首先这个案例不一定能直接拿来用,虽然我觉得可以但是里面肯定有一些我没考虑到的地方。
有问题评论或者私信我: 这个案例适合我这种学生小白
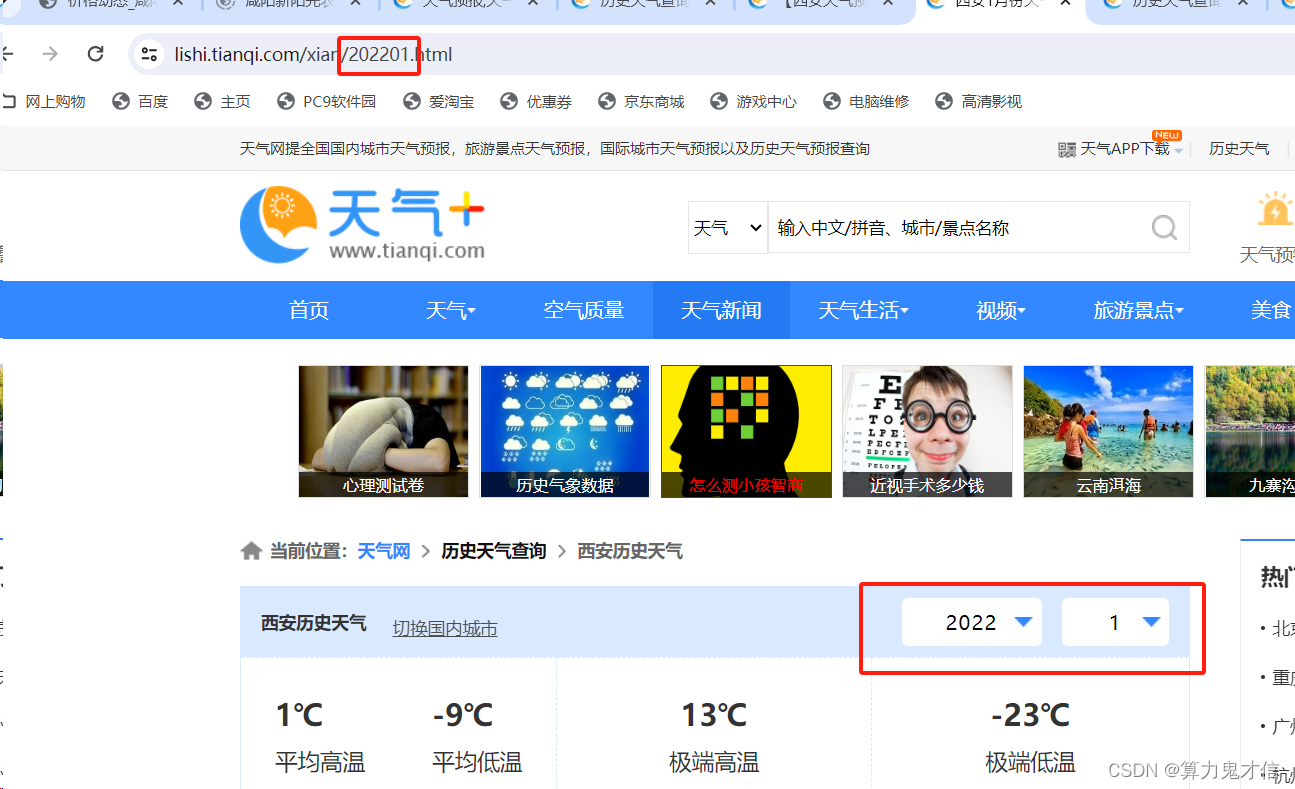
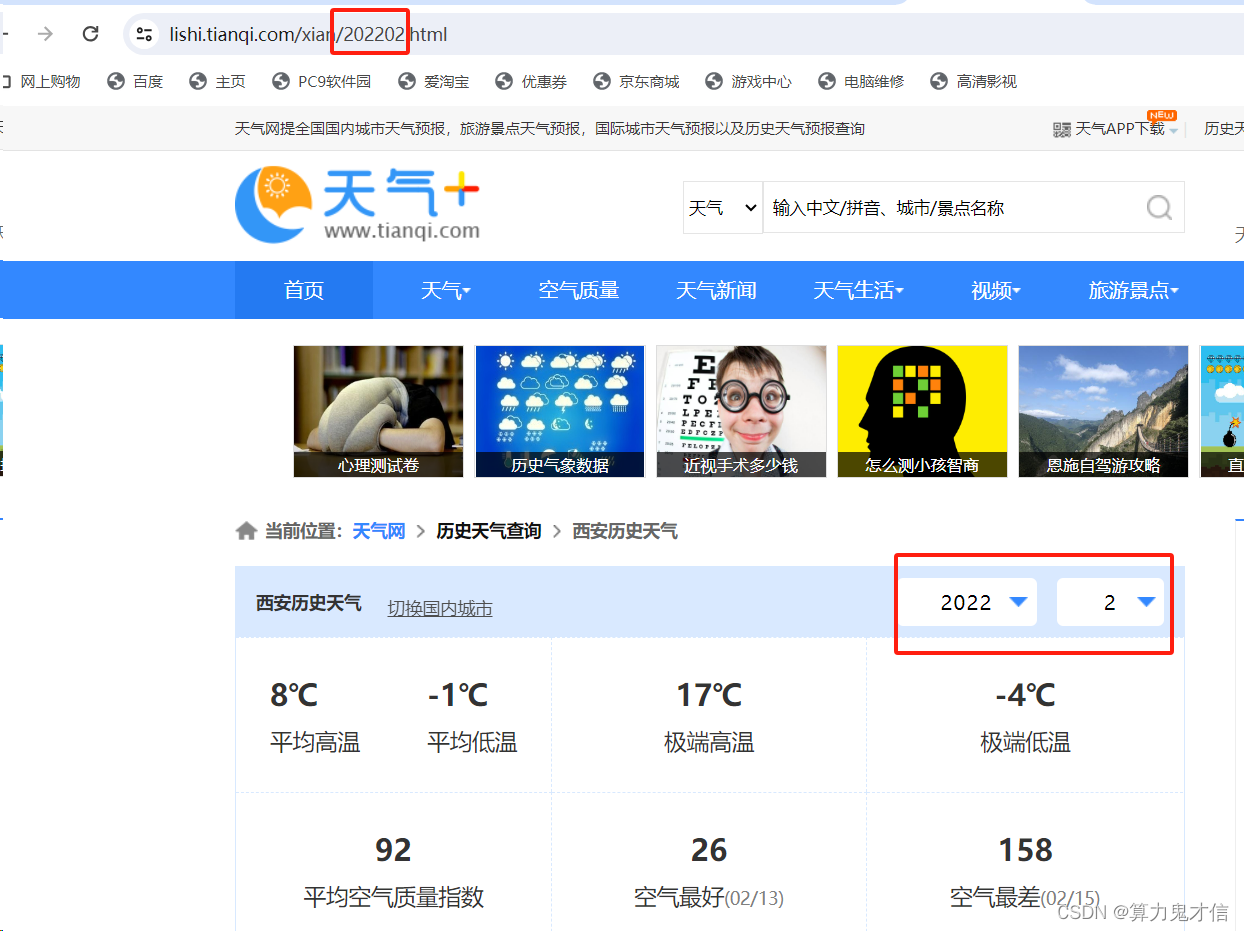
获取天气数据网址: https://lishi.tianqi.com/xianyang/202201.html
网络触手获取天气数据代码直接就可以使用,我们只需要改动几个地方,我将改动的地方给大家注释出来:
首先在url中:
https://lishi.tianqi.com/xianyang/202201.html,你可以改成你们城市的名称比如 西安:
https://lishi.tianqi.com/xian/202401.html
通过观察1月和2月的天气数据存在的网址中发现,https://lishi.tianqi.com/xianyang/202201.html
202201 表示2022年1月份,所以你可以推出2022年2月的网址在这块的变化应该是:202202,那十月份就应该是202210,这个地方体现在代码的
# ('0' + str(month) if month < 10 else str(month)) 这是一个三元表达式
# 首先从 if month < 10 开始,如果month 小于10,则执行 '0' + str(month),这叫做字符串拼接,形成的是一个新的字符串,如果不满足也就是 大于10则执行str(month),将month强制转化为字符串。不论满不满足也就是month < 10 符不符合小于10,都会在执行一次字符串拼接,('2022' + '0' + str(month) 或 ('2022' + str(month))
weather_time = '2022' + ('0' + str(month) if month < 10 else str(month))
# 这里是字符串格式化,还用到字符串拼接,
url = 'https://lishi.tianqi.com/xianyang/'+f'{weather_time}.html'
网址的其他地方都一样:
其他地方都不用管你可以直接用,我知道代码可能对有的朋友不太友好,看不懂,没关系,你先试试看能不能用。看不懂你给我发私信,我看到第一时间给大家回复。
# 开始请求时间start_time = time.time()# global requests_count, start_time# # 请求完成结束时间# current_time = time.time()# elapsed_time_since_start = current_time - start_time# minute_passed = int(elapsed_time_since_start/60)# while requests_count >= minute_passed *max_reuqests_per:## print("请求过于频繁")# ## ## requests_count +=1def getWeather(url):weather_info = []headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36','Cookie': 