Synthetic Temporal Anomaly Guided End-to-End Video Anomaly Detection 论文阅读
- Abstract
- 1. Introduction
- 2. Related Work
- 3. Methodology
- 3.1. Architecture
- 3.1.1 Autoencoder
- 3.1.2 Temporal Pseudo Anomaly Synthesizer
- 3.2. Training
- 3.3. Anomaly Score
- 4. Experiments
- 4.1. Datasets
- 4.2. Experimental Setup
- 4.3. Quantitative Results
- 4.4. Qualitative Results
- 5. Conclusion
- 阅读总结
文章信息:

中文标题:伪时间异常引导的端到断的视频异常检测
文章信息:

发表与:ICCV 2021
原文链接:https://arxiv.org/abs/2110.09768
源代码:https://github.com/aseuteurideu/STEAL
Abstract
由于异常样本的有限可用性,视频异常检测通常被视为一类分类(OCC)问题。解决这个问题的一种流行方法是利用仅在正常数据上训练的自编码器(AE)。在测试时,预期AE能够良好地重构正常输入,同时对异常重构较差。然而,一些研究显示,即使只有正常数据的训练,AE也经常会开始将异常样本重构得很好,从而降低了其异常检测性能。为了缓解这一问题,我们提出了一种时间伪异常合成器,利用仅有的正常数据生成假异常样本。然后,训练AE以最大化伪异常的重构损失,同时最小化正常数据的损失。通过这种方式,鼓励AE为正常和异常帧生成可区分的重构。对三个具有挑战性的视频异常数据集进行的大量实验和分析表明,我们的方法在提高基本AE在超越几种现有最先进模型方面的有效性方面表现出了有效性。
1. Introduction
最近,视频序列中的异常检测引起了极大的关注,因为在监控系统中具有重要意义 [37, 41, 18, 4, 16, 21, 19, 1, 46]。由于在现实生活中异常事件很少发生,并且收集大量异常示例可能很麻烦,因此这项任务非常具有挑战性。因此,异常检测通常被视为一类分类(OCC)问题,其中仅使用正常数据来训练新颖性检测模型 [7, 18, 4, 35, 39, 17, 14]。在测试时,不符合学习到的表示的事件被视为异常。
解决OCC问题的一种常见方法是使用深度自动编码器(AE)[8, 45, 39, 4, 21, 29, 20, 35, 7]。通过在正常数据上训练以最小化重构误差,鼓励模型在其潜在空间中提取代表正常数据的特征。这样,在测试时,预期网络会对异常情况进行差劲的重构。然而,正如几位研究人员之前观察到的[47, 26, 39],AEs 也经常能够成功重构异常示例。在这种情况下,正常数据和异常数据之间的重构损失可能不足以成功识别异常情况。
