原文[0] :Ivan Burmistrov - 2024.02.15
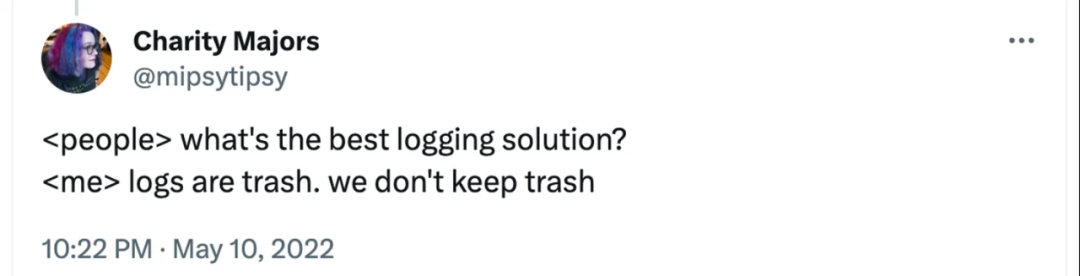
这段引自 Charity Majors 的话,或许是对当前科技行业可观测性状况的最佳概括——一个全面的、大规模的混乱。每个人都感到困惑,什么是 trace?什么是 span?一条 log 是 span 吗?我如果有 log,还需要 trace 吗?如果我有很好的 metrics,为什么还需要 trace?这样的问题层出不穷。Charity 与来自名为 Honeycomb[1] 的可观测性系统中的其他优秀成员,一直在为这些问题提供解答。