文章目录
-
自适应hash:
采用自适应 Hash 索引目的是方便根据 SQL 的查询条件加速定位到叶子节点,特别是当 B+ 树比较深的时候,通过自适应 Hash 索引可以明显提高数据的检索效率。 -
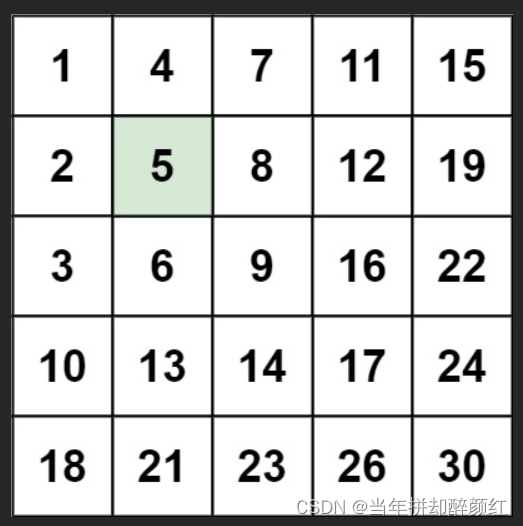
页目录:
页目录其实就是给页做了个目录,为了加速查找的,一个页中存放了一个一个的行记录它们是以链表连接的,一个一个查找效率低,所以给每个页做了页目录,使用了二分查找,对应的是slot槽,二分查找也是对slot查找的,每个槽会指向某个行记录,对于非叶子节点的话行记录里面存储的是目录项,对于叶子节点的话存储了具体的数据,非叶子节点存储了多少多少页用来快速定位到叶子节点,叶子节点存储实打实的数据。 -
定位慢查询:
开启慢查询日志,超过查询时间的sql会写入到慢查询日志中,可以使用工具来查看,再拿到慢的sql后,explain生成执行计划,分析。 -
执行计划中有什么:
执行计划其实就详细的说明了查询的细节吧,像type:它表示对一个表在查询时怎样访问,是用到主键索引还是唯一索引还是普通索引。还能看到可能用到的索引实际用到的索引、用到索引的长度啊,包括额外字段啊提示我们用没用索引,是不是索引条件下推等等啊,然后可以根据查询计划来具体的分析,然后优化。 -
索引失效:
最左前缀、联合索引范围后失效、%开头、对索引字段计算啊作用函数啊类型转换啊、非条件索引失效(不等于啊、is not null) -
覆盖索引和索引条件下推:

-
数据并发安全问题:

解决办法:
-
事务的ACID:
A:原子性,undo log
C:一致性:事务执行前后要合理要符合我们规定的,与业务是有关的,钱不能为负数
I:隔离性:锁机制来实现
D:持久性 redo log -
redo log

10 redo log一定安全吗不会丢失数据吗?
不一定吧,其实他有三种刷新的策略的也是可以去设置的,0 的话其实 每次commit后都会在redo log buffer中记录,由innoDB的后台线程每一秒将buffer中的写入文件系统缓存再刷新到磁盘,所以这种情况下可能会丢失一秒的数据;设置为1的话每次事务commit就一定会记录到磁盘,这时候是安全的;设置为2的话它是由操作系统没一秒刷新到磁盘。
11 undo log的作用:
MVCC的实现就依赖于undo log,行记录中的回滚指针就指向了undo log,undo log版本链记录了对这个记录的历史的修改信息,读之前的版本或者事务回滚都依赖undo log
12 意向锁:
意向锁其实就像一种行级锁的标志,当我们要加表锁时,如果表中有行的X锁的话,那其实是不能让这个事务获得表锁的,这样的话如果没有意向锁的话就要去一条一条记录去查看看有没有X锁,这样的话就性能低,意向锁就是在表级别上的这样一个锁,它描述的就是表中记录的X锁啊S锁啊这种,其实更类似于一种行锁的标记吧,也是为了快速判断能不能加表锁。
13 MVCC

14 ReadView的规则

15 redo log 写入master成功此时没写入bin log master宕机了,那slave与master数据就造成不一致怎么解决:
两阶段提交,redo log 提交分两阶段,在写入bin log 后再最终提交
16