Pytorch从零开始实战——指定生成手势图像
本系列来源于365天深度学习训练营
原作者K同学
文章目录
- Pytorch从零开始实战——指定生成手势图像
- 环境准备
- 模型选择
- 模型训练
- 可视化分析
- 生成指定图像
- 总结
环境准备
本文基于Jupyter notebook,使用Python3.8,Pytorch2.0.1+cu118,torchvision0.15.2,需读者自行配置好环境且有一些深度学习理论基础。本次实验的目的是使用CGAN模型,完成手势图像生成并学习如何运用生成好的生成器生成指定图像。其余内容与上一篇文章差别不大。
第一步,导入常用包
import torch
import numpy as np
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.autograd import Variable
from torchvision.utils import save_image
from torchvision.utils import make_grid
from torch.utils.tensorboard import SummaryWriter
from torchsummary import summary
import matplotlib.pyplot as plt
查看设备对象
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
batch_size = 128
device # device(type='cuda')
使用transform调整数据集图像,本次数据集使用手势图像,用于生成对抗网络的训练。其中数据集源于K同学
train_transform = transforms.Compose([transforms.Resize(128),transforms.ToTensor(),transforms.Normalize([0.5,0.5,0.5], [0.5,0.5,0.5])])train_dataset = datasets.ImageFolder(root='./data/Gan3/rps/', transform=train_transform)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True,num_workers=6)
查看数据集图像
def show_images(images):fig, ax = plt.subplots(figsize=(20, 20))ax.set_xticks([]); ax.set_yticks([])ax.imshow(make_grid(images.detach(), nrow=22).permute(1, 2, 0))def show_batch(dl):for images, _ in dl:show_images(images)breakshow_batch(train_loader)

设置超参数
image_shape = (3, 128, 128) # 生成器和判别器操作的图像的形状
image_dim = int(np.prod(image_shape)) # 图像的总维度
latent_dim = 100 # 生成器的输入随机噪声向量的维度n_classes = 3 # 条件生成对抗网络中的类别数量
embedding_dim = 100 # 类别嵌入向量的维度
模型选择
条件生成对抗网络(CGAN)是一种生成对抗网络(GAN)的变体,它引入了条件信息以指导生成器生成特定类型的输出。在标准的生成对抗网络中,生成器的输入是一个随机噪声向量,而在条件生成对抗网络中,生成器的输入不仅包括随机噪声向量,还包括一个额外的条件向量,用于指定所需输出的特征。
例如我们需要生成器G生成一张没有阴影的图像,此时判别器D就需要判断生成器所生成的图像是否是一张没有阴影的图像。条件生成对抗网络的本质是将额外添加的信息融入到生成器和判别器中,其中添加的信息可以是图像的类别、人脸表情和其他辅助信息等,旨在把无监督学习的GAN转化为有监督学习的CGAN,便于网络能够在我们的掌控下更好地进行训练。
使用weights_init(m)对神经网络的权重进行初始化
