3. 脉冲神经网络
好久之前第一次写的时候完全对第三题没感觉,提交上去得了个0 分…
这次自己再写了一遍,花的时间不多,写的时候感觉逻辑也不是特别难。最后是超时了,感觉第三题开始涉及到优化了,不仅仅是暴力模拟就可以拿分了,下面先贴上自己写的 66 分代码
#include<bits/stdc++.h>
using namespace std;
const int M = 100010;
//const int M = 100;
int N, S, P, T; //N个神经元, S个突触, P个脉冲源, T时刻
double deltaT; //间隔时间struct cell{double u, v;double a, b, c, d;
};
struct edge{int from;int to;double w;int D;
};
double r[2 * M]; //存放脉冲源的r信息
cell neuron[M]; //定义一个神经元数组
edge synapse[M]; //定义一个脉冲数组double timePulse[M][1010]; //在每个时刻,哪些神经元收到了多少信号
unordered_set<int> sendPulse; //记录当前时刻会发送脉冲的编号
int res[M];static unsigned long next_1 = 1;/* RAND_MAX assumed to be 32767 */
int myrand(void) {next_1 = next_1 * 1103515245 + 12345;return((unsigned)(next_1/65536) % 32768);
}int main()
{ios::sync_with_stdio(false);cin.tie(0);cin >> N >> S >> P >> T >> deltaT;int cnt = 0, Rn;while(cnt < N){double v, u, a, b, c, d;cin >> Rn >> v >> u >> a >> b >> c >> d;for(int i = cnt; i < cnt + Rn; i ++){neuron[i].a = a; neuron[i].b = b; neuron[i].c = c; neuron[i].d = d;neuron[i].v = v; neuron[i].u = u;}cnt += Rn;}for(int i = 0;i < P; i ++){ //输入脉冲源信息cin >> r[i + N];}for(int i = 0;i < S; i ++){ //输入突触信息cin >> synapse[i].from >> synapse[i].to >>synapse[i].w >> synapse[i].D;}double MAXV = -1 * 0x3f3f3f3f, MINV = 0x3f3f3f3f;for(int t = 1;t <= T; t ++){sendPulse.clear();for(int i = 0;i < P; i ++){int rand = myrand();//cout << rand << "\n";if(r[i + N] > rand){ //该脉冲源在该时刻将发送脉冲sendPulse.insert(i + N);}}for(int i = 0;i < N;i ++){double Ik = timePulse[t][i];double cur_v = neuron[i].v;double cur_u = neuron[i].u;double a = neuron[i].a, b = neuron[i].b, c = neuron[i].c, d = neuron[i].d;double v, u;v = cur_v + deltaT * (0.04*cur_v*cur_v+5*cur_v+140-cur_u) + Ik;u = cur_u + deltaT * a * (b * cur_v - cur_u);if(v >= 30){sendPulse.insert(i);res[i] ++;v = c;u += d;}if(t == T){MAXV = max(v, MAXV);MINV = min(v, MINV);}//cout << v <<"\n";neuron[i].v = v; neuron[i].u = u;}for(int i = 0;i < S; i ++){int from = synapse[i].from, to = synapse[i].to, D = synapse[i].D;double w = synapse[i].w;if(sendPulse.count(from)){ //输入端接收到脉冲timePulse[t + D][to] += w;}}}int MAXS = 0, MINS = 0x3f3f3f3f;for(int i = 0;i < N;i ++){if(res[i] > MAXS) MAXS = res[i];if(res[i] < MINS) MINS = res[i];}cout << fixed << setprecision(3) << MINV << " " << MAXV << "\n" << MINS << " " << MAXS;return 0;
