领取资料,咨询答疑,请➕wei: June__Go
上一小节,我们学习了requests的HTTPS请求方法,本小节我们讲解一下在requests文件上传与下载。
文件上传
使用requests库上传文件时,需要使用files参数,并将文件打开并读取为二进制格式。以下是使用requests库上传文件的示例:
import requestsurl = 'https://www.example.com/api/upload'
files = {'file': open('example.txt', 'rb')}
response = requests.post(url, files=files)
print(response.json())在上面的示例中,我们使用requests库发送了一个POST请求到https://www.example.com/api/upload,并使用files参数上传了example.txt文件。然后,我们使用json()方法获取响应的JSON格式内容。
文件下载
1、小型文件
使用requests库下载小型文件时,需要使用get方法,并将文件保存到本地。以下是使用requests库下载文件的示例:
import requestsurl = 'https://www.example.com/api/download'
response = requests.get(url)
with open('example.txt', 'wb') as f:f.write(response.content)在上面的示例中,我们使用requests库发送了一个GET请求到https://www.example.com/api/download,并将响应的内容保存到本地的example.txt文件中。
需要注意的是,使用requests库下载文件时,需要使用二进制模式打开文件,并将响应的内容保存到文件中。
2、大型文件
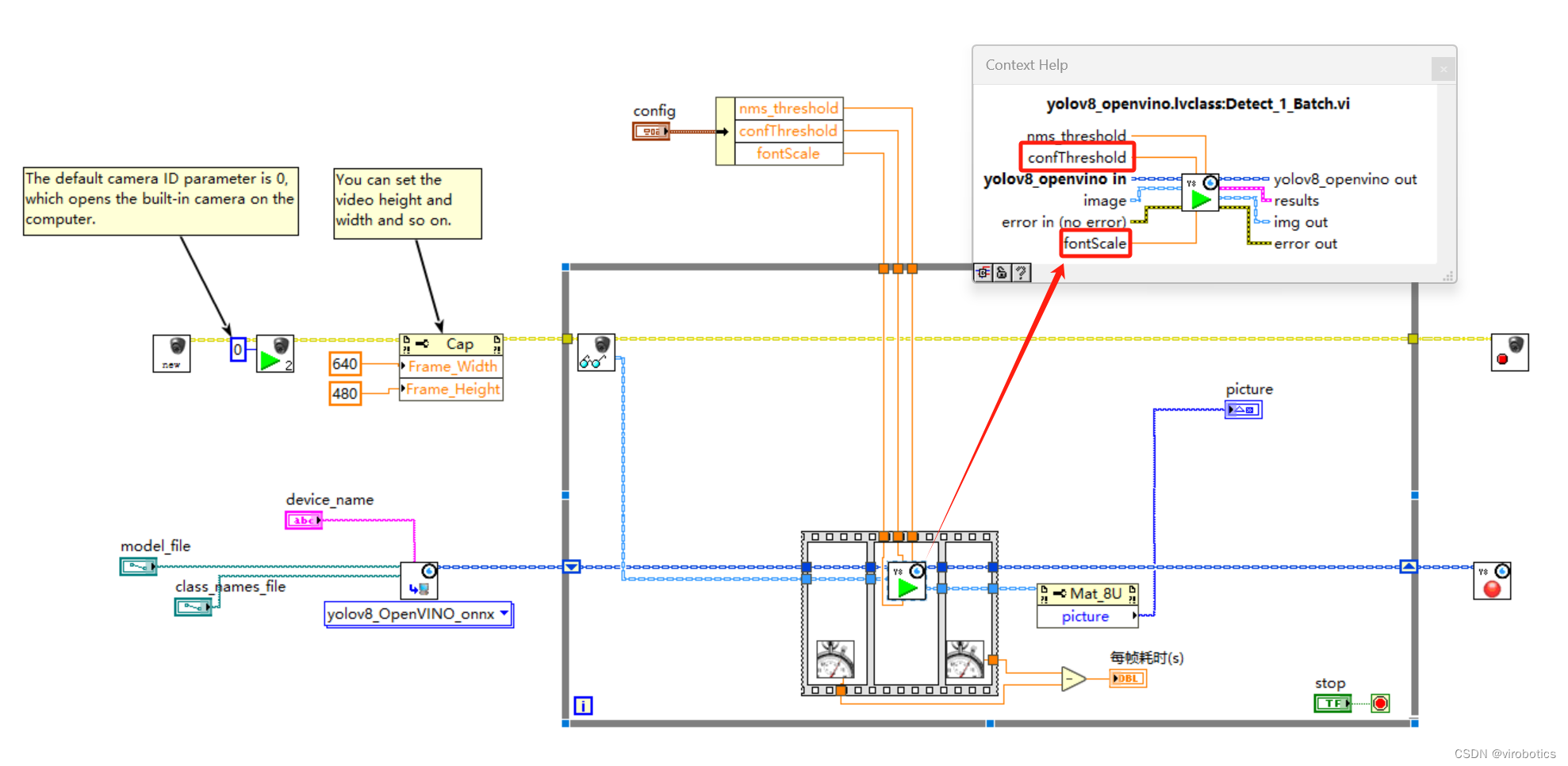
那么在有些情况下所下载的文件可能会有几十G这么大,而直接读取内容的话耗费时间也太长了,并且会一直占用大量内容和系统资源。所以下载大型文件时需要用到stream参数,它的作用就是将先创建连接。然后只有再调用特定方法时才开始下载文件,并且每次下载都不会超过设定好的内容上限,代码如下:
import requestsurl = 'https://www.example.com/api/download'
r = requests.get(url, stream=True)
f = open("example.txt", "wb")
#循环去读取信息写入,chunk_size=512文件大小
for chunk in r.iter_content(chunk_size=512):if chunk:#把循环读取的值,写入example.txt文件f.write(chunk)最后感谢每一个认真阅读我文章的人,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走,希望可以帮助到大家!领取资料,咨询答疑,请➕wei: June__Go