'lianjia_uuid=9d3277d3-58e4-440e-bade-5069cb5203a4; UM_distinctid=16ba37f7160390-05f17711c11c3e-454c0b2b-100200-16ba37f716618b; _smt_uid=5d176c66.5119839a; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2216ba37f7a942a6-0671dfdde0398a-454c0b2b-1049088-16ba37f7a95409%22%2C%22%24device_id%22%3A%2216ba37f7a942a6-0671dfdde0398a-454c0b2b-1049088-16ba37f7a95409%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22%22%2C%22%24latest_referrer_host%22%3A%22%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%7D%7D; _ga=GA1.2.1772719071.1561816174; Hm_lvt_9152f8221cb6243a53c83b956842be8a=1561822858; _jzqa=1.2532744094467475000.1561816167.1561822858.1561870561.3; CNZZDATA1253477573=987273979-1561811144-%7C1561865554; CNZZDATA1254525948=879163647-1561815364-%7C1561869382; CNZZDATA1255633284=1986996647-1561812900-%7C1561866923; CNZZDATA1255604082=891570058-1561813905-%7C1561866148; _qzja=1.1577983579.1561816168942.1561822857520.1561870561449.1561870561449.1561870847908.0.0.0.7.3; select_city=110000; lianjia_ssid=4e1fa281-1ebf-e1c1-ac56-32b3ec83f7ca; srcid=eyJ0Ijoie1wiZGF0YVwiOlwiMzQ2MDU5ZTQ0OWY4N2RiOTE4NjQ5YmQ0ZGRlMDAyZmFhODZmNjI1ZDQyNWU0OGQ3MjE3Yzk5NzFiYTY4ODM4ZThiZDNhZjliNGU4ODM4M2M3ODZhNDNiNjM1NzMzNjQ4ODY3MWVhMWFmNzFjMDVmMDY4NWMyMTM3MjIxYjBmYzhkYWE1MzIyNzFlOGMyOWFiYmQwZjBjYjcyNmIwOWEwYTNlMTY2MDI1NjkyOTBkNjQ1ZDkwNGM5ZDhkYTIyODU0ZmQzZjhjODhlNGQ1NGRkZTA0ZTBlZDFiNmIxOTE2YmU1NTIxNzhhMGQ3Yzk0ZjQ4NDBlZWI0YjlhYzFiYmJlZjJlNDQ5MDdlNzcxMzAwMmM1ODBlZDJkNmIwZmY0NDAwYmQxNjNjZDlhNmJkNDk3NGMzOTQxNTdkYjZlMjJkYjAxYjIzNjdmYzhiNzMxZDA1MGJlNjBmNzQxMTZjNDIzNFwiLFwia2V5X2lkXCI6XCIxXCIsXCJzaWduXCI6XCIzMGJlNDJiN1wifSIsInIiOiJodHRwczovL2JqLmxpYW5qaWEuY29tL3p1ZmFuZy9yY28zMS8iLCJvcyI6IndlYiIsInYiOiIwLjEifQ=='}reponse = requests.get(url=url, headers=headers)if reponse.status_code==200:reponse.encoding = reponse.apparent_encoding# 正则表达式获取需要标题pattern = r'<div class="th200">(.