编者
在临床研究中,数据缺失是不可避免的,甚至没有缺失,数据的真实性都会受到质疑。
那我们该如何应对缺失的数据?放着不管?还是重新开始?不妨试着对缺失值进行填补,简单又高效。毕竟对于统计师来说,对缺失值进行填补也是日常工作之一。
今天为大家带来一篇CHARLS数据库有关缺失值填补的文章复现,包括全部的代码与处理好的数据一并提供给诸位!
复现文章介绍
今天要介绍的文章是发表在《中国慢性病预防与控制》(IF=2.18),题为:“中国城市老年人身体活动与衰弱的相关性研究” 的研究论文。研究结果显示,中高身体活动有助于降低城市老年人的衰弱风险,应对城市老年人开展衰弱筛查,并重视身体活动在降低衰弱风险中的作用,积极引导城市老年人进行身体活动。

本公众号回复“立春”即可获得“立春”临床统计学沙龙PPT,数据等资料 |
1. 研究设计
P(Population)参与者:CHARLS2018年城市样本中 60~95岁的老年人。
E(exposure)暴露因素:身体活动水平(PA)。(1周身体活动量(MET-min/周)=对应身体活动的代谢当量(MET)×每天活动时间(min)×1 周活动天数(d);低水平身体活动 MET 赋值为 