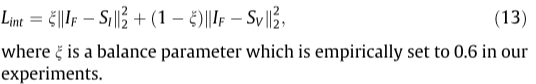Infrared and visible image fusion based on a two-stage class conditioned auto-encoder network
(基于两级类条件自编码器网络的红外与可见光图像融合)
现有的基于自动编码器的红外和可见光图像融合方法通常利用共享编码器从不同模态中提取特征,并在解码器部分之前采用手工融合策略将提取的特征融合成中间表示。在本文中,我们提出了一种新的两阶段类条件自动编码器的框架,高品质的多光谱融合任务。在第一个训练阶段,我们在编码器网络中引入了一个类嵌入子分支,用于对不同模态的特征进行建模,并根据输入模态自适应地缩放中间特征。此外,我们设计了一个交叉传输的残差块,以促进编码器中的内容和纹理信息流,以产生更具代表性的功能。在第二个训练阶段,我们在预训练的类条件编码器和解码器部分之间插入一个可学习的融合模块,以取代手工融合策略。利用特定的强度和梯度损失函数来调整模型,以便以数据驱动的方式融合独特的深度特征。通过类条件自动编码器和两阶段训练策略等重要设计,我们提出的TSClassstrom可以更好地保留源图像的独特信息/特征,并降低同时提取信息特征和确定最佳融合方案的训练难度。
Introduction
可见光成像传感器捕获可见光波段的反射光,生成具有丰富场景细节的图像,但在光线较差的条件下工作时,其性能受到严重影响。相比之下,红外传感器测量物体发出的热辐射,这在全天候和全天条件下保留了物体的显著结构,但不能很好地描绘局部纹理或细节。为了充分发挥多光谱传感器的优势,图像融合技术在融合从获取的可见光和红外图像中提取的互补信息方面发挥着重要作用。有效的多光谱融合解决方案可以为人类观察者或机器生成信息丰富的图像,以执行后续的视觉识别任务,如夜间监视,军事监控和医学成像。
为了执行高质量的多光谱融合任务,现有的传统方法通常部署适当的信号处理滤波器或表示技术来提取不同模态的特征,然后设计手工制作的策略来融合提取的可见光和红外特征。一些代表性的方法包括基于多尺度分解的方法、基于稀疏表示的方法、基于优化的模型、基于子空间聚类的方法、基于显著性的方法和混合方法。尽管他们取得了巨大的成功,这些传统的方法的性能是严重依赖于手工制作的特征提取器和融合规则,这遭受在不同的条件下的通用性差。
最近,已经提出了许多基于深度学习(DL)的方法来克服传统方法的缺点。这些方法探索了卷积神经网络(CNN)以数据驱动的方式构建最佳特征表示或/和融合策略的强大能力。一般来说,基于DL的融合方法可以分为两大类,包括端到端方法和非端到端方法。端到端基于DL的方法直接将单个源图像作为输入,并以无监督学习方式输出最终融合结果。为了简单起见,他们将特征提取器和融合策略的复杂设计集成到模型训练过程中,通过融合中间深度特征来实现更好的性能。然而,这些端到端基于DL的方法在训练过程中无法获得地面实况图像来指导特征提取和图像融合。因此,需要仔细设计损失函数来驱动端到端CNN模型的训练,并且很难同时确定保留哪些信息特征以及融合这些特征的最佳方案。因此,一些研究人员利用生成对抗网络(GAN)通过测量源图像和融合结果之间的特定数据分布来弥补重要信息丢失。然而,它们仍然需要手动确定融合目标,并且GAN的不稳定能力也可能在最终融合结果中产生严重的伪影。
