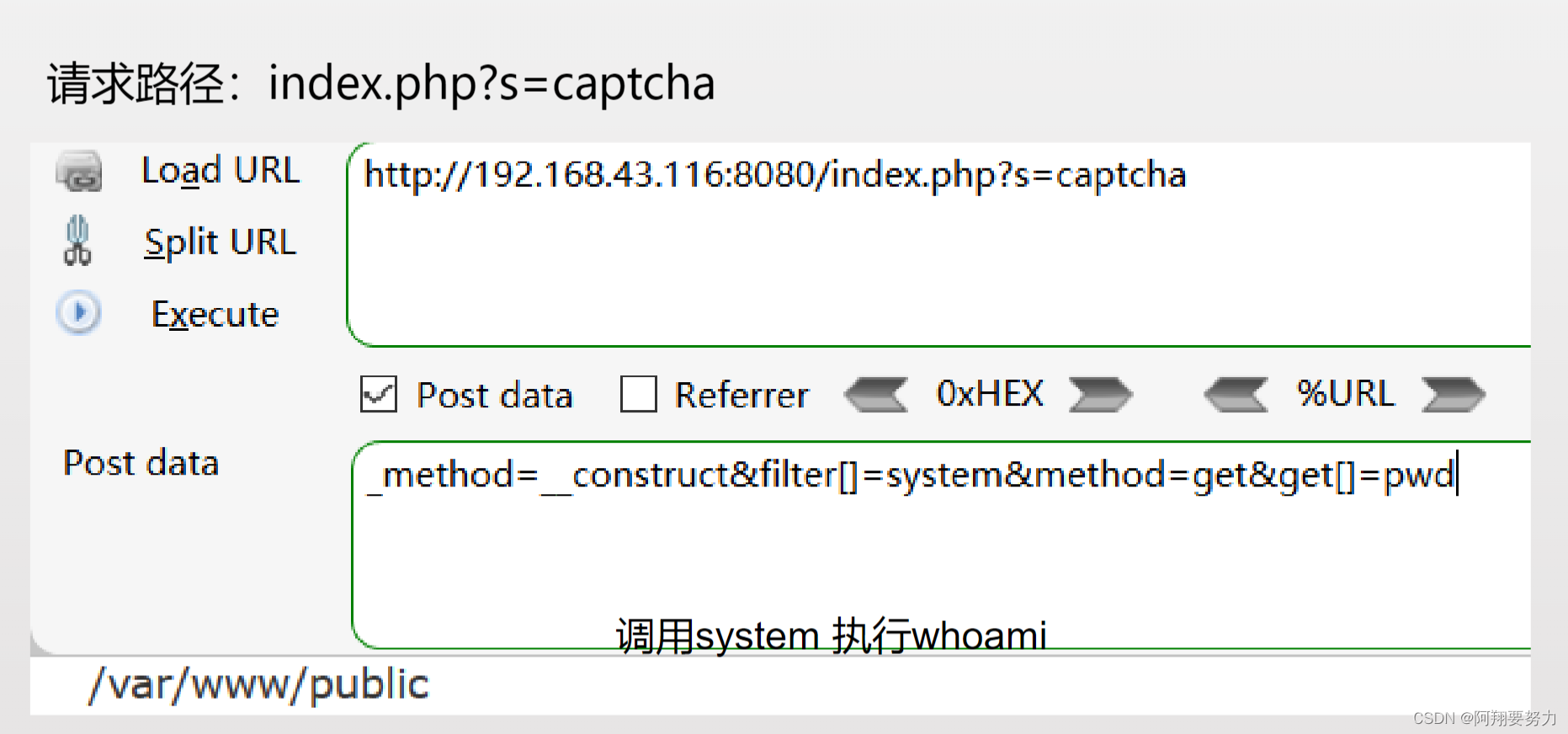
概念:
基于MPP设计理念实现的数据库,支持大数据集存储、实时数据分析,交互式数据分析等。
MPP:将任务并行分散至多个节点,由各节点单独计算,再将各节点计算结果汇总得到最终结果。
原理:
- FE:即frontend,类似于前端节点,用来维护元数据(表结构、用户权限...),解析查询请求,以及返回查询结果
- 1>Leader&&Follower:保证元数据高可用
- 2>Observer:备份元数据,扩展结点
- BE:即Backend,类似后端节点,用来保存物理数据(用户需要操作的数据,计算后的结果数据)和计算。此外BE还提供了副本机制用于保证数据的高可用性。
-
数据模型
Aggregate:聚合数据模型,按照相同的key对行数据进行处理,处理方式有如下几种
SUM:求和,多行的 Value 进行累加。
REPLACE:替代,下一批数据中的 Value 会替换之前导入过的行中的 Value。
MAX:保留最大值。
MIN:保留最小值
例如:对同一个用户的两条订单,在导入数据时,如果设置了AggregationType属性为上述四种,则按照对应方式聚合,下图中用户10000的两条订单数据在last_visit_date(REPLACE)、cost(SUM)、max_dwell_time(MAX)、min_dwell_time(MIN)处发生聚合。
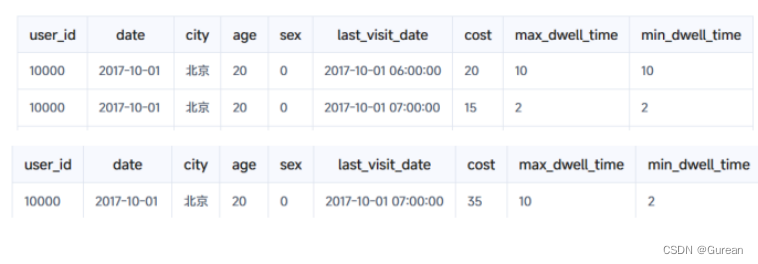
注意:聚合之后,Doris并不会保存原始数据,若需要某个字段的原始数据,可另设字段存储
Unique:本质上也是一种聚合模型,但更关注key的唯一性
例如:对同一个条数据的两个唯一字段,在导入数据时,仅保留一条,后插入的数据会对先插入的数据进行覆盖。对于下表数据,设置user
_id、user_name为唯一字段,若再插入一条与其相同但age为19的数据,则前者被覆盖
| user_id | user_name | city | age | sex | phone | address |
| 1 | 张三 | 北京 | 17 | 0 | 123456 | 北京市海淀区 |
| 2 | 李四 | 北京 | 18 | 0 | 123456 | 北京市朝阳区 |
Duplicate:对导入的数据不进行任何聚合操作,保持原样,即使两条数据完全相同,也都会保留。虽然如此,为了提高查询效率,在创建数据表时,依然可以使用DUPLICATE 对字段进行设置。
总结:
数据模型在建表时就已确认,且无法修改,因此选择一个合适的数据模型非常重要。
- Aggregate:该模型可以通过预聚合的方式降低聚合查询时需要扫描的数据量和计算量,适用于固定模式的报表类查询场景,但对count(*)不友好。
- Unique:模型针对需要唯一主键约束的场景,可以保证唯一性。
- Duplicate:模型较为灵活,不受聚合模型的约束,但同样无法利用聚合的特性。4
count(*)
对于定义了预聚合的表,在使用count(*)查询过程中,可能会发生预期结果和事实结果不一致的问题。Doris底层对这种情况的处理方式是查询中扫描全部的AGGREGATEKEY列,并聚合,然后得出结果(在聚合列较多数据大的时候并不友好)。此外,还可以通过添加聚合类型为SUM的新列来模拟count(*),其值恒为1。