3.3,中水平身体活动赋值为4.0,高水平身体活动赋值为 8.0;将<600 MET-min/周划分为低水平身体活动,≥600 MET-min/周划分为中高水平身体活动。)
O(outcome)结局:是否衰弱(FI)。(FI 的计算方法为存在健康缺陷的指标数目除以纳入总数,范围为 0~1;本研究将衰弱定义为 FI≥0.25。)
2. 统计学方法
利用多重填补法对缺失数据进行填补,疾病维度的使用前一期调查数据,使用多因素非条件logistic回归和分层logistic回归对结果进行分析。

3. 文章数据介绍
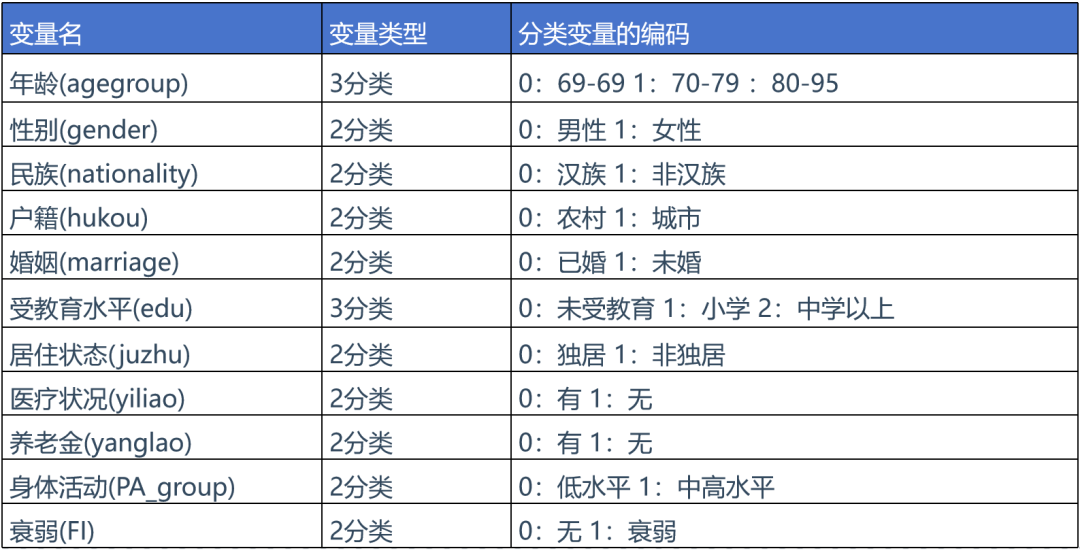
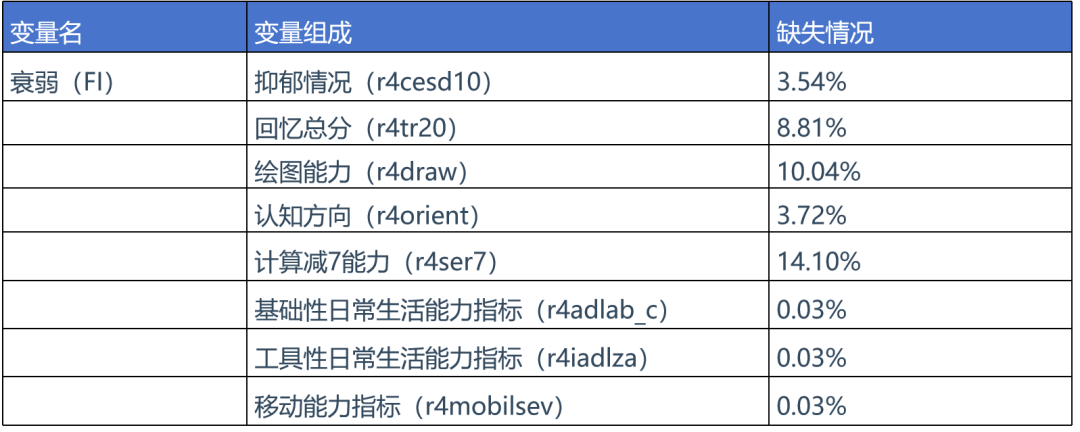
研究涉及charls数据库的变量如下表所示,本次复现所用到的变量也与文章保持一致。

4. 研究结果
4.1 基线特征
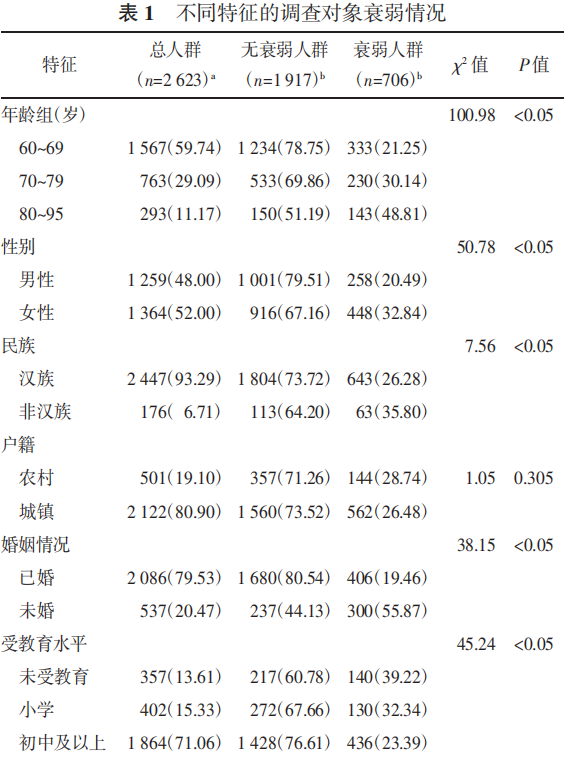
2623 名城市老年人年龄为 60~95 岁,平均年龄为(69.3±7.3)岁,男性1259 人(48.00%),女性 1 364 人(52.00%)。