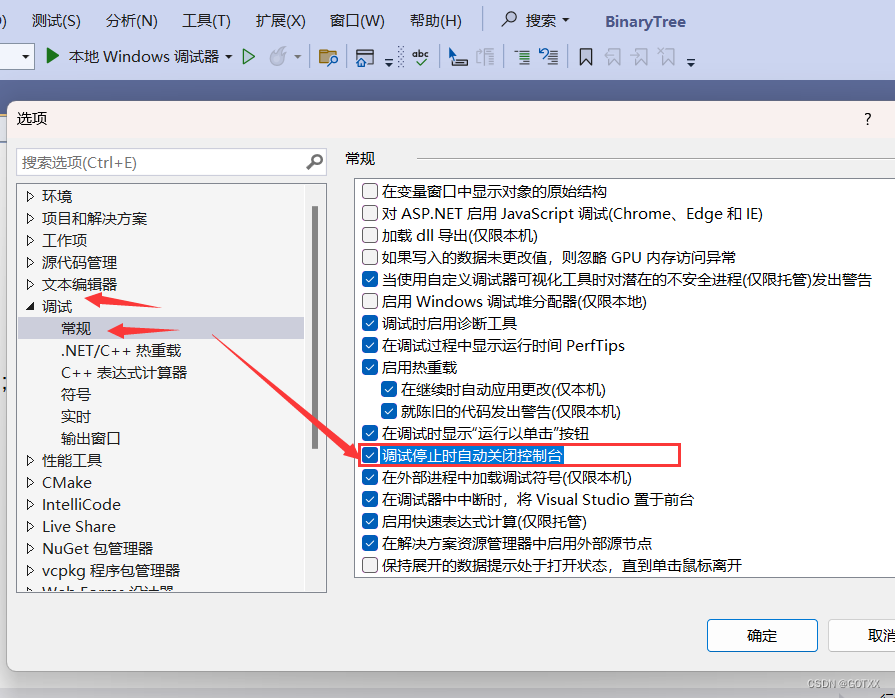
相比之下,非端到端方法利用多光谱输入图像作为地面实况来训练CNN网络(例如,自动编码器),其能够从源图像中提取信息特征并执行高保真图像重建。利用训练好的编码器从红外和可见光图像中提取深度特征,并采用手工融合策略整合互补特征。最后,在训练的自动编码器中的解码器处理融合的深度特征以生成融合结果。值得指出的是,编码器和解码器需要表现出强大的特征提取和重建能力,并以不同的方式保留输入图像的信息/特征。然而,现有的基于AE的多光谱融合方法通常使用如图1(a)所示的共享编码器来处理红外和可见光图像,忽略了红外和可见光光谱之间的数据差异,并且无法保留来自源图像的原始信息。非端到端方法的另一个值得注意的缺点是,它们仍然需要设计手工融合规则,以在解码器部分之前集成来自各个模态的特征。
为了解决上述问题,我们提出了一种新的两阶段类条件自动编码器框架,称为TS-ClassFuse。提出的TS-ClassFuse,首先执行自适应AE为基础的特征提取条件的输入模态,然后通过一个可学习的融合模块,有利于不同的模态的独特的中间特征的融合。更具体地说,我们将类嵌入子分支插入到编码器网络中,如图1(b)所示。类嵌入子分支对红外和可见光模态的数据特征进行建模,根据其类别自适应地缩放中间深度特征,以改进基于AE的方法,从而更好地保留信息。此外,我们还提出了一个交叉流残差块(CRB),以促进在特征提取过程中的内容和纹理信息流。受[12]的启发,我们进一步开发了一个具有特定强度和梯度损失项的可学习融合模块(LFM),以避免设计手工融合规则。通过两阶段和类条件设计,TS-ClassFuse 有效地增强了基于AE的多光谱特征提取方法的表示能力,并继承了端到端方法的简单性,而不需要手工制定融合规则。我们的方法的贡献总结如下:
1)我们提出了一种新的类条件自动编码器框架,以促进不同形式的自适应特征提取。与现有的非端到端的基于AE的方法相比,它集成了一个类嵌入子分支,以自适应地缩放中间深度特征,更好地保留来自源图像的信息/特征。此外,它部署了一个交叉传输残差块(CRB),以促进在特征提取过程中的内容和纹理信息的交互。
2)基于两阶段训练策略,我们首先训练类条件编码器-解码器网络,然后将可学习的融合模块插入到预先训练好的AE网络中。利用特定的强度和梯度损失函数来调整模型,以便以学习的方式融合独特的深度特征。这种两阶段训练方案降低了同时确定保留哪些信息特征和最佳特征融合方案的难度。
