简介
在本文中,我们将介绍如何在分布式系统中使用transaction以及分布式系统中transaction的局限性。然后我们通过一个具体的例子,介绍了一种通过设计状态机来避免使用transaction的方法。
什么是数据库transaction
Transaction是关系型数据普遍支持的一种操作。Transaction可以包含若干对数据库的操作。如果任何操作失败,所有的操作都被取消,数据保持transaction执行前的状态。这种情况叫回滚(rollback)。假如所有操作成功,transaction被认为成功。这种情况叫做提交(commit)。Transaction需要支持所谓的ACID。因为我们这种主要介绍NO-SQL数据库的transaction,ACID就不详细说了,如果不熟悉大家可以自行阅读。Transaction对于维护数据的完整性非常重要。比如说对于在两个银行账户之间的转账操作,从一个账户扣除金额和向一个账户增加金额就应该放在一个transaction里。否则只完成了扣除操作或者只完成增加操作,都会破坏数据的完整性,恢复起来非常麻烦。
No-SQL数据库的transaction
不少No-SQL数据库也支持transaction,但是普遍来说No-SQL数据库对transaction的支持相对较弱。主要原因是No-SQL数据库一般都是基于分布式的架构设计和实现的,而transaction的某些特性是和分布式系统有冲突的。比如说,在分布式系统中,我们往往放弃数据的强制一致性而追求整体系统的可用性。但是数据可能存在不一致的状态对于维护transaction的原子性和一致性是非常大的挑战。
我们在这里以AWS的DynamoDB为例。DDB支持两种transaction:写transaction和读transaction。写transaction可以支持最多100个写操作,包括put(创建),update(更新),delete(删除),和conditionCheck(条件检查)。而读transaction可以支持最多100个读操作,也就是通过primary key获取一个item,即Get。关于DDB的transaction的介绍可以参考这篇文档。
问题
现在我们在DDB中有四张表。表1保存了某种记录,该记录拥有自己的primary key,同时该记录还拥有3种其它的属性可以作为index。另外3张表即用来保存某种index到该记录的primary key的对应关系。关系如下所示:
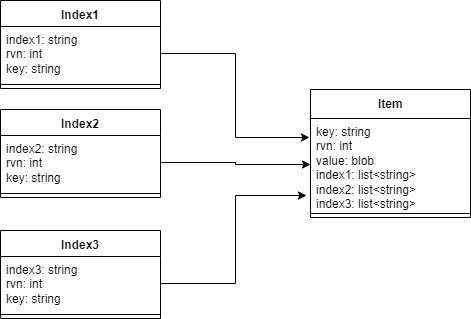
需要说明的是每一种index都可能有多个值,也就是说在item里每种index都是一个list。比如说对于一个item,我们可能有3个index1,5个index2,10个index3。这样我们就要在index1表中创建3条记录,在index2表中创建5条记录,在index3中创建10条记录。很明显,我们需要保持item和它相关的index的完整性。也就是说我们不希望出现如下的情况:
- Index存在,但是其索引的item已经被删除了;
- Index存在,但是它已经不该索引到当前的item了;
- Item存在,但是它的某个index丢失了;
- 。。。
如果我们考虑使用DDB transaction来解决这个问题,我们会发现我们可能面临下面两个问题:
- 一个item和它的索引数目大于100,所以DDB transaction无法支持该操作;
- 因为有太多的数据要被一起更新,有很大的概率更新之间经常互相冲突,造成transaction的commit的成功率很低。
那么我们该如何解决这个问题呢?
解决方案
通过分析,我们发现这个问题其实可以通过设计一个简单的状态机来解决。我们将该方法的细节描述如下。
首先,我们规定在更新item和index时,我们遵循以下的顺序:
- 更新index1
- 更新index2
- 更新index3
- 更新item
如果我们其中任何一个步骤失败的话,我们就终止掉本次更新,并且抛出一个异常,然后根据设定在某段时间后重新尝试更新。根据我们执行的过程,我们可能会有如下的状态和状态转换:
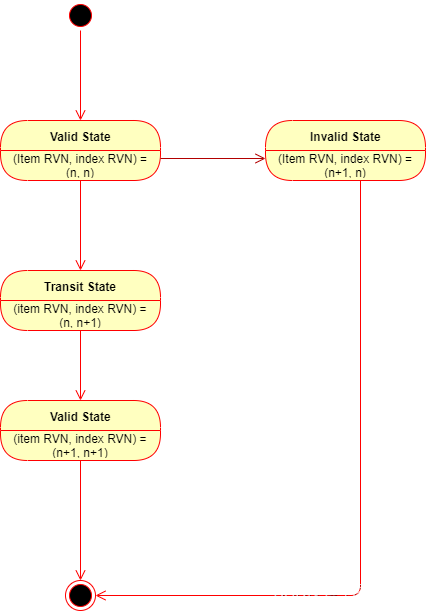
最开始假设我们处于一个合法的状态下,也就是说item的RVN和index的RVN是相等的,都是n。然后我们更新index成功,此时我们处于一个临时状态下,也就是index的RVN变成了n+1,但是item的RVN仍然是n。再然后我们更新item成功,我们就转换成下一个合法的状态,也就是item的RVN和index的RVN再次相等,都变成了n+1。有一个例外的不合法状态,就是item的RVN已经变成了n+1,但是index的RVN仍然是n。出现这种状态的原因是这个index被从RVN为n+1的数据中移除出去了,那么此时这个index就不能再被认为是该item的合法索引了。
现在我们在更新数据时逻辑非常简单,我们不需要做很多的比较和检查,仅仅是依照顺序依次更新index和item即可。那么在使用该index查询item时,我们就需要做一些检查工作,确保我们是通过合法的index找到了合法的item。首先,我们需要一个index的值,来获取该index的RVN。然后我们通过该index获取item和item的RVN。然后我们检查的具体逻辑如下:
- 假如index的RVN和item的RVN相等,那么我们得到的index和item都是合法的;
- 假如index的RVN大于item的RVN,那么我们得到的是一个临时状态数据。我们可以抛出一个异常,然后重新尝试读取数据;
- 假如index的RVN小于item的RVN,我们是否可以直接认为数据不合法而放弃呢?是不可以的。原因在于有可能在我们得到index的RVN和得到item的RVN之间有过一次更新,从而使得我们已经有的index的RVN变旧了。所以我们要再次查询一次index的RVN,然后分成下面三种情况进行处理:
- 如果新的index的RVN仍然等于之前得到的index的RVN,说明是index被移除的情况,此时我们应该认为通过该index查询不到item;
- 如果新的index的RVN和item的RVN相等了,说明我们得到了合法的数据;
- 如果新的index的RVN和item的RVN仍然不相等,并且新的index的RVN和之前的index的RNV也不相等,说明我们得到的是一个中间状态的数据。我们可以抛出异常然后重新尝试查询。
通过这个处理逻辑,我们是可以完成保证没有任何合法的数据被遗漏,通过也不会有任何非法的数据被使用的。
结论和扩展
本文中,我们介绍了一种通过设计状态机以达到最终数据一致性的方法来避免使用transaction的方法。在这里我们看到两个问题:第一,在分布式环境中的transaction通过有一定的局限性,并且transaction本身运行的代价也很大,所以我们在决定使用transaction的时候还要经过和其它方法的比较,以及分析可能出现的局限性和问题;第二,基于数据的最终一致性,我们可能会发现其它更简单的方法以避免使用transaction。但是需要说明的是,这里并不是简单的建议不使用transaction。事实上,transaction在很多情况下是最佳解决方案。只是提供一个在使用transaction之外的其它代替方案。