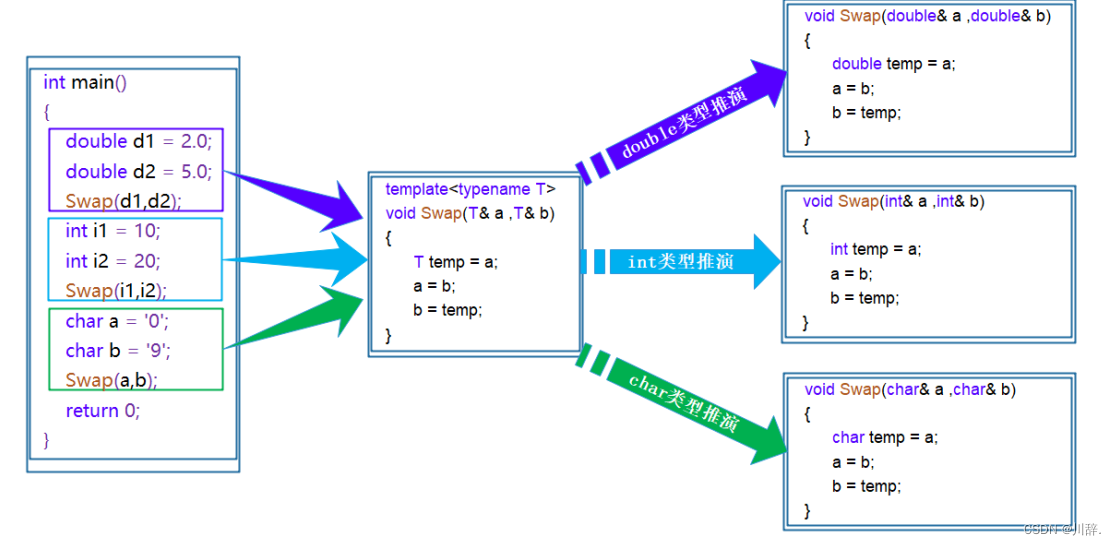
AI视野·今日CS.NLP 自然语言处理论文速览
Tue, 5 Mar 2024 (showing first 100 of 175 entries)
Totally 100 papers
👉上期速览✈更多精彩请移步主页

Daily Computation and Language Papers
| Key-Point-Driven Data Synthesis with its Enhancement on Mathematical Reasoning Authors Yiming Huang, Xiao Liu, Yeyun Gong, Zhibin Gou, Yelong Shen, Nan Duan, Weizhu Chen 大型语言模型法学硕士在复杂的推理任务中表现出了巨大的潜力,但其性能往往因缺乏高质量、以推理为重点的训练数据集而受到阻碍。为了应对这一挑战,我们提出了关键点驱动数据合成 KPDDS,这是一种新颖的数据合成框架,它通过利用来自真实数据源的关键点和样本对来合成问题答案对。 KPDDS 通过严格的质量控制和显着的可扩展性确保新颖问题的生成。因此,我们推出了 KPMath,这是迄今为止为数学推理量身定制的最广泛的综合数据集,包含超过一百万个问题答案对。利用 KPMath 并通过额外的推理密集型语料库对其进行增强,我们创建了全面的 KPMath Plus 数据集。在 KPMath Plus 上微调 Mistral 7B 模型可在 MATH 测试集上获得 39.3 的零样本 PASS 1 准确度,该性能不仅超过其他微调的 7B 模型,还超过某些 34B 模型。 |
| Detection of Non-recorded Word Senses in English and Swedish Authors Jonathan Lautenschlager, Emma Sk ldberg, Simon Hengchen, Dominik Schlechtweg 这项研究解决了英语和瑞典语中未知意义检测的任务。此任务的主要目标是确定特定单词用法的含义是否记录在字典中。为此,使用预先训练的“上下文中的单词”嵌入器将意义条目与现代和历史语料库中的单词用法进行比较,该嵌入器允许我们在几个镜头场景中对该任务进行建模。此外,我们使用人工注释来调整和评估我们的模型。 |
| Emotion Granularity from Text: An Aggregate-Level Indicator of Mental Health Authors Krishnapriya Vishnubhotla, Daniela Teodorescu, Mallory J. Feldman, Kristen A. Lindquist, Saif M. Mohammad 我们一致认为情绪是塑造我们经历的核心,但个体在识别、分类和表达情绪的方式上却存在很大差异。在心理学中,个体区分情绪概念的能力的变化被称为情绪粒度,它是通过一个人的情绪自我报告来确定的。高情绪粒度与更好的心理和身体健康有关,而低情绪粒度与适应不良的情绪调节策略和不良的健康结果有关。在这项工作中,我们提出了从社交媒体中按时间排序的说话者话语衍生的情感粒度的计算测量,以代替遭受各种偏见的自我报告。然后,我们研究了这种文本衍生的情感粒度测量作为各种心理健康状况 MHC 标记的有效性。我们建立了从文本话语中得出的情绪粒度的基线测量,并表明,在总体水平上,自我报告具有 MHC 的人的情绪粒度明显低于对照人群。 |
| RIFF: Learning to Rephrase Inputs for Few-shot Fine-tuning of Language Models Authors Saeed Najafi, Alona Fyshe 预先训练的语言模型 PLM 可以针对下游文本处理任务进行精确微调。最近,研究人员推出了几种参数有效的微调方法,可以优化输入提示或调整少量模型参数,例如 LoRA。在本研究中,我们结合参数高效的微调方法探讨了改变原始任务的输入文本的影响。为了最有效地重写输入文本,我们训练了一些具有最大边际似然目标的镜头释义模型。 |
| FENICE: Factuality Evaluation of summarization based on Natural language Inference and Claim Extraction Authors Alessandro Scir , Karim Ghonim, Roberto Navigli 文本摘要方面的最新进展,特别是随着大型语言模型法学硕士的出现,已经显示出卓越的性能。然而,一个显着的挑战仍然存在,因为大量自动生成的摘要表现出事实不一致,例如幻觉。针对这个问题,出现了各种评估摘要一致性的方法。然而,这些新引入的指标面临着一些局限性,包括缺乏可解释性、关注简短的文档摘要(例如新闻文章)以及计算不切实际,特别是对于基于 LLM 的指标。为了解决这些缺点,我们提出了基于自然语言推理和声明提取的摘要的事实性评估 FENICE,这是一种更可解释和更有效的面向事实的指标。 FENICE 利用源文档中的信息与从摘要中提取的一组原子事实(称为声明)之间基于 NLI 的对齐。我们的指标为 AGGREFACT 设定了新的技术水平,这是事实性评估的事实上的基准。 |
| Subjective $\textit{Isms}$? On the Danger of Conflating Hate and Offence in Abusive Language Detection Authors Amanda Cercas Curry, Gavin Abercrombie, Zeerak Talat 受标签变化的推动,自然语言处理研究已经开始接受注释者主观性的概念。这种方法将每个注释者的观点理解为有效的,这非常适合嵌入主观性的任务,例如情感分析。然而,这种结构可能不适合仇恨言论检测等任务,因为它为所有关于性别歧视或种族主义的立场提供了同等的有效性。 |
| Birbal: An efficient 7B instruct-model fine-tuned with curated datasets Authors Ashvini Kumar Jindal, Pawan Kumar Rajpoot, Ankur Parikh 由于硬件要求,LLMOps 会产生大量成本,阻碍了其广泛使用。此外,模型训练方法和数据缺乏透明度导致大多数模型不可重现。为了应对这些挑战,NeurIPS Workshop 上推出了 LLM 效率挑战赛,旨在通过在 24 小时内对单个 GPU RTX 4090 或 40GB 的 A100 进行微调,使基础模型适应不同的任务。在本系统描述论文中,我们介绍了 Birbal,这是我们基于 Mistral 7B 的获胜模型,在单个 RTX 4090 上进行了 16 小时的微调。 |
| PHAnToM: Personality Has An Effect on Theory-of-Mind Reasoning in Large Language Models Authors Fiona Anting Tan, Gerard Christopher Yeo, Fanyou Wu, Weijie Xu, Vinija Jain, Aman Chadha, Kokil Jaidka, Yang Liu, See Kiong Ng 大型语言模型法学硕士的最新进展表明,他们的能力在自然语言处理的许多任务中与人类相当,甚至优于人类。尽管取得了这些进展,法学硕士在人类天生擅长的社会认知推理方面仍然存在不足。本研究从关于某些人格特质与心智理论 ToM 推理之间联系的心理学研究中汲取灵感,并从提示对影响法学硕士能力的超敏感性的提示工程学研究中汲取灵感,研究了使用提示诱导法学硕士的个性如何影响他们的 ToM 推理能力。我们的研究结果表明,某些诱发的个性可以显着影响法学硕士在三种不同 ToM 任务中的推理能力。特别是,来自黑暗三合会的特征对跨不同 ToM 任务的 GPT 3.5、Llama 2 和 Mistral 等 LLM 具有更大的可变影响。我们发现,在 ToM 中的人格提示中表现出较高方差的法学硕士在人格测试中也往往更可控,像 GPT 3.5、Llama 2 和 Mistral 这样的法学硕士的人格特征可以通过我们的人格提示进行可控调整。 |
| Not all Layers of LLMs are Necessary during Inference Authors Siqi Fan, Xin Jiang, Xiang Li, Xuying Meng, Peng Han, Shuo Shang, Aixin Sun, Yequan Wang, Zhongyuan Wang 大型语言模型法学硕士的推理阶段非常昂贵。法学硕士的理想推理阶段可以利用更少的计算资源,同时仍然保持其能力,例如泛化和上下文学习能力。在本文中,我们试图回答这样的问题:在LLM推理过程中,我们是否可以对简单实例使用浅层,对困难实例使用深层。为了回答这个问题,我们首先通过统计分析激活的层来表明在推理过程中并非所有层都是必需的。跨任务层。然后,我们提出了一种名为 AdaInfer 的简单算法,用于根据输入实例自适应地确定推理终止时刻。更重要的是,AdaInfer 不会改变 LLM 参数并保持跨任务的通用性。在著名的 Llama2 系列和 OPT 等著名 LLM 上进行的实验表明,AdaInfer 在保持相当的性能的同时,平均节省了 14.8 的计算资源,在情感任务上甚至节省了 50 的计算资源。 |
| Masked Thought: Simply Masking Partial Reasoning Steps Can Improve Mathematical Reasoning Learning of Language Models Authors Changyu Chen, Xiting Wang, Ting En Lin, Ang Lv, Yuchuan Wu, Xin Gao, Ji Rong Wen, Rui Yan, Yongbin Li 在推理任务中,即使是很小的错误也可能会导致不准确的结果,从而导致大型语言模型在此类领域的性能不佳。早期的微调方法试图通过利用来自人类标签、更大模型或自采样的更精确的监督信号来缓解这一问题,尽管成本很高。相反,我们开发了一种避免外部资源的方法,而是依赖于对输入引入扰动。我们的训练方法随机掩盖思维链中的某些标记,我们发现这种技术对于推理任务特别有效。当应用于 GSM8K 的微调时,该方法在修改了一些代码且无需额外标记工作的情况下,比标准监督微调的精度提高了 5 倍。此外,它是对现有方法的补充。当与相关的数据增强方法集成时,在不同质量和大小的五个数据集以及两个基础模型中,GSM8K 精度平均提高 3 倍,数学精度平均提高 1 倍。我们通过案例研究和定量分析进一步研究了这种改进背后的机制,表明我们的方法可以为模型捕获长距离依赖关系(尤其是与问题相关的依赖关系)提供卓越的支持。这种增强可以加深对问题和先前步骤中前提的理解。 |
| ProTrix: Building Models for Planning and Reasoning over Tables with Sentence Context Authors Zirui Wu, Yansong Feng 表格在各个领域的信息传递中发挥着至关重要的作用,是以结构化方式组织和呈现数据的不可或缺的工具。我们提出了一个 Plan then Reason 框架来回答不同类型的用户对具有句子上下文的表的查询。该框架首先规划上下文的推理路径,然后将每个步骤分配给基于程序或文本的推理以得出最终答案。我们按照框架构建了一个指令调优集TrixInstruct。我们的数据集涵盖了程序无法解决的查询或需要结合表格和句子中的信息以获得规划和推理能力的查询。我们通过在 TrixInstruct 上微调 Llama 2 7B 来展示 ProTrix。我们的实验表明,ProTrix 可以推广到各种表格任务,并实现与 GPT 3.5 Turbo 相当的性能。我们进一步证明 ProTrix 可以生成准确且忠实的解释来回答复杂的自由形式问题。我们的工作强调了规划和推理能力对于具有普遍性和可解释性的表格任务模型的重要性。 |
| EEE-QA: Exploring Effective and Efficient Question-Answer Representations Authors Zhanghao Hu, Yijun Yang, Junjie Xu, Yifu Qiu, Pinzhen Chen 当前的问答方法依赖于 RoBERTa 等预先训练的语言模型 PLM。这项工作挑战了现有的问题答案编码约定,并探索了更精细的表示。我们首先测试各种池化方法,与使用句子开头标记作为问题表示以获得更好的质量进行比较。接下来,我们探索将所有候选答案同时嵌入问题的机会。这可以实现答案选择之间的交叉引用,并通过减少内存使用来提高推理吞吐量。尽管它们简单有效,但这些方法尚未在当前框架中得到广泛研究。我们尝试了不同的 PLM,以及集成或不集成知识图谱的情况。结果证明,所提出的技术的记忆功效几乎没有牺牲性能。实际上,我们的工作通过允许相当大的批量大小,在消费级 GPU 上提高了 38 100 的吞吐量和 26 65 的加速。 |