然而,根据我自己的经验,要解释 Charity 所说的“log 是垃圾”仍然极其困难,更不用说 log 和 trace 本质上是同一种事物。为什么每个人都如此困惑?
冒着可能引起争议的风险,我要责怪 Open Telemetry。是的,它正在推动现代可观测性技术栈的发展,但我却因其引发的大规模混乱而责备它。并非因为它是个糟糕的解决方案——它实际上非常棒!但是,其展示和解释 Open Telemetry 是什么,以及它能做什么的整个方法,使可观测性看起来复杂而难以理解。
首先,Open Telemetry 从一开始就明确区分了 traces、metrics 和 logs:
OpenTelemetry 是一套 API、SDK 和工具的集合。你可以使用它来插装(instrument)、生成、收集和导出遥测数据(metrics、logs 和 traces),以帮助你分析软件的性能和行为。
然后,它深入解释了这三者。
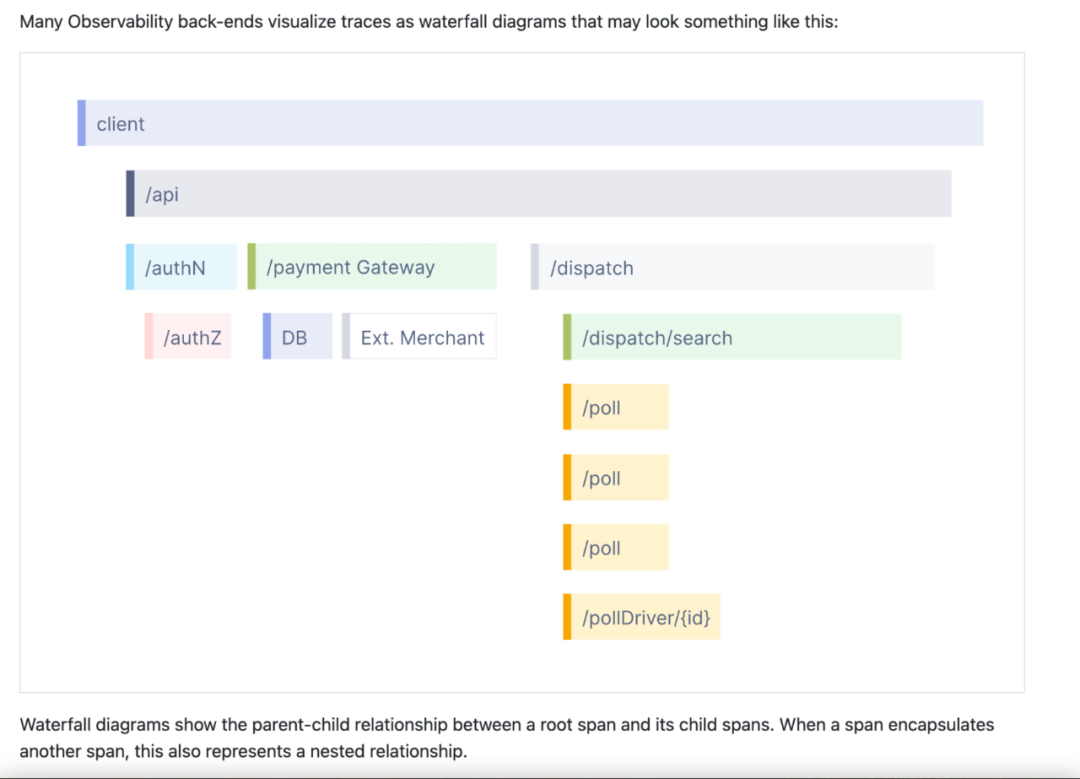
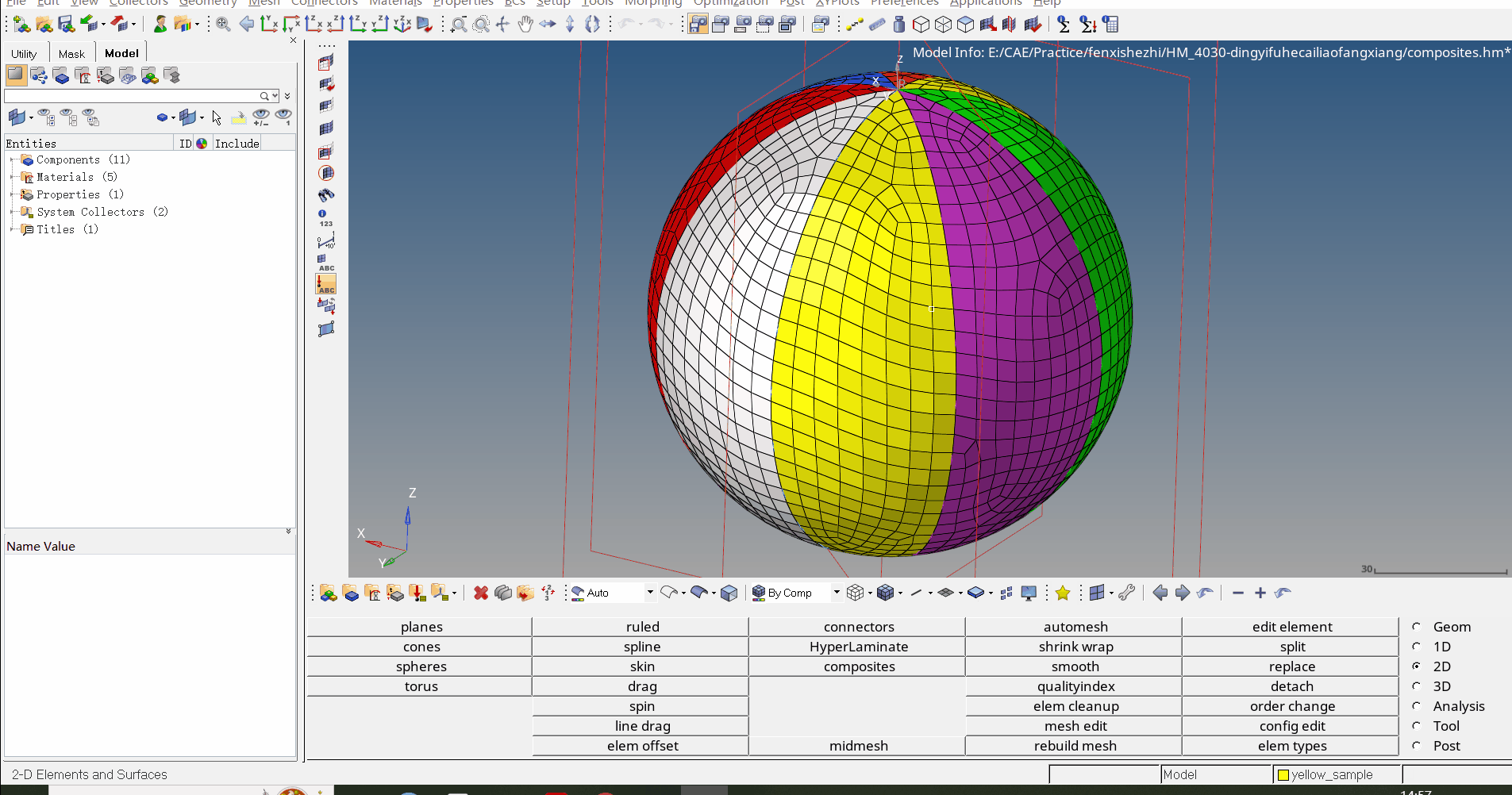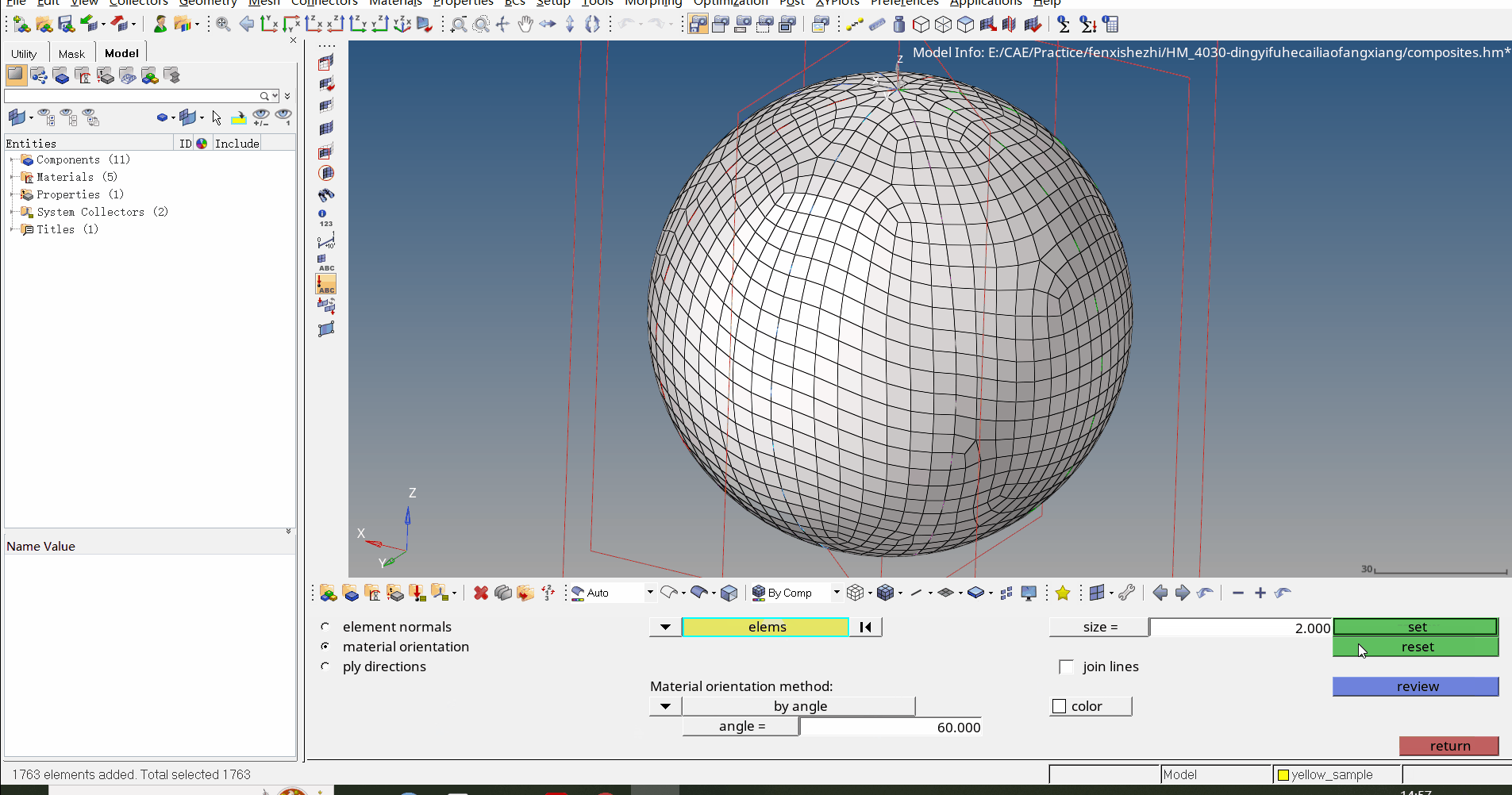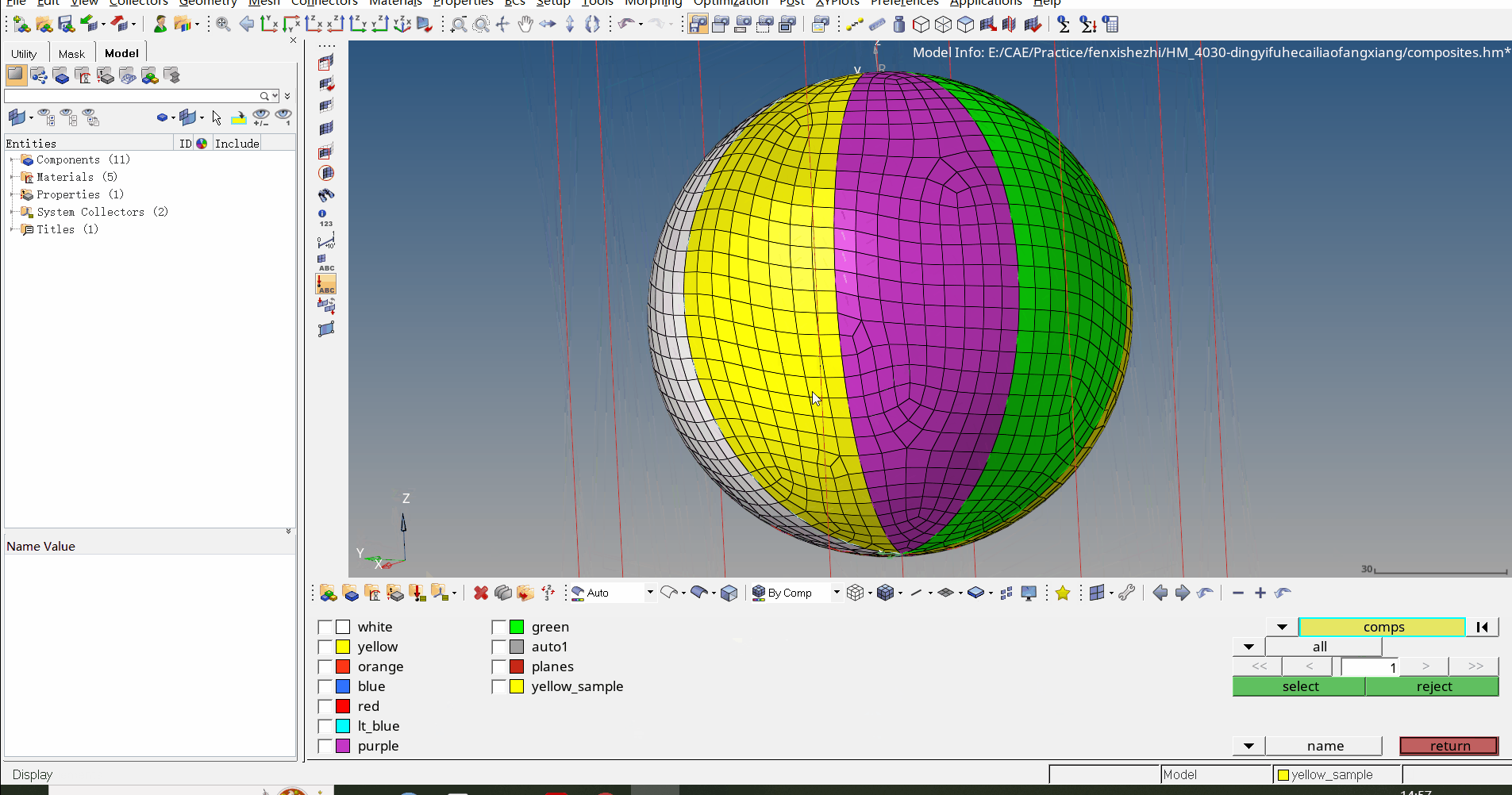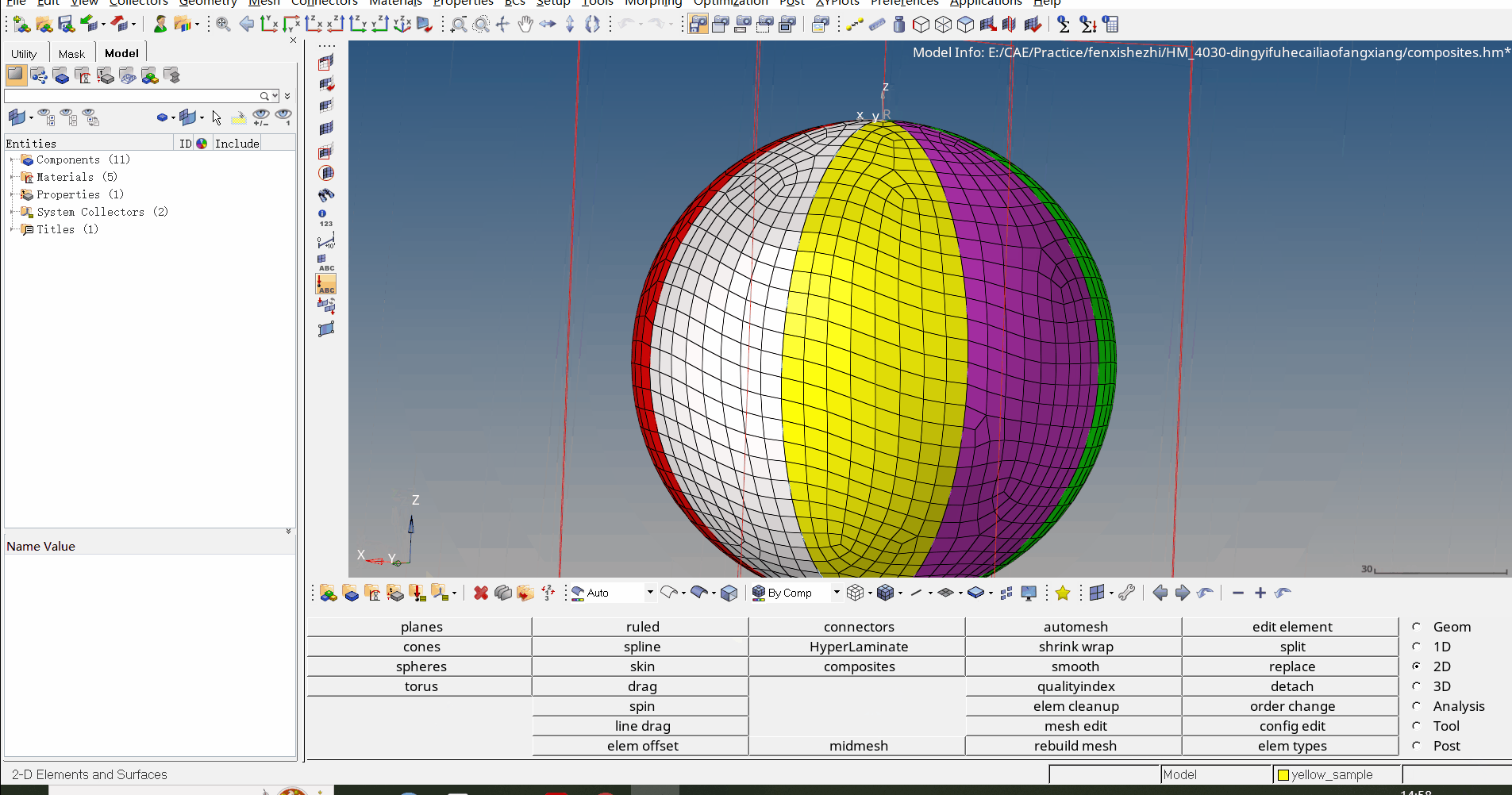
这是 Open Telemetry 网站介绍 trace 部分的截图。根据我与使用 OpenTelemetry 的人交谈的经验,这种展示确实已经成为与可观测性关联的主要图像之一。对一些人来说,这就是可观测性。而且它也将 trace 与其他任何事物区分开来。这显然不是 log,对吧?这也不像 metrics,对吧?它是某种特殊的,可能有点神圣的,需要投入学习的东西。根据我的经验,一旦人们了解了 trace,他们只会在这张图片以及 span、根 span、嵌套 span 等一系列术语的背景下思考它们。OpenTelemetry 网站有一个包含 60 多个术语的词汇表[2]页面!这一切都复杂到令人发狂!