城市老年人的衰弱率为 26.92%。不同年龄、性别、民族、婚姻、教育、地域、居住状态、医疗保险拥有情况以及身体活动水平的城市老年人衰弱率差异均有统计学意义 (P<0.05),见表 1。

4.2 城市老年人身体活动与衰弱的相关性分析
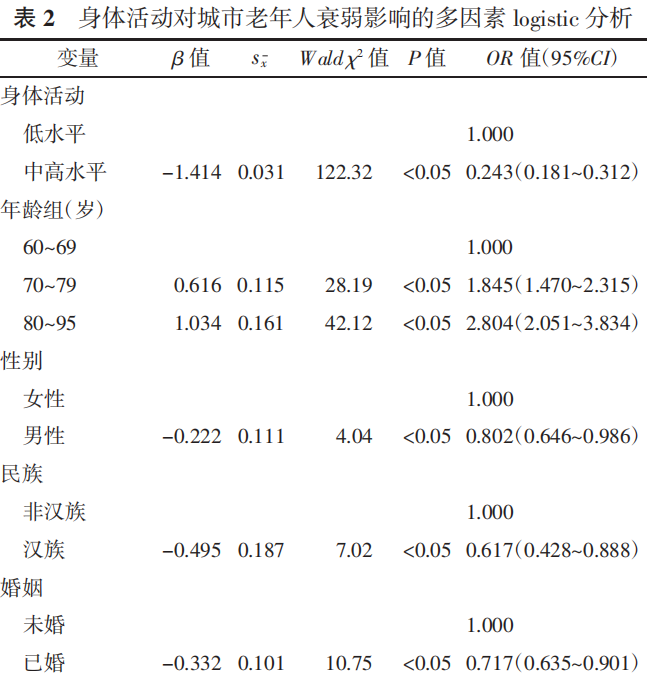
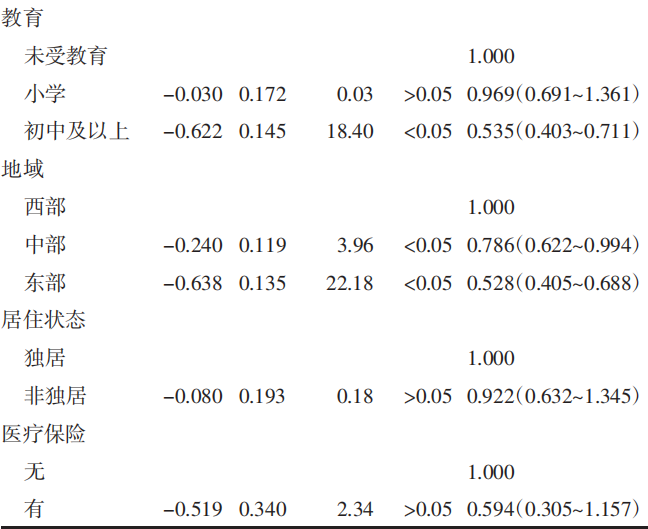
衰弱情况(0=无,1=衰弱)为因变量,身体活动水平作为自变量进行 logistic 回归分析,控制混杂因素后,相比低身体活动,中高身体活动的城市老年人衰弱风险更低(OR=0.243,95%CI:0.181~0.312,P<0.05)。其他控制变量中,除居住状态和医疗保险外,其余因素均与老年人衰弱的发生相关,均有统计学意义(P<0.05)。见表 2。
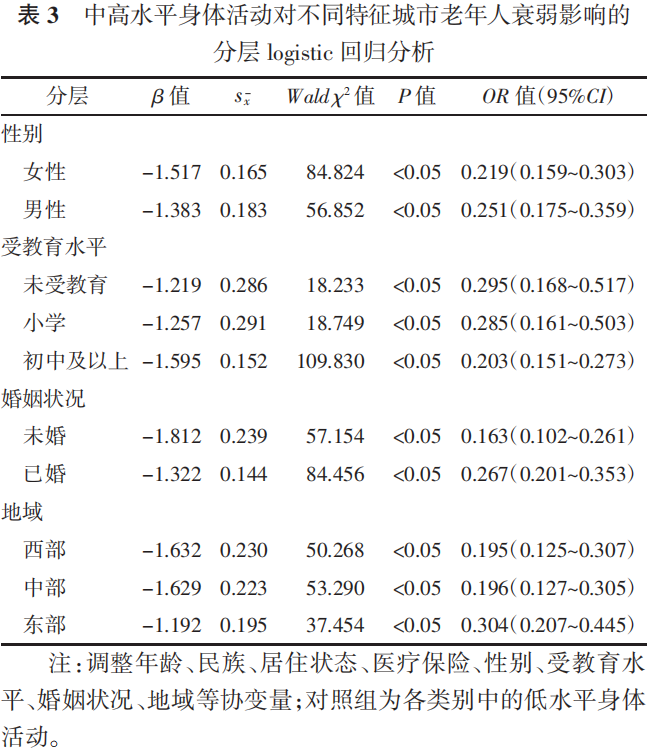
4.3 中高身体活动对不同特征城市老年人衰弱的影响
以衰弱(0=无,1=衰弱)为因变量,身体活动水平(0=低水平,1=中高水平)为自变量,按性别、受教育水平、婚姻状况和地域进行分层 logistic 回归分析。结果显示,与低身体活动相比,进行中高身体活动对于女性、受教育水平偏高、未婚以及居住在中西部地区的老年人衰弱风险降低的作用更大(P<0.05),见表 3。
