文章目录
- Rethinking Data Augmentation for Image Super-resolution:
- 1.概述
- 2.一些现有方法的分析
- 3.cutblur
- 4.MOA 各种策略的混合
- 5.降噪
- 6.cutblur 代码
Rethinking Data Augmentation for Image Super-resolution:
A Comprehensive Analysis and a New Strategy
1.概述
根据方法应用的位置将现有的增强技术分为两组:像素域就是针对图像 和 特征域就是中间的特征层。
作者提出cutblur方法,正则化模型使模型可以学到 在图像的什么区域区增强以及如何增强。
作者基于提出cutblur数据增强方法以及其他一些辅助方法 构建一个混合的数据增强策略,效果很好。
作者主要利用EDSR model 在 DIV2K和 RealSR 两个数据集上从头训练,进行分析。
一些数据增强方法 被提出,但是一般应用在high level任务上,对于超分,降噪这种low level任务不一定可行,甚至有害,也比较好理解。
许多增强方法的核心思想是对训练信号进行部分屏蔽或混淆,从而使模型获得更强的泛化能力。然而,与分类等高级任务不同,模型学习抽象图像。
low level任务像素之间的局部和全局关系在低层次视觉任务中尤为重要,如去噪和超分辨率。
2.一些现有方法的分析
下图是一些方法的展示:
这里简单说明一下:
blend就是 对通道 随机加减乘除 随机数,改变颜色
rgb permute 我理解使 各通道换一下位置
cutout 随机去掉一块
mixup 2张图像混合
cutmix 从其他图像取一块贴在新图像上
cutmixup 从其他图像取一块 与 新图像上的一块 混合

以上这些DA方法作者进行实验
cutout(%0.1%) 就是随机丢弃千分之一的像素,丢弃很少。
可以看出最简单方法 blend, rgb permute, 都是有效的。
作者提出的cut blur效果最好

关于cutmix介绍:参考https://meetonfriday.com/posts/b4202d1/

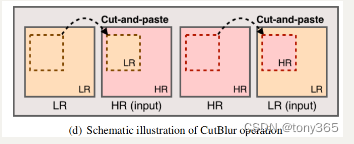
3.cutblur
cutblur也很简单:
从hr中取一块 paste lr中 改变原来的lr
从lr中取一块 paste hr中 改变原来的hr
使用和不使用cutblur的效果对比:

不使用cutblur训练的模型,当输入cutblur的图片是 会产生过度锐化
毕竟不使用cutblur训练,对全图都会进行超分,也在情理之中。不过这也说明了利用cutblur训练会使model学会在哪些区域做超分,哪些区域保持不变。

作者又和将hr作为输入,hr作为输出来锻炼model对hr的识别能力,发现效果不如cutblur。
4.MOA 各种策略的混合
MOA就是table1中的各个策略随机选择进行 DA
-
不同尺寸的超分模型
模型越大对DA的包容性越大,否则小模型本身拟合能力不够,不能处理DA数据。

