文章目录
- Kubernetes-4
- 1、pod的生命周期
- 2、pod的中止过程
- 3、强制终止pod
- 4、查看资源类型
- 4.1、kubectl get 后面接的都是资源类型
- 4.2、kubectl api-resources 查看目前有哪些资源类型
- 5、容器的状态
- 5.1、总结
- 5.2、Pod 状态和 Pod 内部容器状态
- 5.3、容器的重启策略
- 6、探针probe
- 6.1、什么是探针?
- 6.2、探针有什么用?
- 6.3、探针的类型
- 6.4、探针的优先级
- 6.5、探测方法
- 6.6、演示探测方法
- 6.6.1、exec
- 6.6.2、端口扫描
- 6.6.3、访问网站:httpget
- 7、最完美的探针例子
- 8、pod里的镜像升级和回滚
- 8.1、升级
- 8.2、回滚
- 9、HPA-VPA
- 9.1、HPA
- 9.1.1、HPA是什么
- 9.1.2、水平pod自动扩缩
- 9.1.3、做个实验,需要提前安装metrics-server
- 10、怎么停止一些没用的pod
Kubernetes-4
1、pod的生命周期
我们一般将pod对象从创建至终的这段时间范围称为pod的生命周期,它主要包含下面的过程:
-
pod创建过程—>
节点服务器上 -
先运行pause容器—>
创建命名空间 -
再运行初始化容器(init container)过程
-
然后运行主容器(main container)
- 容器启动后钩子(post start)、容器终止前钩子(pre stop)
- 容器的存活性探测(liveness probe)、就绪性探测(readiness probe)
-
pod终止过程:
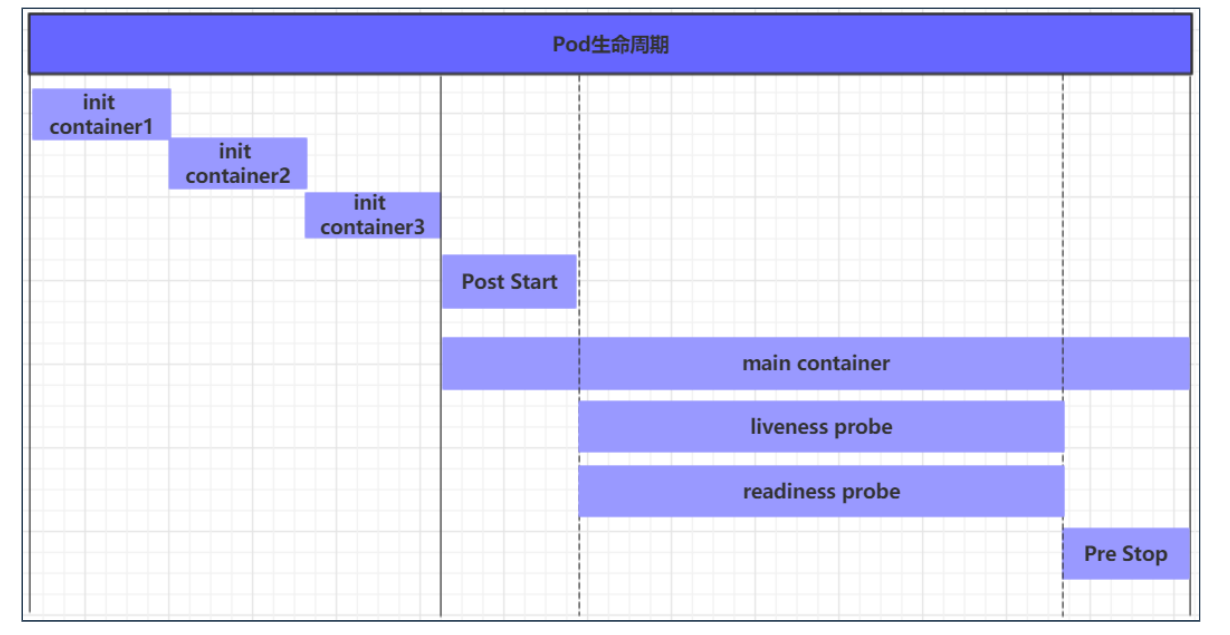
在整个生命周期中,Pod会出现5种状态(相位),分别如下:
-
挂起(Pending):apiserver已经创建了pod资源对象,但它尚未被调度完成或者仍处于下载镜像的过程中
-
运行中(Running):pod已经被调度至某节点,并且所有容器都已经被kubelet创建完成
-
成功(Succeeded):pod中的所有容器都已经成功终止并且不会被重启
-
失败(Failed):所有容器都已经终止,但至少有一个容器终止失败,即容器返回了非0值的退出状态
-
未知(Unknown):apiserver无法正常获取到pod对象的状态信息,通常由网络通信失败所导致
2、pod的中止过程
-
用户向apiServer发送删除pod对象的命令
-
apiServcer中的pod对象信息会随着时间的推移而更新,在宽限期内(默认30s),pod被视为dead
-
将pod标记为terminating状态---->正在被删除
-
kubelet在监控到pod对象转为terminating状态的同时启动pod关闭过程
-
端点控制器监控到pod对象的关闭行为时将其从所有匹配到此端点的service资源的端点列表中移除
-
如果当前pod对象定义了preStop钩子处理器,则在其标记为terminating后即会以同步的方式启动执行
-
pod对象中的容器进程收到停止信号
-
宽限期结束后,若pod中还存在仍在运行的进程,那么pod对象会收到立即终止的信号
-
kubelet请求apiServer将此pod资源的宽限期设置为0从而完成删除操作,此时pod对于用户已不可见

3、强制终止pod
kubectl --grace-period=0 --force
[root@master pod2]# kubectl delete --grace-period=0 --force -f simple-pod.yaml
warning: Immediate deletion does not wait for confirmation that the running resource has been terminated. The resource may continue to run on the cluster indefinitely.
