😎😎😎物体检测-系列教程 总目录
有任何问题欢迎在下面留言
本篇文章的代码运行界面均在Pycharm中进行
本篇文章配套的代码资源已经上传
点我下载源码
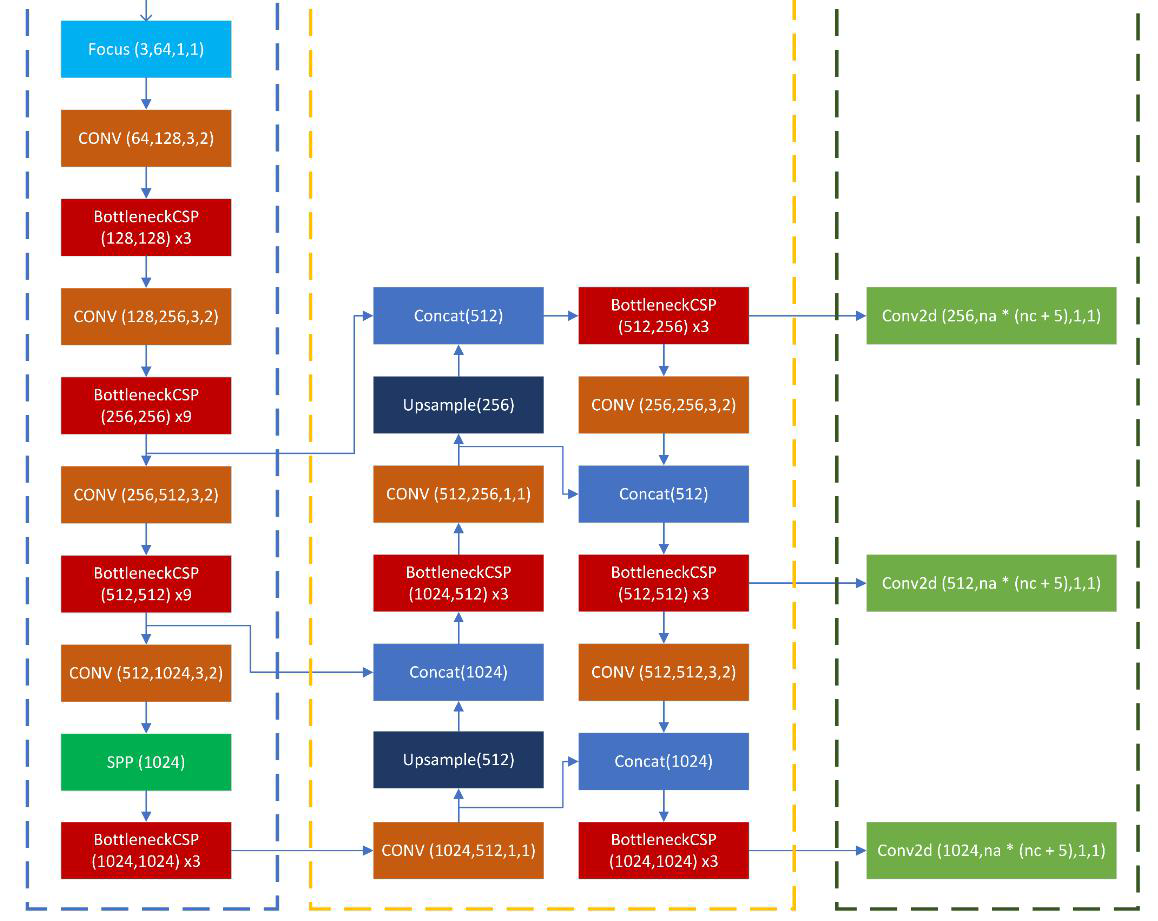
17、SPP模块
17.1 SPP类
SPP是一种特殊的池化策略,最初在YOLOv3-SPP中被使用,旨在提高模型对于不同尺寸输入的适应性,通过对同一特征图进行不同尺寸的池化,然后将这些池化后的特征图拼接起来,增加了模型捕捉不同尺度特征的能力
class SPP(nn.Module):# Spatial pyramid pooling layer used in YOLOv3-SPPdef __init__(self, c1, c2, k=(5, 9, 13)):super(SPP, self).__init__()c_ = c1 // 2 # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1)self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])def forward(self, x):x = self.cv1(x)return self.cv2(torch.cat([x] + [m(x) for m in self.m], 1))
- 继承nn.Module
- 构造函数,传入3个参数:输入通道c1、输出通道c2、不同池化核的大小元组k(包含三个整数,表示特征金字塔池化中不同池化核的大小)
- 初始化
- c_,计算中间层的通道数,即通道数减半
- cv1 ,定义一个卷积模块,通道数从c1降到c_
- cv2,定义一个卷积模块,输入通道数为c_ * (len(k) + 1),这是因为SPP层将原始特征图与len(k)个池化后的特征图拼接,因此增加了通道数。该卷积层的作用是将拼接后的特征图降维到输出通道数c2
- m,m是一个模块列表,相当于是pytorch对应的list,是专门用来保存pytorch中的模型的list,m包含三个最大池化层,每个池化层的核大小分别为k元组中的值。步长设置为1,并且填充(padding)设置为kernel_size // 2,这样做是为了保持特征图的尺寸不变
- 前向传播
- x,将输入经过一个卷积模块
- 将前面的输出和前面输出经过一个包含3个池化层的模块分别进行拼接,拼接的结果再经过一个卷积模块,返回结果
SPP模块通过特征金字塔池化技术增强了模型对不同尺度特征的捕捉能力。通过在不改变特征图空间维度的前提下增加通道维度信息,SPP可以有效提升模型的性能
17.2 Flatten类
class Flatten(nn.Module):# Use after nn.AdaptiveAvgPool2d(1) to remove last 2 dimensions@staticmethoddef forward(x):return x.view(x.size(0), -1)
- 继承nn.Module
- 一个Python装饰器,表示是一个静态方法,静态方法不需要实例化即可调用,它不依赖于类的实例变量
- 前向传播,被装饰圈重写
- 返回执行压平操作的输出
17.3 Concat类
class Concat(nn.Module):def __init__(self, dimension=1):super(Concat, self).__init__()self.d = dimensiondef forward(self, x):return torch.cat(x, self.d)
- 继承nn.Module
- 构造函数,传入一个在哪个维度进行拼接的参数
