MySQL-查询SQL语句的执行过程:连接器->查询缓存<8就没了>->分析器->优化器->执行器->返回结果
- 查询SQL语句的执行过程
- 1、主要步骤
- 2、实用案例
查询SQL语句的执行过程
1、主要步骤
在MySQL中,一条查询SQL语句的执行过程非常复杂且精细,可以分为以下几个主要步骤:
连接->查询缓存(8就没了)->分析->优化->执行->返回结果
1、连接器(Connection Handler)阶段:
- 客户端应用程序首先与MySQL服务器建立TCP连接。连接请求到达后,MySQL的连接器模块负责验证客户端的身份和权限。
- 如果用户提供了正确的用户名、密码及数据库名,连接器会分配一个线程来处理这个连接,并根据账户的权限信息确定该用户对哪些数据库或表具有访问权限。
2、查询缓存(Query Cache)阶段(已废弃自MySQL 8.0开始):
- 在MySQL早期版本中,如果连接器完成授权后发现这是一个SELECT查询,它会首先查看查询缓存(假设查询缓存功能启用)。
- 查询缓存的工作原理是,如果之前有完全相同的SQL查询并且结果已经存储在缓存中,则直接返回缓存中的结果,跳过后续的所有执行阶段,从而提高性能。
- 然而,由于查询缓存带来的维护成本和实际收益并不总是成正比,在高并发或者数据更新频繁的情况下,缓存命中率低且可能导致大量的无效缓存失效,所以在MySQL 8.0之后的版本中移除了查询缓存功能。
3、分析器(Parser)阶段:
- 当查询无法从缓存中获取时,MySQL将对SQL文本进行词法分析和语法分析。
词法分析:将SQL字符串拆解成一个个代表不同成分的符号(Token),比如关键词、标识符、常量值等。语法分析:根据MySQL SQL语法规则检查这些符号组成的序列是否符合语法规则,形成解析树。
4、优化器(Optimizer)阶段:
- 经过分析器确认SQL语句合法后,优化器会对执行计划进行选择,决定如何最优地执行查询操作。
- MySQL通常提供多种可能的执行计划,如索引的选择、表的扫描顺序、JOIN操作的方式等。(可以
explain查看) - 优化器通过成本估算模型(基于统计信息)选择预期成本最低的执行计划。
5、执行器(Executor)阶段:
- 根据优化器生成的执行计划,执行器开始读取数据并进行相应的运算。
- 执行过程中,执行器会根据需要对涉及到的数据行加锁,对于可重复读(REPEATABLE READ)事务隔离级别下的InnoDB存储引擎,还会应用Next-Key Locks来防止幻读。
- 对于涉及多表查询的操作,执行器按照JOIN条件逐步从每个表中检索符合条件的数据行。
6、返回结果集:
- 当执行器完成了所有数据检索和计算后,将结果集返回给客户端。
2、实用案例
笔者用的是MySQL8.0
-- 创建 customers 表
CREATE TABLE customers (id INT PRIMARY KEY, country VARCHAR(255) NOT NULL
);-- 创建 orders 表
CREATE TABLE orders (order_id INT PRIMARY KEY, customer_id INT, order_date DATE NOT NULL, FOREIGN KEY (customer_id) REFERENCES customers(id)
);-- 插入数据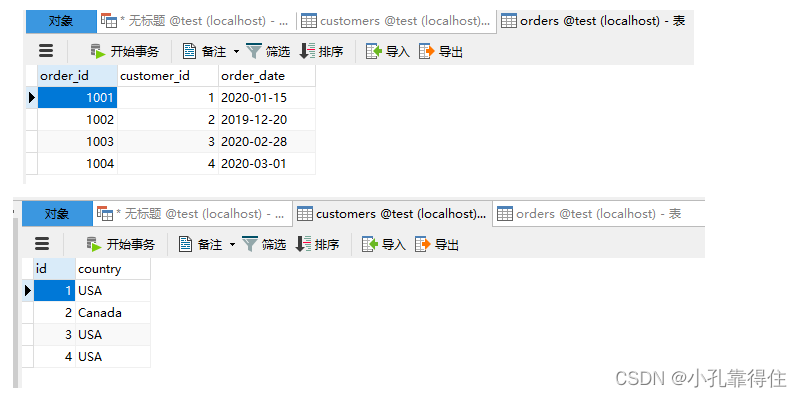
SELECT * FROM orders JOIN customers ON orders.customer_id = customers.id WHERE customers.country = 'USA' AND orders.order_date >= '2020-01-01';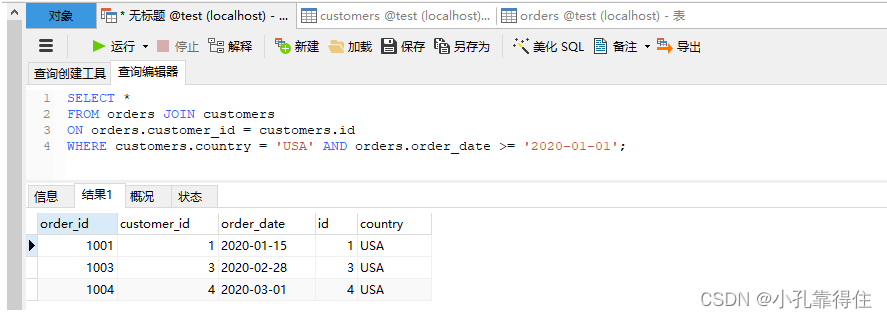
explain一下
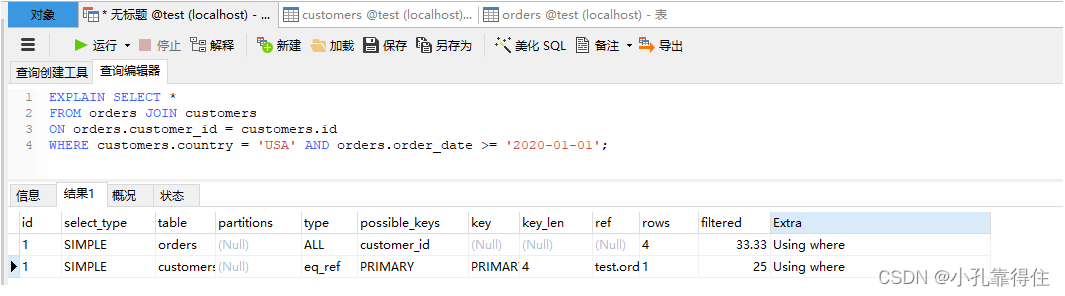
针对这条SQL查询:
- 连接器会验证用户的登录信息以及对orders和customers表是否有查询权限。
- 分析器解析SQL,识别出这是个SELECT查询,并正确理解JOIN和WHERE子句的含义。
- 优化器评估使用哪个索引更高效(例如customers.country上的索引或者orders.order_date上的索引,甚至考虑联合索引),并决定JOIN的顺序。
- 执行器根据优化器的决策锁定相关行,从customers表中找到国家为’USA’的客户记录,然后根据customer_id关联到orders表中对应的订单记录,最后筛选出2020年1月1日以后的订单。
- 在整个过程中,MySQL服务器确保了并发控制的一致性和安全性,同时尽可能地优化查询效率。
MySQL-查询SQL语句的执行过程:连接器->查询缓存(8就没了)->分析器->优化器->执行器->返回结果 到此完结,笔者归纳、创作不易,大佬们给个3连再起飞吧