最近,在OCC领域的一个新的补充是利用从正常训练数据中生成的伪异常。例如,Zaheer等人[39]将正常数据中的两个随机图像融合以生成外观异常,并将它们用于训练图像分类器。然而,这项工作需要重构器的旧状态和新状态,并在两阶段方案中进行训练。此外,该方法仅限于外观,并未考虑任何用于异常检测的时间信息。相反,我们的工作提出了一个简单但非常有效的时间伪异常合成器,以一种端到端的方式辅助AE的训练,没有任何复杂的技巧。对于每个伪异常示例作为输入,我们的AE模型被训练以产生高重构损失。这有助于限制AE在测试时重构异常的能力。
我们的方法灵感来源于这样一种直觉,即检测快速或突然变化的运动在很大程度上是重要的,并与检测异常密切相关。例如,人们常常观察到动物通常将强烈的运动与危险情况联系起来。这种情况对人类也是类似的。例如,人们异常奔跑可能表明附近存在生命威胁的情况,如火灾或自然灾害。此外,斗殴或抢劫也可能表现为突然的强烈动作。其他一些例子可能包括在人行道上骑自行车或车辆,超速行驶的车辆等。因此,我们假设大多数异常事件都可以通过所描述的运动来表征。
为此,我们提出了一种时间伪异常合成器,将合成的异常示例注入到自动编码器(AE)的训练中。为了从正常数据中模拟异常运动,我们任意地跳过几帧来生成伪异常序列,如图1所示。然后,进行整体训练,最小化正常数据的重建损失,同时最大化合成异常数据的重建损失。值得注意的是,与现有的基于运动跟踪的异常检测方法不同,我们的方法不提取任何手动选择的运动信息。相反,通过将时间伪异常合成器与深度AE相结合,我们利用深度学习的力量来检测视频中各种异常活动。我们广泛的实验证明了我们的方法在三个具有挑战性的异常检测数据集(Ped2,Avenue和ShanghaiTech)中具有卓越的能力。

图1. 正常、异常和伪异常帧的可视化。在给定红线作为参考线的情况下,(a)显示了一个正常的运动模式,其中人们以通常的速度行走。(b)显示了异常运动,即异常对象在几帧内几乎完全穿过参考线。©显示了我们从正常帧中生成的伪异常合成器的输出,模拟了异常运动。
总之,本文的贡献如下:1) 我们提出利用时间伪异常合成器辅助训练单类分类器,产生具有高度区分性的正常和异常重构。2) 大量实验表明,与广泛存在的一系列最新工作[12, 25, 22, 19, 44, 33, 8, 45, 20, 21, 34, 39, 1, 4, 18, 7, 29, 10]相比,我们的方法在三个基准数据集上表现出了显著的优越性。
2. Related Work
由于很难获取异常示例,因此流行的异常检测方法是一类分类(OCC),其中仅使用正常数据进行训练。一些研究利用通过目标跟踪器提取的特征来训练一类分类器。然而,这种手动选择的特征往往会限制网络在不同类型活动上的泛化能力。
