结论
计算的权重略有区别,个别可能比较大;计算的综合指标差异不大,但趋势一致。
反思:如果嫌麻烦,那就全扔进去。因为面板的个体差异和时间差异,如果很看重权重,那还是分开计算好。
最后,模拟数据,结论仅供参考
当你使用熵值法来测算面板数据的影响因素权重,你面临的主要决策之一是是否应该将数据按省份或年份分组来进行分析,或者是将所有数据作为一个整体来分析。这个决定取决于你的研究目标以及数据本身的性质。以下是一些指导原则和步骤,帮助你决定如何操作,并说明了如何计算权重。
决定是否分组
-
研究目标为整体趋势分析:如果你的目标是理解整体趋势,比如整个国家不同因素随时间的影响权重变化,那么可以将所有数据一起分析,不进行分组。这样可以得到一个全国范围内各影响因素的综合权重。
-
研究目标为区域或时间细分析:如果你关注的是不同省份之间或不同时间段内的差异,分组分析将更有意义。按省份分组可以帮助你理解不同地区之间的差异;按年份分组则可以揭示时间序列上的变化趋势。
模拟数据实验
不同方式计算的权重
import numpy as np
import pandas as pd# 步骤 1: 生成模拟数据
np.random.seed(0) # 确保生成的数据是可复现的
data = {'Province': np.repeat(['A', 'B', 'C'], 4), # 省份'Year': np.tile([2020, 2021, 2022, 2023], 3), # 年份'X1': np.random.rand(12), # 影响因素1'X2': np.random.rand(12), # 影响因素2'X3': np.random.rand(12) # 影响因素3
}
df = pd.DataFrame(data)# 计算熵值法权重的函数
def entropy_weight(data):# 数据标准化data_normalized = data / data.sum()# 计算熵值epsilon = 1e-12 # 避免对0取对数data_entropy = -np.sum(data_normalized * np.log(data_normalized + epsilon), axis=0) / np.log(len(data))# 计算权重weights = (1 - data_entropy) / (1 - data_entropy).sum()return weights# 步骤 2A: 不分组直接计算权重
weights_all = entropy_weight(df[['X1', 'X2', 'X3']])# 步骤 2B: 按省份分组计算权重
weights_by_province = df.groupby('Province')[['X1', 'X2', 'X3']].apply(entropy_weight)# 输出结果
print("全数据权重:\n", weights_all)
print("\n按省份分组计算的权重:\n", weights_by_province)
print("\n按省份分组计算的权重平均值:\n", weights_by_province.mean())
全数据权重:X1 0.084956
X2 0.477880
X3 0.437164
dtype: float64按省份分组计算的权重:X1 X2 X3
Province
A 0.008879 0.567479 0.423642
B 0.131374 0.677755 0.190871
C 0.173210 0.096664 0.730126按省份分组计算的权重平均值:X1 0.104487
X2 0.447300
X3 0.448213
dtype: float64
不同方式计算的综合指标
# 继续使用之前的df# 标准化函数
def normalize_data(data):return (data - data.min()) / (data.max() - data.min())# 应用标准化
df_normalized = df[['X1', 'X2', 'X3']].apply(normalize_data)# 使用全数据权重计算综合指标
composite_score_all = df_normalized.mul(weights_all, axis=1).sum(axis=1)# 将综合指标添加到df
df['Composite_Score_All'] = composite_score_all# 使用按省份分组的权重计算综合指标
# 注意,由于每个省份的权重可能不同,我们需要对每个省份单独计算
for province in df['Province'].unique():province_weights = weights_by_province.loc[province]province_data = df[df['Province'] == province][['X1', 'X2', 'X3']].apply(normalize_data)df.loc[df['Province'] == province, 'Composite_Score_By_Province'] = province_data.mul(province_weights, axis=1).sum(axis=1)# 查看结果
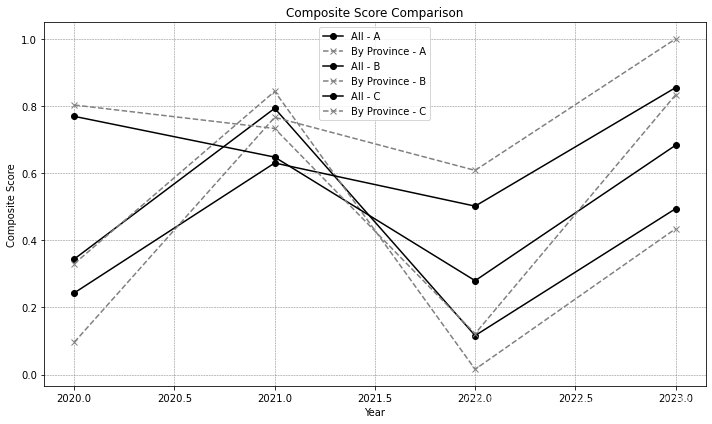
