目录
一、前言
二、数据准备
三、索引的分类
四、索引示例
示例1、主键索引(Primary Key Index)与 唯一索引(Unique Index)
示例2、前缀索引(Prefix Index)
示例3、联合索引(复合索引)
五、索引失效场景(较多,演示两个实例)
一、前言
朋友们大家好啊,在数据库的性能优化和调优过程中,索引起到了不可小觑的作用,并且索引分为了很多种,本文是在InnoDB存储引擎下测试索引的使用
二、数据准备
1.创建用例表(这里随便从本地库中找张表,挑了个xxljob的日志表,补充点数据)
CREATE TABLE `xxl_job_log` (`id` bigint NOT NULL AUTO_INCREMENT,`job_group` int NOT NULL COMMENT '执行器主键ID',`job_id` int NOT NULL COMMENT '任务,主键ID',`executor_address` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT '执行器地址,本次执行的地址',`executor_handler` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT '执行器任务handler',`executor_param` varchar(512) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT '执行器任务参数',`executor_sharding_param` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT '执行器任务分片参数,格式如 1/2',`executor_fail_retry_count` int NOT NULL DEFAULT '0' COMMENT '失败重试次数',`trigger_time` datetime DEFAULT NULL COMMENT '调度-时间',`trigger_code` int NOT NULL COMMENT '调度-结果',`trigger_msg` text CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci COMMENT '调度-日志',`handle_time` datetime DEFAULT NULL COMMENT '执行-时间',`handle_code` int NOT NULL COMMENT '执行-状态',`handle_msg` text CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci COMMENT '执行-日志',`alarm_status` tinyint NOT NULL DEFAULT '0' COMMENT '告警状态:0-默认、1-无需告警、2-告警成功、3-告警失败',PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;2、需要借助SQL的explain命令来查看数据执行的结果,先来看下每个参数
![]()

id: 表示查询中执行 SELECT 语句或子查询的序列号。
select_type: 表示查询的类型,常用的值有 SIMPLE、PRIMARY、SUBQUERY、DERIVED 等。
table: 指示查询涉及的表名。
partitions: 表示查询涉及的分区信息,如果查询中涉及到了分区表,则会显示分区的信息。
type: 表示 MySQL 在表中找到所需行的方式,常见的值有 ALL、index、range 等。
possible_keys: 表示可能应用在这张表中的索引。
key: 实际使用的索引。如果为 NULL,则表示没有使用索引;如果为 PRIMARY,则表示使用了主键索引。
key_len: 表示 MySQL 在索引键部分使用的字节数。
ref: 显示索引的哪一列被使用了,如果可能的话,是一个常数。
rows: 表示 MySQL 从表中找到所需行所需读取的行数。
filtered: 表示在表的数据行中,通过条件过滤后,剩下的行所占的比例,范围是 0 到 100。
Extra: 提供关于 MySQL 执行查询时的额外信息,比如是否使用了临时表、使用了文件排序等等。
三、索引的分类
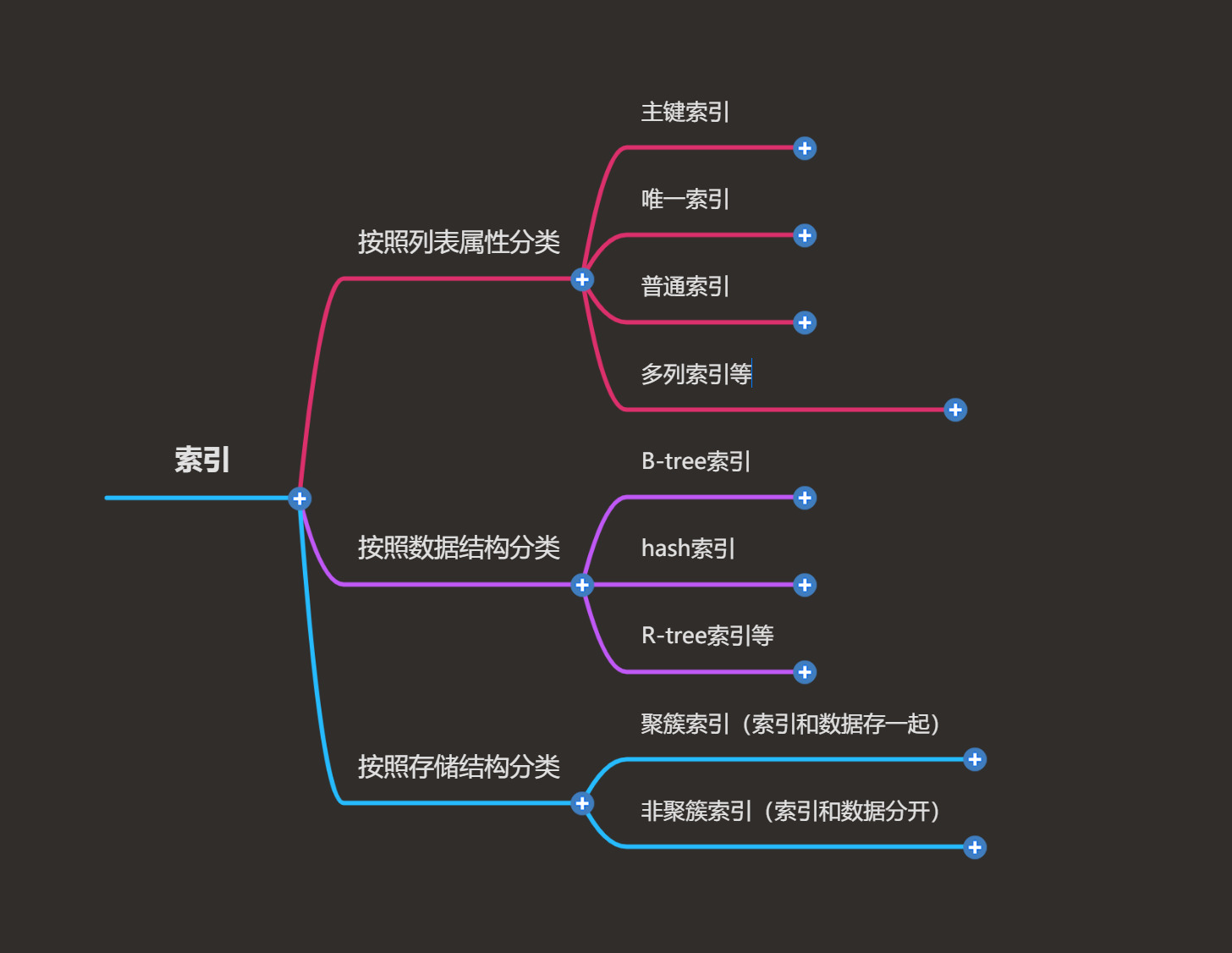
四、索引示例
示例1、主键索引(Primary Key Index)与 唯一索引(Unique Index)
- 主键索引是一种特殊的唯一索引,具有以下特点:
- 一张表只能有一个主键,用来唯一标识每一行数据。
- 主键列的值不能为 NULL,确保每行数据都有一个唯一的标识。
- 主键索引是表的物理排序顺序,通常会自动创建一个主键索引。
- 主键索引在查询中的速度很快,可以通过主键快速定位到唯一的行。
唯一索引 (Unique Index):
- 唯一索引是一种约束,确保索引列的值在整个表中是唯一的。
- 一张表可以有多个唯一索引,不同于主键索引的唯一之处在于允许 NULL 值(除非定义了 NOT NULL 约束)。
- 唯一索引可以用来确保数据的完整性,防止重复值的插入。
- 主键索引在定义上有更多的限制和特殊性,用途也不完全相同。主键索引一般用于唯一标识每一行数据,而唯一索引则用于确保某一列或多列的取值唯一性。
这里根据主键id查找,查看explain命令返回结果,挑两个参数看下
possible_keys: 显示了可能被查询用到的索引,这里显示了PRIMARY,即主键索引。type: const,表示使用了常量连接,这是最有效率的一种查询方式。key: 显示实际使用的索引,也是PRIMARY,即使用了主键索引。Extra: 显示了其他额外信息,这里是 "Using index",表示查询过程中使用了索引加速。