*?)</div>\s*<div class="th140">(.*?)</div>\s*<div class="th140">(.*?)</div>\s*<div class="th140">(.*?)</div>'matches = re.findall(pattern, reponse.text)# 将匹配的结果转换为字典列表for match in matches[1:]:# 这里有错误date_str = match[0]# 使用split分割字符串,取第一部分date_str = date_str.split(' ')[0]#第一个 %Y-%m-%d 在 strptime 函数中起到解析的作用,将字符串 date_only 按照这种格式解释为一个 datetime 对象#第二个 %Y-%m-%d 在 strftime 方法中起到格式化的作用,将前面解析得到的 datetime 对象转换回字符串#转换回字符串 不会影响存入mysql吗 因为刚才在写入MySQL的Connect_MySQL.py 文件中Date#将日期字符串转换回 YYYY-MM-DD 格式的字符串并不会影响其存入MySQL数据库,只要数据库表结构中的对应列是日期类型(如 DATE 或 DATETIME)formatted_date = datetime.strptime(date_str, '%Y-%m-%d').strftime('%Y-%m-%d')highest_temp = float(match[1].replace('℃', ''))lowest_temp = float(match[2].replace('℃', ''))weather_data = {'日期':formatted_date , '最高温': highest_temp,'最低温': lowest_temp,'天气状况': match[3]}weather_info.append(weather_data)return weather_info# 创建一个空的DataFrame 且给上columns 名称weather_df = pd.DataFrame(columns=['日期', '最高温', '最低温', '天气状况'])for month in range(1,13):# 202302# 三元表达式 凑请求链接weather_time = '2022' + ('0' + str(month) if month < 10 else str(month))url = 'https://lishi.tianqi.com/xianyang/'+f'{weather_time}.html'# 调用函数并将结果添加到DataFrame中monthly_weather = getWeather(url)monthly_weather_df = pd.DataFrame(monthly_weather)weather_df = pd.concat([weather_df, monthly_weather_df])# response_time = time.time() - start_time# time.sleep(min(response_time, 5) + random.uniform(0.5, 1))print(weather_df)存入数据库代码:
需要注意的是(都输入你的):
