MySQL–优化(索引篇)
- 定位慢查询
- SQL执行计划
- 索引
- 存储引擎
- 索引底层数据结构
- 聚簇和非聚簇索引
- 索引创建原则
- 索引失效场景
- SQL优化经验
索引
索引(index)是帮助 MySQL 高效获取数据的数据结构(有序)。在数据之外,数据库系统还维护着满足特定査找算法的数据结构(B+树),这些数据结构以某种方式引用(指向)数据这样就可以在这些数据结构上实现高级查找算法,这种数据结构就是索引。
一、 例子(理解索引的用处)
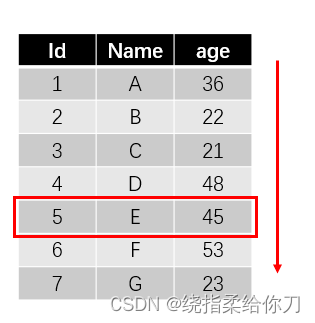
无索引
- 当前我们有一张表,里面有很多条数据
- 现在我们要去查年龄为 45 的数据
- 在没有索引的情况,age会逐条的进行比对,当找到了 45 也不会停,他会接着往下找,直到整张表多遍历一遍
有索引
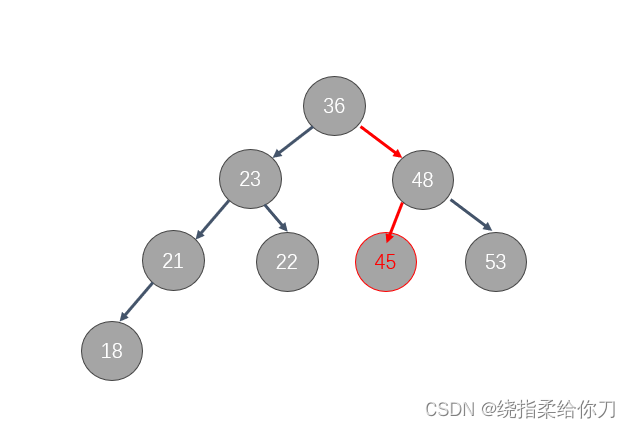
比如维护了一个索引(二叉搜索数)MySQL 中的索引不是(二叉搜索数),说到二叉树是方便理解