示例2、前缀索引(Prefix Index)
比如 trigger_msg是一个很长的文本字段,通常按照前缀进行查询,可以创建一个前缀索引
未加索引前查询

创建一个前缀索引,再次执行查询看看结果,显示走了索引
alter table xxl_job_log add index i_trigger_msg_prefix (trigger_msg(10));
type: range,表示在索引上进行范围扫描。possible_keys: 可能被查询用到的索引是i_trigger_msg_prefix。key: 实际使用的索引是i_trigger_msg_prefix。
示例3、联合索引(复合索引)
先对于group,id这两个列创建一个联合索引,看下结果是走了索引
alter table xxl_job_log add index i_job_group_job_id (job_group,job_id);

type: ref,表示使用了某个索引进行查找,返回匹配某个值的所有行。possible_keys: 可能被查询用到的索引是i_job_group_job_id。key: 实际使用的索引是i_job_group_job_id。
注意:
(1)最左前缀匹配原则:如果查询条件不是按照索引定义的顺序依次使用索引中的列,那么索引失效
比如,只用到了索引的第二个列,索引失效

如果只查第一个列 正常走索引

(2)覆盖索引:查询的列均有使用索引
这个查询使用了索引 i_job_group_job_id,通过索引进行了 ref 查找,同时使用了覆盖索引(Using index),这意味着查询可以直接从索引中获取所需的数据,而无需回表到主表,从而提高了查询效率,这就实现了覆盖索引,也是为什么不推荐 select * ... 的原因。覆盖索引能够显著减少磁盘I/O操作,从而极大提升查询性能。

五、索引失效场景(较多,演示两个实例)
1、主键索引:对主键列进行了计算操作

2、前缀索引:like通配符在开头

3、使用or关键字
4、使用范围查询中的not in/exists
5、索引列使用函数
文章到这里就结束了




![[linux]shell脚本语言:变量、测试、控制语句以及函数的全面详解](https://img-blog.csdnimg.cn/76b6806d36ed47b2a145cb9bf9e78dc9.png)