3)定性和定量实验都证明了我们提出的TS-ClassFuse 优于其他先进的多光谱图像融合方法,实现更好的融合效果,改善视觉效果,并在不同的情况下执行更一致。
Related works
Deep learning-based fusion approaches
数据驱动的CNN在不同的场景下表现出强大的表示能力,这激发了研究人员构建深度网络进行有效的图像融合。这些基于DL的方法通常分为两大类,包括(1)基于集成特征提取和融合功能的端到端方法;以及(2)基于基于CNN的特征提取和手工融合规则的非端到端融合方法。
End-to-end fusion approaches
为了避免设计手工制作的融合规则,Hou等人通过在编码器和解码器网络之间设置多个融合层,将Densetron 扩展到端到端学习框架。虽然PMGI 将源图像解耦为梯度和强度部分,但他们手动分配比例保留以完成各种图像融合任务。相比之下,U2Fusion 使用测量指标来自动改变不同融合任务中的信息保留程度。这些方法严重依赖于适当的损失函数来指导特征提取和重建方向。因此,Ma 等人首先引入了一种基于GAN的融合网络FusionGAN,其中采用了一种新的算法来强制融合结果从可见输入图像中获得更多的纹理细节。后来,AttentionFGAN 设计了一个基于GAN的框架,该框架具有以两种图像为条件的双阈值,它保留了来自不同模态的更多潜在内容或详细信息。由于的结果呈现出令人不快的视觉外观,Ma等人将多分类约束添加到具有单个分类器的基于GAN的融合网络中,其中多分类器迫使融合结果以更平衡的方式获得信息。
虽然端到端方法将融合策略与特征提取过程结合到一个统一的网络中,但由于缺乏对端到端训练任务的地面实况监督,它们需要定义详细的学习目标来驱动端到端CNN模型的训练,确定保留哪些信息特征以及同时融合这些特征的最佳方案。值得一提的是,基于GAN的融合方法经常面临的问题是,训练的稳定性并不总是得到保证,并且最终的融合结果包含不期望的伪影。
Non end-to-end fusion approaches
Li 等人首先提出了一种基于AE的框架,称为Densetron,其中密集连接被插入到编码器网络中以尽可能多地保留源信息,并且他们引入了一种额外的L1范数融合策略来融合这些显着特征,用于红外和可见光图像融合任务。后来,设计了一种基于嵌套连接的AE来提取多尺度深度特征,并使用一种新的空间和通道注意力融合策略来合并提取的特征。Jian等人提出了SEDR,他们在编码器部分重用来自浅层的补偿特征,弥补图像重建过程中丢失的细节。最近,Wang等人在编码器网络中部署了密集的Res2net块来提取多尺度深度特征。中间特征通过基于双重非局部注意力的融合策略进行融合。同时,为了进一步提高现有的基于嵌套连接的AE方法的表示能力,他们在编码器和解码器中引入了密集跳跃连接,并采用Lp归一化注意力模型来整合UNFusion中的特征。除了上述方法外,为了避免设计手工融合规则来融合中间深度特征,RFN-Nest 开发了一种两阶段训练策略,以共同提高AE网络的特征提取和特征重建能力。