| What has LeBenchmark Learnt about French Syntax? Authors Zdravko Dugonji , Adrien Pupier, Benjamin Lecouteux, Maximin Coavoux 该论文报告了一系列旨在探索 LeBenchmark(一种经过 7000 小时法语口语训练的预训练声学模型)以获取句法信息的实验。预训练声学模型越来越多地用于下游语音任务,例如自动语音识别、语音翻译、口语理解或语音解析。他们接受原始语音信号的非常低级信息的训练,并且没有明确的词汇知识。尽管如此,他们在需要更高水平语言知识的任务上取得了合理的结果。因此,一个新出现的问题是这些模型是否编码句法信息。我们使用 Orf o 树库探测 LeBenchmark 的每个表示层的语法,并观察到它已经学习了一些语法信息。 |
| Using LLMs for the Extraction and Normalization of Product Attribute Values Authors Nick Baumann, Alexander Brinkmann, Christian Bizer 电子商务网站上的产品报价通常由文本产品标题和文本产品描述组成。为了提供分面产品过滤或基于内容的产品推荐等功能,网站需要从非结构化产品描述中提取属性值对。本文探讨了使用大型语言模型 LLM(例如 OpenAI 的 GPT 3.5 和 GPT 4)从产品标题和产品描述中提取和规范化属性值的潜力。对于我们的实验,我们引入了 WDC 产品属性值提取 WDC PAVE 数据集。 |
| Leveraging Weakly Annotated Data for Hate Speech Detection in Code-Mixed Hinglish: A Feasibility-Driven Transfer Learning Approach with Large Language Models Authors Sargam Yadav 1 , Abhishek Kaushik 1 , Kevin McDaid 1 1 Dundalk Institute of Technology, Dundalk 大型语言模型法学硕士的出现提高了各种自然语言处理 NLP 任务的基准。然而,训练法学硕士需要大量有标签的训练数据。此外,数据注释和训练在计算上是昂贵且耗时的。零样本和少样本学习最近已成为使用大型预训练模型标记数据的可行选择。混合代码低资源语言中的仇恨语音检测是一个活跃的问题领域,LLM 的使用已被证明是有益的。在这项研究中,我们编制了包含 100 条 YouTube 评论的数据集,并在混合代码印度英语中对它们进行了粗粒度和细粒度的厌女症分类的弱标记。由于标注过程需要大量劳动,因此应用了弱标注。然后应用零样本学习、一样本学习以及少量样本学习和提示方法来为评论分配标签,并将它们与人类分配的标签进行比较。 |
| Automated Generation of Multiple-Choice Cloze Questions for Assessing English Vocabulary Using GPT-turbo 3.5 Authors Qiao Wang, Ralph Rose, Naho Orita, Ayaka Sugawara 评估语言学习者对词汇掌握程度的常见方法是通过多项选择完形填空,即填空问题。但对于个别教师或大型语言项目来说,创建测试项目可能很费力。在本文中,我们评估了一种使用大型语言模型 LLM 自动生成此类问题的新方法。 VocaTT词汇教学和训练引擎是用Python编写的,包括三个基本步骤:预处理目标单词列表,使用GPT生成句子和候选单词选项,最后选择合适的单词选项。为了测试该系统的效率,针对学术词汇生成了 60 个问题。生成的项目由专家评审员评审,他们判断句子和单词选项的格式是否良好,并为判断为格式不正确的项目添加评论。结果显示,句子的格式正确率为 75,单词选项的正确率为 66.85。与我们研究中早期使用的生成器相比,这是一个显着的改进,该生成器没有利用 GPT 的功能。 |
| Topic Aware Probing: From Sentence Length Prediction to Idiom Identification how reliant are Neural Language Models on Topic? Authors Vasudevan Nedumpozhimana, John D. Kelleher 基于 Transformer 的神经语言模型在各种自然语言处理任务上实现了最先进的性能。然而,一个悬而未决的问题是,这些模型在处理自然语言时在多大程度上依赖于词序句法或词共现主题信息。这项工作通过解决这些模型是否主要使用主题作为信号的问题,通过探索基于 Transformer 的模型 BERT 和 RoBERTa 在一系列英语探测任务(从简单的词汇任务(例如句子)中)的表现之间的关系,为这场辩论做出了贡献对成语标记识别等复杂语义任务的长度预测,以及这些任务对主题信息的敏感性。为此,我们提出了一种新颖的探测方法,称为主题感知探测。我们的初步结果表明,基于 Transformer 的模型在其中间层中对主题和非主题信息进行编码,而且这些模型区分惯用用法的能力主要基于它们识别和编码主题的能力。 |
| LLM-Oriented Retrieval Tuner Authors Si Sun, Hanqing Zhang, Zhiyuan Liu, Jie Bao, Dawei Song 密集检索 DR 现在被认为是一种很有前途的工具,可以通过合并外部存储器来增强 GPT3 和 GPT 4 等大型语言模型 LLM 的记忆能力。然而,由于LLM和DR的文本生成之间的范式差异,将检索和生成任务集成到共享LLM中仍然是一个开放的挑战。在本文中,我们提出了一种高效的面向LLM的检索调谐器,即LMORT,它将DR容量与基础LLM解耦,并以非侵入方式将LLM的最佳对齐和均匀层协调到统一的DR空间,从而无需调整即可实现高效且有效的DR法学硕士本身。 |
| Vanilla Transformers are Transfer Capability Teachers Authors Xin Lu, Yanyan Zhao, Bing Qin 最近,Mixture of Experts MoE Transformers 由于其在模型容量和计算效率方面的优势而受到越来越多的关注。然而,研究表明,MoE Transformers 在许多下游任务中表现不如普通 Transformers,从而显着削弱了 MoE 模型的实用价值。为了解释这个问题,我们提出模型的预训练性能和迁移能力是其下游任务性能的共同决定因素。与普通模型相比,MoE 模型的传输能力较差,导致其在下游任务中的性能不佳。为了解决这个问题,我们引入了转移能力蒸馏的概念,认为虽然普通模型的性能较弱,但它们是转移能力的有效老师。以普通模型为指导的 MoE 模型可以实现强大的预训练性能和迁移能力,最终提高其在下游任务中的性能。我们设计了特定的蒸馏方法并在 BERT 架构上进行了实验。实验结果表明MoE模型的下游性能有了显着改善,许多进一步的证据也有力地支持了转移能力蒸馏的概念。 |
| FakeNewsGPT4: Advancing Multimodal Fake News Detection through Knowledge-Augmented LVLMs Authors Xuannan Liu, Peipei Li, Huaibo Huang, Zekun Li, Xing Cui, Jiahao Liang, Lixiong Qin, Weihong Deng, Zhaofeng He 多模态假新闻的大量产生表现出巨大的分布差异,促使需要通用检测器。然而,特定领域内训练的隔离性质限制了经典检测器获取开放世界事实的能力。在本文中,我们提出了 FakeNewsGPT4,这是一种新颖的框架,它通过用于操纵推理的伪造特定知识来增强大视觉语言模型 LVLM,同时继承广泛的世界知识作为补充。 FakeNewsGPT4 中的知识增强涉及获取两种类型的伪造特定知识,即语义相关性和工件追踪,并将它们合并到 LVLM 中。具体来说,我们设计了一个多级跨模态推理模块,该模块建立跨模态的交互以提取语义相关性。同时,提出了双分支细粒度验证模块来理解局部细节以对工件痕迹进行编码。生成的知识被转化为与 LVLM 兼容的精细嵌入。我们还结合了候选答案启发式和软提示来增强输入信息量。对公共基准的大量实验表明,与以前的方法相比,FakeNewsGPT4 实现了卓越的跨域性能。 |
| Transformers for Low-Resource Languages:Is Féidir Linn! Authors S amus Lankford, Haithem Afli, Andy Way Transformer 模型是机器翻译领域的最新技术。然而,一般来说,神经翻译模型在训练数据不足的语言对上通常表现不佳。因此,在低资源语言对上使用这种架构进行的实验相对较少。在本研究中,评估了 Transformer 模型在翻译低资源英语爱尔兰语对时的超参数优化。我们证明,选择适当的参数可以带来显着的性能改进。最重要的是,子词模型的正确选择被证明是翻译性能的最大驱动力。使用一元语法和 BPE 方法的 SentencePiece 模型进行了评估。模型架构的变化包括修改层数、测试各种正则化技术以及评估注意力的最佳头部数量。使用通用 55k DGT 语料库和域内 88k 公共管理语料库进行评估。与基线 RNN 模型相比,Transformer 优化模型的 BLEU 分数提高了 7.8 分。包括 TER 在内的一系列指标都得到了改进,这表明具有 16k BPE 子字模型的 Transformer 优化模型的后期编辑工作量大大减少。在与 Google 翻译的基准测试中,我们的翻译引擎表现出了显着的改进。变形金刚是否可以在英语爱尔兰语翻译资源匮乏的情况下有效使用的问题已经得到解决。 |
| Language and Speech Technology for Central Kurdish Varieties Authors Sina Ahmadi, Daban Q. Jaff, Md Mahfuz Ibn Alam, Antonios Anastasopoulos 库尔德语是一种印欧语言,有超过 3000 万使用者使用,被认为是一个方言连续体,并以其语言变体的多样性而闻名。先前针对库尔德语的语言和语音技术的研究将其作为宏观语言以单一的方式处理,导致方言和变体之间存在差异,而可用的资源和工具很少。在本文中,我们朝着开发中库尔德语各种语言和语音技术资源的方向迈出了一步,通过转录电影和电视剧来创建语料库,作为实地考察的替代方案。此外,我们还报告了机器翻译、自动语音识别和语言识别的性能,作为对中部库尔德语品种进行评估的下游任务。 |
| SciAssess: Benchmarking LLM Proficiency in Scientific Literature Analysis Authors Hengxing Cai, Xiaochen Cai, Junhan Chang, Sihang Li, Lin Yao, Changxin Wang, Zhifeng Gao, Yongge Li, Mujie Lin, Shuwen Yang, Jiankun Wang, Yuqi Yin, Yaqi Li, Linfeng Zhang, Guolin Ke 大型语言模型法学硕士最近取得的突破彻底改变了自然语言的理解和生成,激发了人们对利用这些技术进行科学文献分析的微妙领域的兴趣。然而,现有的基准不足以评估法学硕士在科学领域的熟练程度,特别是在涉及复杂理解和多模态数据的场景中。为此,我们推出了 SciAssess,这是一个专为深入分析科学文献而定制的基准,旨在对法学硕士的功效进行全面评估。 SciAssess 专注于评估法学硕士在科学背景下的记忆、理解和分析能力。它包括来自不同科学领域的代表性任务,例如普通化学、有机材料和合金材料。严格的质量控制措施确保其在正确性、匿名性和版权合规性方面的可靠性。 SciAssess 评估领先的法学硕士,包括 GPT 4、GPT 3.5 Turbo 和 Gemini,确定其优势和需要改进的领域,并支持法学硕士在科学文献分析中的应用的持续开发。 |
| Multi-perspective Improvement of Knowledge Graph Completion with Large Language Models Authors Derong Xu, Ziheng Zhang, Zhenxi Lin, Xian Wu, Zhihong Zhu, Tong Xu, Xiangyu Zhao, Yefeng Zheng, Enhong Chen 知识图补全 KGC 是一种广泛使用的方法,通过对缺失链接进行预测来解决知识图 KG 中的不完整性问题。基于描述的 KGC 利用预先训练的语言模型来学习实体和关系表示及其名称或描述,这显示出有希望的结果。然而,基于描述的 KGC 的性能仍然受到文本质量和不完整结构的限制,因为它缺乏足够的实体描述并且仅依赖关系名称,导致次优结果。为了解决这个问题,我们提出了MPIKGC,一个通用框架,通过从不同角度查询大语言模型LLM来弥补上下文知识的不足并改进KGC,其中涉及利用LLM的推理、解释和总结能力来扩展实体描述,分别理解关系和提取结构。 |
| AS-ES Learning: Towards Efficient CoT Learning in Small Models Authors Nuwa Xi, Yuhan Chen, Sendong Zhao, Haochun Wang, Bing Qin, Ting Liu 思想链 CoT 是法学硕士的一项重要的新兴能力,尤其是在逻辑推理方面。人们已经尝试通过从大型语言模型法学硕士生成的 CoT 数据中提取数据,在小型模型中引入这种能力。然而,现有方法通常只是简单地生成并合并来自法学硕士的更多数据,而没有注意到有效利用现有 CoT 数据的重要性。我们在这里提出了一种新的训练范式 AS ES Abstractive Segments Extractive Segments 学习,它利用 CoT 中的固有信息进行迭代生成。实验表明,我们的方法超越了在 MWP 和 PET 总结等 CoT 广泛任务上的直接 seq2seq 训练,无需数据增强或改变模型本身。 |
