapPartitions算子**********")val rdd4: RDD[Int] = sc.parallelize(List(1, 2, 3, 4, 4, 5, 4, 4, 3, 10),2)val mapParition_rdd: RDD[Int] = rdd4.mapPartitions(iter => {print("模拟数据库连接操作")iter.map(_ * 2)})mapParition_rdd.foreach(println(_))//5. mapPartitionsWithIndex算子,类似于mapPartitions,不过有两个参数// 第一个参数是分区索引,第二个是对应的迭代器// 注意:函数返回的是一个迭代器println("*****5. mapPartitionsWithIndex算子**********")val rdd5: RDD[Int] = sc.parallelize(List(10, 20, 30, 40, 60),2)val mapPartitionWithIndex_Rdd: RDD[String] = rdd5.mapPartitionsWithIndex((index, it) => {it.map(e => s"partition:$index,val:$e")})mapPartitionWithIndex_Rdd.foreach(println(_))//6.keys算子: RDD中的数据是【对偶元组】类型,返回【对偶元组】的全部keyprintln("*****6.keys算子**********")val lst: List[(String, Int)] = List(("spark", 1), ("spark", 3), ("hive", 2),("Java", 1), ("Scala", 3), ("Python", 2))val rdd6: RDD[(String, Int)] = sc.parallelize(lst)val keysRdd: RDD[String] = rdd6.keyskeysRdd.foreach(println(_))//7.values: RDD中的数据是【对偶元组】类型,返回【对偶元组】的全部valueprintln("*****7.values算子**********")val values_RDD: RDD[Int] = rdd6.valuesvalues_RDD.foreach(println(_))//8.mapValues: RDD中的数据为对偶元组类型, 将value进行计算,然后与原Key进行组合返回(即返回的仍然是元组)println("*****8.mapValues算子**********")val lst2: List[(String, Int)] = List(("Hello", 1), ("world", 2),("I", 2), ("love", 3), ("you", 2))val rdd8: RDD[(String, Int)] = sc.parallelize(lst2, 2)val mapValues_rdd: RDD[(String, Int)] = rdd8.mapValues(_ * 10)mapValues_rdd.foreach(println(_))//9.flatMaplValues:RDD是对偶元组,将value应用传入flatMap打平后,再与key组合println("*****9.flatMaplValues算子**********")// ("spark","1 2 3") => ("spark",1),("spark",2),("spark",3)val lst3: List[(String,String )] = List(("Hello", "1 2 3"), ("world", "4 5 6"),)val rdd9: RDD[(String, String)] = sc.parallelize(lst3)// 第一个_是指初始元组中的value;第二个_是指value拆分后的每一个值(转换成整数)val flatMapValues: RDD[(String, Int)] = rdd9.flatMapValues(_.split(" ").map(_.toInt))flatMapValues.foreach(println(_))//10.union:将两个类型一样的RDD合并到一起,返回一个新的RDD,新的RDD分区数量是两个RDD分区数量之和println("*****10.union算子**********")val union_rdd1 = sc.parallelize(List(1, 2, 3), 2)val union_rdd2 = sc.parallelize(List(4, 5, 6), 3)val union_rdd: RDD[Int] = union_rdd1.union(union_rdd2)union_rdd.foreach(println(_))//11.reducedByKey,在每个分区中进行局部分组聚合,然后将每个分区聚合的结果从上游拉到下游再进行全局分组聚合println("*****11.reducedByKey算子**********")val lst4: List[(String, Int)] = List(("spark", 1), ("spark", 1), ("hive", 3),("Python", 1), ("Java", 1), ("Scala", 3),("flink", 1), ("Mysql", 1), ("hive", 3))val rdd11: RDD[(String, Int)] = sc.parallelize(lst4, 2)val reduced_rdd: RDD[(String, Int)] = rdd11.reduceByKey(_ + _)reduced_rdd.foreach(println(_))//12.combineByKey:相比reducedByKey更底层的方法,后者分区内和分区之间相同Key对应的value值计算逻辑相同,但是前者可以分别定义不同的// 的计算逻辑.combineByKey 需要传入三个函数作为参数:// 其中第一个函数:key在上游分区第一次出现时,对应的value该如何处理// 第二个函数:分区内相同key对应value的处理逻辑// 第三个函数: 分区间相同Key对应value的处理逻辑println("*****12.combineByKey算子**********")val f1 = (v:Int) => {val stage = TaskContext.get().stageId()val partition = TaskContext.getPartitionId()println(s"f1 function invoked in stage: $stage,partiton:$partition")v}//分区内相同key对应的value使用乘积val f2 = (a:Int,b:Int) => {val stage = TaskContext.get().stageId()val partition = TaskContext.getPartitionId()println(s"f2 function invoked in stage: $stage,partiton:$partition")a * b}//分区间相同key对应的value使用加法val f3 = (m:Int,n:Int) => {val stage = TaskContext.get().stageId()val partition = TaskContext.getPartitionId()println(s"f3 function invoked in stage: $stage,partiton:$partition")m + n}val rdd12: RDD[(String, Int)] = sc.parallelize(lst4,2)val combineByKey_rdd: RDD[(String, Int)] = rdd12.combineByKey(f1, f2, f3)combineByKey_rdd.foreach(println(_))//13.groupByKey:按key进行分组,返回的是(key,iter(value集合)println("*****13.groupByKey算子**********")val rdd13: RDD[(String, Int)] = sc.parallelize(lst4, 3)val groupByKey_rdd: RDD[(String, Iterable[Int])] = rdd13.groupByKey()groupByKey_rdd.foreach(println(_))//14.foldByKey:每个分区应⽤⼀次初始值,先在每个进⾏局部聚合,然后再全局聚合(注意全局聚合的时候,初始值并不会被用到)// 局部聚合的逻辑与全局聚合的逻辑相同println("*****14.foldByKey算子**********")val lst5: List[(String, Int)] = List(("maple", 1), ("kelly", 1), ("Avery", 1),("maple", 1), ("kelly", 1), ("Avery", 1))val rdd14: RDD[(String, Int)] = sc.parallelize(lst5)val foldByKey_rdd: RDD[(String, Int)] = rdd14.foldByKey(1)(_ + _)foldByKey_rdd.foreach(println(_))//15.aggregateByKey:foldByKey,并且可以指定初始值,每个分区应⽤⼀次初始值,传⼊两个函数,分别是局部聚合的计算逻辑// 和全局聚合的逻辑println("*****15.aggregateByKey算子**********")val rdd15: RDD[(String, Int)] = sc.parallelize(lst5)val aggregateByKey_rdd: RDD[(String, Int)] = rdd15.aggregateByKey(1)(_ + _,_ * _ )aggregateByKey_rdd.foreach(print(_))//16 ShuffledRDD:reduceByKey、combineByKey、aggregateByKey、foldByKey底层都是使⽤的ShuffledRDD,// 并且 mapSideCombine = trueprintln("*****16.ShuffledRDD算子**********")val rdd16: RDD[(String, Int)] = sc.parallelize(lst5,2)val partitioner = new HashPartitioner(rdd16.partitions.length)// 对rdd16按照指定分区器进行分区// String是rdd16中Key的数据类型,第一个Int是rdd16中value的数据类型,第二个Int是中间结果的数据类型(当然前提是传入聚合器-里面包含计算逻辑// [可以据此知晓中间结果的数据类型])val shuffledRDD: ShuffledRDD[String, Int, Int] = new ShuffledRDD[String, Int, Int](rdd16,partitioner)// 设置一个聚合器: 指定rdd16的计算逻辑(包含三个函数,分别是分区内一个key对应value的处理逻辑;分区内相同key对应value计算逻辑// 和分区间相同Key对应value计算逻辑)val aggregator: Aggregator[String, Int, Int] = new Aggregator[String, Int, Int](f1, f2, f3)// 给shuffledRDD设置聚合器shuffledRDD.setAggregator(aggregator)shuffledRDD.setMapSideCombine(true) // 设置Map端聚合println(shuffledRDD.collect().toList)// 17.distinct算子:对RDD元素进行去重println("*****17.distinct算子**********")val lst6: Array[String] = Array("spark", "spark", "hive","Python", "Python", "Java")val rdd17: RDD[String] = sc.parallelize(lst6)val distinct_rdd: RDD[String] = rdd17.distinct()println(distinct_rdd.collect().toList)// 18.partitionBy: 按照指定的分区器进行分区(底层使用的是ShuffleRDD)println("***** 18.partitionBy算子**********")val rdd18: RDD[(String,Int)] = sc.parallelize(lst5,2)val partitioner2 = new HashPartitioner(rdd18.partitions.length)val partitioned_rdd: RDD[(String, Int)] = rdd18.partitionBy(partitioner2)println(partitioned_rdd.collect().toList)sc.stop()}
}