已经进行了许多尝试来提高编码器-解码器网络的表示能力,例如跳过连接或多尺度学习。然而,大多数方法从不同模态的源图像中提取特征,而没有考虑它们的不同特性,导致潜在的信息/特征丢失。此外,通过级联卷积层处理内容和纹理信息可能不是最佳解决方案。
Conditional learning in neural networks
条件学习广泛用于各种计算机视觉任务。深度神经网络可以通过条件学习显式地利用来自输入数据的先验信息,从而更好地管理模型的优化并更有效地使用数据。例如,Su等人受到传统边缘检测器的启发,并开发了用于边缘检测的多像素差分卷积。Karras等人提出了一种带有潜在编码的映射网络来学习基于风格的潜在表示,然后将其专门用于在合成网络的每个卷积层之后进行自适应实例归一化,从而确保图像合成任务的灵活控制。在图像融合方面,最近提出的高光谱泛锐化模型EC-FTN 融合并转换了以边缘图先验为条件的中间特征。Tang等人提出了一种以光照变化为条件的门控机制,该机制引导他们的融合模型自适应地关注源图像中有意义的信息。受[28,29]的启发,我们的方法建立在实例归一化(IN)机制的基础上,并引入了一个类嵌入子分支来对多光谱图像之间的模态差异进行建模。
Proposed method
Network overview
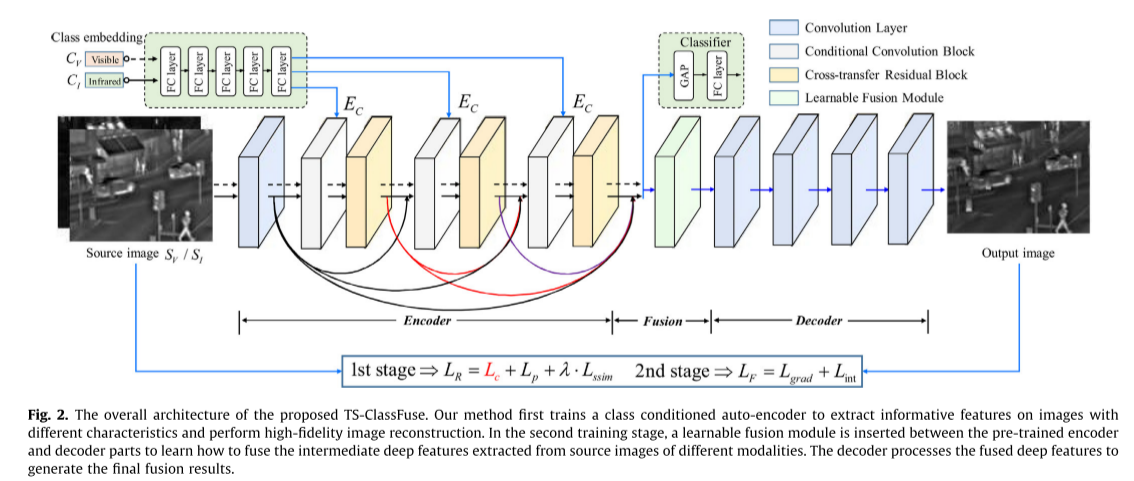
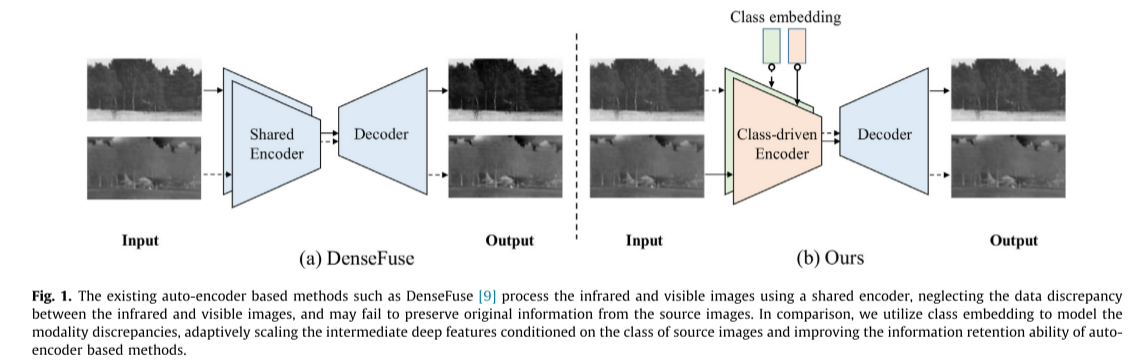
图2说明了我们提出的TSClassertia的总体流程图,其中涉及两个阶段的训练例程,以确定受[12]启发的图像重建和融合策略的过程。在第一阶段,我们训练一个类条件自动编码器网络,使其具有从不同模态中提取和重建信息特征的能力。这里的类条件自动编码器网络由编码器、解码器和小分类器子分支组成。单源可见光图像SV ∈ R H × W R^{H×W} RH×W 或红外图像SI ∈ R H × W R^{H×W} RH×W(H和W表示源图像的高度和宽度)将首先被发送到编码器部分,该编码器部分包括初始卷积层和三个重复的条件卷积块(CCB)模块,交叉传输残差块(CRB)。引入可学习的d维类嵌入向量CV 或CI ∈ R d R^d Rd对模态差异进行编码。该算法通过5个全连通层得到隐类嵌入EC ∈ R d R^d Rd,并在编码器的CCB中进行特征调整。注意,类嵌入向量CV 或CI 是随机初始化的,并且其参数在第一训练阶段之后是固定的。来自编码器的经由密集连接的调整后的特征被级联并发送到用于模态分类任务的小分类器头中,这隐含地引导编码器对不同模态执行区别性特征提取。解码器部分包含四个卷积层,用于重建输出图像O∈ R H × W R^{H×W} RH×W如前所述[9,22]。在第二个融合阶段,我们将可见光和红外图像沿着与特定模态的训练类嵌入一起发送到预训练类条件自动编码器中,并在编码器和解码器部分之间插入可学习融合模块(LFM)。利用特定的强度和梯度损失函数对LFM进行调整,将编码部分提取的不同深度特征进行融合,最后由解码器对融合后的深度特征进行处理,重构出最终的融合结果。