| DECIDER: A Rule-Controllable Decoding Strategy for Language Generation by Imitating Dual-System Cognitive Theory Authors Chen Xu, Tian Lan, Changlong Yu, Wei Wang, Jun Gao, Yu Ji, Qunxi Dong, Kun Qian, Piji Li, Wei Bi, Bin Hu 基于词典的约束解码方法旨在通过某些目标概念来控制生成文本的含义或风格。现有方法过度关注目标本身,导致缺乏关于如何实现目标的高级推理。然而,人类通常通过遵循某些规则来处理任务,这些规则不仅关注目标,而且关注引起目标出现的语义相关概念。在这项工作中,我们提出了 DECIDER,一种受双系统认知理论启发的用于约束语言生成的规则可控解码策略。具体来说,在 DECIDER 中,预训练的语言模型 PLM 配备了逻辑推理器,该逻辑推理器将高级规则作为输入。然后,DECIDER 允许规则信号在每个解码步骤流入 PLM。 |
| VariErr NLI: Separating Annotation Error from Human Label Variation Authors Leon Weber Genzel, Siyao Peng, Marie Catherine de Marneffe, Barbara Plank 当注释者出于正当理由为同一项目分配不同的标签时,就会出现人工标签变化,而当由于无效原因分配标签时,就会出现注释错误。这两个问题在 NLP 基准测试中普遍存在,但现有研究对它们进行了孤立的研究。据我们所知,之前没有任何工作专注于区分信号中的错误,特别是在信号超出黑白范围的情况下。为了填补这一空白,我们引入了一种系统方法和一个新的数据集,VariErr 变化与误差,重点关注英语 NLI 任务。我们提出了一个 2 轮注释方案,其中注释器解释每个标签,然后判断标签解释对的有效性。 name 包含对 500 个重新注释的 NLI 项目的 1,933 个解释的 7,574 个有效性判断。我们评估了各种自动错误检测 AED 方法和 GPT 在发现错误与人类标签变化方面的有效性。我们发现,与 GPT 和人类相比,最先进的 AED 方法的表现明显较差。虽然 GPT 4 是最好的系统,但它仍然低于人类的表现。 |
| Analyzing and Adapting Large Language Models for Few-Shot Multilingual NLU: Are We There Yet? Authors Evgeniia Razumovskaia, Ivan Vuli , Anna Korhonen 有监督微调 SFT、有监督指令调整 SIT 和上下文学习 ICL 是少镜头学习的三种替代方法,事实上的标准方法。随着法学硕士的出现,ICL 由于其简单性和样本效率而最近受到欢迎。先前的研究仅对这些方法如何用于多语言少量镜头学习进行了有限的调查,并且迄今为止的焦点主要集中在它们的性能上。在这项工作中,我们对这三种方法进行了广泛而系统的比较,并在 6 种高资源和低资源语言、三种不同的 NLU 任务以及多种语言和领域设置上对其进行了测试。重要的是,性能只是比较的一方面,我们还通过计算、推理和财务成本来分析这些方法。我们的观察表明,监督指令调优在性能和资源需求之间具有最佳权衡。作为另一项贡献,我们分析了预训练法学硕士的目标语言适应的影响,发现标准适应方法可以表面上提高目标语言生成能力,但通过 ICL 引发的语言理解并没有改善,而且仍然有限,得分较低,尤其是在资源匮乏的情况下 |
| IndicVoices: Towards building an Inclusive Multilingual Speech Dataset for Indian Languages Authors Tahir Javed, Janki Atul Nawale, Eldho Ittan George, Sakshi Joshi, Kaushal Santosh Bhogale, Deovrat Mehendale, Ishvinder Virender Sethi, Aparna Ananthanarayanan, Hafsah Faquih, Pratiti Palit, Sneha Ravishankar, Saranya Sukumaran, Tripura Panchagnula, Sunjay Murali, Kunal Sharad Gandhi, Ambujavalli R, Manickam K M, C Venkata Vaijayanthi, Krishnan Srinivasa Raghavan Karunganni, Pratyush Kumar, Mitesh M Khapra 我们提出了 INDICVOICES,这是一个自然和自发语音的数据集,包含来自印度 145 个地区和 22 种语言的 16237 名说话者的总共 7348 小时的朗读 9 、即兴演奏 74 和会话 17 音频。在这 7348 小时中,1639 小时已被转录,每种语言的中位数为 73 小时。通过本文,我们分享了捕捉印度文化、语言和人口多样性以创建同类包容性和代表性数据集的旅程。更具体地说,我们共享大规模数据收集的开源蓝图,包括标准化协议、集中式工具、跨越多个领域和感兴趣主题的引人入胜的问题、提示和对话场景的存储库、质量控制机制、全面的转录指南和转录工具。我们希望这个开源蓝图将成为世界其他多语言地区数据收集工作的综合入门工具包。使用 INDICVOICES,我们构建了 IndicASR,这是第一个支持印度宪法第 8 条中列出的所有 22 种语言的 ASR 模型。 |
| To Generate or to Retrieve? On the Effectiveness of Artificial Contexts for Medical Open-Domain Question Answering Authors Giacomo Frisoni, Alessio Cocchieri, Alex Presepi, Gianluca Moro, Zaiqiao Meng 医学开放领域问答需要大量获取专业知识。最近的努力试图将知识与模型参数分离,抵消架构扩展并允许在常见的低资源硬件上进行培训。检索然后读取的范式已经变得无处不在,模型预测基于来自外部存储库(例如 PubMed、教科书和 UMLS)的相关知识片段。另一种途径仍在探索中,但由于特定领域的大型语言模型的出现而成为可能,它需要通过提示构建人工上下文。因此,生成或检索相当于现代哈姆雷特的困境。本文介绍了 MedGENIE,这是第一个用于医学领域多项选择问答的生成然后读取的框架。我们对 MedQA USMLE、MedMCQA 和 MMLU 进行了广泛的实验,并通过假设最大 24GB VRAM 纳入了实用的观点。 MedGENIE 在每个测试台的开放书本设置中设置了新的最先进的 SOTA,甚至允许小规模阅读器超越零样本封闭书本 175B 基线,同时使用最多 706 倍的参数。 |
| Arabic Text Sentiment Analysis: Reinforcing Human-Performed Surveys with Wider Topic Analysis Authors Latifah Almurqren, Ryan Hodgson, Alexandra Cristea 情感分析 SA 一直是并且仍然是一个蓬勃发展的研究领域。然而,阿拉伯语情感分析 ASA 任务在研究机构中的代表性仍然不足。这项研究首次对现有 ASA 文本内容研究进行了深入和广度的分析,并确定了它们的共同主题、应用领域、方法、途径、技术和算法。这项深入研究手动分析了 2002 年至 2020 年间发表的 133 篇 ASA 英文论文,这些论文来自四个学术数据库 SAGE、IEEE、Springer、WILEY 和 Google Scholar。这项广泛的研究使用了现代自动机器学习技术,例如针对开放获取资源的主题建模和时间分析,以强化先前对 2010 年至 2020 年间 2297 份 ASA 出版物的研究确定的主题和趋势。主要发现显示了不同的研究结果用于 ASA 机器学习的方法、基于词典的方法和混合方法。其他发现包括 ASA 获胜算法 SVM、NB、混合方法。深度学习方法,例如 LSTM,可以提供更高的准确率,但对于 ASA,有时语料库不够大,无法支持它们。此外,虽然有一些 ASA 语料库和词典,但还需要更多。具体来说,阿拉伯推文语料库和数据集目前规模适中。此外,覆盖率较高的阿拉伯语词典仅包含现代标准阿拉伯语 MSA 单词,而包含阿拉伯方言的词汇则相当少。因此,需要创建新的语料库。另一方面,ASA 工具却严重缺乏。需要开发可用于工业界和学术界的阿拉伯文本 SA 的 ASA 工具。 |
| Fostering the Ecosystem of Open Neural Encoders for Portuguese with Albertina PT* Family Authors Rodrigo Santos, Jo o Rodrigues, Lu s Gomes, Jo o Silva, Ant nio Branco, Henrique Lopes Cardoso, Tom s Freitas Os rio, Bernardo Leite 为了促进葡萄牙语的神经编码,本文贡献了基础编码器模型,这些模型代表了专门为该语言开发的仍然非常稀缺的大型语言模型生态系统的扩展,这些模型是完全开放的,从某种意义上说,它们是开源的并且公开分发给在开放许可下免费用于任何目的,包括研究和商业用途。与英语以外的大多数语言一样,葡萄牙语在这些基础语言资源方面资源匮乏,最初的参数为 9 亿个 Albertina 参数和 3.35 亿个参数 Bertimbau 参数。以这两个模型作为首个模型集,我们展示了最先进的葡萄牙语开放编码器生态系统的扩展,其中包括一个具有 15 亿个参数的更大、顶级性能驱动的模型,以及一个具有 1 亿个参数的更小的、效率驱动的模型。 |
| FCDS: Fusing Constituency and Dependency Syntax into Document-Level Relation Extraction Authors Xudong Zhu, Zhao Kang, Bei Hui 文档级关系提取 DocRE 旨在识别单个文档中实体之间的关系标签。它需要处理几个句子并对它们进行推理。最先进的 DocRE 方法使用图形结构来连接文档中的实体以捕获依赖语法信息。然而,这不足以充分利用文档中丰富的语法信息。在这项工作中,我们建议将选区和依赖语法融合到 DocRE 中。它使用选区语法来聚合整个句子信息并为目标对选择指导性句子。它利用图结构中的依赖语法和选区语法增强,并根据依赖图选择实体对之间的路径。来自不同领域的数据集的实验结果证明了该方法的有效性。 |
| An Improved Traditional Chinese Evaluation Suite for Foundation Model Authors Zhi Rui Tam, Ya Ting Pai, Yen Wei Lee, Sega Cheng, Hong Han Shuai 我们提出了 TMMLU,一个专为繁体中文大规模多任务语言理解数据集设计的综合数据集。 TMMLU 是一个多项选择题回答数据集,包含从初级到专业级别的 66 个科目。与前身 TMMLU 相比,TMMLU 规模扩大了六倍,学科分布更加均衡。我们在 TMMLU 中纳入了闭源模型和参数范围从 1.8B 到 72B 的 24 个开放权重中文大语言模型的基准测试结果。我们的研究结果表明,繁体中文模型仍然落后于简体中文模型。此外,当前的大型语言模型的平均得分尚未超过人类的表现。 |
| Rethinking LLM Language Adaptation: A Case Study on Chinese Mixtral Authors Yiming Cui, Xin Yao Mixtral是一种具有代表性的专家稀疏混合SMoE语言模型,由于其独特的模型设计和优越的性能而受到了广泛的关注。基于Mixtral 8x7B v0.1,本文提出了Chinese Mixtral和Chinese Mixtral Instruct,通过进一步的预训练和指令微调,提高了汉语能力。实验结果表明,我们的汉语混合和汉语混合教学成功地提高了汉语理解和生成表现,同时保留了原有的英语能力。然后,我们讨论了在大型语言模型上进行语言适应时的几个关键问题,包括扩展语言特定词汇的必要性以及初始化模型基础模型与基础模型的选择。教学模型,通过提供实证结果和分析。我们还展示了每位专家的可视化,以检查他们对下游任务的重要性。 |
| CET2: Modelling Topic Transitions for Coherent and Engaging Knowledge-Grounded Conversations Authors Lin Xu, Qixian Zhou, Jinlan Fu, See Kiong Ng 基于知识的对话系统旨在根据对话背景和选定的外部知识生成连贯且引人入胜的响应。以前的知识选择方法往往过于依赖对话上下文或过分强调所选知识中的新信息,导致选择重复或不协调的知识,并进一步产生重复或不连贯的响应,因为响应的生成取决于选择的知识。为了解决这些缺点,我们引入了连贯且引人入胜的主题转换 CET2 框架来对主题转换进行建模,以选择与对话上下文一致的知识,同时为主题开发提供足够的知识多样性。我们的CET2框架考虑了知识选择的多个因素,包括从对话上下文到以下主题的有效转换逻辑以及可用知识候选之间的系统比较。在两个公共基准上的大量实验证明了CET2在知识选择方面的优越性和更好的泛化能力。这是由于我们精心设计的过渡功能和比较知识选择策略,这些策略更容易转移到有关未见过的主题的对话中。 |