print(df[['Province', 'Year', 'Composite_Score_All', 'Composite_Score_By_Province']]) Province Year Composite_Score_All Composite_Score_By_Province
0 A 2020 0.344345 0.330248
1 A 2021 0.793291 0.843774
2 A 2022 0.116266 0.015874
3 A 2023 0.494165 0.434329
4 B 2020 0.243413 0.096354
5 B 2021 0.630426 0.766517
6 B 2022 0.501895 0.608406
7 B 2023 0.854848 1.000000
8 C 2020 0.769341 0.803114
9 C 2021 0.647918 0.733258
10 C 2022 0.279804 0.121882
11 C 2023 0.683157 0.833184
画图展示
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt# 生成模拟数据
np.random.seed(0) # 确保生成的数据是可复现的
data = {'Province': np.repeat(['A', 'B', 'C'], 4), # 省份'Year': np.tile([2020, 2021, 2022, 2023], 3), # 年份'X1': np.random.rand(12), # 影响因素1'X2': np.random.rand(12), # 影响因素2'X3': np.random.rand(12) # 影响因素3
}
df = pd.DataFrame(data)# 计算熵值法权重的函数
def entropy_weight(data):# 数据标准化data_normalized = data / data.sum()# 计算熵值epsilon = 1e-12 # 避免对0取对数data_entropy = -np.sum(data_normalized * np.log(data_normalized + epsilon), axis=0) / np.log(len(data))# 计算权重weights = (1 - data_entropy) / (1 - data_entropy).sum()return weights# 标准化函数
def normalize_data(data):return (data - data.min()) / (data.max() - data.min())# 计算权重
weights_all = entropy_weight(df[['X1', 'X2', 'X3']])
weights_by_province = df.groupby('Province')[['X1', 'X2', 'X3']].apply(entropy_weight)# 应用标准化
df_normalized = df[['X1', 'X2', 'X3']].apply(normalize_data)# 使用全数据权重计算综合指标
composite_score_all = df_normalized.mul(weights_all, axis=1).sum(axis=1)
df['Composite_Score_All'] = composite_score_all# 使用按省份分组的权重计算综合指标
for province in df['Province'].unique():province_weights = weights_by_province.loc[province]province_data = df[df['Province'] == province][['X1', 'X2', 'X3']].apply(normalize_data)df.loc[df['Province'] == province, 'Composite_Score_By_Province'] = province_data.mul(province_weights, axis=1).sum(axis=1)# 绘制图形
plt.figure(figsize=(10, 6))for province in df['Province'].unique():province_data = df[df['Province'] == province]plt.plot(province_data['Year'], province_data['Composite_Score_All'], label=f'All - {province}', linestyle='-', marker='o', color='black')plt.plot(province_data['Year'], province_data['Composite_Score_By_Province'], label=f'By Province - {province}', linestyle='--', marker='x', color='grey')plt.title('Composite Score Comparison')
plt.xlabel('Year')
plt.ylabel('Composite Score')
plt.legend()
plt.grid(True, which='both', linestyle='--', linewidth=0.5, color='grey')
plt.tight_layout()
plt.show()