- 首先找当前二叉树的根节点 36 (拿45跟36作比对,45比36大),走右边找到 37(拿45跟47作比对,45比48小)走左边找到 45
- 这个效率就有明显的提升,这个就是索引的好处(提升查找效率)
总结
- 我们需要维护一个像(二叉搜索数)
- 有个这样一个数据结构,在查找数据的时候可以提升查找效率,减少 IO 的操作
二、索引的底层数据结构
- 在探讨MySQL索引之前,我们需要先了解几种常见的数据结构:二叉搜索树、红黑树、B树和B+树。每种数据结构都有其独特的工作原理和优缺点。
三、数据结构对比
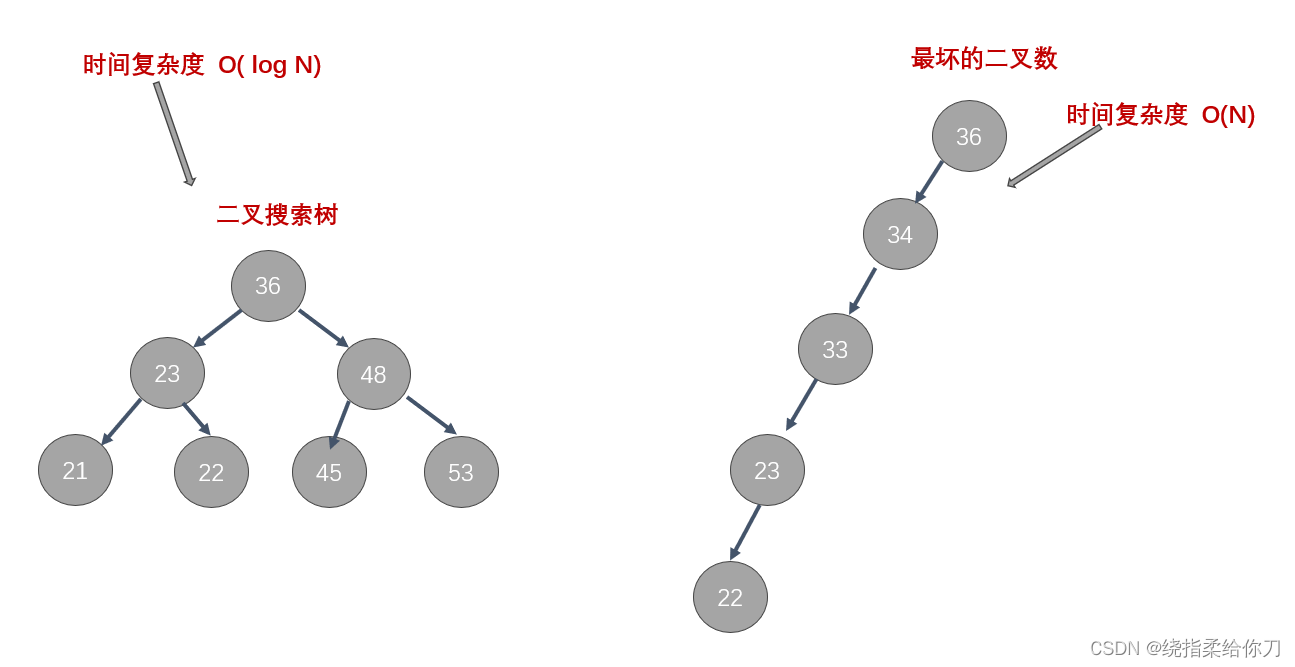
1、二叉搜索树
- 虽然二叉搜索树在理想情况下具有较高的查询效率,但一旦数据不平衡,其性能将大幅下降。
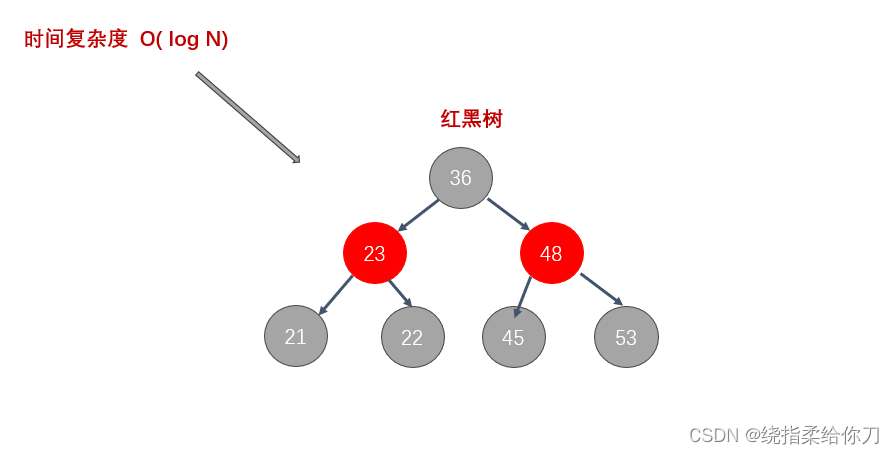
2、红黑数