namespace "sc2" force deleted
pod "sc-nginx-redis" force deleted
[root@master pod2]#

4、查看资源类型
4.1、kubectl get 后面接的都是资源类型
kubectl get node
kubectl get pod
kubectl get ns
kubectl get deploy
kubectl get rs
4.2、kubectl api-resources 查看目前有哪些资源类型
[root@master ~]# kubectl api-resources
NAME SHORTNAMES APIVERSION NAMESPACED KIND
bindings v1 true Binding
componentstatuses cs v1 false ComponentStatus
configmaps cm v1 true ConfigMap
endpoints ep v1 true Endpoints
events ev v1 true Event
limitranges limits v1 true LimitRange
namespaces ns v1 false Namespace
nodes no v1 false Node
persistentvolumeclaims pvc v1 true PersistentVolumeClaim
persistentvolumes pv v1 false PersistentVolume
pods po v1 true Pod
podtemplates v1 true PodTemplate
replicationcontrollers rc v1 true ReplicationController
resourcequotas quota v1 true ResourceQuota
secrets v1 true Secret
serviceaccounts sa v1 true ServiceAccount
services svc v1 true Service
mutatingwebhookconfigurations admissionregistration.k8s.io/v1 false MutatingWebhookConfiguration
validatingwebhookconfigurations admissionregistration.k8s.io/v1 false ValidatingWebhookConfiguration
customresourcedefinitions crd,crds apiextensions.k8s.io/v1 false CustomResourceDefinition
apiservices apiregistration.k8s.io/v1 false APIService
controllerrevisions apps/v1 true ControllerRevision
daemonsets ds apps/v1 true DaemonSet
deployments deploy apps/v1 true Deployment
replicasets rs apps/v1 true ReplicaSet
statefulsets sts apps/v1 true StatefulSet
tokenreviews authentication.k8s.io/v1 false TokenReview
localsubjectaccessreviews authorization.k8s.io/v1 true LocalSubjectAccessReview
selfsubjectaccessreviews authorization.k8s.io/v1 false SelfSubjectAccessReview
selfsubjectrulesreviews authorization.k8s.io/v1 false SelfSubjectRulesReview
subjectaccessreviews authorization.k8s.io/v1 false SubjectAccessReview
horizontalpodautoscalers hpa autoscaling/v1 true HorizontalPodAutoscaler
cronjobs cj batch/v1beta1 true CronJob
jobs batch/v1 true Job
certificatesigningrequests csr certificates.k8s.io/v1 false CertificateSigningRequest
leases coordination.k8s.io/v1 true Lease
bgpconfigurations crd.projectcalico.org/v1 false BGPConfiguration
bgppeers crd.projectcalico.org/v1 false BGPPeer
blockaffinities crd.projectcalico.org/v1 false BlockAffinity
clusterinformations crd.projectcalico.org/v1 false ClusterInformation
felixconfigurations crd.projectcalico.org/v1 false FelixConfiguration
globalnetworkpolicies crd.projectcalico.org/v1 false GlobalNetworkPolicy
globalnetworksets crd.projectcalico.org/v1 false GlobalNetworkSet
hostendpoints crd.projectcalico.org/v1 false HostEndpoint
ipamblocks crd.projectcalico.org/v1 false IPAMBlock
ipamconfigs crd.projectcalico.org/v1 false IPAMConfig
ipamhandles crd.projectcalico.org/v1 false IPAMHandle
ippools crd.projectcalico.org/v1 false IPPool
kubecontrollersconfigurations crd.projectcalico.org/v1 false KubeControllersConfiguration
networkpolicies crd.projectcalico.org/v1 true NetworkPolicy
networksets crd.projectcalico.org/v1 true NetworkSet
endpointslices discovery.k8s.io/v1beta1 true EndpointSlice
events ev events.k8s.io/v1 true Event
ingresses ing extensions/v1beta1 true Ingress
flowschemas flowcontrol.apiserver.k8s.io/v1beta1 false FlowSchema
prioritylevelconfigurations flowcontrol.apiserver.k8s.io/v1beta1 false PriorityLevelConfiguration
nodes metrics.k8s.io/v1beta1 false NodeMetrics
pods metrics.k8s.io/v1beta1 true PodMetrics