# 自定义权重初始化函数,用于初始化生成器和判别器的权重
def weights_init(m):# 获取当前层的类名classname = m.__class__.__name__# 如果当前层是卷积层(类名中包含 'Conv' )if classname.find('Conv') != -1:# 使用正态分布随机初始化权重,均值为0,标准差为0.02torch.nn.init.normal_(m.weight, 0.0, 0.02)# 如果当前层是批归一化层(类名中包含 'BatchNorm' )elif classname.find('BatchNorm') != -1:# 使用正态分布随机初始化权重,均值为1,标准差为0.02torch.nn.init.normal_(m.weight, 1.0, 0.02)# 将偏置项初始化为全零torch.nn.init.zeros_(m.bias)
构建生成器,下面代码实现了一个生成器模型,它接受一个随机噪声向量和一个条件标签作为输入,并生成一个与条件标签相关的合成图像。首先,条件标签被嵌入到一个稠密向量中,将离散的标签映射到连续的嵌入空间,以便与噪声向量进行合并。接下来,从随机噪声向量中生成潜在向量。将噪声向量映射到一个更高维度的表示空间中,最后,将生成的条件标签嵌入向量和潜在向量在通道维度上合并。然后,将合并后的特征图通过一系列反卷积层进行处理,逐渐将其转换为与所需输出图像相同尺寸的特征图。
class Generator(nn.Module):def __init__(self):super(Generator, self).__init__()# 定义条件标签的生成器部分,用于将标签映射到嵌入空间中# n_classes:条件标签的总数# embedding_dim:嵌入空间的维度self.label_conditioned_generator = nn.Sequential(nn.Embedding(n_classes, embedding_dim), # 使用Embedding层将条件标签映射为稠密向量nn.Linear(embedding_dim, 16) # 使用线性层将稠密向量转换为更高维度)# 定义潜在向量的生成器部分,用于将噪声向量映射到图像空间中# latent_dim:潜在向量的维度self.latent = nn.Sequential(nn.Linear(latent_dim, 4*4*512), # 使用线性层将潜在向量转换为更高维度nn.LeakyReLU(0.2, inplace=True) # 使用LeakyReLU激活函数进行非线性映射)# 定义生成器的主要结构,将条件标签和潜在向量合并成生成的图像self.model = nn.Sequential(# 反卷积层1:将合并后的向量映射为64x8x8的特征图nn.ConvTranspose2d(513, 64*8, 4, 2, 1, bias=False),nn.BatchNorm2d(64*8, momentum=0.1, eps=0.8), # 批标准化nn.ReLU(True), # ReLU激活函数# 反卷积层2:将64x8x8的特征图映射为64x4x4的特征图nn.ConvTranspose2d(64*8, 64*4, 4, 2, 1, bias=False),nn.BatchNorm2d(64*4, momentum=0.1, eps=0.8),nn.ReLU(True),# 反卷积层3:将64x4x4的特征图映射为64x2x2的特征图nn.ConvTranspose2d(64*4, 64*2, 4, 2, 1, bias=False),nn.BatchNorm2d(64*2, momentum=0.1, eps=0.8),nn.ReLU(True),# 反卷积层4:将64x2x2的特征图映射为64x1x1的特征图nn.ConvTranspose2d(64*2, 64*1, 4, 2, 1, bias=False),nn.BatchNorm2d(64*1, momentum=0.1, eps=0.8),nn.ReLU(True),# 反卷积层5:将64x1x1的特征图映射为3x64x64的RGB图像nn.ConvTranspose2d(64*1, 3, 4, 2, 1, bias=False),nn.Tanh() # 使用Tanh激活函数将生成的图像像素值映射到[-1, 1]范围内)def forward(self, inputs):noise_vector, label = inputs# 通过条件标签生成器将标签映射为嵌入向量label_output = self.label_conditioned_generator(label)# 将嵌入向量的形状变为(batch_size, 1, 4, 4),以便与潜在向量进行合并label_output = label_output.view(-1, 1, 4, 4)# 通过潜在向量生成器将噪声向量映射为潜在向量latent_output = self.latent(noise_vector)# 将潜在向量的形状变为(batch_size, 512, 4, 4),以便与条件标签进行合并latent_output = latent_output.view(-1, 512, 4, 4)# 将条件标签和潜在向量在通道维度上进行合并,得到合并后的特征图concat = torch.cat((latent_output, label_output), dim=1)# 通过生成器的主要结构将合并后的特征图生成为RGB图像image = self.model(concat)return image