Class conditioned feature extraction
将输入图像本身视为地面实况,编码器-解码器网络打算从源可见光或红外图像中提取信息特征,然后在没有信息损失的情况下完全相同地重建它们。以往的基于AE的方法设计了一个编码器-解码器网络作为特征提取器,而没有考虑模态差异,这可能无法保留原始信息的源图像。因此,我们提出了一种新的类条件特征提取编码器,通过两个关键设计来获得不同的特征:(1)我们通过使用小的类嵌入子分支和正则化分类器来建模不同模态之间的类差异;(2)我们使用潜在的类嵌入和交叉路径特征转移来调整和细化内部深层特征。
对于编码器-解码器网络的每个优化步骤,我们将红外或可见光图像及其相关的类嵌入发送到编码器部分,如图2的实线流程或虚线流程所示。在初始卷积层之后,如图3(a)所示,输入特征FIn ∈ R 1 × c × H × W R^{1×c×H×W} R1×c×H×W的后续CCBs首先通过1×1卷积层生成F ∈ R 1 × d × H × W R^{1×d×H×W} R1×d×H×W,其中c和d分别表示FIn 和F的通道尺寸。同时,将相应的类条件向量CV或CI通过5个全连通层的嵌入网络进行变换,得到潜在类嵌入EC,然后将其传递到2个全连通层,产生2个归一化系数γ ∈ R 1 × d R^{1×d} R1×d和∈ R 1 × d R^{1×d} R1×d。AdaIN [32,28,29]基于其类对特征F执行自适应实例归一化,
AdaIN的输出要素后接LeakyReLU图层,以生成调整后的要素FOut ∈ R 1 × d × H × W R^{1×d×H×W} R1×d×H×W。CCB进行规范化过程的帮助下,类特定的差异信息,从潜在的类嵌入EC,从而促进灵活的特征调整的输入图像的类的条件,以提高编码器部分的表示能力。
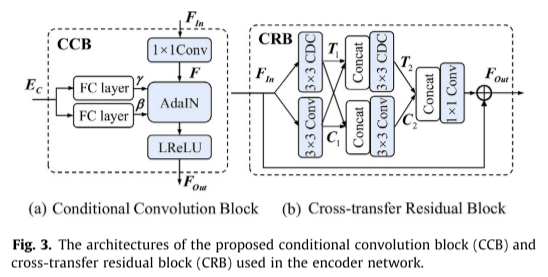
除了在不同的场景中聚合不同的特征外,我们还引入了交叉传输残差块(CRB),以通过两个特征流路径之间的信息传输进一步细化图像特征,如图3(b)所示。CRB涉及两个不同的路径,包括纹理路径(FIN→T1→T2)和内容路径(FIN→C1→C2)。对于纹理路径,我们采用中心差分卷积(CDC)来计算反映纹理模式的局部像素关系,
路径间纹理和内容信息的交换带来了相互促进,使其在执行后续特征提取步骤之前能够预融合和增强有意义的信息
Learnable fusion strategy