R语言复现
本次复现包括的统计学方法有:
|
1.数据导入
首先,导入我们从charls数据库中提取处理好的数据,本次复现数据包括3816名研究对象(原文章n=2623),样本量略有出入,这里大家请多关注统计方法的运用。

2.基线差异性分析
本次复现基线表格用到了tableone包,这里“myVars”汇总了基线表中的全部变量,其中有部分变量为分类变量,则需要通过“catVars”进行指定,否则分类数据也将以定量数据进行展示。

这里tab2中未指定分组变量,则仅展示各变量的数据分布,此外,“showAllLevels = TRUE”表示展示分类变量所有分类因子的结果,“nonnormal =”指定的定量数据将以偏态分布进行分析,如果所有定量数据都是偏态分布,可以简洁的用“nonnormal = TRUE”来表示。

最后,将基线表结果输出保存在工作空间里,这里我们设置保存为csv格式!
3. 缺失值情况
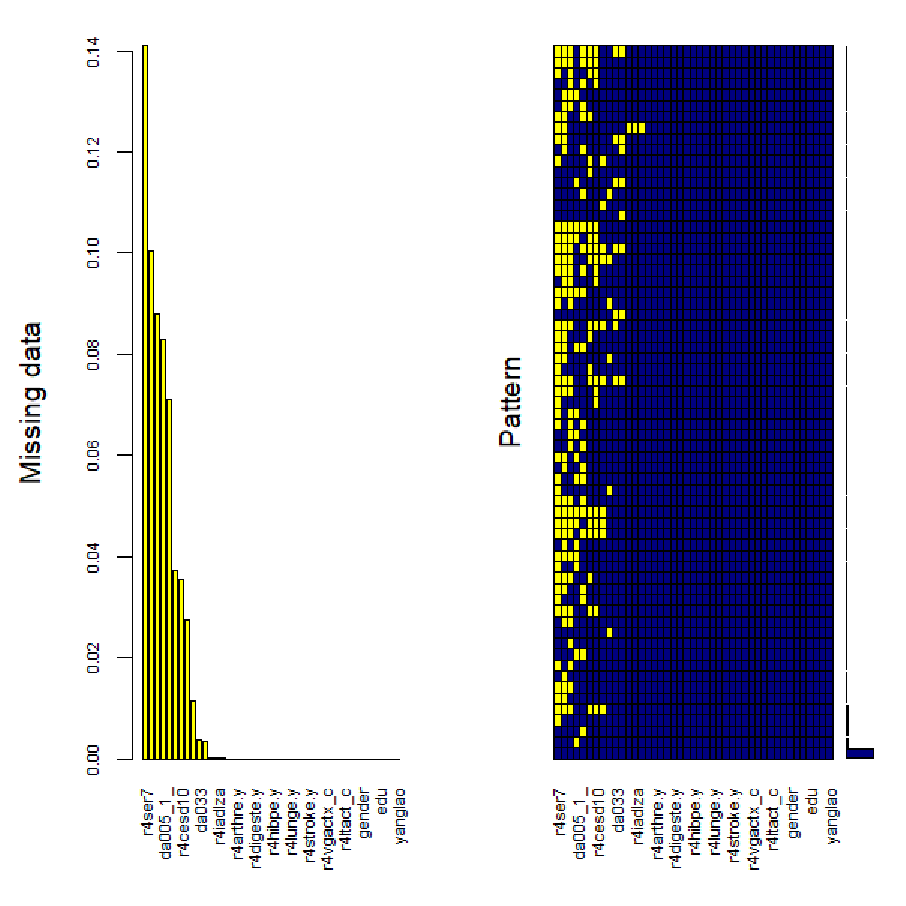