ingressclasses networking.k8s.io/v1 false IngressClass
ingresses ing networking.k8s.io/v1 true Ingress
networkpolicies netpol networking.k8s.io/v1 true NetworkPolicy
runtimeclasses node.k8s.io/v1 false RuntimeClass
poddisruptionbudgets pdb policy/v1beta1 true PodDisruptionBudget
podsecuritypolicies psp policy/v1beta1 false PodSecurityPolicy
clusterrolebindings rbac.authorization.k8s.io/v1 false ClusterRoleBinding
clusterroles rbac.authorization.k8s.io/v1 false ClusterRole
rolebindings rbac.authorization.k8s.io/v1 true RoleBinding
roles rbac.authorization.k8s.io/v1 true Role
priorityclasses pc scheduling.k8s.io/v1 false PriorityClass
csidrivers storage.k8s.io/v1 false CSIDriver
csinodes storage.k8s.io/v1 false CSINode
storageclasses sc storage.k8s.io/v1 false StorageClass
volumeattachments storage.k8s.io/v1 false VolumeAttachment
[root@master ~]# 5、容器的状态
5.1、总结
在Docker中,容器的状态通常有以下几种:
created:容器已创建但尚未启动。restarting:容器正在重新启动。running:容器正在运行。paused:容器已暂停。exited:容器已停止并退出。dead:容器已停止但未成功退出。
在 Kubernetes 中,容器(Pod)的状态是由其内部容器的状态决定的。在 Kubernetes 中,每个 Pod 可以包含一个或多个容器。每个容器在 Pod 中都有自己的状态,主要包括以下几种:
Waiting:容器正在等待某个事件的发生,比如正在下载镜像、调度等待等。Running:容器正在运行中。Terminated:容器已经完成运行,并且已经退出。Unknown:无法获取容器的状态信息。
在 Pod 级别,主要有以下几种状态:
Pending:Pod 已经被创建,但是还未被调度到节点上运行。Running:Pod 中的所有容器都在运行中。Succeeded:Pod 中的所有容器都已经成功完成并退出。Failed:Pod 中的一个或多个容器运行失败。Unknown:无法获取 Pod 的状态信息。ContainerCreating:当一个 Pod 中的容器正在创建时,整个 Pod 的状态会被设置为ContainerCreating。这种状态通常发生在 Pod 创建后,容器镜像需要下载或者容器正在初始化的过程中。当所有容器都创建完成后,Pod 的状态会改变为Running或者Failed,取决于创建过程是否成功。Terminating:当一个 Pod 中的容器正在终止时,整个 Pod 的状态会被设置为Terminating。这种状态通常发生在用户主动删除 Pod 或者 Pod 被调度器驱逐时。在 Pod 被删除的过程中,Kubernetes 会逐个终止 Pod 中的容器,直到所有容器都被终止完毕。最终,整个 Pod 的状态会被设置为Terminated。Initializing:当Pod中的一个或多个容器正在初始化并准备运行时,Pod的状态会被设置为Initializing。这种状态通常发生在容器启动前需要执行一些初始化操作的情况下。CrashLoopBackOff:当一个Pod中的容器因为频繁崩溃而无法正常运行时,Pod的状态会被设置为CrashLoopBackOff。这种状态通常发生在容器启动后立即崩溃并且无法恢复的情况下。Terminated:当一个Pod中的所有容器都已经终止并退出时,整个Pod的状态会被设置为Terminated。这表示Pod已经完成了所有任务并且不再运行。
总的来说,Kubernetes 中的容器和 Pod 的状态是相互关联的,通过监控这些状态可以帮助用户了解容器和 Pod 的运行情况,及时发现和解决问题。
5.2、Pod 状态和 Pod 内部容器状态
当谈到 Kubernetes 中的 Pod 状态和 Pod 内部容器状态时,需要理解 Pod 和容器之间的关系。
- Pod 是 Kubernetes 中最小的调度单元,它可以包含一个或多个容器。Pod 中的所有容器共享网络和存储资源,它们运行在共享的 Linux namespace 中。
- 在 Pod 中,每个容器都有自己的状态,比如
Waiting、Running、Terminated等。这些状态反映了容器当前所处的运行情况,比如容器是否在等待某个事件的发生、是否正在运行中、是否已经完成运行并退出等。 - Pod 的状态受其内部容器状态的影响。当 Pod 中的所有容器都处于
Running状态时,整个 Pod 的状态将被设置为Running。同样,如果 Pod 中的任何一个容器进入了Terminated状态,整个 Pod 的状态也会受到影响。 - Pod 的状态还受到其他因素的影响,比如 Pod 是否已经被调度到节点上运行、Pod 中的容器是否正在创建、是否正在终止等。这些因素都会对 Pod 的状态产生影响,并且反映了 Pod 在 Kubernetes 集群中的当前状态。
总的来说,Pod 的状态与其内部容器的状态密切相关,通过监控和理解 Pod 内部容器的状态,可以更好地了解 Pod 的运行情况,及时发现和解决问题。希望这样的解释能帮助您更好地理解 Pod 和容器状态之间的关系。
5.3、容器的重启策略
Pod 的 spec 中包含一个 restartPolicy 字段,其可能取值包括 Always、OnFailure 和 Never。默认值是 Always。
restartPolicy 应用于 Pod 中的应用容器和常规的 Init 容器。
Sidecar 容器忽略 Pod 级别的 restartPolicy 字段:在 Kubernetes 中,Sidecar 被定义为 initContainers 内的一个条目,其容器级别的 restartPolicy 被设置为 Always。 对于因错误而退出的 Init 容器,如果 Pod 级别 restartPolicy 为 OnFailure 或 Always, 则 kubelet 会重新启动 Init 容器。
-
容器重启处理:当容器因为某种原因退出时,kubelet 会根据配置的重启策略处理容器的重启。重启策略仅适用于同一 Pod 内替换容器并在同一节点上运行的重启。kubelet 会按指数回退方式计算容器重启的延迟,最长延迟为 5 分钟。如果某容器执行了 10 分钟并没有出现问题,kubelet 会重置该容器的重启回退计时器。
-
init containers 的行为:对于因错误而退出的 Init 容器,如果 Pod 级别的 restartPolicy 为 OnFailure 或 Always,kubelet 会重新启动这些 Init 容器。
6、探针probe
6.1、什么是探针?
probe 是由 kubelet 对容器执行的定期诊断。 要执行诊断,kubelet 既可以在容器内执行代码,也可以发出一个网络请求。
-
银针–》试探食物里是否有毒
-
探针: 探测pod是否正常健康运行 --》监控
6.2、探针有什么用?
