前缀和
简介
先来简单看一个场景。现在有一个公交车,第一站上了4个人,第二站上了7个人,第三站上了1个人,第四站上了5个人,问一共上了多少人?

答案很显而易见,只需要遍历这个数组,把所有元素加起来就可以了。
但是,如果我们想多次查询,中间的某几站上了多少人,如果还采用全部加起来的解法,这个时间复杂度就直接上到O(nk)去了。我们能不能让每次查询的时间复杂度都为O(1)呢?
答案也很简单。我们先将所有的数据进行预处理,把每一站公交车上还剩多少人都保存起来,这样求两站之间上了多少人,只需要将两站之间车上的人数作差就可以了。而虽然耗费了O(n)的空间,但是将单次查询的时间复杂度降为了O(1),总时间复杂度降为了O(k),典型的空间换时间的方法。

而这种思想,就是我们常说的——前缀和。
一维前缀和
一维前缀和就和刚刚所说的场景一样,我们有一段很长很长的数组,但是我们想求出任意一段数组区间的和,每次都暴力加起来自然可行,但是时间复杂度直接上到了O(n^2)。想要优化,自然想到的就是刚刚的方法:

证明方法就不多作解释了,小学生都会。
同时,我们在预处理这个前缀和数组的时候,也没有必要每一次都采用累加的方法。这里稍微用了一点点动态规划的皮毛,我们来看前缀和数组prefix[i]和prefix[i-1]的关系

所以对一个一维数组,预处理前缀和的方式:
而在预处理完前缀和数组后,查询任意一段区间的时间复杂度就变为了O(1)
一维前缀和的哈希优化
尽管这种方法看着美好,但是遇到另一个问题,又会显得有些棘手:
 食德,前缀和虽然可以解决查询任意一个区间的和,但是如果要通过和来反向找区间,那时间复杂度又是暴力遍历的O(n^2),难道没有其他解决方案了吗?
食德,前缀和虽然可以解决查询任意一个区间的和,但是如果要通过和来反向找区间,那时间复杂度又是暴力遍历的O(n^2),难道没有其他解决方案了吗?
当然有,我们首要想到的方法便是,把所有的和放入哈希表中,然后再去遍历整个前缀和数组,这样每个元素的查询就变成了O(1),总的时间复杂度也就降为了O(n)。
听不懂很正常,接下来详细讲一讲这个过程:
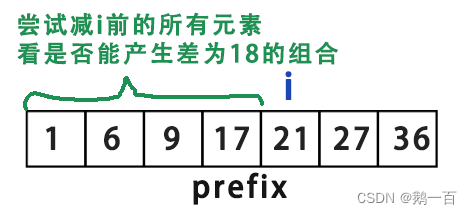
还是原来的数组,我们现在已知前缀和数组,想找到和为18的区间 j 到 i,也就是找到一对 i 和 j,使得前缀和数组
但是,如果按照暴力解法,那就是遍历所有数组的时候,遍历到中间某个位置i,尝试所有的0到i-1位置上的元素,看是否能产生差为18的组合
这个查询复杂度显然是O(n),如果要降为O(1),最好的方法就是哈希表。
哈希表中的键对值<key,val>为<sum,place>,sum为出现过的前缀和,而place为按题目要求 记录该前缀和第一次出现的位置 或者 最后一次出现的位置
先用哈希表将 i 前的所有前缀和存储起来,我们想找到
,转换一下,也就是找到 i 前面是否有 j 使得
也就是说,只需要判断元素prefix[i]-18是否在哈希表中,如果存在,则代表i之前有满足条件的子数组;如果不存在,则代表i之前没有满足条件的子数组。
如果找到了,hash[prefix[i]-18],便是需求数组的左端点,而i就是右端点
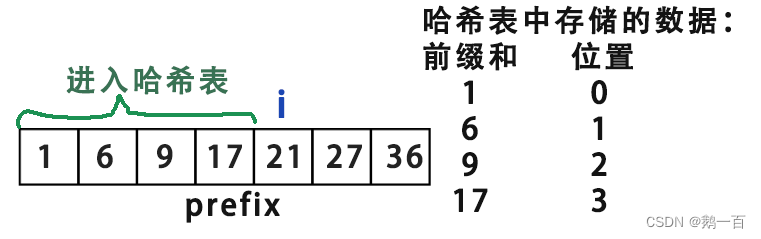
哈希表的查询时间复杂度是O(1),哈希表本身的大小是O(n),也就是在没有过多影响空间复杂度的情况下,大大提升了效率。
而通过这个方法,我们来解一道经典的题:(最好自己先尝试做一做)
经典例题
LCR 010. 和为 K 的子数组 - 力扣(LeetCode)![]() https://leetcode.cn/problems/QTMn0o/description/?envType=list&envId=87dIC4Q4
https://leetcode.cn/problems/QTMn0o/description/?envType=list&envId=87dIC4Q4

