数据库调优的几个维度:
- 索引失效,没有充分用到索引——索引建立
- 关联查询太多JOIN——SQL优化
- 服务器调优以及各个参数设置——调整my.cnf
- 数据过多——分库分表
SQL查询优化的几种方式:
- 物理查询优化:通过索引以及表连接方式进行优化
- 逻辑查询优化:通过SQL等价变换提升查询效率
一、索引失效案例
1.1、尽量全值匹配
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age=30 AND classId=4 AND NAME='abcd'CREATE INDEX idx_age ON student(age); //执行时间0.149s
CREATE INDEX idx_age ON student(age, classId); //执行时间0.001s
CREATE INDEX idx_age ON student(age, classId, NAME); //执行时间0.002s
使用了越多的属性来建立索引,会加快SQL查询的效率,能加速每一个属性的查询
1.2、最佳左前缀法则
CREATE INDEX idx_age ON student(age, classId, NAME);SELECT SQL_NO_CACHE * FROM student
WHERE student.age=30 AND student.classId=2 AND NAME='abcd';
在过滤条件(WHERE)中使用了索引的情况下,要按照索引建立时的顺序从左往右筛选,如果中间跳过了某个字段,比如跳过了student.classId,则NAME字段将无法被用来查询
1.3、主键插入顺序
对于一个使用InnoDB存储引擎的数据库来说,其记录是按照主键值从小到大排序的。如果我们插入的数据是依次递增的,每插满一个数据页就换到下一个数据页继续插。但是插入的数据忽大忽小时,会带来更多得页面分裂以及记录移位。这也就导致了性能损耗。
所以,可以通过设置主键具有AUTO_INCREMENT,让存储引擎自己为记录生成递增的主键,避免用户手动插入。
1.4、计算、函数、类型转换(自动或者手动)导致索引失效
MySQL中的 类型的值会先作用于函数、计算或者类型转换,再作用于整体的操作
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE LEFT(student.name, 3)='abc';
//这条语句MySQL会将name字段的值一个个取出来进行函数操作后再与abc进行比较,所以用不上索引
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.name LIKE 'abc%';
//而这条语句可以用上索引
1.5、范围条件右边的列索引失效
CREATE INDEX idx_age_classId_name ON student(age, classId, NAME);EXPLAIN SELECT SQL_NO_CACHE * FROM student
WHERE student.age=10 AND student.classId>20 AND student.NAME='abc';
如果对索引的过滤条件中限制了一定范围,那么使用B+数来查询后,索引中剩下字段也就没有意义来。这里由于classId在索引的中间位置,所以在它之后的NAME字段索引失效。
解决失效的方法为重新设置索引
CREATE INDEX idx_age_name_classId ON student(age, NAME, classId);
1.6 不等号索引失效
使用!=或者<>导致索引失效,原理同上
1.7、is not null 无法使用索引
is null可以使用索引,is not null无法使用索引,情况类似于等于号可以使用索引,不等号不能使用索引