首先对我们所需要用到的研究因素进行批量因子化,并查看缺失值的特征,进行缺失值可视化。
以下是可视化的结果。
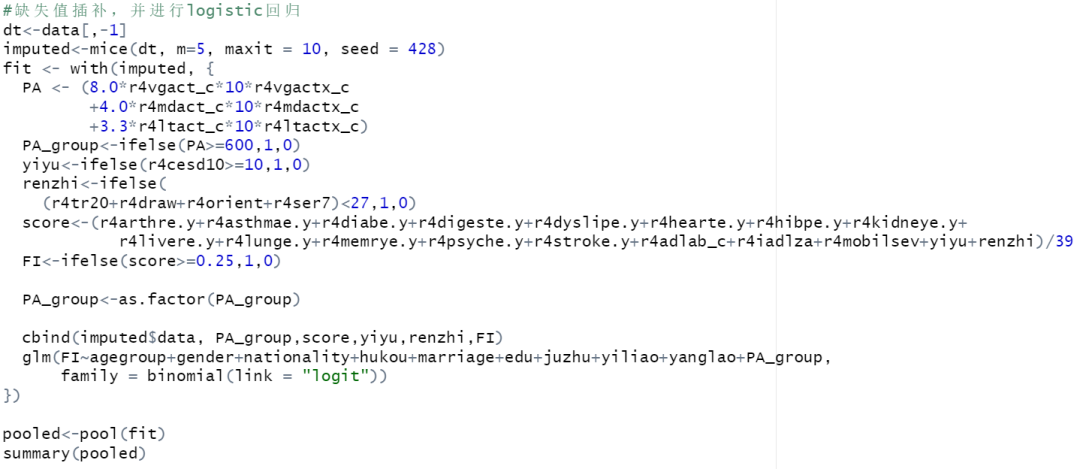
4.缺失值填补,多因素logistic回归
利用mice包进行缺失值的填补,m:多重插补法的数量,默认为 5。method:指定数据中每一列的输入方法。1)数值型数据适用 pmm;2)二分类数据适用 logreg;3)无序多类别数据适用 ployreg;4)有序多分类变量适用 polr。默认方法为 pmm 。maxit:迭代次数,一般为 50。
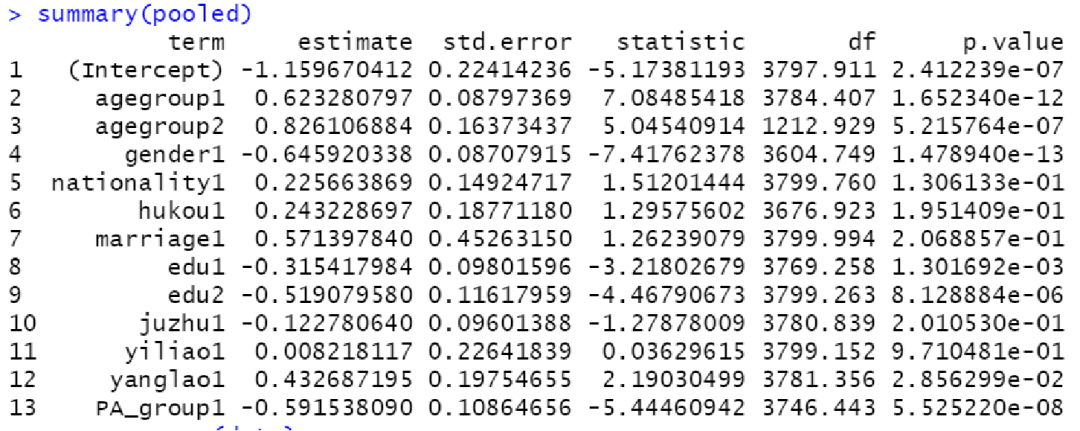
使用with函数对所有数据集进行分析,在填补的数据集中计算身体活动和衰弱指标,按照分组标准进行赋值,并进行多因素logistic回归,最后使用pool函数对结果进行汇总输出。
结果展示:
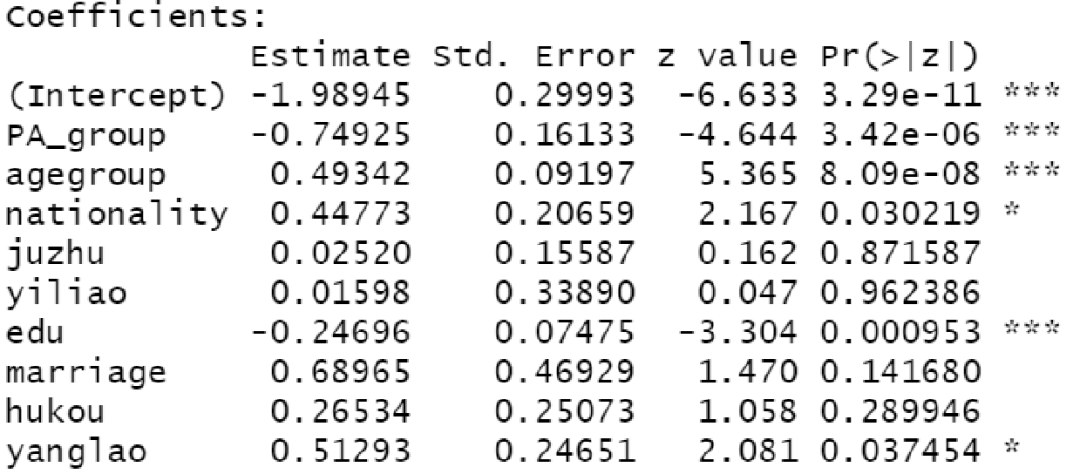
5.分层logistic回归
将各组挑出组成新的数据集,在各个数据集中进行分层logistic回归。

结果展示:

后记