-
使用探针去试探pod是否能正常提供服务
-
监控pod的
-
在pod启动的不同阶段使用不同的方法去监控,判断pod是否正常
检测pod里的容器是否正常运行
6.3、探针的类型
1.存活 liveness --》pod启动起来
2.就绪 readiness -->pod里的主程序需要启动
3. 启动 startup --》主程序启动起来了
6.4、探针的优先级
先进性startup探针,然后再进行liveness探针
6.5、探测方法
- exec 执行命令 execute --》到容器里去运行一条命令,如果命令执行成功,就说明pod是存活的 kubectl exec
- grpc 协议 -->
rpc—>远程调用访问某个端口—》使用grpc协议去访问 - httpget -->
http—》使用http协议去访问 - tcpsocket -->访问pod里的主程序开放的端口 --》nc,nmap,telnet等 —》端口扫描
6.6、演示探测方法
6.6.1、exec
[root@master pod]# cd proce/
[root@master proce]# vim liveness.yaml
apiVersion: v1
kind: Pod
metadata:labels:test: livenessname: liveness-exec
spec:containers:- name: livenessimage: busyboxargs:- /bin/sh- -c- touch /tmp/healthy; sleep 30; rm -f /tmp/healthy; sleep 600livenessProbe:exec:command:- cat- /tmp/healthyinitialDelaySeconds: 5 #容器启动后延迟5s去执行探针periodSeconds: 5 #探测的周期是5s一次
这段 YAML 配置文件描述了一个 Pod,其中包含一个名为 liveness 的容器。这个容器使用 busybox 镜像,并执行一系列命令来模拟 liveness 检查。
具体解释如下:
metadata: 定义了 Pod 的元数据,包括标签和名称。spec: 定义了 Pod 中的容器和相关配置。containers: 列出了 Pod 中的容器列表。name: 定义了容器的名称为 liveness。image: 指定了容器使用的镜像为 registry.k8s.io/busybox。args: 指定了容器启动时执行的命令,包括创建一个/tmp/healthy文件、休眠30秒、删除/tmp/healthy文件、休眠600秒。livenessProbe: 定义了 liveness 探针,用于检测容器是否健康。exec: 指定了使用 exec 检查方式,执行指定的命令。command: 指定了要执行的命令,这里是 cat /tmp/healthy,即检查/tmp/healthy文件是否存在。
initialDelaySeconds: 定义了启动容器后多久开始进行 liveness 检查,这里是5秒。periodSeconds: 定义了 liveness 检查的间隔时间,这里是5秒。
总的来说,这个配置文件描述了一个 Pod,其中的 liveness 容器在启动后会创建一个/tmp/healthy文件,然后根据 livenessProbe 配置的 exec 检查方式检查该文件是否存在,从而判断容器的健康状态。
[root@master proce]# vim liveness.yaml
[root@master proce]# kubectl apply -f liveness.yaml
pod/liveness-exec created
[root@master proce]# kubectl get pod
NAME READY STATUS RESTARTS AGE
counter 3/3 Running 6 45h
liveness-exec 0/1 ContainerCreating 0 8s
myapp-pod 1/1 Running 5 44h
nginx 1/1 Running 5 3d16h
redis 1/1 Running 2 2d2h
[root@master proce]# [root@master proce]# kubectl get pod|grep exec
liveness-exec 1/1 Running 1 2m27s
[root@master proce]#
这时候发现重启了一次
6.6.2、端口扫描
[root@master pod2]# yum install nc -y
[root@master pod2]# nc -z www.baidu.com 80
[root@master pod2]# echo $?
0
[root@master pod2]# nc -z www.baidu.com 8080
[root@master pod2]# echo $?
1
[root@master pod2]#
nc的返回值是0就是成功,开放80端口
nc的返回值是1就是失败,没有开放8080端口
详细例子:
[root@master proce]# cat tcp-liveness-readiness.yaml
apiVersion: v1
kind: Pod
metadata:name: goproxylabels:app: goproxy
spec:containers:- name: goproxyimage: registry.k8s.io/goproxy:0.1imagePullPolicy: IfNotPresentports:- containerPort: 8080readinessProbe:tcpSocket:port: 8080initialDelaySeconds: 5periodSeconds: 10livenessProbe:tcpSocket:port: 8080initialDelaySeconds: 15periodSeconds: 20
[root@master proce]#
[root@master proce]# kubectl apply -f tcp-liveness-readiness.yaml
pod/goproxy created
[root@master proce]# kubectl describe -f tcp-liveness-readiness.yaml Liveness: tcp-socket :8080 delay=15s timeout=1s period=20s #success=1 #failure=3Readiness: tcp-socket :8080 delay=5s timeout=1s period=10s #success=1 #failure=3在nginx实验中,也加入tcpsocket验证
[root@master pod2]# cat simple-pod.yaml
apiVersion: v1
kind: Namespace
metadata:name: sc2
---
apiVersion: v1
kind: Pod
metadata:name: sc-nginx-redisnamespace: sc2
spec:nodeName: node-2containers:- name: sc-nginximage: nginx:latestimagePullPolicy: IfNotPresentports:- containerPort: 80livenessProbe:httpGet:path: /port: 8080initialDelaySeconds: 5periodSeconds: 3readinessProbe:tcpSocket:port: 8090initialDelaySeconds: 5periodSeconds: 10- name: sc-redisimage: redis:latestimagePullPolicy: IfNotPresentports:- containerPort: 6379nodeName: node-2restartPolicy: Always
[root@master pod2]#
[root@master pod2]# kubectl apply -f simple-pod.yaml
namespace/sc2 created
pod/sc-nginx-redis created
[root@master pod2]# kubectl describe -f simple-pod.yaml
Liveness: http-get http://:8080/ delay=5s timeout=1s period=3s #success=1 #failure=3Readiness: tcp-socket :8090 delay=5s timeout=1s period=10s #success=1 #failure=3
Events:Type Reason Age From Message---- ------ ---- ---- -------Normal Pulled 29s kubelet Container image "redis:latest" already present on machineNormal Created 29s kubelet Created container sc-redisNormal Started 29s kubelet Started container sc-redisWarning Unhealthy 24s kubelet Readiness probe failed: dial tcp 10.244.247.39:8090: connect: connection refusedNormal Created 6s (x3 over 29s) kubelet Created container sc-nginxNormal Started 6s (x3 over 29s) kubelet Started container sc-nginxNormal Pulled 6s (x3 over 29s) kubelet Container image "nginx:latest" already present on machineWarning Unhealthy 6s (x6 over 24s) kubelet Liveness probe failed: Get "http://10.244.247.39:8080/": dial tcp 10.244.247.39:8080: connect: connection refusedNormal Killing 6s (x2 over 18s) kubelet Container sc-nginx failed liveness probe, will be restarted