- 红黑树通过自平衡机制解决了这一问题,但由于其每个节点最多只有两个子节点,因此在处理大量数据时,树的高度会显著增加,导致查询效率降低。
- 那假如 MySQL 某张表的数据是 1千万 ,而红黑树也是一个二叉树,一个节点只能有两个分支,如果把1千万的数据存储到红黑树中,那么这个红黑树就会变得特别的高,要去查找的数据依然要去找很多个层级
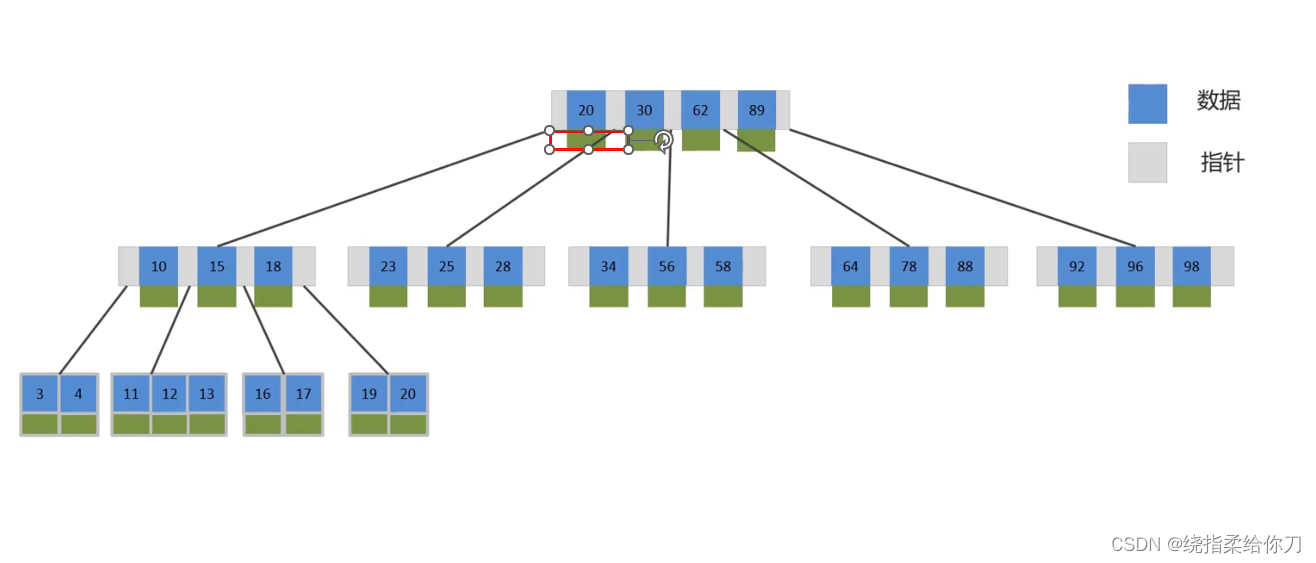
3、B 树
- B树是一种多叉树结构,与二叉树相比,它能够减少树的高度,从而提高查询效率。然而,B树在非叶子节点中既存储键也存储数据,这在处理大量数据时可能导致磁盘IO操作增多。
- B树每个节点可以有多个分支,即多叉。
- 以一颗最大度数(max-degree)为5(5阶)的b-tree为例,那这个B树每个节点最多存储4个key
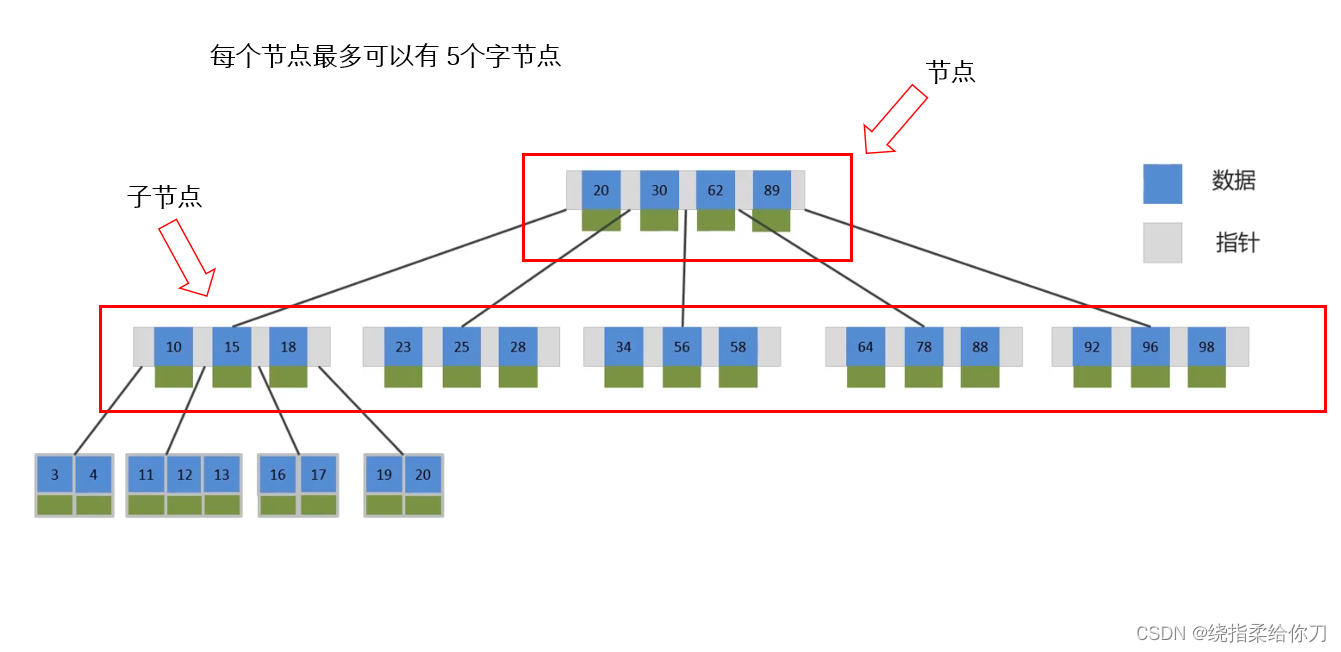
- 每个key多有指针,图中key20指针所对应的20以内的数据
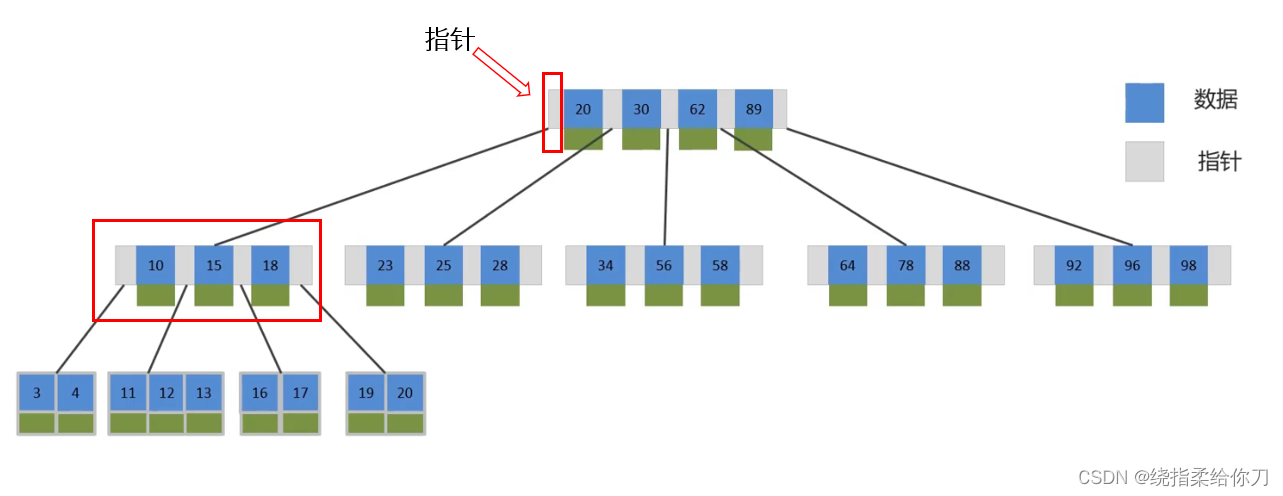