经过第一阶段的训练,类条件自动编码器表现出强大的特征提取和图像重建能力。在第二阶段,我们修复了自动编码器,并在编码器和解码器部分之间添加了可学习的融合模块,其目的是通过预训练的编码器融合在不同源图像上提取的独特特征。正如许多现有的基于AE的方法所建议的那样,它可以通过关注显著信息或特征来更好地探索不同图像模态之间的特征相关性。因此,我们设计了一个基于空间和通道注意机制的可学习融合模块,以更好地从不同的模态中捕获适当的特征,如图4所示。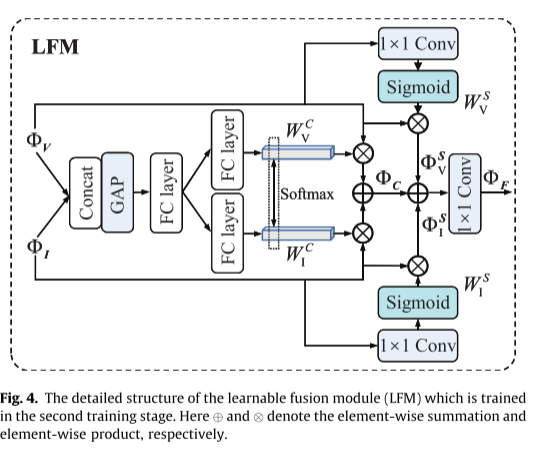
让ΦV和ΦI表示由预训练的编码器提取的可见光和红外特征。对于通道注意机制,我们首先采用全局平均池(GAP)和一个全连接层(FC)的级联可见光和红外特征,以获得类间通道的描述符。然后,部署两个单独的FCs沿着Softmax函数,以分别获得针对可见光和红外模态的通道注意力权重 W C W^C WCV和 W C W^C WCI。融合的通道注意力特征ΦC通过输入特征与其对应的通道注意力权重之间的乘法获得,如下:
对于空间注意力机制,采用简单的1×1卷积层和Sigmoid函数来获得输入特征的每一侧上的空间方面的注意力权重 W S W^S WSV和 W S W^S WSI。然后,我们将空间方向的注意力权重与它们对应的输入特征相乘,以得到融合的空间注意力特征ΦS,
最后,我们将融合的通道注意力特征ΦC与融合的空间注意力特征ΦS相加,并使用附加的1×1卷积层来得到最终的融合特征ΦF,
Loss functions
基于训练阶段,损失函数被分成两部分:第一训练阶段中的类调节自动编码器网络的重构损失LR和第二训练阶段中的可学习融合模块的融合损失LF。
(1) Reconstruction Loss LR: 在第一阶段,类条件自动编码器网络利用输入图像本身及其类标签作为基础事实来监督优化过程。总损失函数由编码器-解码器网络的基本学习目标LBasic和类嵌入子分支的特定分类损失LClass组成,
遵循之前基于AE的方法,我们采用结构相似性指数度量(SSIM)[34]和均方误差损失来构建基本学习目标,
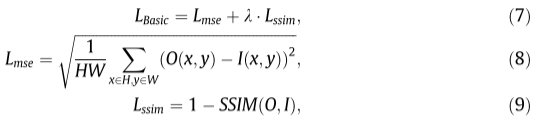
其中H; W是输入源图像I和重建图像O的高度和宽度; λ是权衡超参数,其根据先前的工作经验设置为10 。为了便于类条件特征提取,我们进一步将缩放的中间特征从编码器发送到小分类头,并采用标准的交叉熵损失来构建分类损失,
(2) Fusion Loss LF: 在第二阶段中,融合损失LF引导可学习融合模块整合不同源图像上提取的区别性特征,以供后续解码器生成最终融合结果。在我们的模型中,我们的目标是从源图像中保留两种有意义的信息,即,表征热辐射或以高对比度反射重要区域的强度信息,以及表示来自可见光和红外图像的纹理细节的梯度信息,

我们认为在两个源图像的梯度同样重要,并计算一个额外的目标来约束融合图像的梯度信息。
强度损失Lint约束融合图像以保持与源图像相似的强度分布,以便保留显著的对比度信息,