但更重要的是——这种关注 “Losg、Metrics 和 Traces” 的焦点是否代表了可观测性的真正力量?它确实涵盖了一些真实的场景,但当涉及到大规模分布式系统时,更重要的是能够“深挖”数据——“slice and dice”它,构建和分析各种视图,关联,寻找异常……而提供所有这些功能的系统确实存在。
(译者注:"Slice and dice" 是一个来自烹饪的术语,指将食物切成小块的过程。此处指将大数据集分解成更小、更易于理解和分析的部分。)
Scuba:可观测性的乐园
当我在 Meta 工作的时候,并没有意识到,我有幸使用过最好的可观测系统。这个系统叫 Scuba,它是人们离开 Meta 之后最怀念的东西,优势之大不可估量。
Scuba 的基本理念非常简单,不需要一个词汇表页面就能让人理解。它操作的是 Wide Events。Wide Events 只是一组带有名称和值的字段,很像一个 json 文档。如果你需要记录一些信息——无论是系统的当前状态,还是由 API 调用、后台作业或其他任何事情引起的事件——你都可以向 Scuba 写入一些 Wide Events。例如,如果一个系统提供广告服务,自然会希望记录广告展示——即特定广告已被用户看到的事件。相应的 Wide Events 可能是这样的:
{"Timestamp": "1707951423","AdId": "542508c92f6f47c2916691d6e8551279”,"UserCountry": "US","Placement": "mobile_feed","CampaingType": "direct_ads","UserOS": "Android","OSVersion": "14","AppVersion": "798de3c28b074df9a24a479ce98302b6",...
}
这种事件被称为 Wide Events,因为鼓励将所有可以想到的信息都写入到其中。任何可能在特定数据上下文中相关的东西——只需放进去,稍后可能会有用。这种方法为处理 “_unknown unknowns_” 奠定了基础——你现在想不到的东西可能在后来的事件调查中被揭示出来。