# 定义数据库连接参数 5 db_config = { 6 'host': 'your_host', # 数据库地址 7 'port': your_port, # 数据库端口 8 'user': 'your_username', # 数据库用户名 9 'password': 'your_password', # 数据库密码 10 'database': 'your_database', # 数据库名称 11 } 12 13# 创建数据库引擎 engine = create_engine(f'mysql+pymysql://{db_config["user"]}:{db_config["password"]}@{db_config["host"]}:{db_config["port"]}/{db_config["database"]}')
还有必须要手动在你的本地数据库中创建一个名为 “weather" 的数据库
如果忘记了没关系:
我告诉大家一个方法如何找到这些信息,前提是安装了一些操作数据库的可视化软件任何都行,我用的是sqlyong。
第一步:打开可视化工具
第二步:
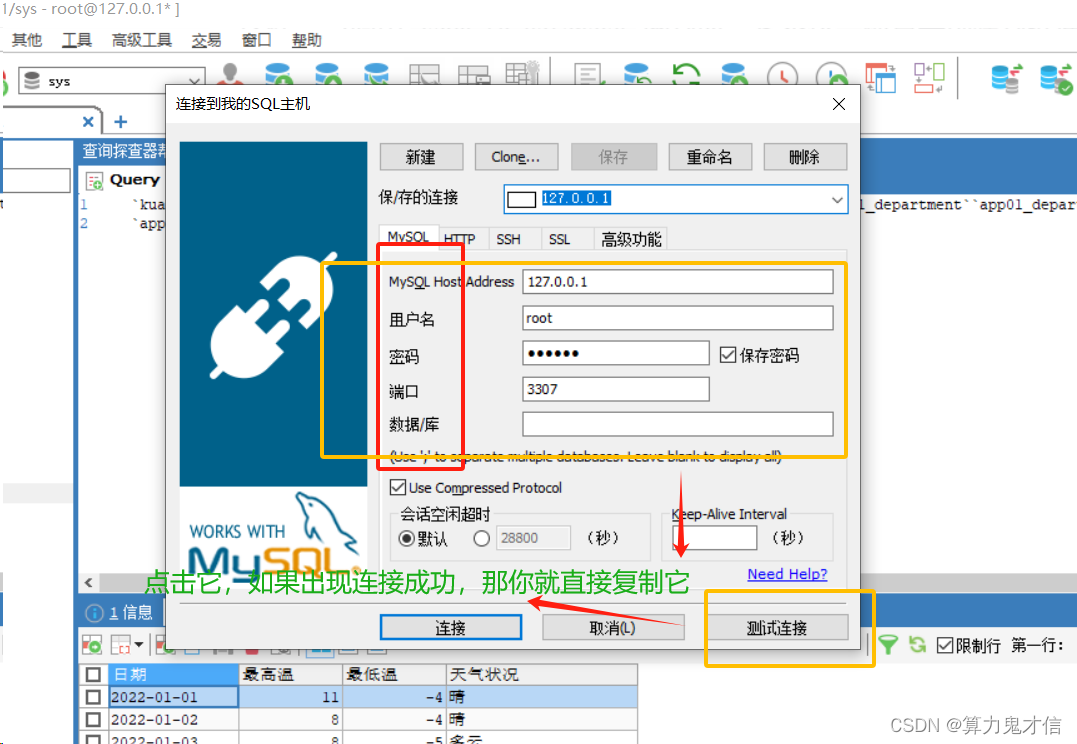
如果出现连接失败,我只能解决密码忘记问题,其他问题其实应该可以我没遇到过,例如端口被占用,数据库地址不对,这在安装数据库的时候就要注意,怎么弄,也就是大家都怎么写你就怎么写,不要搞一些复杂的到时候就忘记了。
mysql 数据库密码忘记,重置密码网址:
http://t.csdnimg.cn/9m1ax 作者: csdn博主 小达学加瓦
连接、测试、写入数据库代码:
(不知道没关系,这个代码包含了检测是否存在表,不存在创建表,数据是否写入成功不成功抛出错误),只要你把我刚说前面那些写对,就应该直接能用
from sqlalchemy import create_engine, MetaData, Table, Column, Float, String, Date
from sqlalchemy.exc import OperationalErrorfrom sqlalchemy import inspect# 定义数据库连接参数db_config = {'host': '127.0.0.1', # 数据库地址'port': 3307, # 数据库端口'user': 'root', # 数据库用户名'password': '123456', # 数据库密码'database': 'weather', # 数据库名称}# 创建数据库引擎engine = create_engine(f'mysql+pymysql://{db_config["user"]}:{db_config["password"]}@{db_config["host"]}:{db_config["port"]}/{db_config["database"]}')# 测试数据库连接是否成功try:connection = engine.connect()print("数据库连接成功!")except Exception as e:print(f"数据库连接失败:{str(e)}")# 创建表(如果不存在)metadata = MetaData()table_name = 'weather_data'table_columns = [Column('日期', Date),Column('最高温', Float),Column('最低温', Float),Column('天气状况', String(255)),]weather_table = Table(table_name, metadata, *table_columns, extend_existing=True)# 检查表是否存在,如果不存在则创建表inspector = inspect(engine)if not inspector.has_table(table_name):# 注意这里需要传递 engine 到 create_all 方法中metadata.create_all(bind=engine)# 