- 初始化
- d,拼接维度
- 前向传播
- 返回拼接
17.4 Classify类
class Classify(nn.Module):def __init__(self, c1, c2, k=1, s=1, p=None, g=1): super(Classify, self).__init__()self.aap = nn.AdaptiveAvgPool2d(1) # to x(b,c1,1,1)self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False) # to x(b,c2,1,1)self.flat = Flatten()def forward(self, x):z = torch.cat([self.aap(y) for y in (x if isinstance(x, list) else [x])], 1) # cat if listreturn self.flat(self.conv(z)) # flatten to x(b,c2)
- 继承nn.Module
- 构造函数,传入输入通道c1、输出c2、卷积核尺寸k=1*1、卷积步长s=1、padding、卷积分组g
- 初始化
- aap,定义一个全局自适应平均池化层
- conv,定义一个卷积层,padding通过调用autopad函数动态计算,不要偏执
- flat,调用一个展平模块
- 前向传播
- z,检查输入x是否为列表:如果是,对列表中的每个元素应用自适应平均池化层aap;如果不是,将x转换为列表后应用aap。然后,在维度1上拼接处理后的特征图,以支持多输入的情况
- 进行一个卷积操作后再展平,返回输出
Classify类实现了一个通用的分类头结构,它通过一个自适应平均池化层和一个卷积层将输入特征图转换为一维特征向量,适用于各种分类任务。此外,它通过处理输入列表的能力,为处理多输入或合并来自不同源的特征提供了便利。这种灵活性和效率是深度学习模型在图像分类任务中常见的要求
17.5 辅助函数
autopad用于自动计算卷积层的填充,输出特征图的尺寸与输入相同
def autopad(k, p=None): # kernel, padding# Pad to 'same'if p is None:p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-padreturn p- 接受两个参数:k卷积核大小,p填充量。如果p没有显式提供(即为None),则该函数将计算并返回一个"自动"填充值,使得卷积操作的输出特征图在空间尺寸上与输入特征图相同
- 检查是否提供了p参数,如果没有,则进入自动计算填充的逻辑
- 这行是自动计算填充量的核心逻辑。如果k是整数(标准情况下,表示卷积核大小是正方形),则p被设置为
k // 2。如果k是一个序列(表示卷积核可能是矩形),则对k中的每个元素进行同样的操作,计算出一个填充量列表 - 返回计算出的填充量p
DWConv,一个深度可分离卷积层,一种高效的卷积实现方式,能够减少参数数量和计算成本
def DWConv(c1, c2, k=1, s=1, act=True):# Depthwise convolutionreturn Conv(c1, c2, k, s, g=math.gcd(c1, c2), act=act)
- 这个函数定义了一个深度可分离卷积层。c1是输入通道数,c2是输出通道数,k是卷积核大小,默认为1,s是步长,默认为1,act标志是否使用激活函数,默认为True
- 返回一个Conv对象,Conv是一个包含二维卷积、激活函数、归一化的卷积模块