处理 “unknown unknowns” 可以通过一个例子更好地展示。Scuba 有一个直观易用的界面,非常容易搜索和操作。它有一个可以选择查看的指标的部分,以及过滤器和分组的部分——Scuba 会绘制出一个漂亮的时间序列图。首次查看广告展示数据集,会简单地绘制出一个展示次数的图表:
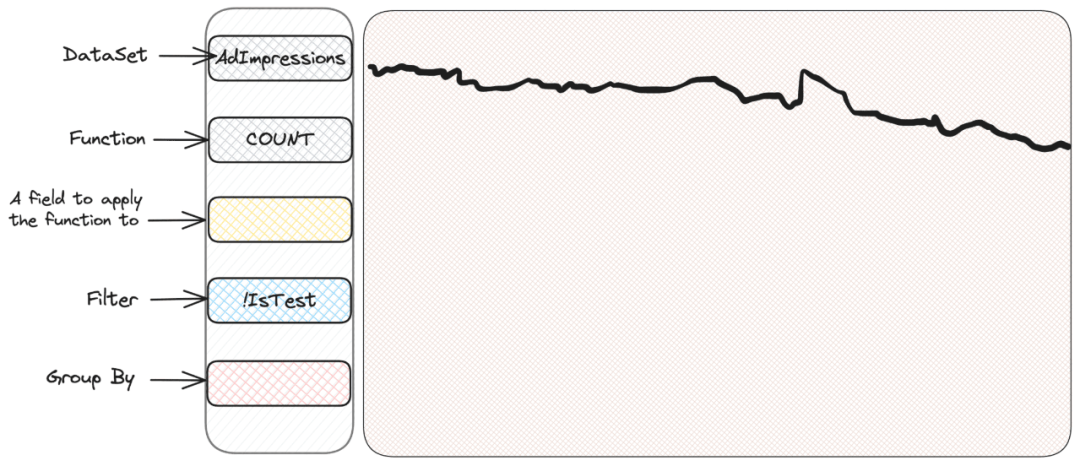
如果我们用 SQL 来表达这里具体查询了什么,那就是类似于
SELECT COUNT(*) FROM AdImpressions
WHERE IsTest = False
实际上,情况并非完全如此。Scuba 还有一个原生采样 的概念。当某个事件被写入 Scuba 时,它还必须写入一个叫做 samplingRate 的字段——该特定事件的采样率。Scuba 使用这个信息来正确地“放大”图表上显示的结果,所以无需在头脑中进行这种放大。这是一个非常棒的概念,因为它允许动态采样——例如,某种类型的展示可能比另一种采样更多,同时在 UI 中保留“真实”值。所以,实际的查询是
SELECT SUM(samplingRate) FROM AdImpressions
WHERE IsTest = False
注意,这整个“放大”过程是由 UI 透明地完成的,用户在查询时不用考虑到这一点。
假设有些告警发生了,指出我们宝贵的广告展示图表看起来有些奇怪:
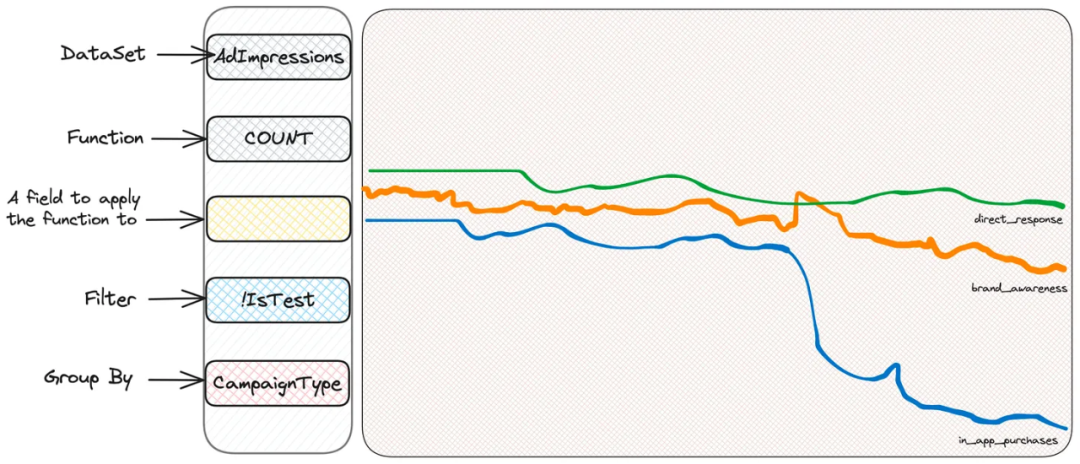
每个使用 Scuba 进行调查的人的第一反应是“slice and dice”,即过滤或分组,看看我们能否学到一些东西。我们不知道在寻找什么,但相信我们会找到它。所以按照比如说展示类型,或用户国家,或展示位置进行分组,直到我们找到一些可疑的东西。假设是 CampaignType 分组:
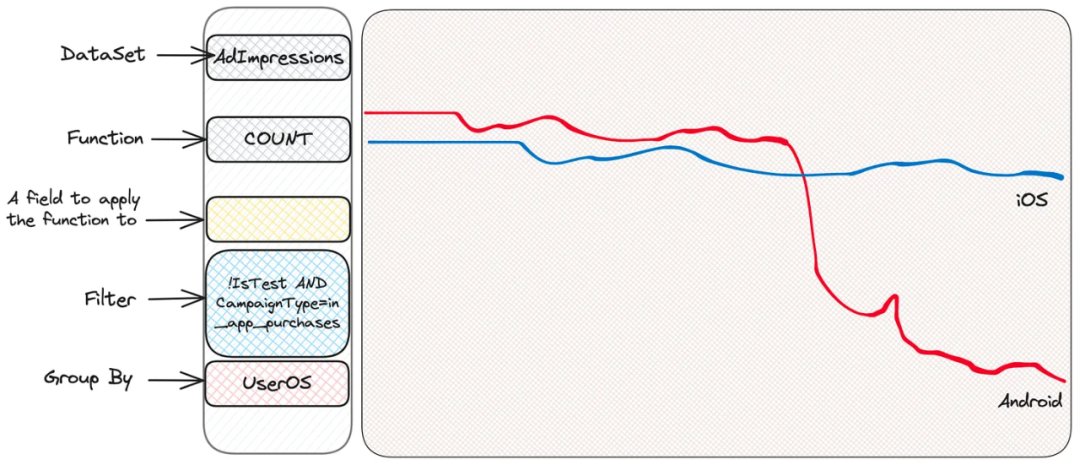
我们看到某种名为 in_app_purchases 的广告活动类型(完全是我编造的类型名)似乎看起来与其他的不同。我们并不知道这实际意味着什么——我们不需要知道!——继续我们的挖掘。好的,现在我们只过滤这些活动,然后按照能想到的其他东西进行分组。例如,用户操作系统就很有意义。
嗯,Android 似乎有问题。iOS 是正常的,这表明问题在客户端——可能是一个出现故障的的应用版本?