| Making Pre-trained Language Models Great on Tabular Prediction Authors Jiahuan Yan, Bo Zheng, Hongxia Xu, Yiheng Zhu, Danny Chen, Jimeng Sun, Jian Wu, Jintai Chen 深度神经网络 DNN 的可迁移性在图像和语言处理方面取得了重大进展。然而,由于表之间的异质性,这种 DNN 优势还远未在表格数据预测(例如回归或分类任务)中得到充分利用。语言模型 LM 凝聚了来自不同领域的知识,具有理解来自不同表的特征名称的能力,有可能成为跨不同表和不同预测任务转移知识的多功能学习者,但它们的离散文本表示空间本质上与数字特征值不兼容。表。在本文中,我们提出了 TP BERTa,这是一种专门用于表格数据预测的预训练 LM 模型。具体来说,一种新颖的相对幅度标记化将标量数字特征值转换为精细离散的高维标记,并且内部特征注意方法将特征值与相应的特征名称集成。 |
| NusaBERT: Teaching IndoBERT to be Multilingual and Multicultural Authors Wilson Wongso, David Samuel Setiawan, Steven Limcorn, Ananto Joyoadikusumo 印度尼西亚的语言景观非常多样化,包含 700 多种语言和方言,使其成为世界上语言最丰富的国家之一。这种多样性,加上代码转换的广泛实践和资源匮乏的区域语言的存在,给现代预训练语言模型带来了独特的挑战。为了应对这些挑战,我们在 IndoBERT 的基础上开发了 NusaBERT,纳入了词汇扩展并利用了包括地区语言和方言在内的多样化多语言语料库。 |
| Enhancing Multi-Domain Automatic Short Answer Grading through an Explainable Neuro-Symbolic Pipeline Authors Felix K nnecke, Anna Filighera, Colin Leong, Tim Steuer 对于电流互感器方法来说,通过分级决策背后的可解释推理自动对简答题进行分级是一个具有挑战性的目标。论证线索检测与逻辑推理器相结合,为 ASAG 中的神经符号架构展示了一个有希望的方向。但是,主要挑战之一是学生的回答中需要带注释的理由提示,而这种提示仅存在于少数 ASAG 数据集中。为了克服这一挑战,我们贡献了 1 一个用于 ASAG 数据集中的论证线索的弱监督注释程序,以及 2 一个基于论证线索的可解释 ASAG 的神经符号模型。与双语、多领域和多问题训练设置中简短答案反馈数据集的最新技术相比,我们的方法将 RMSE 提高了 0.24 到 0.3。 |
| NPHardEval4V: A Dynamic Reasoning Benchmark of Multimodal Large Language Models Authors Lizhou Fan, Wenyue Hua, Xiang Li, Kaijie Zhu, Mingyu Jin, Lingyao Li, Haoyang Ling, Jinkui Chi, Jindong Wang, Xin Ma, Yongfeng Zhang 了解多模态大型语言模型 MLLM 的推理能力是一个重要的研究领域。在本研究中,我们引入了一个动态基准 NPHardEval4V,旨在解决评估 MLLM 纯推理能力方面的现有差距。我们的基准测试旨在提供一个场所,将图像识别和指令遵循等各种因素的影响与模型的整体性能分开,使我们能够专注于评估它们的推理能力。我们的研究结果揭示了不同模型的推理能力存在显着差异,并强调了 MLLM 与 LLM 相比在推理方面的表现相对较弱。我们还研究了不同提示风格(包括视觉、文本以及视觉和文本组合提示)对 MLLM 推理能力的影响,展示了多模式输入对模型性能的不同影响。与主要侧重于静态评估的传统基准不同,我们的基准将每月更新,以防止过度拟合并确保对模型进行更准确的评估。我们相信这个基准可以帮助理解和指导 MLLM 推理能力的进一步发展。 |
| WebCiteS: Attributed Query-Focused Summarization on Chinese Web Search Results with Citations Authors Haolin Deng, Chang Wang, Xin Li, Dezhang Yuan, Junlang Zhan, Tianhua Zhou, Jin Ma, Jun Gao, Ruifeng Xu 增强大型语言模型法学硕士的归因是一项至关重要的任务。一种可行的方法是让法学硕士能够引用支持他们这一代人的外部资源。然而,该领域现有的数据集和评估方法仍然表现出明显的局限性。在这项工作中,我们制定了属性查询集中摘要 AQFS 的任务,并提出了 WebCiteS,这是一个中文数据集,包含 7000 个带有引文的人工注释摘要。 WebCiteS 源自现实世界的用户查询和网络搜索结果,为模型训练和评估提供了宝贵的资源。先前的归因评估工作没有区分接地错误和引用错误。它们在自动验证从多个来源获得部分支持的句子方面也存在缺陷。我们通过开发详细的指标并使自动评估器将句子分解为子声明以进行细粒度验证来解决这些问题。我们对 WebCiteS 上的开源和专有模型的综合评估突出了法学硕士在正确引用来源方面面临的挑战,强调了进一步改进的必要性。 |
| KeNet:Knowledge-enhanced Doc-Label Attention Network for Multi-label text classification Authors Bo Li, Yuyan Chen, Liang Zeng 多标签文本分类 MLTC 是自然语言处理 NLP 领域的一项基本任务,涉及为给定文本分配多个标签。 MLTC 已变得非常重要,并已广泛应用于主题识别、推荐系统、情感分析和信息检索等各个领域。然而,传统的机器学习和深度神经网络尚未解决某些问题,例如有些文档很简短,但标签数量较多,以及如何建立标签之间的关系。还必须承认的是,知识的重要性在 MLTC 领域得到了证实。为了解决这个问题,我们提供了一种称为知识增强文档标签注意网络 KeNet 的新颖方法。具体来说,我们设计了一个注意力网络,它结合了外部知识、标签嵌入和全面的注意力机制。与传统方法相比,我们使用文档、知识和标签的综合表示来预测每个文本的所有标签。我们的方法已经通过对三个多标签数据集进行的综合研究得到验证。实验结果表明,我们的方法优于最先进的 MLTC 方法。 |
| Derivative-Free Optimization for Low-Rank Adaptation in Large Language Models Authors Feihu Jin, Yin Liu, Ying Tan LoRA 等参数高效调整方法可以通过调整一小部分参数来实现与模型调整相当的性能。然而,仍然需要大量的计算资源,因为这个过程涉及计算梯度并在整个模型中执行反向传播。最近,人们致力于利用无导数优化方法来避免梯度计算,并在少数镜头设置中展示增强的鲁棒性水平。在本文中,我们将低秩模块添加到模型的每个自注意力层中,并采用两种无导数优化方法来交替优化每一层的这些低秩模块。 |
| Differentially Private Synthetic Data via Foundation Model APIs 2: Text Authors Chulin Xie, Zinan Lin, Arturs Backurs, Sivakanth Gopi, Da Yu, Huseyin A Inan, Harsha Nori, Haotian Jiang, Huishuai Zhang, Yin Tat Lee, Bo Li, Sergey Yekhanin 由于从中学习的机器学习算法的出现,文本数据变得极其有价值。现实世界中生成的大量高质量文本数据是私有的,因此由于隐私问题而无法自由共享或使用。生成具有正式隐私保证的私有文本数据的合成副本(即差分隐私 DP)提供了一种有前途且可扩展的解决方案。然而,现有方法需要对私有数据上的大型语言模型 LLM 进行 DP 微调,以生成 DP 合成数据。这种方法对于专有的 LLM 来说不可行,例如 GPT 3.5,并且对于开源 LLM 也需要大量的计算资源。林等人。 2024 最近推出了 Private Evolution PE 算法,仅通过 API 访问扩散模型即可生成 DP 合成图像。在这项工作中,我们提出了一种增强的 PE 算法,名为 Aug PE,适用于复杂的文本设置。我们使用 API 访问 LLM 并生成 DP 合成文本,无需任何模型训练。我们对三个基准数据集进行了全面的实验。我们的结果表明,Aug PE 生成的 DP 合成文本可在 SOTA DP 微调基线下产生具有竞争力的效用。这强调了仅依靠法学硕士的 API 访问来生成高质量的 DP 合成文本的可行性,从而促进更容易获取隐私保护法学硕士申请的途径。 |
| Decode Neural signal as Speech Authors Yiqian Yang, Yiqun Duan, Qiang Zhang, Renjing Xu, Hui Xiong 从大脑动力学解码语言是脑机接口BCI领域的一个重要开放方向,特别是考虑到大型语言模型的快速增长。与需要电极植入手术的侵入性信号相比,非侵入性神经信号例如脑电图、脑磁图由于其安全性和通用性而受到越来越多的关注。然而,在三个方面的探索还不够充分 1 以前的方法主要集中在脑电图上,但以前的工作都没有解决信号质量更好的脑电图上的这个问题 2 以前的工作在生成解码过程中主要使用教师强制,这是不切实际的 3 以前的工作大多数是基于 BART 的,不是完全自回归的,在其他序列任务中表现更好。在本文中,我们探索了语音解码形式中 MEG 信号的大脑到文本的翻译。在这里,我们第一个研究了基于交叉注意力的耳语模型,用于直接从 MEG 信号生成文本,而无需教师强制。我们的模型在两个主要数据集 textit GWilliams 和 textit Schoffelen 上无需预训练教师强制即可获得令人印象深刻的 BLEU 1 分数 60.30 和 52.89。 |
| Brilla AI: AI Contestant for the National Science and Maths Quiz Authors George Boateng, Jonathan Abrefah Mensah, Kevin Takyi Yeboah, William Edor, Andrew Kojo Mensah Onumah, Naafi Dasana Ibrahim, Nana Sam Yeboah 非洲大陆缺乏足够的合格教师,这阻碍了提供足够的学习支持。人工智能可能会增强有限数量教师的工作量,从而带来更好的学习成果。为此,这项工作描述并评估了 NSMQ 人工智能大挑战赛的第一个关键成果,它为这样的人工智能提出了一个强大的、现实世界的基准,构建一个人工智能,以在加纳国家科学和数学测验 NSMQ 竞赛中现场竞争并获胜在比赛的各个轮次和阶段都比最好的选手表现更好。 NSMQ 是加纳一年一度的高中生现场科学和数学竞赛,由 2 名学生组成的 3 支队伍进行比赛,分 5 个阶段回答生物、化学、物理和数学方面的问题,分 5 轮进行,直至获胜团队加冕那一年。在这项工作中,我们构建了 Brilla AI,这是一个人工智能参赛者,我们部署它来非正式地进行远程比赛,并现场参加 2023 年 NSMQ 总决赛的谜语轮比赛,这是该比赛 30 年历史上的首次此类比赛。 Brilla AI 目前以网络应用程序形式提供,可直播谜语比赛回合,并运行 4 个机器学习系统:1 个语音转文本、2 个问题提取、3 个问题回答和 4 个文本转语音,这些系统实时协同工作,快速准确地提供回答,然后用加纳口音说出来。在首次亮相时,我们的人工智能领先于 3 支人类参赛队解答了 4 个谜题之一,非正式地获得并列第二名。 |
| Hypertext Entity Extraction in Webpage Authors Yifei Yang, Tianqiao Liu, Bo Shao, Hai Zhao, Linjun Shou, Ming Gong, Daxin Jiang 网页实体提取是研究和应用中的一项基本自然语言处理任务。如今,大多数网页实体提取模型都是在结构化数据集上进行训练的,这些数据集力求保留文本内容及其结构信息。然而,现有的数据集都忽略了丰富的超文本特征,例如字体颜色、字体大小,这些特征在以前的作品中显示了它们的有效性。为此,我们首先从电子商务领域收集文本HEED,使用高质量的手动实体注释来抓取文本和相应的显式超文本特征。此外,我们还提出了基于 textbf Mo E 的 textbf E ntity textbf E xtraction textbf Framework textit MoEEF ,它有效地集成了多个特征,通过专家混合来增强模型性能,并优于强大的基线,包括最先进的小规模模型和 GPT 3.5涡轮增压。 |