6.6.3、访问网站:httpget
适合里面跑web程序的容器
[root@master pod2]# vim simple-pod.yaml
apiVersion: v1
kind: Namespace
metadata:name: sc2
---
apiVersion: v1
kind: Pod
metadata:name: sc-nginx-redisnamespace: sc2
spec:nodeName: node-2containers:- name: sc-nginximage: nginx:latestimagePullPolicy: IfNotPresentports:- containerPort: 80livenessProbe:httpGet:path: /port: 80initialDelaySeconds: 5periodSeconds: 3- name: sc-redisimage: redis:latestimagePullPolicy: IfNotPresentports:- containerPort: 6379nodeName: node-2restartPolicy: Always
[root@master pod2]#
-
这部分定义了一个Pod,名称为"sc-nginx-redis",并指定其所属Namespace为"sc2"。
-
Pod中包含两个容器,一个是名为"sc-nginx"的容器,使用的镜像是nginx:latest,暴露端口为80;另一个是名为"sc-redis"的容器,使用的镜像是redis:latest,暴露端口为6379。
-
Pod设置了nodeName为"node-2",表示将在名为"node-2"的节点上调度Pod。
-
Pod的重启策略是Always,表示当容器失败时将尝试重启容器。
-
此外,Pod还定义了livenessProbe用于检测容器的健康状态,通过向容器的端口80发送HTTP GET请求来判断容器的存活状态。
[root@master pod2]# kubectl apply -f simple-pod.yaml
namespace/sc2 unchanged
pod/sc-nginx-redis created
[root@master pod2]# kubectl describe -f simple-pod.yaml Liveness: http-get http://:80/ delay=5s timeout=1s period=3s #success=1 #failure=3
http-get http://:80/ 没有显示地址
改一下yaml文件重新看看
[root@master pod2]# vim simple-pod.yaml
apiVersion: v1
kind: Namespace
metadata:name: sc2
---
apiVersion: v1
kind: Pod
metadata:name: sc-nginx-redisnamespace: sc2
spec:nodeName: node-2containers:- name: sc-nginximage: nginx:latestimagePullPolicy: IfNotPresentports:- containerPort: 80livenessProbe:httpGet:path: /port: 8080initialDelaySeconds: 5periodSeconds: 3- name: sc-redisimage: redis:latestimagePullPolicy: IfNotPresentports:- containerPort: 6379nodeName: node-2restartPolicy: Always
[root@master pod2]#
[root@master pod2]# kubectl apply -f simple-pod.yaml
namespace/sc2 created
pod/sc-nginx-redis created
[root@master pod2]# Warning Unhealthy 2s (x3 over 8s) kubelet Liveness probe failed: Get "http://10.244.247.37:8080/": dial tcp 10.244.247.37:8080: connect: connection refused
[root@master pod2]# kubectl get -f simple-pod.yaml
NAME STATUS AGE
namespace/sc2 Active 79sNAME READY STATUS RESTARTS AGE
pod/sc-nginx-redis 2/2 Running 4 78s
[root@master pod2]#
很成功,重启4次了
再试试另一个例子:
[root@master proce]# vim http-liveness.yaml
apiVersion: v1
kind: Pod
metadata:labels:test: livenessname: liveness-http
spec:containers:- name: livenessimage: registry.k8s.io/livenessimagePullPolicy: IfNotPresentargs:- /serverlivenessProbe:httpGet:path: /healthzport: 8080httpHeaders:- name: Custom-Headervalue: AwesomeinitialDelaySeconds: 3periodSeconds: 3
[root@master proce]#
[root@master proce]# kubectl apply -f http-liveness.yaml
[root@master proce]# kubectl describe -f http-liveness.yaml Warning Unhealthy 6s (x3 over 12s) kubelet Liveness probe failed: HTTP probe failed with statuscode: 500
7、最完美的探针例子
[root@master pod2]# vim simple-pod.yaml
apiVersion: v1
kind: Namespace
metadata:name: sc2
---
apiVersion: v1
kind: Pod
metadata:name: sc-nginx-redisnamespace: sc2
spec:nodeName: node-2containers:- name: sc-nginximage: nginx:latestimagePullPolicy: IfNotPresentports:- containerPort: 80livenessProbe:httpGet:path: /port: 8080initialDelaySeconds: 3periodSeconds: 3readinessProbe:tcpSocket:port: 8090initialDelaySeconds: 5periodSeconds: 10startupProbe:tcpSocket:port: 8078initialDelaySeconds: 5periodSeconds: 10- name: sc-redisimage: redis:latestimagePullPolicy: IfNotPresentports:- containerPort: 6379nodeName: node-2restartPolicy: Always
[root@master pod2]#
[root@master pod2]# kubectl apply -f simple-pod.yaml
namespace/sc2 unchanged
pod/sc-nginx-redis created
[root@master pod2]# kubectl describe -f simple-pod.yaml
Liveness: http-get http://:8080/ delay=3s timeout=1s period=3s #success=1 #failure=3Readiness: tcp-socket :8090 delay=5s timeout=1s period=10s #success=1 #failure=3Startup: tcp-socket :8078 delay=5s timeout=1s period=10s #success=1 #failure=3
Events:Type Reason Age From Message---- ------ ---- ---- -------Normal Pulled 50s kubelet Container image "nginx:latest" already present on machineNormal Created 50s kubelet Created container sc-nginxNormal Started 50s kubelet Started container sc-nginxNormal Pulled 50s kubelet Container image "redis:latest" already present on machineNormal Created 50s kubelet Created container sc-redisNormal Started 50s kubelet Started container sc-redisWarning Unhealthy 21s (x3 over 41s) kubelet Startup probe failed: dial tcp 10.244.247.40:8078: connect: connection refused