将模型导入GPU并初始化权重,查看模型
generator = Generator().to(device)
generator.apply(weights_init)
print(generator)

下面实现判别器模型,首先,条件标签(被嵌入到一个特征向量中。这一步类似于生成器中的过程,目的是将离散的标签映射到一个连续的嵌入空间,以便与图像特征进行合并。接下来,输入图像和嵌入的标签特征被拼接在一起作为鉴别器的输入。然后,这个输入通过一系列卷积层和批量归一化层进行处理,逐渐将其转换为一个用于区分真实和合成图像的特征表示。在每个卷积层之后,都跟随着 激活函数以及批量归一化层,最后,通过全连接层将特征向量映射到一个单一的输出。
class Discriminator(nn.Module):def __init__(self):super(Discriminator, self).__init__()# 定义一个条件标签的嵌入层,用于将类别标签转换为特征向量self.label_condition_disc = nn.Sequential(nn.Embedding(n_classes, embedding_dim), # 嵌入层将类别标签编码为固定长度的向量nn.Linear(embedding_dim, 3*128*128) # 线性层将嵌入的向量转换为与图像尺寸相匹配的特征张量)# 定义主要的鉴别器模型self.model = nn.Sequential(nn.Conv2d(6, 64, 4, 2, 1, bias=False), # 输入通道为6(包含图像和标签的通道数),输出通道为64,4x4的卷积核,步长为2,padding为1nn.LeakyReLU(0.2, inplace=True), # LeakyReLU激活函数,带有负斜率,增加模型对输入中的负值的感知能力nn.Conv2d(64, 64*2, 4, 3, 2, bias=False), # 输入通道为64,输出通道为64*2,4x4的卷积核,步长为3,padding为2nn.BatchNorm2d(64*2, momentum=0.1, eps=0.8), # 批量归一化层,有利于训练稳定性和收敛速度nn.LeakyReLU(0.2, inplace=True),nn.Conv2d(64*2, 64*4, 4, 3, 2, bias=False), # 输入通道为64*2,输出通道为64*4,4x4的卷积核,步长为3,padding为2nn.BatchNorm2d(64*4, momentum=0.1, eps=0.8),nn.LeakyReLU(0.2, inplace=True),nn.Conv2d(64*4, 64*8, 4, 3, 2, bias=False), # 输入通道为64*4,输出通道为64*8,4x4的卷积核,步长为3,padding为2nn.BatchNorm2d(64*8, momentum=0.1, eps=0.8),nn.LeakyReLU(0.2, inplace=True),nn.Flatten(), # 将特征图展平为一维向量,用于后续全连接层处理nn.Dropout(0.4), # 随机失活层,用于减少过拟合风险nn.Linear(4608, 1), # 全连接层,将特征向量映射到输出维度为1的向量nn.Sigmoid() # Sigmoid激活函数,用于输出范围限制在0到1之间的概率值)def forward(self, inputs):img, label = inputs# 将类别标签转换为特征向量label_output = self.label_condition_disc(label)# 重塑特征向量为与图像尺寸相匹配的特征张量label_output = label_output.view(-1, 3, 128, 128)# 将图像特征和标签特征拼接在一起作为鉴别器的输入concat = torch.cat((img, label_output), dim=1)# 将拼接后的输入通过鉴别器模型进行前向传播,得到输出结果output = self.model(concat)return output
将模型导入GPU并初始化权重,查看模型
discriminator = Discriminator().to(device)