解决这类索引失效问题的方法为:将字段设置为NOT NULL约束,可以设置0为INT类型字段的初始值,空字符串为字符串类型的初始值。
1.8、like以通配符%开头索引失效
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE NAME LIKE '%ab';
开头不确定,所以无法在B+树中搜索
1.9、OR前后存在非索引的列,索引失效
CREATE INDEX student ON student(age)EXPLAIN SELECT SQL_NO_CACHE * FROM student
WHERE age=10 OR classId=1
虽然age可以使用索引,但是classId仍然需要全表扫描,所以整个语句仍然是全表扫描。
1.10、数据库和表的字符集使用不统一
统一字符集可以避免由于字符集转换产生的乱码,不同字符集进行比较前会进行类型转换导致索引失效。
二、关联查询优化
2.1、左外连接
在没有索引的情况下进行查询
EXPLAIN SELECT SQL_NO_CACHE * FROM `type` LEFT JOIN book ON type.card=book.card;
这种情况相当于把type.card值与book.card值一个一个进行比较。
对被驱动表book.card添加索引后
CREATE INDEX Y ON book(card);
EXPLAIN SELECT SQL_NO_CACHE * FROM `type` LEFT JOIN book ON type.card = book.card;
这里相当于驱动表type是一个一个的取,而被驱动表book则是在B+树上进行快速查找
2.2、内连接
在内连接中小表驱动大表,优化器会对两个表进行计算,将数据量小的表作为驱动表,数据量大的表作为被驱动表。
CREATE INDEX X ON book(card);
EXPLAIN SELECT SQL_NO_CACHE * FROM book INNER JOIN `type` ON book.card = `type`.card;
在上面这个语句中,虽然book表在等号左边,但是只有book表具有索引,因此,这里的被驱动表仍然是book表。
2.3、JOIN语句原理
JOIN方式连接多个表,本质上就是各个表之间数据的循环匹配
- 简单嵌套循环连接(Simple Nested-Loop Join)
这种方式的效率最低,其算法为将驱动表A中的每一条记录都与被驱动表B进行匹配。
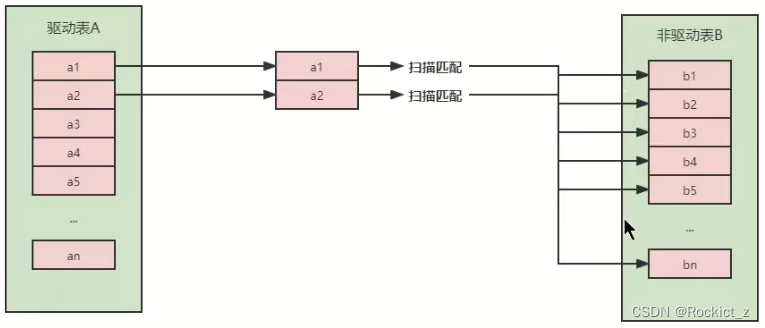
- 索引嵌套循环连接(Index Nested-Loop Join)
索引嵌套循环连接的优化思路主要是使用索引来替换全表查找来进行优化,从而减小内表的查询次数。

- 块嵌套循环连接(Block Nested-Loop Join)
为了减少被驱动表的IO次数,出现了块嵌套循环连接的方式,引入了Join buffer 缓冲区,将驱动表的部分数据缓冲到buffer中,然后全表扫描被驱动表进行匹配,将简单嵌套循环中的多次合并为一次,降低了被驱动表的访问频率。
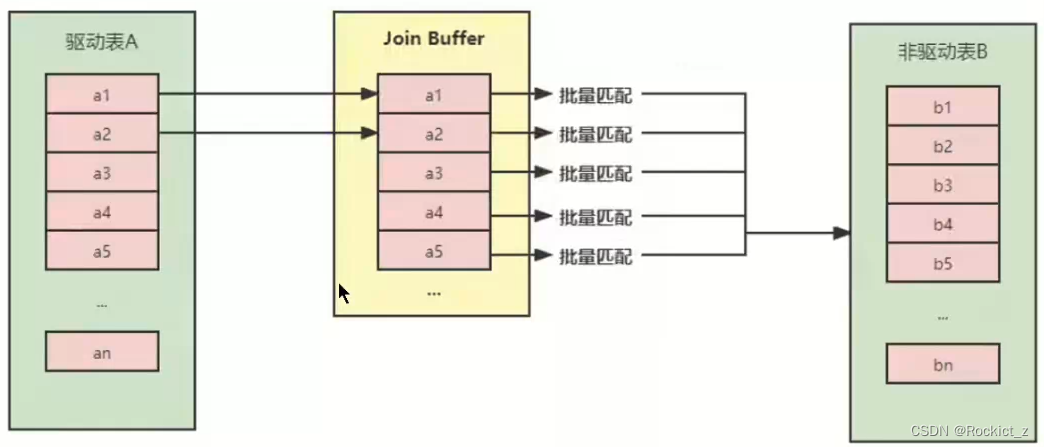
- Hash Join
Hash Join是做大数据集连接时的常用方式,优化器使用较小的表利用Join Key在内存中建立散列表,扫描较大的表并探测散列表进行搜索。
总结
- 对于
JOIN的内部实现来说,整体效率比较INLJ > BNLJ > SNLJ - 永远用小结果集驱动大结果集(结果集大小的判断为
表行数*每行大小) - 在INLJ中,为被驱动表匹配的条件增加索引,能够减少内层表的循环匹配次数
- 在BNLJ中,增大
Join buffer size,可以在内存中存下更多得行数,减少内层表的扫描次数 - 在BNLJ中,减少不必要的字段查询。