| Towards Comprehensive Vietnamese Retrieval-Augmented Generation and Large Language Models Authors Nguyen Quang Duc, Le Hai Son, Nguyen Duc Nhan, Nguyen Dich Nhat Minh, Le Thanh Huong, Dinh Viet Sang |
| Enhancing Neural Machine Translation of Low-Resource Languages: Corpus Development, Human Evaluation and Explainable AI Architectures Authors S amus Lankford 在当前的机器翻译 MT 领域,Transformer 架构脱颖而出,成为黄金标准,尤其是对于高资源语言对。这项研究深入研究了其对资源匮乏的语言对的功效,包括英语左右箭头爱尔兰语和英语左右箭头马拉地语语言对。 |
| SERVAL: Synergy Learning between Vertical Models and LLMs towards Oracle-Level Zero-shot Medical Prediction Authors Jiahuan Yan, Jintai Chen, Chaowen Hu, Bo Zheng, Yaojun Hu, Jimeng Sun, Jian Wu 最近开发的大型语言模型法学硕士在通用和常识问题上表现出了令人印象深刻的零样本熟练程度。然而,法学硕士在特定领域垂直问题上的应用仍然落后,这主要是由于羞辱问题和垂直知识的缺乏。此外,垂直数据注释过程通常需要劳动密集型专家的参与,从而在增强模型的垂直能力方面提出了额外的挑战。在本文中,我们提出了 SERVAL,这是一种协同学习管道,旨在通过相互增强来无监督地开发法学硕士和小型模型的垂直能力。具体来说,SERVAL 利用法学硕士的零样本输出作为注释,利用其信心从头开始教授稳健的垂直模型。相反,经过训练的垂直模型指导 LLM 微调以增强其零样本能力,通过迭代过程逐步改进两个模型。在以复杂的垂直知识和昂贵的注释而闻名的医学领域,综合实验表明,在没有获得任何黄金标签的情况下,SERVAL 凭借 OpenAI GPT 3.5 的协同学习和简单模型,在十个广泛使用的医学数据集上获得了完全监督的竞争性能。 |
| In-Context Sharpness as Alerts: An Inner Representation Perspective for Hallucination Mitigation Authors Shiqi Chen, Miao Xiong, Junteng Liu, Zhengxuan Wu, Teng Xiao, Siyang Gao, Junxian He 大型语言模型法学硕士经常产生幻觉并产生事实错误,但我们对他们为何犯这些错误的理解仍然有限。在这项研究中,我们从内部表征的角度深入研究了LLM幻觉的潜在机制,并发现了与幻觉相关的显着模式,与不正确的世代相比,正确的世代往往在上下文标记的隐藏状态中具有更清晰的上下文激活。那些。利用这种见解,我们提出了一种基于熵的度量来量化上下文隐藏状态之间的清晰度,并将其合并到解码过程中以制定约束解码方法。对各种知识寻求和幻觉基准的实验证明了我们的方法的一致有效性,例如,在 TruthfulQA 上实现了高达 8.6 分的改进。 |
| Leveraging Biomolecule and Natural Language through Multi-Modal Learning: A Survey Authors Qizhi Pei, Lijun Wu, Kaiyuan Gao, Jinhua Zhu, Yue Wang, Zun Wang, Tao Qin, Rui Yan 生物分子建模与自然语言 BL 的集成已成为人工智能、化学和生物学交叉领域的一个有前途的跨学科领域。这种方法利用文本数据源中包含的生物分子的丰富、多方面的描述来增强我们的基本理解并实现下游计算任务,例如生物分子属性预测。通过自然语言表达的细致入微的叙述与通过各种分子建模技术描述的生物分子的结构和功能细节的融合,为全面表示和分析生物分子开辟了新的途径。通过将围绕生物分子的上下文语言数据纳入其建模中,BL 旨在捕获包含通过语言传达的符号品质以及定量结构特征的整体视图。在这篇综述中,我们对通过生物分子和自然语言交叉建模所取得的最新进展进行了广泛的分析。 1 我们首先概述所用生物分子的技术表示,包括序列、2D 图和 3D 结构。 2 然后,我们深入研究语言和分子数据源有效多模式整合的基本原理和关键目标。 3 我们随后调查了这一发展中的研究领域迄今为止实现的实际应用。 4 我们还编译和总结了可用的资源和数据集,以促进未来的工作。 5 展望未来,我们确定了几个有前景的研究方向,值得进一步探索和投资,以继续推进该领域的发展。 |
| Revisiting Dynamic Evaluation: Online Adaptation for Large Language Models Authors Amal Rannen Triki, Jorg Bornschein, Razvan Pascanu, Marcus Hutter, Andras Gy rgy, Alexandre Galashov, Yee Whye Teh, Michalis K. Titsias 我们考虑在测试时在线微调语言模型参数的问题,也称为动态评估。虽然众所周知,这种方法提高了整体预测性能,特别是在考虑训练和评估数据之间的分布变化时,但我们在这里强调在线适应将参数转变为暂时变化的状态,并提供一种上下文长度扩展的形式,其中内存权重,更符合神经科学中记忆的概念。我们特别关注样本效率方面的适应速度、对整体分布漂移的敏感性以及执行梯度计算和参数更新的计算开销。我们的实证研究提供了关于在线适应何时特别有趣的见解。 |
| Fantastic Semantics and Where to Find Them: Investigating Which Layers of Generative LLMs Reflect Lexical Semantics Authors Zhu Liu, Cunliang Kong, Ying Liu, Maosong Sun 大型语言模型在一般语言理解任务中取得了显着的成功。然而,作为一系列以下一个 token 预测为目标的生成方法,这些模型的语义演化与深度并没有得到充分的探索,不像它们的前辈,例如类似 BERT 的架构。在本文中,我们通过使用上下文单词识别任务探测每层末尾的隐藏状态,专门研究了流行的 LLM(即 Llama2)词汇语义的自下而上的演化。我们的实验表明,较低层的表示编码词汇语义,而语义归纳较弱的较高层负责预测。这与具有判别性目标的模型形成对比,例如掩码语言建模,其中较高层获得更好的词汇语义。 |
| Infusing Knowledge into Large Language Models with Contextual Prompts Authors Kinshuk Vasisht, Balaji Ganesan, Vikas Kumar, Vasudha Bhatnagar 知识注入是一种有前途的方法,可以增强特定领域 NLP 任务的大型语言模型,而不是从头开始对大数据进行预训练模型。这些增强的法学硕士通常依赖于额外的预训练或现有知识图的知识提示,这在许多应用中是不切实际的。相比之下,直接从相关文档注入知识更具通用性,并且减轻了对结构化知识图的需求,同时对于通常在任何知识图中找不到的实体也很有用。出于这种动机,我们提出了一种简单但通用的知识注入方法,通过根据输入文本中的上下文生成提示。 |
| Align-to-Distill: Trainable Attention Alignment for Knowledge Distillation in Neural Machine Translation Authors Heegon Jin, Seonil Son, Jemin Park, Youngseok Kim, Hyungjong Noh, Yeonsoo Lee 可扩展深度模型和大型数据集的出现提高了神经机器翻译的性能。知识蒸馏 KD 通过将知识从教师模型转移到更紧凑的学生模型来提高效率。然而,Transformer 架构的 KD 方法通常依赖于启发式方法,特别是在决定从哪些教师层中提取时。在本文中,我们介绍了 Align to Distill A2D 策略,该策略旨在通过在训练期间自适应地将学生注意力头与教师对应的注意力头对齐来解决特征映射问题。 A2D 中的注意力对齐模块在学生和教师注意力头之间进行跨层的密集比较,将组合映射启发法转变为学习问题。 |
| KorMedMCQA: Multi-Choice Question Answering Benchmark for Korean Healthcare Professional Licensing Examinations Authors Sunjun Kweon, Byungjin Choi, Minkyu Kim, Rae Woong Park, Edward Choi 我们介绍 KorMedMCQA,这是韩国第一个多项选择题回答 MCQA 基准,源自韩国医疗保健专业执照考试,涵盖 2012 年至 2023 年。该数据集包含从医生、护士和药剂师执照考试中精选的问题,具有多样化的主题。我们对各种大型语言模型进行了基线实验,包括专有的开源模型、多语言韩语附加预训练模型和临床上下文预训练模型,突出了进一步增强的潜力。 |
| Answerability in Retrieval-Augmented Open-Domain Question Answering Authors Rustam Abdumalikov, Pasquale Minervini, Yova Kementchedjhieva 开放域问答 ODQA 检索系统的性能可能表现出次优行为,提供不同程度不相关的文本摘录。不幸的是,许多现有的 ODQA 数据集缺乏专门针对识别不相关文本摘录的示例。之前解决这一差距的尝试依赖于将问题与随机文本摘录配对的简单方法。本文旨在研究使用这种随机策略训练的模型的有效性,揭示其泛化到具有高度语义重叠的不相关文本摘录的能力的重要限制。结果,我们观察到预测准确度大幅下降,从 98 降至 1。为了解决这个限制,我们发现了一种有效的方法来训练模型来识别此类摘录。 |
| Controlling Cloze-test Question Item Difficulty with PLM-based Surrogate Models for IRT Assessment Authors Jingshen Zhang, Jiajun Xie, Xinying Qiu 项目难度在适应性测试中起着至关重要的作用。然而,很少有工作专注于生成不同难度级别的问题,特别是对于多项选择 MC 完形填空测试。我们建议训练预先训练的语言模型 PLM 作为替代模型,以实现项目反应理论 IRT 评估,从而避免对人类测试对象的需要。我们还提出了两种策略来控制间隙和干扰项的难度级别,使用排名规则来减少无效干扰项。 |
| Fine Tuning vs. Retrieval Augmented Generation for Less Popular Knowledge Authors Heydar Soudani, Evangelos Kanoulas, Faegheh Hasibi 大型语言模型法学硕士能够记住大量事实知识,在不同的任务和领域中表现出强大的表现。然而,据观察,在处理不太流行或低频的概念和实体时(例如在特定领域的应用程序中),性能会下降。提高法学硕士在低频主题上的性能的两种主要方法是检索增强生成 RAG 和对合成数据进行微调 FT。本文探讨并评估了 RAG 和 FT 对定制 LLM 处理问答任务低频实体的影响。我们的研究结果表明,FT 显着提高了不同受欢迎程度的实体的性能,尤其是在最受欢迎和最不受欢迎的群体中,而 RAG 则优于其他方法。此外,检索和数据增强技术的进步也放大了 RAG 和 FT 方法的成功。 |
| OVEL: Large Language Model as Memory Manager for Online Video Entity Linking Authors Haiquan Zhao, Xuwu Wang, Shisong Chen, Zhixu Li, Xin Zheng, Yanghua Xiao 近年来,连接 MEL 的多模态实体由于其在众多多模态应用中的重要性而引起了研究界越来越多的关注。视频作为一种流行的信息传播方式,已经深入到人们的日常生活中。然而,大多数现有的 MEL 方法主要侧重于将文本和视觉提及或离线视频提及与多模态知识库中的实体链接起来,而致力于链接在线视频内容中的提及的努力有限。在本文中,我们提出了一项名为在线视频实体链接 OVEL 的任务,旨在以高精度和时效性在在线视频中的提及与知识库之间建立连接。为了方便OVEL的研究工作,我们特别关注直播场景并构建了一个名为LIVE的直播实体链接数据集。此外,我们提出了一个考虑永恒性、鲁棒性和准确性的评估指标。此外,为了有效处理 OVEL 任务,我们利用大型语言模型管理的内存块,并从知识库中检索候选实体,以增强 LLM 在内存管理方面的性能。 |