检查表是否存在,如果不存在则创建表try:metadata.create_all(engine)except OperationalError as oe:if "already exists" in str(oe): # 如果表已存在则忽略错误print("cunza")else:raise oeprint("表 'weather_data' 已经检查并创建完毕(如有必要)")# 将数据写入数据库if weather_df is not None and not weather_df.empty:weather_df.to_sql(name=table_name, con=engine, if_exists='append', index=False, dtype={'日期': Date,'最高温': Float,'最低温': Float,'天气状况': String(255),})print("数据已成功写入 'weather_data' 表.")else:print("未找到待写入数据库的数据.")主函数:运行这个大程序:
from my_project.tianqi.tianqi import get_weather_data
from my_project.database.Connect_MySQL import save_to_database
def main():weather_df = get_weather_data()save_to_database(weather_df)if __name__ == "__main__":main()文件夹以文件架构:这是模块(包或文件夹的创建位置很重要)

完整程序代码:
# 天气文件 使用前请先按照文件夹的架构层级创建文件夹和文件 ,以下三个python 都是一样的要求
#file--tianqi.py
import random
import time
import re
import pandas as pd
from datetime import datetimeimport requests
from lxml import etree
def get_weather_data():# 设置每分钟允许的最大请求数量max_reuqests_per = 20requests_count = 0# 开始请求时间start_time = time.time()# global requests_count, start_time# # 请求完成结束时间# current_time = time.time()# elapsed_time_since_start = current_time - start_time# minute_passed = int(elapsed_time_since_start/60)# while requests_count >= minute_passed *max_reuqests_per:## print("请求过于频繁")# ## ## requests_count +=1def getWeather(url):weather_info = []headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36','Cookie': 'lianjia_uuid=9d3277d3-58e4-440e-bade-5069cb5203a4; UM_distinctid=16ba37f7160390-05f17711c11c3e-454c0b2b-100200-16ba37f716618b; _smt_uid=5d176c66.5119839a; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2216ba37f7a942a6-0671dfdde0398a-454c0b2b-1049