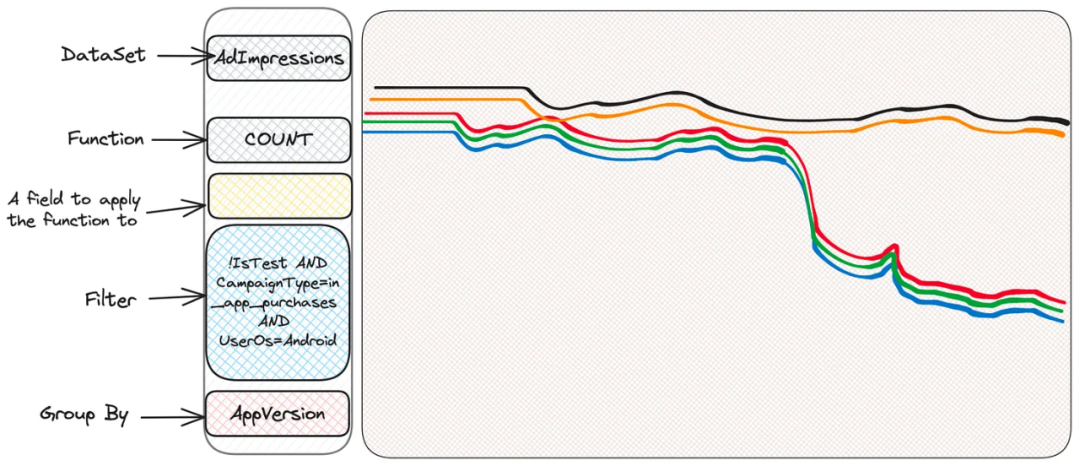
奇怪(按照应用版本分组后)。有些遭受到了影响,有些没有。检查一下操作系统版本吧?
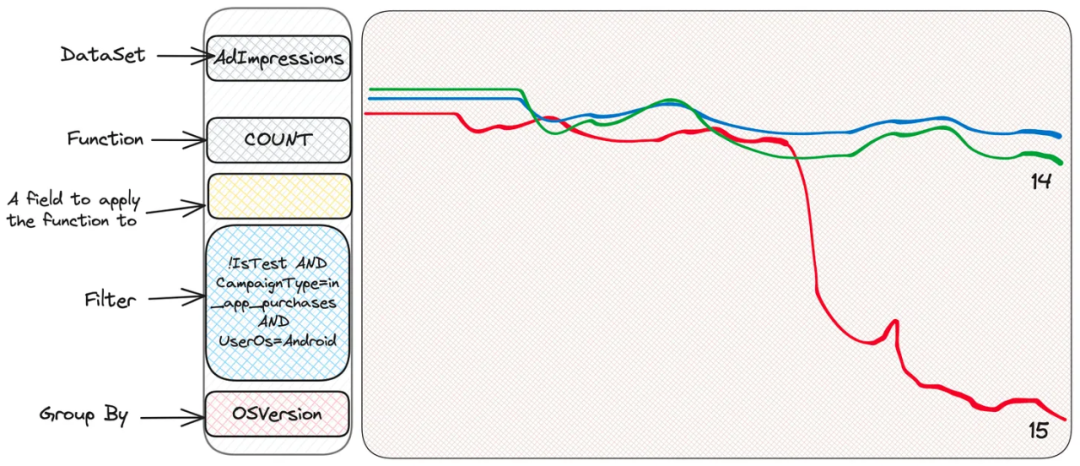
哈!这是最新的 Android 操作系统版本,看起来有些应用版本在这 Android 15 上对这种类型的广告活动表现得不好。有了这些信息,相关的团队现在可以深入研究了。
发生了什么?在没有任何系统知识的情况下,我们已经缩小了问题的范围,并确定了需要进一步调查的团队。我们是否可以提前知道操作系统、操作系统版本、广告活动类型和应用版本的这种奇特组合可能会导致一些问题,以准备专用的 metrics?当然不可能。这就是处理 “_unknown unknowns_” 的一个例子。我们只是将所有相关的上下文信息放入 Wide Events 中,然后在需要的时候使用它。Scuba 使得探索变得简单,因为它速度快,界面非常易用。还要注意,我们从未提到过任何关于基数(cardinality)的事情。因为这并不重要——任何字段都可以有任意基数。Scuba 处理的是原始事件,不预先聚合任何东西,所以基数不是问题。
(译者注:基数指的是在一个特定数据集或数据库表中,某个特定列的唯一值的个数。例如,有一个包含全世界所有国家名字的数据库列,那么这个列的基数就是世界上国家的个数。)
有时候,UI/可视化方面没有得到足够的关注,可观测性系统提供一些查询语言——要么是专有的(非常糟糕),要么是 SQL(稍微好一点,但仍然糟糕)。这样的接口几乎不可能进行类似的调查。Scuba 的一个重要方面是,所有的字段——函数、过滤器、分组等——都是可探索的。这意味着有一个简单的方法来查看我们可以选择什么样的值。当某个字段的所有者不懒惰,他们甚至包含了给定字段的详细描述,包括相关链接等。这是非常重要的。我自己成功地调查了很多事件,而无需完全理解整个系统,或者这个数据集中可用的数据。而且,我在这些调查中,仅仅通过使用 Scuba,就学到了很多关于系统的知识!这真是太棒了。这就是可观测性的乐园。
离开 Meta 后的困惑
现在想象一下,当我离开 Meta 并了解到外面的可观测性系统的状态时,我有多么困惑和难以置信。

Logs?Traces?Metrics?这是什么鬼?有没有人用 Wide Events?我能不能不学那个词汇表的 60 个术语,只是...探索一下?