| What Is Missing in Multilingual Visual Reasoning and How to Fix It Authors Yueqi Song, Simran Khanuja, Graham Neubig 如今的 NLP 模型致力于支持多种语言和模式,提高不同用户的可访问性。在本文中,我们通过视觉推理任务测试来评估他们的多语言、多模式能力。我们观察到,像 GPT 4V 这样的专有系统现在在这项任务上获得了最佳性能,但开放模型相比之下表现较差。令人惊讶的是,GPT 4V 在英语和其他语言之间表现出相似的性能,这表明跨语言公平系统开发的潜力。我们对模型失败的分析揭示了使这项任务挑战多语言、复杂推理和多模态的三个关键方面。为了应对这些挑战,我们提出了三种有针对性的干预措施,包括解决多语言问题的翻译测试方法、分解复杂推理的可视化编程方法以及利用图像字幕解决多模态问题的新颖方法。 |
| CR-LT-KGQA: A Knowledge Graph Question Answering Dataset Requiring Commonsense Reasoning and Long-Tail Knowledge Authors Willis Guo, Armin Toroghi, Scott Sanner 知识图问答 KGQA 是一个成熟的领域,旨在通过利用知识图 KG 为自然语言 NL 问题提供事实答案。然而,现有的 KGQA 数据集面临两个重大限制:1 现有的 KGQA 数据集不需要常识推理才能得出答案;2 现有的 KGQA 数据集专注于流行的实体,大型语言模型法学硕士可以直接回答这些实体,而无需产生幻觉,也无需利用 KG。在这项工作中,我们寻求一种新颖的 KGQA 数据集,该数据集支持常识推理并专注于长尾实体,例如法学硕士经常产生幻觉的非主流和近期实体,因此需要利用 KG 进行事实和可归因的常识推理的新颖方法。我们创建了一个新颖的常识推理 CR 和长尾 LT KGQA 数据集,其中包含两个子任务问答和声明验证,解决了限制 1 和 2。我们通过在 Wikidata 上构建现有推理数据集 StrategyQA 和 CREAK 的扩展来构建 CR LT KGQA。虽然现有的 KGQA 方法由于缺乏常识推理支持而不适用,但对 CR LT KGQA 的法学硕士的基线评估表明幻觉率很高。 |
| Right for Right Reasons: Large Language Models for Verifiable Commonsense Knowledge Graph Question Answering Authors Armin Toroghi, Willis Guo, Mohammad Mahdi Abdollah Pour, Scott Sanner 知识图问答 KGQA 方法寻求使用知识图 KG 中存储的关系信息来回答自然语言问题。随着大型语言模型法学硕士的最新进展及其卓越的推理能力,利用它们进行 KGQA 的趋势越来越明显。然而,现有的方法仅侧重于回答事实问题,例如,西尔维奥·贝卢斯科尼的第一任妻子出生在哪个城市,而留下了现实世界用户可能更经常提出的涉及常识推理的问题,例如,我需要单独的签证才能看到金星吗?维伦多夫并参加今年夏天的奥运会未得到解决。在这项工作中,我们首先观察到现有的基于 LLM 的 KGQA 方法在此类问题上与幻觉作斗争,特别是针对长尾实体(例如非主流和最新实体)的查询,从而阻碍了它们在现实世界应用中的适用性,特别是因为它们的推理过程是不容易验证。作为回应,我们提出了 Right for Right Reasons R3,这是一种常识性的 KGQA 方法,它通过公理地呈现法学硕士内在的常识性知识并将每个事实推理步骤基于 KG 三元组来实现可验证的推理过程。 |
| Automatic Question-Answer Generation for Long-Tail Knowledge Authors Rohan Kumar, Youngmin Kim, Sunitha Ravi, Haitian Sun, Christos Faloutsos, Ruslan Salakhutdinov, Minji Yoon 预训练大型语言模型 法学硕士因解决开放域问答 QA 问题而受到广泛关注。虽然法学硕士在回答与常识相关的问题时表现出很高的准确性,但法学硕士在学习不常见的长尾知识尾实体时遇到了困难。由于手动构建 QA 数据集需要大量人力资源,现有 QA 数据集的类型有限,导致我们缺乏数据集来研究 LLM 在尾部实体上的性能。在本文中,我们提出了一种自动方法来为尾部实体生成专门的 QA 数据集,并提出相关的研究挑战。 |
| Evaluating and Mitigating Number Hallucinations in Large Vision-Language Models: A Consistency Perspective Authors Huixuan Zhang, Junzhe Zhang, Xiaojun Wan 大视觉语言模型在解决与文本和视觉内容相关的挑战方面表现出了显着的功效。然而,这些模型很容易产生各种幻觉。在本文中,我们关注一种新形式的幻觉,具体称为数字幻觉,它表示模型无法准确识别图像中物体数量的情况。我们建立了一个数据集并采用评估指标来评估数字幻觉,揭示了这个问题在主流大视觉语言模型 LVLM 中的明显普遍性。此外,我们还深入分析了数字幻觉,从两个相关的角度审视内部和外部的不一致问题。 |
| Improving Cross-lingual Representation for Semantic Retrieval with Code-switching Authors Mieradilijiang Maimaiti, Yuanhang Zheng, Ji Zhang, Fei Huang, Yue Zhang, Wenpei Luo, Kaiyu Huang 语义检索SR已经成为面向任务的问答QA对话场景中FAQ系统中不可或缺的一部分。近年来,电子商务平台或某些特定业务场景对跨语言智能客服系统的需求不断增加。之前的大多数研究都利用跨语言预训练模型 PTM 直接进行多语言知识检索,而其他一些研究也在下游任务上微调 PTM 之前利用持续的预训练。然而,无论使用哪种模式,之前的工作都忽略了向 PTM 告知下游任务的一些特征,即在不提供任何与 SR 相关的信号的情况下训练他们的 PTM。为此,在这项工作中,我们提出了一种通过代码切换实现 SR 的替代跨语言 PTM。我们是第一个利用代码转换方法进行跨语言 SR 的人。此外,我们引入了新颖的代码切换连续预训练,而不是直接在 SR 任务上使用 PTM。 |
| LM4OPT: Unveiling the Potential of Large Language Models in Formulating Mathematical Optimization Problems Authors Tasnim Ahmed, Salimur Choudhury 在快速发展的自然语言处理领域,将语言描述转化为优化问题的数学公式提出了巨大的挑战,要求大型语言模型法学硕士具有复杂的理解和处理能力。本研究比较了著名的法学硕士,包括 GPT 3.5、GPT 4 和 Llama 2 7b,在零样本和单样本设置下完成此任务。我们的研究结果表明 GPT 4 具有卓越的性能,尤其是在一次性场景中。这项研究的核心部分是引入 LM4OPT,这是一种针对 Llama 2 7b 的渐进式微调框架,利用噪声嵌入和专门的数据集。然而,这项研究突显了 Llama 2 7b 等较小模型与较大模型相比,在上下文理解能力方面存在显着差距,特别是在处理冗长且复杂的输入上下文方面。我们利用 NL4Opt 数据集进行的实证调查表明,GPT 4 超越了之前研究建立的基准性能,仅基于自然语言的问题描述,且不依赖任何额外的命名实体信息,F1 得分为 0.63。 GPT 3.5 紧随其后,两者的性能均优于经过微调的 Llama 2 7b。 |
| VNLP: Turkish NLP Package Authors Meliksah Turker, Mehmet Erdi Ari, Aydin Han 在这项工作中,我们推出了 VNLP 第一个专用的、完整的、开源的、文档齐全的、轻量级的、生产就绪的、最先进的土耳其语自然语言处理 NLP 包。它包含各种各样的工具,从最简单的任务(例如句子分割和文本规范化)到更高级的任务(例如文本和标记分类模型)。其令牌分类模型基于上下文模型,这是一种新颖的架构,既是编码器又是自回归模型。 VNLP模型解决的NLP任务包括但不限于情感分析、命名实体识别、形态分析消歧和词性标注。此外,它还带有预先训练的词嵌入和相应的 SentencePiece Unigram 标记器。 VNLP 拥有开源 GitHub 存储库、ReadtheDocs 文档、方便安装的 PyPi 包、Python 和命令行 API 以及用于测试所有功能的演示页面。 |
| VBART: The Turkish LLM Authors Meliksah Turker, Mehmet Erdi Ari, Aydin Han 我们推出了 VBART,这是第一个对在大型语料库上从头开始进行预训练的大型语言模型法学硕士进行排序的土耳其语序列。 VBART 是紧凑型法学硕士,基于 BART 和 mBART 模型的好创意,有两种尺寸:大号和超大号。经过微调的 VBART 模型在抽象文本摘要、标题生成、文本释义、问答和问题生成任务方面超越了现有技术水平。它们允许对未来的文本生成任务和数据集进行微调,为土耳其自然语言处理 NLP 研究开辟了新的道路。我们的工作表明,针对土耳其语进行预训练的法学硕士的性能优于多语言模型的 3 倍,从而改进了现有结果并提供了有效的训练和推理模型。此外,我们表明我们的单语言分词器比 OpenAI 的多语言分词器效率高 7 倍。最后但并非最不重要的一点是,我们引入了一种方法来扩大现有的预训练法学硕士,并质疑 Chinchilla 缩放定律与序列到序列掩码语言模型的相关性。 |
| Improving the Validity of Automatically Generated Feedback via Reinforcement Learning Authors Alexander Scarlatos, Digory Smith, Simon Woodhead, Andrew Lan 通过智能辅导系统和在线学习平台中的大型语言模型自动生成法学硕士反馈,有可能提高许多学生的学习成果。然而,反馈生成和评估都具有挑战性,反馈内容必须有效,尤其是在数学等学科中,这需要模型来理解问题、解决方案以及学生的错误所在。反馈还必须在教学上有效,以反映有效的辅导策略,例如解释可能的误解和鼓励学生,以及其他理想的功能。在这项工作中,我们解决了自动生成和评估反馈的问题,同时考虑了正确性和一致性。首先,我们提出了一个评估数学反馈的标准,并表明 GPT 4 能够有效地使用它来注释人类书面和 LLM 生成的反馈。其次,我们提出了一个反馈生成框架,该框架使用强化学习 RL 来优化正确性和对齐性。具体来说,我们使用 GPT 4 注释在增强数据集中创建对反馈对的偏好,以便通过直接偏好优化 DPO 进行训练。 |
| Greed is All You Need: An Evaluation of Tokenizer Inference Methods Authors Omri Uzan, Craig W. Schmidt, Chris Tanner, Yuval Pinter 虽然 BPE 和 WordPiece 等子词分词器通常用于为 NLP 模型构建词汇表,但将这些词汇表中的文本解码为标记序列的方法通常未指定,或者不适合构建它们的方法。我们对四种不同算法和三种词汇大小的七种标记器推理方法进行了受控分析,在我们为英语策划的新颖的内在评估套件上进行,结合了植根于形态、认知和信息论的测量。 |
| A comprehensive cross-language framework for harmful content detection with the aid of sentiment analysis Authors Mohammad Dehghani 在当今的数字世界中,社交媒体在促进沟通和内容共享方面发挥着重要作用。然而,用户生成内容的指数级增长给维持尊重的在线环境带来了挑战。在某些情况下,用户利用匿名性来使用有害语言,这可能会对用户体验产生负面影响并造成严重的社会问题。认识到手动审核的局限性,已经开发了自动检测系统来解决这个问题。然而,仍然存在一些障碍,包括缺乏有害语言的通用定义、跨语言的数据集不足、需要详细的注释指南,以及最重要的是,需要一个全面的框架。本研究旨在通过首次引入适用于任何语言的详细框架来应对这些挑战。该框架涵盖有害语言检测的各个方面。该框架的一个关键组成部分是制定通用且详细的注释指南。此外,情感分析的集成代表了一种增强有害语言检测的新方法。此外,还提出了基于对不同相关概念的回顾的有害语言的定义。为了证明所提出的框架的有效性,以具有挑战性的低资源语言进行了实施。我们收集了波斯语数据集,并应用注释指南进行有害检测和情感分析。接下来,我们提出利用机器和深度学习方法来设置基准的基线实验。 |
| Accelerating Greedy Coordinate Gradient via Probe Sampling Authors Yiran Zhao, Wenyue Zheng, Tianle Cai, Xuan Long Do, Kenji Kawaguchi, Anirudh Goyal, Michael Shieh 鉴于其快速发展和广泛应用,大型语言模型的安全性已成为法学硕士的中心问题。贪心坐标梯度GCG被证明可以有效地构建包含对抗性后缀的提示来打破假定安全的LLM,但GCG的优化非常耗时并且限制了其实用性。为了减少GCG的时间成本并能够更全面地研究LLM安全性,在这项工作中,我们研究了一种称为texttt Probe抽样的新算法来加速GCG算法。该算法的核心是一种机制,可以动态确定较小草稿模型的预测与提示候选目标模型的预测的相似程度。当目标模型与草稿模型相似时,我们严重依赖草稿模型来过滤掉大量潜在的候选提示,以减少计算时间。 |