discriminator.apply(weights_init)
print(discriminator)

模型训练
设置损失函数、优化算法和学习率
adversarial_loss = nn.BCELoss() def generator_loss(fake_output, label):gen_loss = adversarial_loss(fake_output, label)return gen_lossdef discriminator_loss(output, label):disc_loss = adversarial_loss(output, label)return disc_losslearning_rate = 0.0002G_optimizer = optim.Adam(generator.parameters(), lr = learning_rate, betas=(0.5, 0.999))
D_optimizer = optim.Adam(discriminator.parameters(), lr = learning_rate, betas=(0.5, 0.999))
开始训练
# 设置训练的总轮数
num_epochs = 300
# 初始化用于存储每轮训练中判别器和生成器损失的列表
D_loss_plot, G_loss_plot = [], []# 循环进行训练
for epoch in range(1, num_epochs + 1):# 初始化每轮训练中判别器和生成器损失的临时列表D_loss_list, G_loss_list = [], []# 遍历训练数据加载器中的数据for index, (real_images, labels) in enumerate(train_loader):# 清空判别器的梯度缓存D_optimizer.zero_grad()# 将真实图像数据和标签转移到GPU(如果可用)real_images = real_images.to(device)labels = labels.to(device)# 将标签的形状从一维向量转换为二维张量(用于后续计算)labels = labels.unsqueeze(1).long()# 创建真实目标和虚假目标的张量(用于判别器损失函数)real_target = Variable(torch.ones(real_images.size(0), 1).to(device))fake_target = Variable(torch.zeros(real_images.size(0), 1).to(device))# 计算判别器对真实图像的损失D_real_loss = discriminator_loss(discriminator((real_images, labels)), real_target)# 从噪声向量中生成假图像(生成器的输入)noise_vector = torch.randn(real_images.size(0), latent_dim, device=device)noise_vector = noise_vector.to(device)generated_image = generator((noise_vector, labels))# 计算判别器对假图像的损失(注意detach()函数用于分离生成器梯度计算图)output = discriminator((generated_image.detach(), labels))D_fake_loss = discriminator_loss(output, fake_target)# 计算判别器总体损失(真实图像损失和假图像损失的平均值)D_total_loss = (D_real_loss + D_fake_loss) / 2D_loss_list.append(D_total_loss)# 反向传播更新判别器的参数D_total_loss.backward()D_optimizer.step()# 清空生成器的梯度缓存G_optimizer.zero_grad()# 计算生成器的损失G_loss = generator_loss(discriminator((generated_image, labels)), real_target)G_loss_list.append(G_loss)# 反向传播更新生成器的参数G_loss.backward()G_optimizer.step()# 打印当前轮次的判别器和生成器的平均损失print('Epoch: [%d/%d]: D_loss: %.3f, G_loss: %.3f' % ((epoch), num_epochs, torch.mean(torch.FloatTensor(D_loss_list)), torch.mean(torch.FloatTensor(G_loss_list))))# 将当前轮次的判别器和生成器的平均损失保存到列表中D_loss_plot.append(torch.mean(torch.FloatTensor(D_loss_list)))G_loss_plot.append(torch.mean(torch.FloatTensor(G_loss_list)))if epoch%10 == 0:# 将生成的假图像保存为图片文件save_image(generated_image.data[:50], './images/sample_%d' % epoch + '.png', nrow=5, normalize=True)# 将当前轮次的生成器和判别器的权重保存到文件torch.save(generator.state_dict(), './training_weights/generator_epoch_%d.pth' % (epoch))torch.save(discriminator.state_dict(), './training_weights/discriminator_epoch_%d.pth' % (epoch))

可视化分析
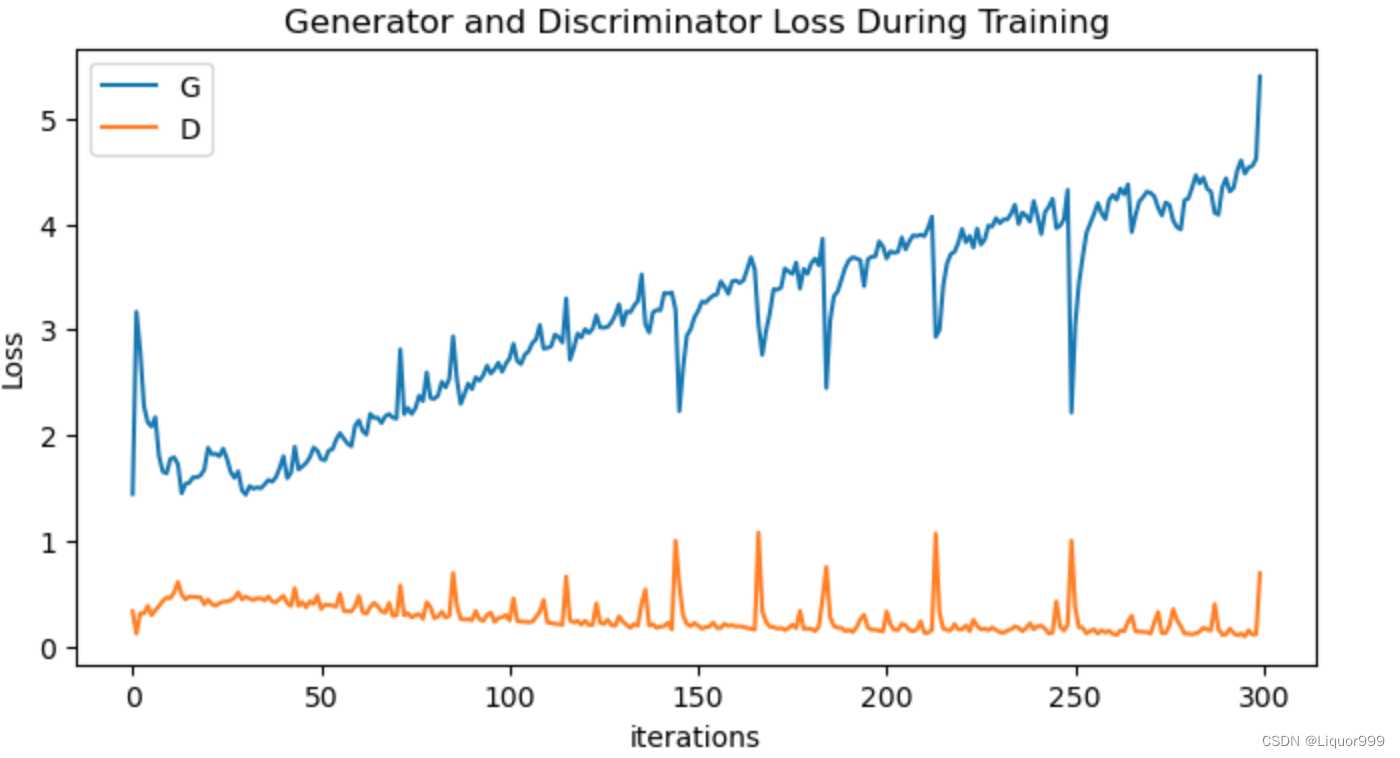
查看模型训练过程
G_loss_list = [i.item() for i in G_loss_plot]
D_loss_list = [i.item() for i in D_loss_plot]import matplotlib.pyplot as plt
#隐藏警告
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 #分辨率plt.figure(figsize=(8,4))
plt.title("Generator and Discriminator Loss During Training")
plt.plot(G_loss_list,label="G")
plt.plot(D_loss_list,label="D")
plt.xlabel("iterations")
plt.ylabel("Loss")
plt.legend()
plt.show()
生成指定图像
使用训练好的生成器模型在给定潜在空间点和标签的情况下生成图像,并将生成的图像显示出来。将手势标签设置为1,接着将随机点和标签传递给生成器模型,生成相应的图像。
# 导入所需的库
from numpy.random import randint, randn
from numpy import linspace
from matplotlib import pyplot, gridspec# 导入生成器模型
generator.load_state_dict(torch.load('./training_weights/generator_epoch_300.pth'), strict=False)
generator.eval() interpolated = randn(100) # 生成两个潜在空间的点
# 将数据转换为torch张量并将其移至GPU(假设device已正确声明为GPU)
interpolated = torch.tensor(interpolated).to(device).type(torch.float32)label = 1 # 手势标签,可在0,1,2之间选择
labels = torch.ones(1) * label
labels = labels.to(device).unsqueeze(1).long()# 使用生成器生成插值结果
predictions = generator((interpolated, labels))
predictions = predictions.permute(0,2,3,1).detach().cpu()plt.figure(figsize=(8, 3))pred = (predictions[0, :, :, :] + 1 ) * 127.5
pred = np.array(pred)
plt.imshow(pred.astype(np.uint8))
plt.show()

总结
本次实验将CGAN模型又重新复习了一遍,并且使用训练好的生成器模型指定生成对象。由于生成器模型的训练是在一个带有手势标签的数据集上进行的,这使得生成器可以学会生成具有特定手势的图像。
手势标签被设定为 1,并且将这个标签传递给了生成器模型后,生成器模型在生成图像时考虑了这个标签,因此生成的图像会具有与该标签对应的手势特征。