088-16ba37f7a95409%22%2C%22%24device_id%22%3A%2216ba37f7a942a6-0671dfdde0398a-454c0b2b-1049088-16ba37f7a95409%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22%22%2C%22%24latest_referrer_host%22%3A%22%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%7D%7D; _ga=GA1.2.1772719071.1561816174; Hm_lvt_9152f8221cb6243a53c83b956842be8a=1561822858; _jzqa=1.2532744094467475000.1561816167.1561822858.1561870561.3; CNZZDATA1253477573=987273979-1561811144-%7C1561865554; CNZZDATA1254525948=879163647-1561815364-%7C1561869382; CNZZDATA1255633284=1986996647-1561812900-%7C1561866923; CNZZDATA1255604082=891570058-1561813905-%7C1561866148; _qzja=1.1577983579.1561816168942.1561822857520.1561870561449.1561870561449.1561870847908.0.0.0.7.3; select_city=110000; lianjia_ssid=4e1fa281-1ebf-e1c1-ac56-32b3ec83f7ca; srcid=eyJ0Ijoie1wiZGF0YVwiOlwiMzQ2MDU5ZTQ0OWY4N2RiOTE4NjQ5YmQ0ZGRlMDAyZmFhODZmNjI1ZDQyNWU0OGQ3MjE3Yzk5NzFiYTY4ODM4ZThiZDNhZjliNGU4ODM4M2M3ODZhNDNiNjM1NzMzNjQ4ODY3MWVhMWFmNzFjMDVmMDY4NWMyMTM3MjIxYjBmYzhkYWE1MzIyNzFlOGMyOWFiYmQwZjBjYjcyNmIwOWEwYTNlMTY2MDI1NjkyOTBkNjQ1ZDkwNGM5ZDhkYTIyODU0ZmQzZjhjODhlNGQ1NGRkZTA0ZTBlZDFiNmIxOTE2YmU1NTIxNzhhMGQ3Yzk0ZjQ4NDBlZWI0YjlhYzFiYmJlZjJlNDQ5MDdlNzcxMzAwMmM1ODBlZDJkNmIwZmY0NDAwYmQxNjNjZDlhNmJkNDk3NGMzOTQxNTdkYjZlMjJkYjAxYjIzNjdmYzhiNzMxZDA1MGJlNjBmNzQxMTZjNDIzNFwiLFwia2V5X2lkXCI6XCIxXCIsXCJzaWduXCI6XCIzMGJlNDJiN1wifSIsInIiOiJodHRwczovL2JqLmxpYW5qaWEuY29tL3p1ZmFuZy9yY28zMS8iLCJvcyI6IndlYiIsInYiOiIwLjEifQ=='}reponse = requests.get(url=url, headers=headers)if reponse.status_code==200:reponse.encoding = reponse.apparent_encoding# 正则表达式获取需要标题pattern = r'<div class="th200">(.*?)</div>\s*<div class="th140">(.