随着深度学习的近期流行,一些研究人员利用自动编码器(AE)网络来学习正常数据的表示。AE仅在正常数据上进行重建或预测任务的训练。在测试时,模型预期会产生异常数据的差劲重建,对应着较高的异常分数。一些基于AE的方法仅使用外观信息,而另一些则同时使用外观和动态信息。然而,AE通常也能够重建异常数据,因此正常和异常数据变得难以区分。
已经有一些尝试限制自动编码器(AE)在异常数据上的重建能力。基于记忆的网络在AE的编码器和解码器之间的潜在空间上采用了一种记忆机制。该网络被限制只能使用记忆中的正常定义,从而限制了其重建异常数据的能力。然而,这样的网络高度依赖于记忆大小,而且小型记忆可能也会限制它们对正常数据的重建能力。在我们的方法中,我们也尝试限制AE在异常输入上的重建能力。但是,我们没有使用记忆网络,而是利用伪异常合成器生成虚假异常示例,并鼓励AE在这些示例上产生高重建损失。
与我们的工作最相关的是OGNet [39],它将正常图像融合以生成外观异常,并使用正常和伪异常示例来训练网络。此外,OGNet 需要一个两阶段的对抗训练方案,其中鉴别器是基于两个先前冻结的生成器模型进行训练的。另一方面,我们合成异常的方法有很大的不同。我们提出利用时间信息而不是外观来合成异常。此外,我们的方法是端到端可训练的,并且与传统的AE训练相辅相成。
为了增强正常数据和异常数据的区分能力,一些研究者提出采用真实的异常示例进行训练,从而偏离了OCC的基本定义。而我们的方法则利用仅正常数据来合成用于训练的伪异常示例,因此遵循了传统的OCC协议。
3. Methodology
在本节中,我们介绍了我们提出的STEAL(Synthetic TEmporal AnomaLy guided end-to-end video anomaly detection)网络。由于在训练过程中缺乏异常示例,大多数基于AE的异常检测方法在测试时经常无法区分异常与正常数据。因此,我们提出利用伪异常示例来增强AE的性能,这些示例是通过我们的伪异常合成器仅使用正常训练视频生成的。
3.1. Architecture
我们的整体架构如图2所示。
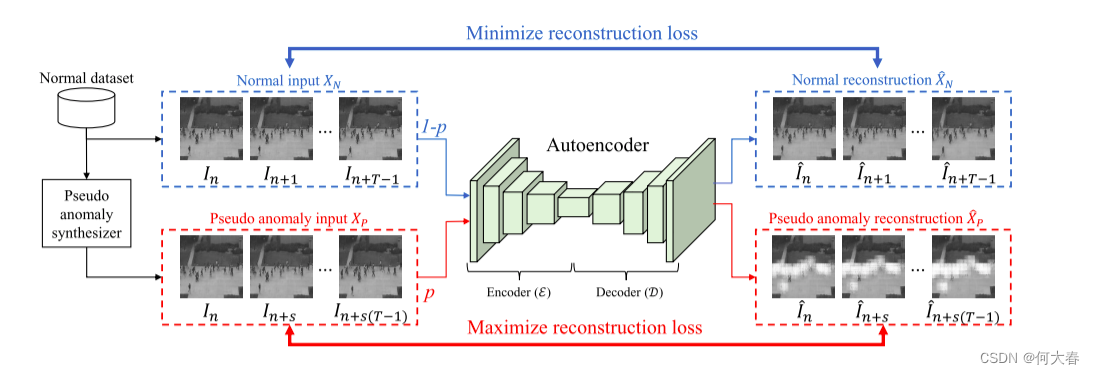
图2. 我们的方法使用正常序列和伪异常序列训练自动编码器。伪异常是仅使用正常数据合成的。伪异常示例的数量由概率p调节。总体配置旨在减少正常输入的重构损失,同时增加伪异常输入的重构损失。
我们训练一个传统的自动编码器(AE)作为我们的基线模型,它将一系列正常帧作为输入,并将其重构作为输出。为了补充基线训练,我们提出了一个伪异常合成器,用于生成虚假的异常示例。然后,这些示例以概率 p 用于训练。这样,我们通过迫使AE在这些伪异常示例上增加重构损失来限制其重构能力。最后,使用帧级别的重构损失计算异常分数。接下来讨论我们架构的每个组件:
3.1.1 Autoencoder