-
不同的dataset size
数据集比较小的时候,大模型很容易过拟合,这个时候DA方法有助于帮助改善,下图的c,d

-
在div2k 和 realsr训练比较
realsr上应用DA,效果普遍提升较大

-
一个应用
现在手机上会有背景虚化或者前后景分辨率不同的图像,这个时候的图像适合 本文提出DA数据的训练
5.降噪

另外model对不同噪声水平的图像降噪的泛化能力更高
6.cutblur 代码
看一下下面代码的实现,修改的都是im2,即始终修改的使 lr图像,hr图像始终不变。实际代码 和论文图示,论文解释,论文公式都有点出入。
im1是HR
im2是LR
def cutblur(im1, im2, prob=1.0, alpha=1.0):if im1.size() != im2.size():raise ValueError("im1 and im2 have to be the same resolution.")if alpha <= 0 or np.random.rand(1) >= prob:return im1, im2cut_ratio = np.random.randn() * 0.01 + alphah, w = im2.size(2), im2.size(3)ch, cw = np.int(h*cut_ratio), np.int(w*cut_ratio)cy = np.random.randint(0, h-ch+1)cx = np.random.randint(0, w-cw+1)# apply CutBlur to inside or outsideif np.random.random() > 0.5:im2[..., cy:cy+ch, cx:cx+cw] = im1[..., cy:cy+ch, cx:cx+cw]else:im2_aug = im1.clone()im2_aug[..., cy:cy+ch, cx:cx+cw] = im2[..., cy:cy+ch, cx:cx+cw]im2 = im2_augreturn im1, im2
参数设置
# default augmentation policiesif opt.use_moa:opt.augs = ["blend", "rgb", "mixup", "cutout", "cutmix", "cutmixup", "cutblur"]opt.prob = [1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0]opt.alpha = [0.6, 1.0, 1.2, 0.001, 0.7, 0.7, 0.7]opt.aux_prob, opt.aux_alpha = 1.0, 1.2opt.mix_p = Noneif "RealSR" in opt.dataset:opt.mix_p = [0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.4]if "DN" in opt.dataset or "JPEG" in opt.dataset:opt.prob = [0.6, 0.6, 0.6, 0.6, 0.6, 0.6, 0.6]if "CARN" in opt.model and not "RealSR" in opt.dataset:opt.prob = [0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2]
训练代码:
LR, HR都是 N3HW shape
然后调用augments增强函数
HR = inputs[0].to(self.dev)LR = inputs[1].to(self.dev)# match the resolution of (LR, HR) due to CutBlurif HR.size() != LR.size():scale = HR.size(2) // LR.size(2)LR = F.interpolate(LR, scale_factor=scale, mode="nearest")HR, LR, mask, aug = augments.apply_augment(HR, LR,opt.augs, opt.prob, opt.alpha,opt.aux_alpha, opt.aux_alpha, opt.mix_p)SR = self.net(LR)if aug == "cutout":SR, HR = SR*mask, HR*maskloss = self.loss_fn(SR, HR)self.optim.zero_grad()loss.backward()
完整的DA代码:
"""
CutBlur
Copyright 2020-present NAVER corp.
MIT license
"""
import numpy as np
import torch
import torch.nn.functional as Fdef apply_augment(im1, im2,augs, probs, alphas,aux_prob=None, aux_alpha=None,mix_p=None
):idx = np.random.choice(len(augs), p=mix_p)aug = augs[idx]prob = float(probs[idx])alpha = float(alphas[idx])mask = Noneif aug == "none":im1_aug, im2_aug = im1.clone(), im2.clone()elif aug == "blend":im1_aug, im2_aug = blend(im1.clone(), im2.clone(),prob=prob, alpha=alpha)elif aug == "mixup":im1_aug, im2_aug, = mixup(im1.clone(), im2.clone(),prob=prob, alpha=alpha,)elif aug == "cutout":im1_aug, im2_aug, mask, _ = cutout(im1.clone(), im2.clone(),prob=prob, alpha=alpha)elif aug == "cutmix":im1_aug, im2_aug = cutmix(im1.clone(), im2.clone(),prob=prob, alpha=alpha,)elif aug == "cutmixup":im1_aug, im2_aug = cutmixup(im1.clone(), im2.clone(),mixup_prob=aux_prob, mixup_alpha=aux_alpha,cutmix_prob=prob, cutmix_alpha=alpha,)elif aug == "cutblur":im1_aug, im2_aug = cutblur(im1.clone(), im2.clone(),prob=prob, alpha=alpha)elif aug == "rgb":im1_aug, im2_aug = rgb(im1.clone(), im2.clone(),prob=prob)else:raise ValueError("{} is not invalid.".format(aug))return im1_aug, im2_aug, mask, augdef blend(im1, im2, prob=1.0, alpha=0.6):if alpha <= 0 or np.random.rand(1) >= prob:return im1, im2c = torch.empty((im2.size(0), 3, 1, 1), device=im2.device).uniform_(0, 255)rim2 = c.repeat((1, 1, im2.size(2), im2.size(3)))rim1 = c.repeat((1, 1, im1.size(2), im1.size(3)))v = np.random.uniform(alpha, 1)im1 = v * im1 + (1-v) * rim1im2 = v * im2 + (1-v) * rim2return im1, im2def mixup(im1, im2, prob=1.0, alpha=1.2):if alpha <= 0 or np.random.rand(1) >= prob:return im1, im2v = np.random.beta(alpha, alpha)r_index = torch.randperm(im1.size(0)).to(im2.device)im1 = v * im1 + (1-v) * im1[r_index, :]im2 = v * im2 + (1-v) * im2[r_index, :]return im1, im2def _cutmix(im2, prob=1.0, alpha=1.0):if alpha <= 0 or np.random.rand(1) >= prob:return Nonecut_ratio = np.random.randn() * 0.01 + alphah, w = im2.size(2), im2.size(3)ch, cw = np.int(h*cut_ratio), np.int(w*cut_ratio)fcy = np.random.randint(0, h-ch+1)fcx = np.random.randint(0, w-cw+1)tcy, tcx = fcy, fcxrindex = torch.randperm(im2.size(0)).to(im2.device)return {"rindex": rindex, "ch": ch, "cw": cw,"tcy": tcy, "tcx": tcx, "fcy": fcy, "fcx": fcx,}def cutmix(im1, im2, prob=1.0, alpha=1.0):c = _cutmix(im2, prob, alpha)if c is None:return im1, im2scale = im1.size(2) // im2.size(2)rindex, ch, cw = c["rindex"], c["ch"], c["cw"]tcy, tcx, fcy, fcx = c["tcy"], c["tcx"], c["fcy"], c["fcx"]hch, hcw = ch*scale, cw*scalehfcy, hfcx, htcy, htcx = fcy*scale, fcx*scale, tcy*scale, tcx*scaleim2[..., tcy:tcy+ch, tcx:tcx+cw] = im2[rindex, :, fcy:fcy+ch, fcx:fcx+cw]im1[..., htcy:htcy+hch, htcx:htcx+hcw] = im1[rindex, :, hfcy:hfcy+hch, hfcx:hfcx+hcw]return im1, im2def cutmixup(im1, im2,mixup_prob=1.0, mixup_alpha=1.0,cutmix_prob=1.0, cutmix_alpha=1.0
):c = _cutmix(im2, cutmix_prob, cutmix_alpha)if c is None:return im1, im2scale = im1.size(2) // im2.size(2)rindex, ch, cw = c["rindex"], c["ch"], c["cw"]tcy, tcx, fcy, fcx = c["tcy"], c["tcx"], c["fcy"], c["fcx"]hch, hcw = ch*scale, cw*scalehfcy, hfcx, htcy, htcx = fcy*scale, fcx*scale, tcy*scale, tcx*scalev = np.random.beta(mixup_alpha, mixup_alpha)if mixup_alpha <= 0 or np.random.rand(1) >= mixup_prob:im2_aug = im2[rindex, :]im1_aug = im1[rindex, :]else:im2_aug = v * im2 + (1-v) * im2[rindex, :]im1_aug = v * im1 + (1-v) * im1[rindex, :]# apply mixup to inside or outsideif np.random.random() > 0.5:im2[..., tcy:tcy+ch, tcx:tcx+cw] = im2_aug[..., fcy:fcy+ch, fcx:fcx+cw]im1[..., htcy:htcy+hch, htcx:htcx+hcw] = im1_aug[..., hfcy:hfcy+hch, hfcx:hfcx+hcw]else:im2_aug[..., tcy:tcy+ch, tcx:tcx+cw] = im2[..., fcy:fcy+ch, fcx:fcx+cw]im1_aug[..., htcy:htcy+hch, htcx:htcx+hcw] = im1[..., hfcy:hfcy+hch, hfcx:hfcx+hcw]im2, im1 = im2_aug, im1_augreturn im1, im2def cutblur(im1, im2, prob=1.0, alpha=1.0):if im1.size() != im2.size():raise ValueError("im1 and im2 have to be the same resolution.")if alpha <= 0 or np.random.rand(1) >= prob:return im1, im2cut_ratio = np.random.randn() * 0.01 + alphah, w = im2.size(2), im2.size(3)ch, cw = np.int(h*cut_ratio), np.int(w*cut_ratio)cy = np.random.randint(0, h-ch+1)cx = np.random.randint(0, w-cw+1)# apply CutBlur to inside or outsideif np.random.random() > 0.5:im2[..., cy:cy+ch, cx:cx+cw] = im1[..., cy:cy+ch, cx:cx+cw]else:im2_aug = im1.clone()im2_aug[..., cy:cy+ch, cx:cx+cw] = im2[..., cy:cy+ch, cx:cx+cw]im2 = im2_augreturn im1, im2def cutout(im1, im2, prob=1.0, alpha=0.1):scale = im1.size(2) // im2.size(2)fsize = (im2.size(0), 1)+im2.size()[2:]if alpha <= 0 or np.random.rand(1) >= prob:fim2 = np.ones(fsize)fim2 = torch.tensor(fim2, dtype=torch.float, device=im2.device)fim1 = F.interpolate(fim2, scale_factor=scale, mode="nearest")return im1, im2, fim1, fim2fim2 = np.random.choice([0.0, 1.0], size=fsize, p=[alpha, 1-alpha])fim2 = torch.tensor(fim2, dtype=torch.float, device=im2.device)fim1 = F.interpolate(fim2, scale_factor=scale, mode="nearest")im2 *= fim2return im1, im2, fim1, fim2def rgb(im1, im2, prob=1.0):if np.random.rand(1) >= prob:return im1, im2perm = np.random.permutation(3)im1 = im1[:, perm]im2 = im2[:, perm]return im1, im2
官方代码:https://github.com/clovaai/cutblur
这里扩展一下,如果是降噪任务:
- rgb permute, blend 比较通用
- cutout 这里是随机去掉千分之一的pixel 也可以提高对图像内容的理解,之前有介绍过另一篇论文。
- mixup 函数是 一个batch里的图像打乱后与原先batch混合,lr,hr同样的打乱顺序,似乎还行。
- 但是这里我想到另一个mixup方法,就是lr, hr以一定程度混合得到lr, 会不会更好,提高处理不同noise level图像的泛化能力。
- cutmix, cutmixup类似mixup 在一个batch种的图像,随机打乱后, 对应位置的patch进行替换 或者 混合。
- cutblur, 将hr中的patch 替换到 lr中 本文提到的方法。 当然我感觉也可以cut and mixup, 而不只是cut and paste.