- 其中每个key对应的数据
4、B + 树
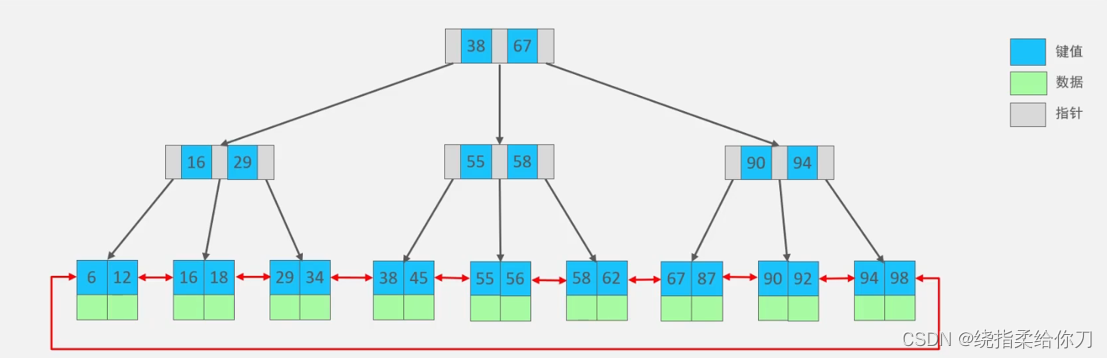
- B+树是B树的一种优化版本。
- 它在非叶子节点中仅存储键和子节点的指针,而将数据全部存储在叶子节点中。
- 这种设计使得B+树的查询效率更加稳定,且更适合于磁盘等辅助存储器的数据读写操作。
- 此外,B+树的叶子节点之间通过指针相连,便于进行范围查询和扫库操作。
总结
- 什么是索引
- 索引(index)是帮助MySQL高效获取数据的数据结构(有序)
- 提高数据检索的效率,降低数据库的I0成本(不需要全表扫描)
- 通过索引列对数据进行排序,降低数据排序的成本,降低了CPU的消耗
- 索引的底层数据结构
- MySQL的InnoDB引擎采用的B+树的数据结构来存储索
- B+树 阶数更多,路径更短
- 磁盘读写代价B+树更低,非叶子节点只存储指针,叶子阶段存储数据
- B+树便于扫库和区间查询,叶子节点是一个双向链表