为了捕获鲁棒性的表示,通常设计自动编码器 ( A E ) (AE) (AE)以接收多帧输入[7, 29, 8, 45]。因此,我们将我们的AE模型设置为接收大小为 T × C × H × W T×C×H×W T×C×H×W的输入 X X X,其中 T 、 C 、 H T、C、H T、C、H和 W W W分别是输入序列中的帧数、通道数、帧的高度和宽度。重构 X ^ \hat{X} X^如下所示:
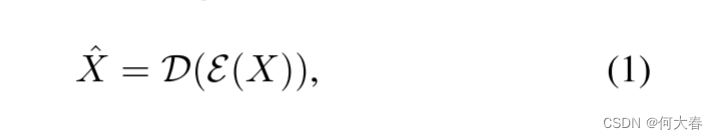
其中 ε \varepsilon ε和 D \mathcal{D} D分别表示模型的编码器和解码器。
传统上,自动编码器(AE)是使用训练集中的正常数据进行训练的。在测试时,它应该能够很好地重建正常数据,而对异常示例的重建效果较差。然而,并非总是如此。自动编码器有时会“过分泛化”,也会对异常示例进行重建 [47, 26, 39]。由于在训练时没有使用异常示例,因此很难训练出基于重建的异常检测模型 [39]。为了解决这个问题,我们提出了一个伪异常合成器,它可以提供虚假的异常示例。然后,利用这些示例来限制自动编码器的生成能力,并鼓励其在任何类型的异常输入上产生高重建损失。
在训练期间,视频帧X的序列被提供给网络作为:

其中, X P X_P XP是使用我们提出的伪异常合成器生成的一系列帧, X N X_N XN是来自正常训练数据的一系列帧, p p p是定义所使用的伪异常示例比例的概率。请注意,伪异常仅在训练期间引入。在测试时,我们只需将原始的视频帧序列输入到自动编码器中。
3.1.2 Temporal Pseudo Anomaly Synthesizer
在我们提出的方法中,我们遵循仅利用正常数据进行训练的OCC协议。因此,为了生成时间伪异常,我们仅利用正常的训练视频。类似于训练传统自动编码器的常见做法,我们从训练视频 V i = { I 1 , I 2 , . . . , I K i } V_i = \{I_1, I_2, ..., I_{K_i} \} Vi={I1,I2,...,IKi}中提取帧序列 X N X_N XN,其长度为 K i K_i Ki帧,方法是随机选择一个帧索引 n n n从 V i V_i Vi中,然后取连续的T帧作为序列,具体描述如下:

另一方面,伪异常 X P X_P XP 是通过将跳帧参数 s s s引入到方程(3)中来合成的:
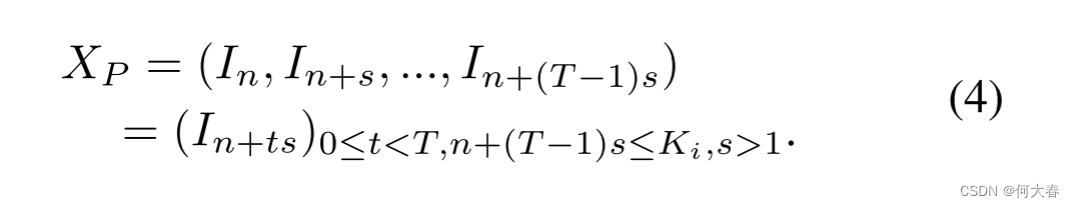
跳帧参数 s 控制我们跳过的帧数,用于生成时间上的伪异常示例。当 s = 2 时,示例伪异常序列的可视化如图 1( c ) 所示。
3.2. Training
为了学习正常的表示,常规的自编码器通过最小化输入帧 I n + t I_{n+t} In+t 与其重构 I ^ n + t \hat{I}_{n+t} I^n+t 之间的重构损失来进行训练:
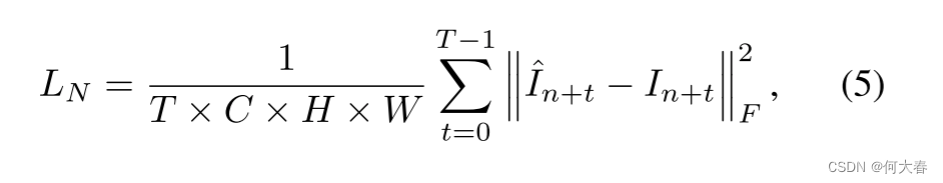
这里的 ∥ . ∥ \lVert.\rVert ∥.∥F 表示Frobenius范数。