*?)</div>\s*<div class="th140">(.*?)</div>\s*<div class="th140">(.*?)</div>'matches = re.findall(pattern, reponse.text)# 将匹配的结果转换为字典列表for match in matches[1:]:# 这里有错误date_str = match[0]# 使用split分割字符串,取第一部分date_str = date_str.split(' ')[0]#第一个 %Y-%m-%d 在 strptime 函数中起到解析的作用,将字符串 date_only 按照这种格式解释为一个 datetime 对象#第二个 %Y-%m-%d 在 strftime 方法中起到格式化的作用,将前面解析得到的 datetime 对象转换回字符串#转换回字符串 不会影响存入mysql吗 因为刚才在写入MySQL的Connect_MySQL.py 文件中Date#将日期字符串转换回 YYYY-MM-DD 格式的字符串并不会影响其存入MySQL数据库,只要数据库表结构中的对应列是日期类型(如 DATE 或 DATETIME)formatted_date = datetime.strptime(date_str, '%Y-%m-%d').strftime('%Y-%m-%d')highest_temp = float(match[1].replace('℃', ''))lowest_temp = float(match[2].replace('℃', ''))weather_data = {'日期':formatted_date , '最高温': highest_temp,'最低温': lowest_temp,'天气状况': match[3]}weather_info.append(weather_data)return weather_info# 创建一个空的DataFrame 且给上columns 名称weather_df = pd.DataFrame(columns=['日期', '最高温', '最低温', '天气状况'])for month in range(1,13):# 202302# 三元表达式 凑请求链接weather_time = '2022' + ('0' + str(month) if month < 10 else str(month))url = 'https://lishi.tianqi.com/xianyang/'+f'{weather_time}.html'# 调用函数并将结果添加到DataFrame中monthly_weather = getWeather(url)monthly_weather_df = pd.DataFrame(monthly_weather)weather_df = pd.concat([weather_df, monthly_weather_df])# response_time = time.time() - start_time# time.sleep(min(response_time, 5) + random.uniform(0.5, 1))print(weather_df)return weather_dfget_weather_data()数据库文件:
# file--Coonect_MySQl
import pymysql
from sqlalchemy import create_engine, MetaData, Table, Column, Float, String, Date
from sqlalchemy.exc import OperationalErrorfrom sqlalchemy import inspect