和我们刚刚说的情况几乎没有什么差别,所以就不多对题目进行解释。
解题思路:
拿到这个题目,第一想法就是先把前缀和数组撸出来。
int n=nums.size();vector<int> prefix(n);
prefix[0]=nums[0];for(int i=1;i<n;i++)prefix[i]=prefix[i-1]+nums[i];
食德,你无敌了孩子,求前缀和数组就是公式。
然后再来看题目,要求子数组和为k的个数,甚至比刚刚所讲的求出长度更加简单。
我们在遍历的时候,实际上是要求前缀和为sum的子数组个数,于是哈希表的键对值<key,val>为<sum,time>,sum代表出现过的前缀和,time代表该前缀和出现过的次数。
 同时,我们一边插入,一边搜索,如果有满足条件的就让结果加上哈希表中key对应的值
同时,我们一边插入,一边搜索,如果有满足条件的就让结果加上哈希表中key对应的值

但是,我们明显漏掉了一种情况:当遍历到2时,就要找哈希表中出现过几个2-2=0。虽然哈希表中出现过0次,但是子数组[1,1]显然也是满足条件的。所以,其实我们漏掉的情况便是,当数组中没有元素时的前缀和。故而我们初始化的时候要加上hash[0]=1
unordered_map<int,int> hash;//键对值为前缀和sum和出现的次数time
hash[0]=1;//初始化0
int ret=0;for(int i=0;i<prefix.size();i++)
{if(hash.find(prefix[i]-k)!=hash.end())//看前缀和数组中是否有ret+=hash[prefix[i]-k];//如果有返回值就加上hash.insert(prefix[i]);
}
解题代码:
class Solution {
public:int subarraySum(vector<int>& nums, int k) {unordered_map<int,int> hash;hash[0]=1;int sum=0;//把前缀和数组也优化掉了,但是优不优化都不会太影响空间复杂度int ret=0;for(int i=0;i<nums.size();i++){sum+=nums[i];if(hash.find(sum-k)!=hash.end())ret+=hash[sum-k];hash[sum]++;}return ret;}
};公式
看到一维前缀和的题,不管那么多,直接先把前缀和数组撸出来。
然后,根据题目要求构建哈希表。
在遍历的时候,一边对之前的元素进行查找,一边在哈希表中插入当前的元素。一定要一边查找一边插入,如果全部插入完再查找,后面才会出现的前缀和也会在前面的计算中加入,最终导致结果增多。
而哈希表的键对值一般来说只有两种:
- <sum,place> 存储前缀和与其对应的第一次或最后一次出现的位置
- <sum,time> 存储前缀和与其出现的次数
按照题目要求构建哈希表,就可以解决大部分问题。
二维前缀和
二维前缀和,就是在一维前缀和的基础上,将数组变为二维数组,然后求二维数组中某个区间的和。