注意:
startupProbe能和其他探针共存,如果执行失败,就不再执行其他的探针了。如果执行成功,还是会其他的探针
如果启动了startupProbe其他的探针会被禁用
所以得修改一下yaml文件
[root@master pod2]# vim simple-pod.yaml
apiVersion: v1
kind: Namespace
metadata:name: sc2
---
apiVersion: v1
kind: Pod
metadata:name: sc-nginx-redisnamespace: sc2
spec:nodeName: node-2containers:- name: sc-nginximage: nginx:latestimagePullPolicy: IfNotPresentports:- containerPort: 80livenessProbe:httpGet:path: /port: 8080initialDelaySeconds: 3periodSeconds: 3readinessProbe:tcpSocket:port: 80initialDelaySeconds: 5periodSeconds: 10startupProbe:tcpSocket:port: 8078initialDelaySeconds: 5periodSeconds: 10- name: sc-redisimage: redis:latestimagePullPolicy: IfNotPresentports:- containerPort: 6379nodeName: node-2restartPolicy: Always
[root@master pod2]#
[root@master pod2]# kubectl apply -f simple-pod.yaml
namespace/sc2 created
pod/sc-nginx-redis created
[root@master pod2]# kubectl describe -f simple-pod.yaml
[root@master pod2]# kubectl apply -f simple-pod.yaml
namespace/sc2 created
pod/sc-nginx-redis created
[root@master pod2]# kubectl describe -f simple-pod.yaml Liveness: http-get http://:8080/ delay=3s timeout=1s period=3s #success=1 #failure=3Readiness: tcp-socket :8090 delay=5s timeout=1s period=10s #success=1 #failure=3Startup: tcp-socket :80 delay=5s timeout=1s period=10s #success=1 #failure=3
Events:Type Reason Age From Message---- ------ ---- ---- -------Normal Pulled 67s kubelet Container image "redis:latest" already present on machineNormal Created 67s kubelet Created container sc-redisNormal Started 67s kubelet Started container sc-redisNormal Pulled 28s (x3 over 67s) kubelet Container image "nginx:latest" already present on machineNormal Created 28s (x3 over 67s) kubelet Created container sc-nginxNormal Started 28s (x3 over 67s) kubelet Started container sc-nginxNormal Killing 28s (x2 over 49s) kubelet Container sc-nginx failed liveness probe, will be restartedWarning Unhealthy 13s (x8 over 55s) kubelet Liveness probe failed: Get "http://10.244.247.44:8080/": dial tcp 10.244.247.44:8080: connect: connection refusedWarning Unhealthy 10s (x3 over 50s) kubelet Readiness probe failed: dial tcp 10.244.247.44:8090: connect: connection refused
Liveness和Readiness 演示成功
8、pod里的镜像升级和回滚
官方文档:https://kubernetes.io/zh-cn/docs/concepts/workloads/controllers/deployment/
8.1、升级
-
部署一个nginx
[root@master image]# vim nginx-deployment.yaml apiVersion: apps/v1 kind: Deployment metadata:name: sc-nginx-deploymentlabels:app: nginx spec:replicas: 2selector:matchLabels:app: nginxtemplate:metadata:labels:app: nginxspec:containers:- name: nginximage: nginx:1.14.2ports:- containerPort: 80 [root@master image]#
apiVersion: apps/v1: 指定了使用的 Kubernetes API 版本为 apps/v1。kind: Deployment: 定义了该 YAML 文件中的对象类型为 Deployment。metadata: 元数据部分,包含了 Deployment 的名称和标签。name: sc-nginx-deployment: 指定了 Deployment 的名称为 sc-nginx-deployment。labels: 定义了标签,这里指定了一个标签为 app: nginx。
spec: Deployment 的规格部分,定义了 Deployment 的规格信息。replicas: 2: 指定了该 Deployment 的副本数为 2,即需要部署两个 Pod。selector: 选择器部分,指定了如何选择要控制的 Pod。matchLabels: 匹配标签为 app: nginx 的 Pod。
template: Pod 的模板部分,定义了要创建的 Pod 的模板信息。metadata: Pod 的元数据部分,包含了 Pod 的标签。labels: 定义了 Pod 的标签,与 Deployment 的标签相同。
spec: Pod 的规格部分,定义了 Pod 的规格信息。containers: 容器部分,定义了要在 Pod 中运行的容器。name: nginx: 容器的名称为 nginx。image: nginx:1.14.2: 指定了容器要运行的镜像为 nginx:1.14.2。ports: 指定了容器暴露的端口,这里将容器的 80 端口映射到 Pod 的端口。
总的来说,该 YAML 文件描述了一个名为 sc-nginx-deployment 的 Deployment 对象,该 Deployment 包含了两个副本,每个副本运行一个名为 nginx 的容器,使用 nginx:1.14.2 镜像,并将容器的 80 端口映射到 Pod 的端口。Deployment 中的 Pod 根据标签选择器选择要控制的 Pod。
-
运行
[root@master image]# kubectl apply -f nginx-deployment.yaml deployment.apps/sc-nginx-deployment created [root@master image]# kubectl get -f nginx-deployment.yaml -o wide NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR sc-nginx-deployment 2/2 2 2 16s nginx nginx:1.14.2 app=nginx [root@master image]# -
进行升级,只需要把yaml文件中 nginx的版本改成高版本即可
[root@master image]# cat nginx-deployment.yaml apiVersion: apps/v1 kind: Deployment metadata:name: sc-nginx-deploymentlabels:app: nginx spec:replicas: 2selector:matchLabels:app: nginxtemplate:metadata:labels:app: nginxspec:containers:- name: nginximage: nginx:1.22.1ports:- containerPort: 80 -
开始更新,在线升级,不需要删除之前的pod