我花了相当长的时间才将我的基于 Scuba 的思维模型映射到 Open Telemetry 的思维模型。我意识到 Open Telemetry 的 Span 实际上就是 Wide Events。实际上,我还不太确定是否理解正确:

如果我们以 AdImpression(广告展示)为例,这个展示实际上并不是一个操作,而只是我们想要记录的一些事实……公平地说,Open Telemetry 中有一些关于事件的概念:

但是如果我们点击链接深入挖掘,会再次发现事件实际上是 traces、metrics 或 logs 中的一种 🤷

但无论如何,Span 是最接近 Wide Events 的概念。问题是——当人们已经学习了 Open Telemetry 提出的模型时,要倡导这种思维模型是极其困难的。这真的很让人沮丧,因为 traces、metrics 和 logs 实际上都只是 Wide Events 的特例:
-
Traces 和 Spans: 这些只是具有 SpanId、TraceId 和 ParentSpanId 字段的 Wide Events。所以我们可以过滤所有具有给定 TraceId 的 span,使用 SpanId → ParentSpanId 关系对它们进行拓扑排序,然后绘制大家都喜欢的分布式调用链视图。
-
Logs: 说实话,我真的很困惑 Open Telemetry 中的日志是什么意思。看起来有很多东西[3],其中之一就是结构化日志,这基本上就是 Wide Events。太好了!但是,问题在于,“log” 是一个相当明确的概念,通常人们指的是那些
logger.info(…)调用产生的内容。无论如何,无论意思是什么,log 当然可以轻易地映射到 Wide Events。在最简单的情况下,我们可以获取 log 消息,将其放入 “log_message” 字段,添加一堆元数据,然后就可以了。在更复杂的情况下,我们可以尝试通过删除看起来像 ID 的令牌,从日志消息中自动提取一个模板,并获取这个模板的哈希值。这可以让我们按这个哈希值分组,从而快速得到最频繁的错误。Meta 有这样的系统,它非常酷。 -
Metrics: 指标也可以轻易地映射。我们只需要每隔一段时间发出一个包含系统状态(如 CPU、各种计数器等系统 metrics)的 Wide Events。顺便说一句,Prometheus 通过抓取方法就是这样做的——每隔一段时间抓取系统的快照。然而,与 Prometheus 不同,使用 Wide Events 方法我们不需要担心基数问题。
(译者注:metrics label 的值,需要提前设计好,如果值的维度(基数)很大,则会非常占用 Prometheus 的存储。比如 restful uri 要记录成 /user/{id}, 而不是具体的 /user/123)
但 Wide Events 可以提供比这些“三大支柱”更多的东西。前面提到的调试过程就是一个例子,它并没有真正被 traces、logs 和 metrics 覆盖——至少不是自然覆盖的。也可能有其他的用例——例如,连续的性能分析数据可以轻易地表示为 Wide Events,并查询以构建火焰图[4]。无需为此拥有单独的系统——一个处理 Wide Events 的系统就能做到所有这些。想象一下,当所有的东西都在一个地方,一起存储时,进行交叉关联和根源分析的可能性。特别是现在,AI-based 工具在数据关联发现方面表现出色的时代。
那又怎样?
我不知道...我只是想表达对这种混乱程度和对“三大支柱”重点关注的挫败感。
我只是希望可观测供应商能够对抗混乱,提供一种简单自然的方式来与系统交互。Honeycomb[5] 似乎正在做这件事[6],还有一些其他系统,如 Axiom[7]。这很棒!我希望其他人也能跟随。
参考资料
[0] 原文: https://isburmistrov.substack.com/p/all-you-need-is-wide-events-not-metrics
[1] Honeycomb: https://www.honeycomb.io/
[2] 词汇表: https://opentelemetry.io/docs/concepts/glossary/
[3] 有很多东西: https://opentelemetry.io/docs/specs/otel/glossary/#logs
[4] 火焰图: https://www.brendangregg.com/flamegraphs.html
[5] Honeycomb: https://www.honeycomb.io/
[6] 做这件事: https://x.com/mipsytipsy/status/1738048200630792245?s=20
[7] Axiom: https://axiom.co/