对于我们的时间伪异常合成器生成的 X P X_P XP,损失可以类似地定义为:
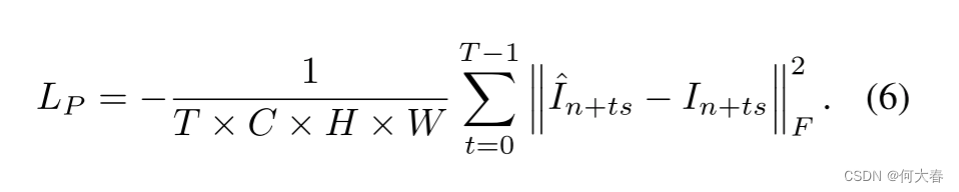
请注意方程(6)中的负号,它是为了增加伪异常示例的重构损失。这有助于限制我们的自编码器在异常输入上的重构能力。
然后,训练的总损失 L L L采用以下形式:
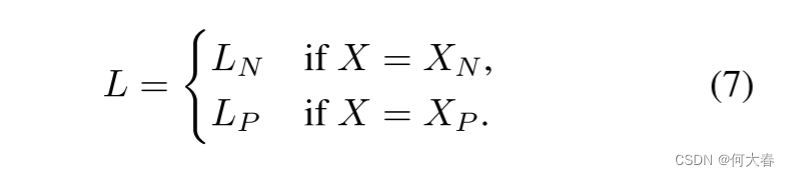
3.3. Anomaly Score
在测试阶段,与现有方法[7, 29, 18, 8, 45, 39, 41]相一致,我们在帧级别进行异常分数预测。此外,我们通过利用基于重构的峰值信噪比(PSNR)来计算这些分数。根据Mathieu等人的研究[23],PSNR通常比重构损失本身更好地评估图像质量。最近,它还被用于异常检测[29, 18],其中输入帧与其重构之间的PSNR用于计算异常分数。在我们的方法中,我们计算PSNR P t \mathcal{P}_t Pt如下:
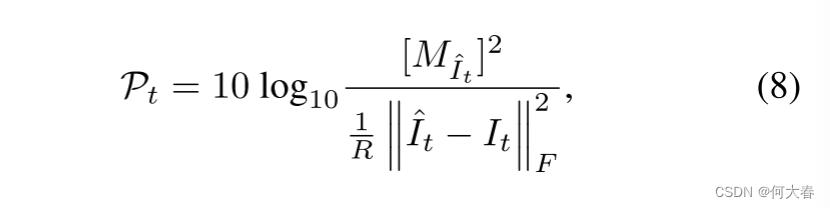
其中, R R R是 I ^ t \hat{I}_t I^t中的像素总数, t t t是帧索引,而 M I ^ t M_{\hat{I}_t} MI^t是 I ^ t \hat{I}_t I^t的最大可能值。
然后,按照[29, 18]的方法,我们通过对测试视频 V i V_i Vi中所有帧的PSNR值进行最小-最大归一化,将其归一化到[0, 1]的范围内,具体如下所示:
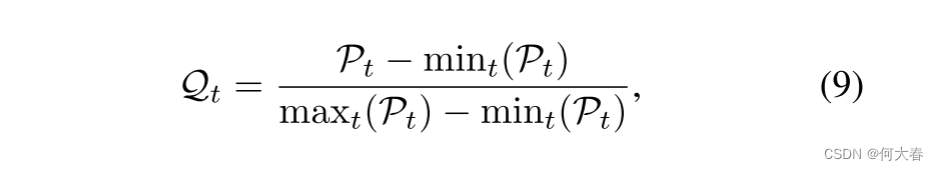
在方程(9)中,较高的 Q t \mathcal{Q}_t Qt表示与Vi中的其他帧相比较低的重构损失,反之亦然。因此,我们计算最终的异常分数 A t \mathcal{A}_t At如下:
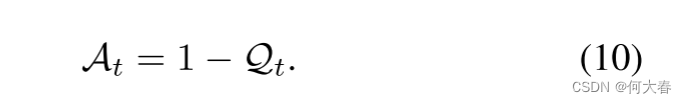
4. Experiments
4.1. Datasets

4.2. Experimental Setup
Evaluation criteria.为了评估我们的方法,我们遵循广泛使用的帧级ROC曲线下面积(AUC)指标。ROC曲线通过变化异常分数的阈值来绘制整个数据集的假阳性率和真阳性率。更高的AUC值表示更准确的结果。
Parameters and implementation details.我们采用了最近由Gong等人提出的生成式架构作为我们的基线模型,它接受大小为16×1×256×256的输入序列X(公式(1)),并产生相同大小的重构。在训练期间(公式(5)-(6)),所有16帧都用于计算重构损失。在测试时,遵循[7]的做法,仅考虑16帧中的第9帧进行异常分数的计算(公式(8)-(10))。然而,与原始实现不同的是,我们移除了记忆网络,仅利用了自动编码器部分。此外,我们添加了Tanh输出层,使输出范围为[-1, 1]。