不要被这个样子吓到,其实解决问题的方法还是一样的。
我们知道,一维数组的前缀和,是从0到i中所有元素的和。同理,到了二维,那么就是从(0,0)到(i,j)中,所有元素的和。无论是三维还是四维,分析方式都是一样的,以一个点为基准点,计算出每一个点到他所形成的区间的前缀和。
既然这样,那么计算前缀和的方式自然不可能累加。我们还是稍微使用一下动态规划的思想,找到每一个位置和其相邻位置之间的关系。
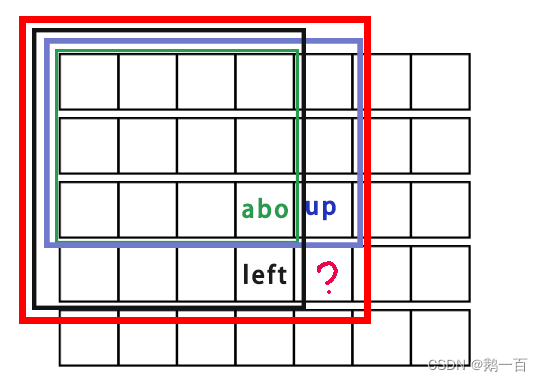
虽然这个图有点抽象,但是我们不难发现
- left黑色的区域+up蓝色的区域,中间重叠了above绿色的区域
- 红色的区域,正好包括了left,up,above三个区域,同时多出来了一小块区域
- 多出来的区域正好是nums[i][j]
于是,我们便可以通过数学关系推出来:
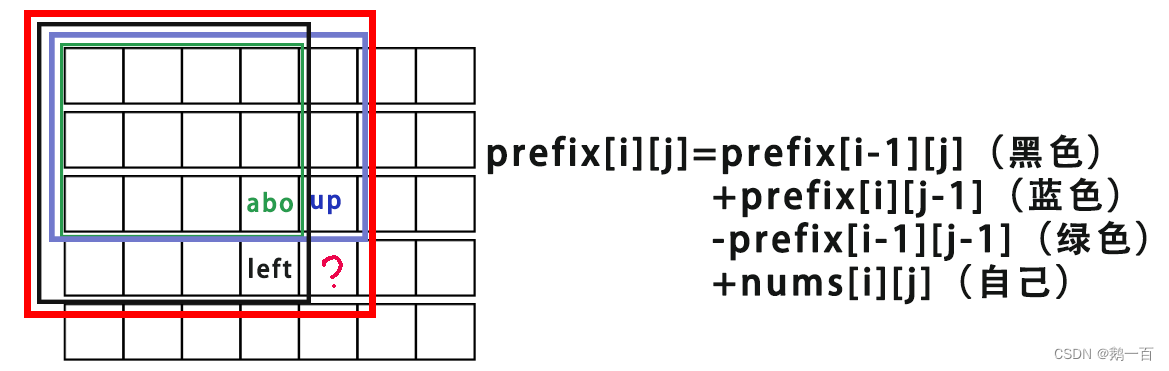
但是很明显,当i=0或者j=0时,这个表达式会越界。在一维的时候,我们的解决方案是手动初始化,但是二维手动初始化不免有些麻烦。所以我们采用动态规划最常用的一种方法:多开一行一列
//假设原二维数组为vector<vector<int>> nums
int row=nums.size();//行
int col=nums[0].size();//列vector<vector<int>> prefix(row+1,vector<int>(col+1));for(int i=1;i<row+1;i++)
{for(int j=1;j<col+1;j++){prefix[i][j]=prefix[i-1][j]+prefix[i][j-1]-prefix[i-1][j-1]+nums[i-1][j-1];//注意多开了一行一列,所以前缀和数组和原数组的映射发生了变化}
}
//预处理完毕那有人可能就要问了,海老师海老师,预处理完这个数组之后怎么求区间和呢?
和求前缀和一样的思想,还是看区间的关系。最终可以得到表达式:

用这个思想,这个题目便不在话下1314. 矩阵区域和 - 力扣(LeetCode)
抽象前缀和
如果前缀和只能解决这些求和的问题,那研究前缀和就真没什么意义了。前缀和还在其他场景中,将一个其他的问题转换为前缀和的问题,然后用前缀和的方法公式解决。
1124. 表现良好的最长时间段 - 力扣(LeetCode)![]() https://leetcode.cn/problems/longest-well-performing-interval/description/
https://leetcode.cn/problems/longest-well-performing-interval/description/

如果说,这个一看就是动态规划,与前缀和八竿子打不着的题目,要用前缀和的方法来解决,你信吗?
题目解析
这是一道及其抽象的题目。给一个数组,如果某一个元素大于8,那么这个元素就是good;否则元素就是bad。对一个子数组,其中good的数量大于bad的数量,求满足条件的子数组最长的长度为多少。
 一看子数组,oh,dp问题。但是,我们可以将其巧妙转换为前缀和的问题:
一看子数组,oh,dp问题。但是,我们可以将其巧妙转换为前缀和的问题:
问题转化
我们发现,不管题目描述多花里胡哨,但是最终只想说一句话:数组里的元素只有两个状态。
这里的状态不是动态规划里所说的状态,而就是我们日常里所说的状态——两种元素具有不同的性质。
我们不妨就按照题目的意思,把两个状态分别定义为1和-1,1代表大于8的元素,-1代表不大于8的元素,然后把整个数组修改一下:
for(auto& e:hours)e=e>8?1:-1;有什么用?我们再来看整个数组:
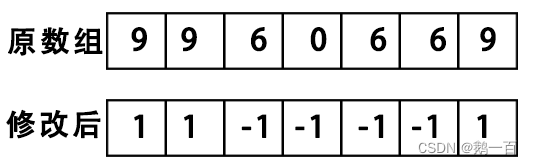
而题目意思,要求good大于bad的最长子数组,我们修改完数组以后,问题是不是就变成了,和大于0的最长子数组

此刻,这个问题就转换为了一个前缀和的问题,而通过一维前缀和的哈希优化那里的知识,我们便能完美解决这个问题:
- 哈希表:sum,place型,place为sum第一次出现的位置
- 重置数组种的所有元素为1和-1
- 撸出前缀和数组
- 根据题目要求,遍历一次,over
解题代码
class Solution {
public:int longestWPI(vector<int>& hours) {unordered_map<int,int> hash;//sum,place型hash[0]=-1;for(auto& e:hours){if(e>8) e=1;else e=-1;}int sum=0;//优化了前缀和数组,优不优化一样int ret=0;//返回值for(int i=0;i<hours.size();i++){sum+=hours[i];if(sum>0)//如果sum大于0,表示从0到现在所有元素都满足条件,直接就为到i为止的所有元素ret=max(ret,i+1);else if(hash.count(sum-1))//如果sum小于0,找到极限情况sum-1的位置ret=max(ret,i-hash[sum-1]);if(hash.find(sum)==hash.end())hash[sum]=i;//如果哈希表中已经有了该元素,因为要求第一个出现的元素,所以不能修改值//只有在哈希表中没有该元素的时候,再去插入这个值}return ret;}
};总结和公式
很多看似不是前缀和的问题,但是如果数组中只有两个状态,要求某个满足某条件区间的长度,完全可以将两个状态定义为1和-1,然后再去用前缀和的思想来解决。在一些个别情况,有三个状态,也可以转换成1,0,-1,再来用前缀和解决。
- 观察是否只有两个状态的元素数组,是否求某个区间的长度或个数
- 将两个状态分别转化成1和-1
- 用一维前缀和的哈希优化那里的方法来解决问题
懂了?再把这题解决到掉,LCR 011. 连续数组 - 力扣(LeetCode)