[root@master image]# kubectl apply -f nginx-deployment.yaml deployment.apps/sc-nginx-deployment configured [root@master image]# kubectl get -f nginx-deployment.yaml -o wide NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR sc-nginx-deployment 2/2 1 2 14m nginx nginx:1.22.1 app=nginx [root@master image]#[root@master image]# kubectl get pod -o wide --watch NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES sc-nginx-deployment-55f4d8c85-6q5hh 1/1 Running 0 111s 10.244.247.55 node-2 <none> <none> sc-nginx-deployment-55f4d8c85-rlr7t 1/1 Running 0 29s 10.244.247.56 node-2 <none> <none>他会帮我们重新启2个pod,然后删除之前的pod
-
解释一下滚动升级
-
首先一开始会有2个pod
-
升级开始:会先新建一个pod,删除1个旧pod,始终保持2个副本(因为yaml文件有要求)
-
然后新pod创建好之后,再创建一个pod,删除第二个旧pod,直到新pod运行
-
原来的副本控制器维持着旧的pod,然后升级之后,会创建新的副本控制器,控制升级之后的pod,原副本控制器会保留,弃用(给回滚做准备)
[root@master image]# kubectl get rs NAME DESIRED CURRENT READY AGE sc-nginx-deployment-55f4d8c85 2 2 2 10m sc-nginx-deployment-66b6c48dd5 0 0 0 24m [root@master image]#

-
8.2、回滚
-
查看历史版本
[root@master image]# kubectl rollout history deployment/sc-nginx-deployment deployment.apps/sc-nginx-deployment REVISION CHANGE-CAUSE 1 <none> 2 <none>[root@master image]# -
回滚到第一个版本
[root@master image]# kubectl rollout undo deployment/sc-nginx-deployment deployment.apps/sc-nginx-deployment rolled back [root@master image]# kubectl get -f nginx-deployment.yaml -o wide NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR sc-nginx-deployment 2/2 2 2 30m nginx nginx:1.14.2 app=nginx [root@master image]# -
回滚的方式有两种
1:'回到修订前的一个版本' kubectl rollout undo deployment/sc-nginx-deployment 2:'指定回退的版本' kubectl rollout undo deployment/sc-nginx-deployment --to-revision=1 -
回滚之后的副本控制器会变成之前的那个
[root@master image]# kubectl get rs NAME DESIRED CURRENT READY AGE sc-nginx-deployment-55f4d8c85 0 0 0 16m sc-nginx-deployment-66b6c48dd5 2 2 2 30m [root@master image]# kubectl get pod -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES sc-nginx-deployment-66b6c48dd5-cxkzn 1/1 Running 0 32s 10.244.84.176 node-1 <none> <none> sc-nginx-deployment-66b6c48dd5-qmmn6 1/1 Running 0 31s 10.244.84.177 node-1 <none> <none> [root@master image]#
9、HPA-VPA
9.1、HPA
9.1.1、HPA是什么
HPA 是 Horizontal Pod Autoscaler 的缩写,是 Kubernetes 中的一个资源,用于根据 CPU 使用率或自定义指标来自动调整 Pod 的副本数量,以实现自动水平扩展或收缩应用程序的能力。HPA 会监控 Pod 的 CPU 使用率或自定义指标,并根据预设的规则来增加或减少 Pod 的副本数量,从而确保应用程序能够有效地利用集群资源,同时保持稳定和高可用性。HPA 可以帮助避免资源浪费和提高应用程序的响应能力。
9.1.2、水平pod自动扩缩
水平扩缩是:增加pod的数量
垂直扩缩是:是增加pod的cpu和内存的大小
HPA—>降低基础设施的成本
9.1.3、做个实验,需要提前安装metrics-server
去网上找资源下载:hpa-example.tar 镜像
[root@master hpa]# scp hpa-example.tar node-2:/root
hpa-example.tar 100% 482MB 127.2MB/s 00:03
[root@master hpa]#
'传递到node-2上'
- 开始写yaml文件
[root@master hpa]# vim php-apache.yaml
apiVersion: apps/v1
kind: Deployment
metadata:name: php-apache
spec:selector:matchLabels:run: php-apachetemplate:metadata:labels:run: php-apachespec:nodeName: node-2containers:- name: php-apacheimage: registry.cn-beijing.aliyuncs.com/google_registry/hpa-exampleimagePullPolicy: IfNotPresentports:- containerPort: 80resources:limits:cpu: 500mrequests:cpu: 200m
---
apiVersion: v1
kind: Service
metadata:name: php-apachelabels:run: php-apache
spec:ports:- port: 80selector:run: php-apache
---
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:name: php-apache
spec:scaleTargetRef:apiVersion: apps/v1kind: Deploymentname: php-apacheminReplicas: 1maxReplicas: 10targetCPUUtilizationPercentage: 50
[root@master hpa]#
- 启动
[root@master hpa]# kubectl apply -f php-apache.yaml
deployment.apps/php-apache created
service/php-apache created
[root@master hpa]#
-
创建一个水平扩缩的控制器
'在原有的yaml文件最后加上' --- apiVersion: autoscaling/v1 kind: HorizontalPodAutoscaler metadata:name: php-apache spec:scaleTargetRef: #指定HPA监控的对象apiVersion: apps/v1kind: Deploymentname: php-apache #指定deployment控制器的名字minReplicas: 1 #最少1个maxReplicas: 10 #最多10个pod副本targetCPUUtilizationPercentage: 50 #指定cpu的使用率达到50%就增加pod -
重新apply
[root@master hpa]# kubectl apply -f php-apache.yaml deployment.apps/php-apache unchanged service/php-apache unchanged horizontalpodautoscaler.autoscaling/php-apache created [root@master hpa]# -
查看资源
[root@master hpa]# kubectl get -f php-apache.yaml -o wide NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR deployment.apps/php-apache 1/1 1 1 113s php-apache registry.cn-beijing.aliyuncs.com/google_registry/hpa-example run=php-apacheNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR service/php-apache ClusterIP 10.105.60.246 <none> 80/TCP 113s run=php-apacheNAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE horizontalpodautoscaler.autoscaling/php-apache Deployment/php-apache 0%/50% 1 10 1 113s [root@master hpa]# -
查看pod是否启动
[root@master hpa]# kubectl get pod NAME READY STATUS RESTARTS AGE php-apache-5898d567df-wd4j7 1/1 Running 0 2m8s -