| Mitigating Catastrophic Forgetting in Large Language Models with Self-Synthesized Rehearsal Authors Jianheng Huang, Leyang Cui, Ante Wang, Chengyi Yang, Xinting Liao, Linfeng Song, Junfeng Yao, Jinsong Su 大型语言模型法学硕士在持续学习过程中会遭受灾难性遗忘。传统的基于演练的方法依赖于以前的训练数据来保留模型的能力,这在现实世界的应用中可能不可行。当基于公开发布的LLM检查点进行持续学习时,原始训练数据的可用性可能不存在。为了应对这一挑战,我们提出了一个名为“自合成排练 SSR”的框架,该框架使用 LLM 生成用于排练的合成实例。具体来说,我们首先使用基础法学硕士进行上下文学习来生成合成实例。随后,我们利用最新的法学硕士根据合成输入细化实例输出,保留其获得的能力。最后,我们选择各种高质量的合成实例用于未来阶段的排练。实验结果表明,与传统的基于排练的方法相比,SSR 实现了卓越或相当的性能,同时数据效率更高。 |
| IntactKV: Improving Large Language Model Quantization by Keeping Pivot Tokens Intact Authors Ruikang Liu, Haoli Bai, Haokun Lin, Yuening Li, Han Gao, Zhengzhuo Xu, Lu Hou, Jun Yao, Chun Yuan 大型语言模型 法学硕士在自然语言处理方面表现出色,但需要大量计算。为了缓解这个问题,人们探索了各种量化方法,但它们却损害了 LLM 的性能。本文揭示了法学硕士中以前被忽视的异常值类型。研究发现,此类异常值将大部分注意力分数分配在输入的初始标记(称为枢轴标记)上,这对于量化 LLM 的性能至关重要。鉴于此,我们建议 IntactKV 从全精度模型无损地生成枢轴令牌的 KV 缓存。该方法简单且易于与现有量化解决方案结合。此外,IntactKV 可以作为额外的 LLM 参数进行校准,以进一步提高量化的 LLM。数学分析也证明IntactKV有效降低了量化误差的上限。 |
| Emotion Analysis in NLP: Trends, Gaps and Roadmap for Future Directions Authors Flor Miriam Plaza del Arco, Alba Curry, Amanda Cercas Curry, Dirk Hovy 情感是沟通的一个核心方面。因此,情感分析 EA 是自然语言处理 NLP 中一个快速发展的领域。然而,在范围、方向或方法上尚未达成共识。在本文中,我们对过去十年的 154 篇相关 NLP 出版物进行了彻底的回顾。基于这篇综述,我们解决了四个不同的问题 1 NLP 中如何定义 EA 任务 2 什么是最突出的情感框架以及对哪些情感进行建模 3 是否从人口统计和文化因素方面考虑了情感的主观性以及 4 情绪的主观性是什么? EA 的主要 NLP 应用 我们评估 EA 和任务的趋势、使用的情感框架、现有数据集、方法和应用程序。然后我们讨论四个缺陷 1 人口和文化方面的缺失并不能解释情感感知方式的差异,而是假设人们普遍以相同的方式体验情感 2 两种主要情感理论与情感类别的不匹配任务 3 缺乏标准化的 EA 术语阻碍了差距识别、比较和未来目标,4 缺乏跨学科研究使 EA 与其他领域的见解隔离开来。 |
| API Is Enough: Conformal Prediction for Large Language Models Without Logit-Access Authors Jiayuan Su, Jing Luo, Hongwei Wang, Lu Cheng 本研究旨在解决在没有 Logit 访问权限的大型语言模型法学硕士中量化不确定性的普遍挑战。保形预测 CP 以其模型无关和分布自由的特性而闻名,是各种 LLM 和数据分布的理想方法。然而,LLM 的现有 CP 方法通常假设可以访问 logits,而这对于某些仅 API 的 LLM 来说是不可用的。此外,已知 logits 会被错误校准,从而可能导致 CP 性能下降。为了应对这些挑战,我们引入了一种新颖的 CP 方法,该方法 1 专为没有 Logit 访问权限的仅 API 法学硕士量身定制 2 最小化预测集的大小 3 确保用户定义覆盖范围的统计保证。这种方法的核心思想是使用粗粒度(即样本频率)和细粒度不确定性概念(例如语义相似性)来制定不合格度量。 |
| DMoERM: Recipes of Mixture-of-Experts for Effective Reward Modeling Authors Shanghaoran Quan 奖励模型 RM 的性能是提高大语言模型 LLM 在对齐微调过程中的有效性的关键因素。 RM 训练仍然存在两个挑战 1 使用不同类别的数据训练同一个 RM 可能会导致其泛化性能受到多任务干扰,2 人类注释一致性率通常只有 60 到 75 ,导致训练数据包含大量数据的噪音。为了应对这两个挑战,我们首次将专家混合教育部的想法引入RM领域。我们提出双层 MoE RM DMoERM 。外层MoE是稀疏模型。将输入分类为任务类别后,我们将其路由到相应的内层任务特定模型。内层MoE是密集模型。我们将特定任务分解为多个能力维度,并针对每个维度单独微调 LoRA 专家。然后,它们的输出由 MLP 合成以计算最终奖励。为了最大限度地降低成本,我们调用公共 LLM API 来获取能力偏好标签。对手动标记数据集的验证证实,我们的模型与人类偏好实现了卓越的一致性,并且超越了先进的生成方法。同时,通过 BoN 采样和 RL 实验,我们证明我们的模型优于最先进的 RM 集成方法,并减轻了过度优化问题。 |
| Machine Translation in the Covid domain: an English-Irish case study for LoResMT 2021 Authors S amus Lankford, Haithem Afli, Andy Way 针对 LoResMT 2021 共享任务开发了将 Covid 数据从英语翻译成爱尔兰语的特定领域的翻译模型。应用领域适应技术,使用来自翻译总局的 Covid 适应通用 55k 语料库。将微调、混合微调和组合数据集方法与在扩展域数据集中训练的模型进行了比较。作为这项研究的一部分,开发了来自健康和教育领域的新冠病毒相关数据的英语爱尔兰数据集。性能最高的模型使用了 Transformer 架构,并使用扩展域 Covid 数据集进行了训练。 |
| RAGged Edges: The Double-Edged Sword of Retrieval-Augmented Chatbots Authors Philip Feldman. James R. Foulds, Shimei Pan ChatGPT 等大型语言模型法学硕士展示了人工智能的显着进步。然而,他们产生幻觉的倾向会产生看似合理但虚假的信息,这构成了重大挑战。这个问题至关重要,从最近的法庭案件中可以看出,ChatGPT 的使用导致引用了不存在的法律裁决。本文探讨了检索增强生成 RAG 如何通过将外部知识与提示相结合来对抗幻觉。我们使用旨在诱发幻觉的提示,根据标准法学硕士对 RAG 进行实证评估。我们的结果表明,RAG 在某些情况下提高了准确性,但当提示直接与模型预先训练的理解相矛盾时,仍然可能会被误导。这些发现凸显了幻觉的复杂性以及对更强大的解决方案的需求,以确保法学硕士在现实世界应用中的可靠性。 |
| A Compositional Typed Semantics for Universal Dependencies Authors Laurestine Bradford, Timothy John O Donnell, Siva Reddy 语言可以使用不同的句子结构来编码相似的含义。这使得提供一套可以同时从多种语言的句子中得出含义的正式规则成为一项挑战。为了克服这一挑战,我们可以利用意义和语法之间的语言一般联系,并建立跨语言并行的句法结构。我们介绍 UD 类型演算,这是一种组合的、有原则的、与语言无关的词汇项语义类型和逻辑形式系统,它建立在广泛使用的语言通用依存语法框架之上。我们解释了 UD 类型微积分的基本特征,这些特征都涉及给出像单词一样的依赖关系指示。这些允许 UD TC 通过使用依存标签为具有广泛句法结构的句子导出正确的含义。 |
| Balancing Exploration and Exploitation in LLM using Soft RLLF for Enhanced Negation Understanding Authors Ha Thanh Nguyen, Ken Satoh NLP 中的微调方法通常侧重于利用而不是探索,这可能会导致模型不理想。考虑到自然语言的巨大搜索空间,这种有限的探索可能会限制它们在复杂、高风险领域的表现,而在这些领域,准确的否定理解和逻辑推理能力至关重要。为了解决这个问题,我们利用逻辑反馈 RLLF 的强化学习在法学硕士的探索和利用之间建立有效的平衡。我们的方法采用适当的基准数据集进行训练和评估,强调探索在增强否定理解能力方面的重要性。我们将 RLLF 增强型 LLM 的性能与未经 RLLF 训练的基线模型进行比较,证明了这种平衡方法的价值。此外,我们通过采用迁移学习并评估其对否定理解的影响,展示了我们的方法在法律人工智能应用中的潜力。我们的实验结果展示了利用 RLLF 平衡探索和利用在提高 LLM 否定能力方面的有效性。 |
| DINER: Debiasing Aspect-based Sentiment Analysis with Multi-variable Causal Inference Authors Jialong Wu, Linhai Zhang, Deyu Zhou, Guoqiang Xu 尽管已经取得了显着的进展,但基于神经方面的情感分析 ABSA 模型很容易从注释偏差中学习虚假相关性,导致对抗性数据转换的鲁棒性较差。在去偏差解决方案中,基于因果推理的方法引起了广泛的研究关注,主要可分为因果干预方法和反事实推理方法。然而,目前的去偏方法大多侧重于单变量因果推理,这不适用于具有目标方面和评论两个输入变量的ABSA。在本文中,我们提出了一种基于多变量因果推理的新颖框架,用于消除 ABSA 偏差。在此框架中,根据不同的因果干预方法来解决不同类型的偏见。对于审查分支,偏差被建模为来自上下文的间接混杂,其中采用后门调整干预来消除偏差。对于方面分支,偏差被描述为与标签直接相关,其中采用反事实推理来消除偏差。 |
| STAR: Constraint LoRA with Dynamic Active Learning for Data-Efficient Fine-Tuning of Large Language Models Authors Linhai Zhang, Jialong Wu, Deyu Zhou, Guoqiang Xu 尽管大型语言模型法学硕士已经通过提示方法展示了少量镜头学习的强大能力,但对于复杂的推理任务,监督训练仍然是必要的。由于其广泛的参数和内存消耗,参数高效微调 PEFT 方法和内存高效微调方法已被提出用于 LLM。然而,大量注释数据消耗的问题(数据高效微调的目标)仍未得到探索。一种明显的方法是将 PEFT 方法与主动学习相结合。然而,实验结果表明,这种组合并非微不足道,并且产生的结果较差。通过探针实验,这种观察结果可能可以用两个主要原因来解释:不确定性差距和模型校准不良。因此,在本文中,我们提出了一种有效整合基于不确定性的主动学习和 LoRA 的新方法。具体来说,对于不确定性差距,我们引入了动态不确定性测量,在主动学习的迭代过程中结合了基础模型的不确定性和完整模型的不确定性。针对较差的模型校准,我们在LoRA训练过程中加入正则化方法来防止模型过度自信,并采用蒙特卡罗dropout机制来增强不确定性估计。 |
| BootTOD: Bootstrap Task-oriented Dialogue Representations by Aligning Diverse Responses Authors Weihao Zeng, Keqing He, Yejie Wang, Dayuan Fu, Weiran Xu 预训练的语言模型在许多场景中都取得了成功。然而,由于一般文本和面向任务的对话之间存在内在的语言差异,它们在面向任务的对话中的用处受到限制。目前面向任务的对话预训练方法依赖于对比框架,面临着选择真阳性和硬阴性等挑战,并且缺乏多样性。在本文中,我们提出了一种新颖的对话预训练模型,称为 BootTOD。它通过自引导框架学习面向任务的对话表示。与对比对应物不同,BootTOD 对齐上下文和上下文响应表示,并消除对比对的要求。 BootTOD 还使用多个适当的响应目标来模拟人类对话的内在一对多多样性。 |
| A Survey of AI-generated Text Forensic Systems: Detection, Attribution, and Characterization Authors Tharindu Kumarage, Garima Agrawal, Paras Sheth, Raha Moraffah, Aman Chadha, Joshua Garland, Huan Liu 最近,我们目睹了能够生成高质量文本的高级大型语言模型法学硕士的快速增长。虽然这些法学硕士彻底改变了各个领域的文本生成,但它们也给信息生态系统带来了重大风险,例如大规模产生令人信服的宣传、错误信息和虚假信息的潜力。本文对人工智能生成的文本取证系统进行了回顾,这是一个解决法学硕士滥用挑战的新兴领域。我们通过引入详细的分类法,重点关注三个主要支柱:检测、归因和表征,概述了人工智能生成文本取证的现有工作。这些支柱使人们能够实际理解人工智能生成的文本,从识别人工智能生成的内容检测,确定涉及归因的特定人工智能模型,以及对文本表征的潜在意图进行分组。 |