STEAL Net和基线的实现是在PyTorch [30]中完成的。使用Adam [13]进行训练,学习率设置为 1 0 − 4 10^{-4} 10−4,批量大小设置为4。公式(4)中的跳帧参数 s s s设置为{2, 3, 4, 5},这意味着每次生成伪异常序列时,s可以随机选择为2、3、4、5中的一个。公式(2)中的伪异常概率 p p p设置为0.01。在我们的结果中,基线指的是在没有伪异常的情况下训练的模型,即公式(2)中的概率 p p p设置为0。
4.3. Quantitative Results
表1显示了我们提出的STEAL Net在Ped2 [16]、Avenue [19]和ShanghaiTech [21]数据集上的AUC比较结果。我们的方法在所有三个数据集上均优于基线。具体来说,在Ped2、Avenue和ShanghaiTech数据集上,我们的方法分别实现了5.9%、5.6%和2.4%的AUC绝对增益。这表明我们的方法成功地提高了基线在多个不同数据集上的性能。
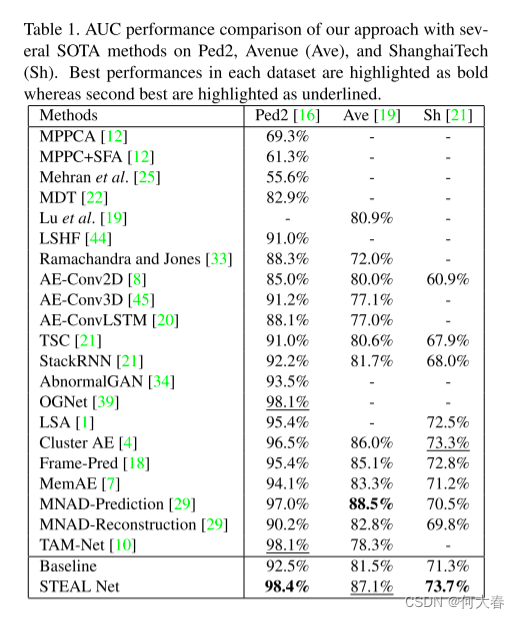
与现有方法相比,我们在所有三个数据集上都取得了优越的性能。尽管MNAD-Prediction [29]在Avenue数据集上的性能比我们的方法更好,但其优越性也可能归因于不同的基本架构以及训练设置,即预测任务。然而,与MNAD-Reconstruction相比,后者具有与我们类似的基本架构并执行相同的重建任务,我们的模型表现出明显更好的性能,从而证明了我们方法的优越性。
总体而言,STEAL Net的优越性能验证了我们的假设,即多种不同类型的异常可能可以通过其中存在的运动特征来表征。因此,通过利用时间伪异常合成器,我们释放了深度自动编码器在更准确的异常检测方面的潜力。
4.4. Qualitative Results
图3的前三列显示了STEAL Net和基准模型生成的输入图像及其重构图像的比较。此外,最后两列展示了重构误差热图。这些热图是通过计算重构图像与输入帧之间每个像素的平方误差,然后进行最小-最大归一化得到的。由于我们的方法专门训练用于在异常输入上产生高重构损失,因此它会尝试通过扭曲异常区域来满足这一条件。另一方面,与多项研究报告一致,基准模型对异常的重构效果良好,因此通常无法产生明显的区分。

5. Conclusion
我们提出了利用伪异常的方法,这些异常是使用正常数据生成的,以辅助自动编码器(AE)进行视频异常检测的训练。除了常规的AE训练,其中网络仅尝试最小化输入的重构误差之外,我们进一步鼓励网络在伪异常上最大化此损失。我们的方法在三个具有挑战性的视频异常数据集上广泛分析了其在增强AE方面的有效性,从而使其在多个现有先进模型面前表现出优势。
阅读总结
方法很简单,通过跳帧的方式合成伪异常来作为部分输入。有时间复现一下,有几个细节地方感觉说的还是有点问题的。