kubectl get hpa是用来获取 Kubernetes 集群中的 Horizontal Pod Autoscaler (HPA) 对象的信息[root@master hpa]# kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE php-apache Deployment/php-apache 0%/50% 1 10 1 8m14s [root@master hpa]# -
启动客户端去进行压力测试, 模拟用户去访问web服务,消耗大量的cpu资源
[root@master hpa]# kubectl run -i --tty load-generator --rm --image=busybox:1.28 --restart=Never -- /bin/sh -c "while sleep 0.01; do wget -q -O- http://php-apache; done" -
查看pod和副本
[root@master hpa]# kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE php-apache Deployment/php-apache 75%/50% 1 10 7 14m [root@master hpa]# kubectl get pod NAME READY STATUS RESTARTS AGE load-generator 1/1 Running 0 82s php-apache-5898d567df-2gmtg 0/1 OutOfmemory 0 4s php-apache-5898d567df-2w8xs 0/1 OutOfmemory 0 6s php-apache-5898d567df-4rs8k 1/1 Running 0 54s php-apache-5898d567df-5t6lm 0/1 OutOfmemory 0 1s php-apache-5898d567df-65f6z 0/1 OutOfmemory 0 6s php-apache-5898d567df-94ml5 0/1 Pending 0 0s php-apache-5898d567df-dd45v 0/1 OutOfmemory 0 8s php-apache-5898d567df-f24qf 0/1 OutOfmemory 0 2s php-apache-5898d567df-fn2st 0/1 OutOfmemory 0 3s php-apache-5898d567df-gmqxq 0/1 Pending 0 1s php-apache-5898d567df-hp22v 0/1 OutOfmemory 0 5s php-apache-5898d567df-j9m4b 0/1 OutOfmemory 0 8s php-apache-5898d567df-jgkjr 1/1 Running 0 54s php-apache-5898d567df-jnh4d 0/1 OutOfmemory 0 8s php-apache-5898d567df-khk2x 0/1 OutOfmemory 0 2s php-apache-5898d567df-kpmw2 0/1 OutOfmemory 0 7s php-apache-5898d567df-l2wfm 0/1 OutOfmemory 0 4s php-apache-5898d567df-ln244 0/1 OutOfmemory 0 8s php-apache-5898d567df-mj7lc 1/1 Running 0 54s php-apache-5898d567df-mqjpm 0/1 OutOfmemory 0 8s php-apache-5898d567df-ng488 1/1 Running 0 39s php-apache-5898d567df-nhpxj 0/1 OutOfmemory 0 6s php-apache-5898d567df-p5r6x 0/1 OutOfmemory 0 3s php-apache-5898d567df-rs625 0/1 OutOfmemory 0 8s php-apache-5898d567df-s64dc 0/1 OutOfmemory 0 8s php-apache-5898d567df-sdv8l 0/1 OutOfmemory 0 8s php-apache-5898d567df-tm6r5 0/1 OutOfmemory 0 2s php-apache-5898d567df-vdmsr 0/1 OutOfmemory 0 4s php-apache-5898d567df-wd4j7 1/1 Running 0 13m php-apache-5898d567df-z2hr7 0/1 OutOfmemory 0 8s php-apache-5898d567df-zg5dx 0/1 OutOfmemory 0 5s php-apache-5898d567df-ztdmv 0/1 OutOfmemory 0 7s sc-nginx-deployment-66b6c48dd5-cxkzn 1/1 Running 0 3h49m sc-nginx-deployment-66b6c48dd5-qmmn6 1/1 Running 0 3h49m [root@master hpa]# -
ctrl+c结束负载,观察kubectl get hpa和kubectl get pod 会慢慢降下来
[root@master hpa]# kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE php-apache Deployment/php-apache 0%/50% 1 10 7 17m [root@master hpa]#
10、怎么停止一些没用的pod
[root@master image]# kubectl get pod
NAME READY STATUS RESTARTS AGE
counter 3/3 Running 9 2d16h
goproxy 1/1 Running 1 15h
liveness-exec 0/1 CrashLoopBackOff 141 19h
liveness-http 0/1 CrashLoopBackOff 123 15h
myapp-pod 1/1 Running 15 2d15h
nginx 1/1 Running 6 4d11h
redis 1/1 Running 3 2d21h
sc-nginx-deployment-66b6c48dd5-885zb 1/1 Running 0 83s
sc-nginx-deployment-66b6c48dd5-bznvk 1/1 Running 0 83s
[root@master image]#
- 首先看部署控制器
[root@master image]# kubectl get deploy
NAME READY UP-TO-DATE AVAILABLE AGE
sc-nginx-deployment 2/2 2 2 2m43s
[root@master image]#
有多余的就删掉
-
如果发现部署控制器没有,你也找不到yaml文件了,直接删吧
[root@master image]# kubectl get deploy NAME READY UP-TO-DATE AVAILABLE AGE sc-nginx-deployment 2/2 2 2 4m18s [root@master image]# kubectl get pod NAME READY STATUS RESTARTS AGE counter 3/3 Running 9 2d16h goproxy 1/1 Running 1 15h liveness-exec 1/1 Running 143 19h liveness-http 0/1 CrashLoopBackOff 125 15h myapp-pod 1/1 Running 15 2d15h nginx 1/1 Running 6 4d11h redis 1/1 Running 3 2d21h sc-nginx-deployment-66b6c48dd5-885zb 1/1 Running 0 4m33s sc-nginx-deployment-66b6c48dd5-bznvk 1/1 Running 0 4m33s [root@master image]# kubectl delete pod counter pod "counter" deleted [root@master image]# kubectl delete pod goproxy pod "goproxy" deleted [root@master image]# kubectl delete pod liveness-exec pod "liveness-exec" deleted [root@master image]# kubectl delete pod liveness-http pod "liveness-http" deleted [root@master image]# kubectl delete pod myapp-pod pod "myapp-pod" deleted [root@master image]# kubectl delete pod nginx pod "nginx" deleted [root@master image]# kubectl delete pod redis pod "redis" deleted [root@master image]# kubectl get pod NAME READY STATUS RESTARTS AGE sc-nginx-deployment-66b6c48dd5-885zb 1/1 Running 0 6m56s sc-nginx-deployment-66b6c48dd5-bznvk 1/1 Running 0 6m56s [root@master image]# -
如果删除有点慢,直接强制删除
kubectl delete pod goproxy(pod名) --grace-period=0 --force