缺失值填补,简单来说就是,人为的地给我们没有观测到的变量赋予一个值,并将这个值用于分析。这样做,虽然听起来可能比较主观,不太科学,但实际上,这也是我们不得不采取的措施。
试验中存在缺失值,本来是一件遗憾的事情,但是我们可以适当“调整”,对缺失进行填补,这难道不比重新开始更方便吗?
相信看完了全文的读者对于缺失数据填补已经有了大致的了解,如果想要了解更多,不妨关注本公众号,我们会带来更多缺失数据文章的复现!敬请期待!!
本公众号回复“立春”即可获得“立春”临床统计学沙龙PPT,数据等资料 |
本公众提供各种科研服务了!
一、课程培训 2022年以来,我们召集了一批富有经验的高校专业队伍,着手举行短期统计课程培训班,包括R语言、meta分析、临床预测模型、真实世界临床研究、问卷与量表分析、医学统计与SPSS、临床试验数据分析、重复测量资料分析、nhanes、孟德尔随机化等10余门课。如果您有需求,不妨点击查看: 发文后退款:2024-2025年科研统计课程介绍 二、数据分析服务 浙江中医药大学郑老师团队接单各项医学研究数据分析的服务,提供高质量统计分析报告。有兴趣了解一下详情: 课题、论文、毕业数据分析 临床试验设计与分析 、公共数据库挖掘与统计 |