def save_to_database(weather_df):# 定义数据库连接参数db_config = {'host': '127.0.0.1', # 数据库地址'port': 3307, # 数据库端口'user': 'root', # 数据库用户名'password': '123456', # 数据库密码'database': 'weather', # 数据库名称}# 创建数据库引擎engine = create_engine(f'mysql+pymysql://{db_config["user"]}:{db_config["password"]}@{db_config["host"]}:{db_config["port"]}/{db_config["database"]}')# 测试数据库连接是否成功try:connection = engine.connect()print("数据库连接成功!")except Exception as e:print(f"数据库连接失败:{str(e)}")# 创建表(如果不存在)metadata = MetaData()table_name = 'weather_data'table_columns = [Column('日期', Date),Column('最高温', Float),Column('最低温', Float),Column('天气状况', String(255)),]weather_table = Table(table_name, metadata, *table_columns, extend_existing=True)# 检查表是否存在,如果不存在则创建表inspector = inspect(engine)if not inspector.has_table(table_name):# 注意这里需要传递 engine 到 create_all 方法中metadata.create_all(bind=engine)# 检查表是否存在,如果不存在则创建表try:metadata.create_all(engine)except OperationalError as oe:if "already exists" in str(oe): # 如果表已存在则忽略错误print("cunza")else:raise oeprint("表 'weather_data' 已经检查并创建完毕(如有必要)")# 将数据写入数据库if weather_df is not None and not weather_df.empty:weather_df.to_sql(name=table_name, con=engine, if_exists='append', index=False, dtype={'日期': Date,'最高温': Float,'最低温': Float,'天气状况': String(255),})print("数据已成功写入 'weather_data' 表.")else:print("未找到待写入数据库的数据.")主文件充当运行程序运行文件
from my_project.tianqi.tianqi import get_weather_data
from my_project.database.Connect_MySQL import save_to_database
def main():weather_df = get_weather_data()save_to_database(weather_df)if __name__ == "__main__":main()这是效果:
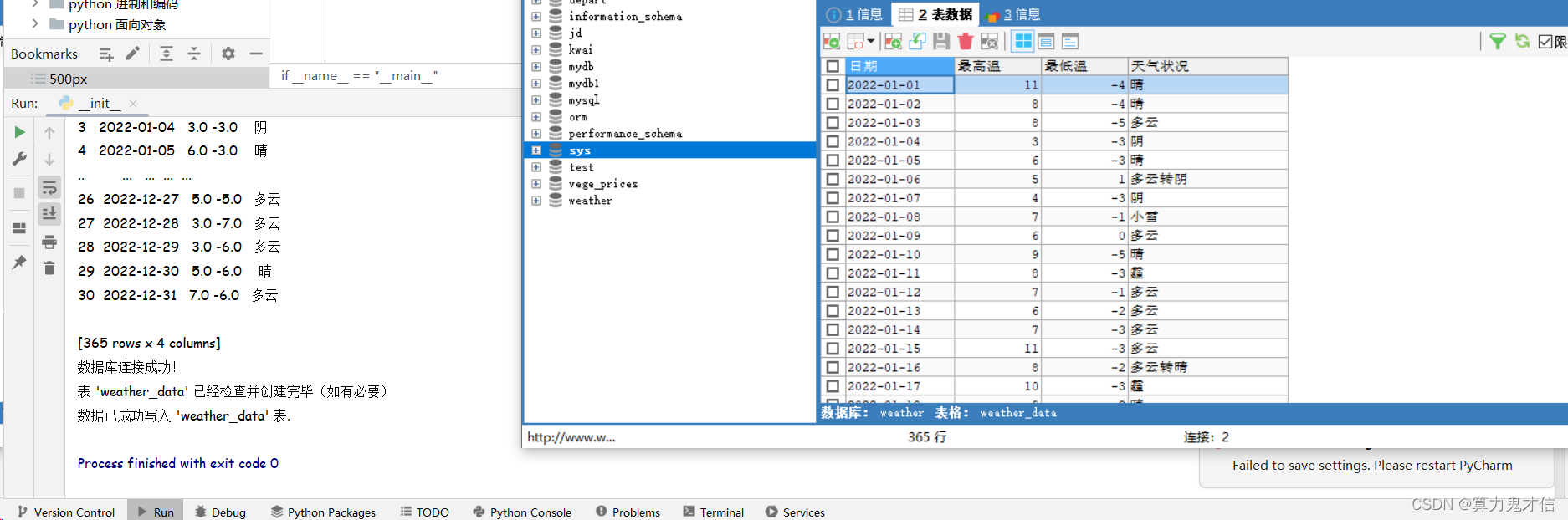
这里的很多技术难点我都是问的大模型,他们很聪明,完全能应付一些简单日常的问题。
希望帮到大家,祝大家安康