| ParallelPARC: A Scalable Pipeline for Generating Natural-Language Analogies Authors Oren Sultan, Yonatan Bitton, Ron Yosef, Dafna Shahaf 类比是人类认知的核心,它使我们能够适应新的情况,而这是当前人工智能系统仍然缺乏的能力。如今,大多数类比数据集都专注于简单的类比,例如,包含复杂类型类比的单词类比数据集通常是手动管理的并且非常小。我们认为这阻碍了计算类比的进步。在这项工作中,我们设计了一个数据生成管道,即 ParallelPARC Parallel Paragraph Creator,利用最先进的大型语言模型 LLM 来创建复杂的、基于段落的类比以及干扰因素,既简单又具有挑战性。我们展示了我们的流程并创建了 ProPara Logy,这是一个科学过程之间类比的数据集。我们发布了由人类验证的黄金组和自动生成的白银组。我们在二元和多项选择设置中测试了法学硕士和人类类比识别,发现在轻度监督后,人类的表现优于最佳模型 13 倍。我们证明我们的银组对于训练模型很有用。最后,我们发现具有挑战性的干扰因素会让法学硕士感到困惑,但不会让人类感到困惑。 |
| MulCogBench: A Multi-modal Cognitive Benchmark Dataset for Evaluating Chinese and English Computational Language Models Authors Yunhao Zhang, Xiaohan Zhang, Chong Li, Shaonan Wang, Chengqing Zong 预先训练的计算语言模型最近在利用被认为是人类独有的语言能力方面取得了显着的进展。他们的成功引起了人们对这些模型是否像人类一样代表和处理语言的兴趣。为了回答这个问题,本文提出了 MulCogBench,这是一个从母语为中文和英语的参与者收集的多模态认知基准数据集。它包含各种认知数据,包括主观语义评分、眼球追踪、功能磁共振成像 fMRI 和脑磁图 MEG。为了评估语言模型和认知数据之间的关系,我们进行了相似性编码分析,该分析根据认知数据与文本嵌入的模式相似性对认知数据进行解码。结果表明,语言模型与人类认知数据具有显着的相似性,并且相似性模式受到数据模态和刺激复杂性的调节。具体来说,随着语言刺激复杂性的增加,上下文感知模型优于上下文无关模型。上下文感知模型的浅层与高时间分辨率 MEG 信号更好地对齐,而较深层则与高空间分辨率 fMRI 表现出更多相似性。这些结果表明语言模型与大脑语言表征有着微妙的关系。 |
| Distilling Text Style Transfer With Self-Explanation From LLMs Authors Chiyu Zhang, Honglong Cai, Yuezhang Music Li, Yuexin Wu, Le Hou, Muhammad Abdul Mageed 文本样式迁移 TST 旨在改变文本样式,同时保留其核心内容。考虑到 TST 并行数据集有限的限制,我们提出了 CoTeX,一个利用大型语言模型 LLM 以及 CoT 思想链促进 TST 的框架。 CoTeX 将法学硕士的复杂重写和推理能力提炼成更简化的模型,能够处理非并行和并行数据。通过对四个 TST 数据集的实验,CoTeX 被证明超越了传统的监督微调和知识蒸馏方法,特别是在资源匮乏的环境中。我们进行了全面的评估,将 CoTeX 与当前的无监督、监督、上下文学习 ICL 技术和指令调整的 LLM 进行比较。 |
| LAB: Large-Scale Alignment for ChatBots Authors Shivchander Sudalairaj, Abhishek Bhandwaldar, Aldo Pareja, Kai Xu, David D. Cox, Akash Srivastava 这项工作介绍了 LAB Large scale Alignment for chatBots,这是一种新颖的方法,旨在克服大型语言模型 LLM 训练的指令调整阶段的可扩展性挑战。利用分类学引导的合成数据生成过程和多阶段调整框架,LAB 显着减少了对昂贵的人工注释和 GPT 4 等专有模型的依赖。我们证明,与传统人工训练的模型相比,LAB 训练的模型可以在多个基准上实现具有竞争力的性能带注释或 GPT 4 生成的合成数据。 |
| LLMCRIT: Teaching Large Language Models to Use Criteria Authors Weizhe Yuan, Pengfei Liu, Matthias Gall 人类在执行任务时遵循标准,这些标准直接用于评估任务完成的质量。因此,让模型学习使用标准来提供反馈可以帮助人类或模型更好地执行任务。然而,该领域的现有研究往往只考虑一组有限的标准或质量评估方面。为了填补这一空白,我们提出了一个通用框架,使大型语言模型法学硕士能够使用任务的综合标准来提供有关任务执行的自然语言反馈。特别是,我们在循环框架中提出了一个模型,该模型从收集的不同写作任务指南中半自动地导出标准,并在每个标准的上下文演示中构建。我们从现实场景中选择了三个任务来实施这个想法论文介绍写作、Python 代码编写和 Reddit 帖子写作,并使用不同的法学硕士评估我们的反馈生成框架。 |
| FaiMA: Feature-aware In-context Learning for Multi-domain Aspect-based Sentiment Analysis Authors Songhua Yang, Xinke Jiang, Hanjie Zhao, Wenxuan Zeng, Hongde Liu, Yuxiang Jia 基于多领域方面的情感分析 ABSA 力求捕获跨不同领域的细粒度情感。虽然现有的研究狭隘地集中于受方法论限制和数据稀缺限制的单一领域应用,但现实是情绪自然地跨越多个领域。尽管大型语言模型法学硕士为 ABSA 提供了一个有前景的解决方案,但很难与现有技术(包括基于图的模型和语言学)有效集成,因为修改其内部架构并不容易。为了缓解这个问题,我们提出了一种新颖的框架,即特征感知上下文学习多域 ABSA FaiMA 。 FaiMA 的核心见解是在上下文学习中利用 ICL 作为一种特征感知机制,促进多领域 ABSA 任务中的自适应学习。具体来说,我们采用多头图注意力网络作为文本编码器,通过语言、领域和情感特征的启发式规则进行优化。通过对比学习,我们通过关注这些不同的特征来优化句子表示。此外,我们构建了一个高效的索引机制,使 FaiMA 能够针对任何给定输入稳定地跨多个维度检索高度相关的示例。为了评估 FaiMA 的功效,我们构建了第一个多域 ABSA 基准数据集。大量的实验结果表明,与基线相比,FaiMA 在多个领域实现了显着的性能改进,F1 平均提高了 2.07。 |
| Reading Subtext: Evaluating Large Language Models on Short Story Summarization with Writers Authors Melanie Subbiah, Sean Zhang, Lydia B. Chilton, Kathleen McKeown 我们对最近的大型语言模型法学硕士进行了总结短篇小说这一具有挑战性的任务的评估,这些短篇小说可能很长,并且包括微妙的潜台词或混乱的时间线。重要的是,我们直接与作者合作,以确保这些故事没有在网上分享,因此不会被模型看到,并根据作者自己的判断来获得对摘要质量的明智评估。通过基于叙事理论的定量和定性分析,我们比较了 GPT 4、Claude 2.1 和 LLama 2 70B。我们发现这三个模型在 50 多个摘要中都犯了忠实错误,并且难以解释困难的潜台词。然而,在最好的情况下,这些模型可以提供对故事进行深思熟虑的主题分析。 |
| Peacock: A Family of Arabic Multimodal Large Language Models and Benchmarks Authors Fakhraddin Alwajih, El Moatez Billah Nagoudi, Gagan Bhatia, Abdelrahman Mohamed, Muhammad Abdul Mageed 多模态大语言模型 MLLM 已被证明在需要复杂推理和语言理解的各种任务中是有效的。然而,由于缺乏英语以外的高质量多式联运资源,MLLM 的成功仍然相对限于英语环境。这对开发其他语言的可比模型提出了重大挑战,甚至包括阿拉伯语等人口众多的语言。为了缓解这一挑战,我们引入了一个全面的阿拉伯语 MLLM 系列,称为 textit Peacock,具有强大的视觉和语言能力。通过全面的定性和定量分析,我们展示了我们的模型在各种视觉推理任务上的可靠表现,并进一步展示了它们新兴的方言潜力。 |
| Attribute Structuring Improves LLM-Based Evaluation of Clinical Text Summaries Authors Zelalem Gero, Chandan Singh, Yiqing Xie, Sheng Zhang, Tristan Naumann, Jianfeng Gao, Hoifung Poon 总结临床文本对于健康决策支持和临床研究至关重要。大型语言模型法学硕士已显示出生成准确的临床文本摘要的潜力,但仍面临基础和评估方面的问题,特别是在健康等安全关键领域。全面评估文本摘要具有挑战性,因为它们可能包含未经证实的信息。在这里,我们探索使用 Attribute Structuring AS 的通用缓解框架,该框架构建了摘要评估过程。它将评估过程分解为一个基础程序,使用法学硕士进行相对简单的结构化和评分任务,而不是整体总结评估的完整任务。实验表明,AS 持续改善了临床文本摘要中人工注释和自动指标之间的对应关系。此外,AS 会以与每个输出相对应的短文本范围的形式产生解释,从而实现高效的人工审核,为在资源有限的情况下对临床信息进行可信评估铺平道路。 |
| Predictions from language models for multiple-choice tasks are not robust under variation of scoring methods Authors Polina Tsvilodub, Hening Wang, Sharon Grosch, Michael Franke 本文系统地比较了针对多项选择任务导出语言模型项目级预测的不同方法。它比较了基于自由生成响应的答案选项的评分方法、各种基于概率的评分、李克特量表风格评分方法和嵌入相似性。在关于语用语言解释的案例研究中,我们发现法学硕士的预测在方法选择变化的情况下并不稳健,无论是在单个法学硕士内还是在不同的法学硕士之间。 |
| Formulation Comparison for Timeline Construction using LLMs Authors Kimihiro Hasegawa, Nikhil Kandukuri, Susan Holm, Yukari Yamakawa, Teruko Mitamura 构建时间线需要确定文章中事件的时间顺序。在先前的时间线构建数据集中,时间顺序通常通过事件到时间锚定或事件到事件成对排序来注释,这两者都缺少时间信息。为了缓解这个问题,我们开发了一个新的评估数据集 TimeSET,它由带有文档级顺序注释的单个文档时间线组成。 TimeSET 具有基于显着性的事件选择和部分排序的功能,可实现实用的注释工作负载。为了构建更好的自动时间线构建系统,我们提出了一种新颖的评估框架,通过促进开放的 LLM(即 Llama 2 和 Flan T5)来将多个任务公式与 TimeSET 进行比较。考虑到识别事件的时间顺序是时间线构建中的核心子任务,我们进一步对现有事件时间顺序数据集上的开放法学硕士进行基准测试,以获得对其功能的深入了解。我们的实验表明,使用 Flan T5 的 1 NLI 公式在其他方面表现出了强大的性能,而 2 时间线构建和事件时间排序对于少数镜头法学硕士来说仍然是具有挑战性的任务。 |
| Merging Text Transformer Models from Different Initializations Authors Neha Verma, Maha Elbayad 最近基于一次性排列的模型合并的工作表明,来自完全不同的初始化的模型之间具有令人印象深刻的低或零障碍模式连接性。然而,尽管 Transformer 在语言领域占据主导地位,但该工作尚未扩展到 Transformer 架构。因此,在这项工作中,我们研究了单独的 Transformer 最小值学习相似特征的程度,并提出了一种模型合并技术来研究损失景观中这些最小值之间的关系。该架构的细节,如残差连接、多头注意力和离散顺序输入,需要特定的干预才能计算保留在同一功能等价类内的模型排列。在将这些模型与我们的方法合并时,我们一致发现,与在掩码语言建模任务上训练或在语言理解基准上进行微调的多个模型的模型平均相比,最小值之间的损失障碍更低。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页
pic from pexels.com