}
感觉本题很多人都卡了66分,代码逻辑上基本相同,满分代码和66分代码的优化主要在以下两点
- 时间优化(针对卡常):在时间的循环中,对各个脉冲源和神经元的循环是不可省略的,这里涉及到计算。因此进行的优化就是更改突触的存储结构,采用邻接表的形式进行存储,此时若计算出当前节点将发出脉冲后,所有与该节点有突触连接的出节点立马进行更新。此时会减少一次10^3的遍历时间。
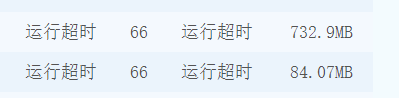
- 空间优化:在进行时间优化后,会发现仍然超时,且出现空间过大的情况,如下图所示。所以在这里将进行空间的优化,主要是针对于
timePluse[][]这个存储数组的优化)
用邻接表来存储突触边:采用数组的方式来模拟邻接表的存储
可参考我之前写的一个链接:图论堆优化
邻接表声明:
int h[N], e[M], w[M], ne[M], idx; //N为节点个数,M为边的个数
其中
h[a] 指向a节点起点的邻接表列表的最后一个元素
e[idx] 为当前idx编号的边指向的节点
w[idx] 为当前idx编号的边的权重
ne 存储邻接表链表,当前值对于邻接表下一个的地址,类似于值为指针初始化
idx = 0;
memset(h, -1, sizeof h);邻接表构建
void add(int a, int b, int c) {e[idx] = b;w[idx] = c; //以上的两步构建了一条边,这条边只存储了终点和权值(因为邻接表的表头就是起点,所以不存储无用信息)ne[idx] = h[a]; //类似于头插法 node->next = L->next(当前节点的next指针指向头节点的下一个节点)h[a] = idx ++; //L->next = node; idx++ 将当前的头节点的next节点设置为当前节点}1. 在这种构建方式中, idx为边的序号,作为边的唯一标识,找到了idx就可以读到该条边的终点信息和权值信息
2. 邻接表的构造方式和头插法类似,h[a]指向最新录入的以a节点为起点的边的信息,其存储的值是一个边的idx,通过ne[idx]可以获得当前边的下一条的边的idx值;ne[idx] == -1 与 node->next == NULL类似,此时遍历到了该链表的尾部节点
3. 如果指向下一个为空时,指针值为-1
邻接表遍历
for(int i = h[vel]; i != -1; i = ne[i]) { //TODO
}i = ne[i] 模拟链表指针的next操作
h[vel] 指向vel链表的最后一个,遍历是从后往前的
此时可以创建一个用来存储突触信息的邻接表,其中以h[idx]来获取与编号为idx的脉冲源或者神经元 相连接的神经元编号,以idx = ne[idx]来模拟指针的移动获取更多的出结点神经元编号。当idx == -1时,也就是相当于表中指针next == nullptr,也即已经移动到尾部,此时即可退出循环
在代码中,每当r[i + N] > rand或者v >= 30,也即当前脉冲源或者神经元将发出脉冲。以i + N / i为idx开始遍历邻接表,找到所有与之链接的节点timePluse[当前时间+延迟时间][出结点编号] += 输出脉冲值
引入mod来减少timePluse[][]的存储空间
在66分代码中,timePluse[][]的规模是1e5 x 1e3(T的规模 * 神经元的规模)此时会导致空间内存不足。在参考满分代码中,引入了滚动数组的概念
在本题的滚动数组我的理解是:为了减少规模,我们需要将T的时间进行分组,用分组规模来替换T的规模。同时要保证这个分组规模足够满足神经元和脉冲源 在当前时刻的 读取以及存储要求。比较像背包问题里面的设计,只保存在当前任务下,我会用到的信息量(以这个信息量的跨度为划分依据,比如背包问题就只保留了上一层的信息)
这里的mod = max(D[i]),也即mod取值为所有突触的最大时间间隔加一
在这个划分下,
原本存储时我的第一维度为当前时间加上该突触的时间间隔,此时修改为(k + D[i]) % mod. 其中k = t % mod (k >= 1 and k <= mod). 则修改后的时间会落入到划分长度为mod的时间段中的 k 的后方(此时和当前时刻划分在同一个时间段),或者k的前方(此时为当前时刻划分段的下一个时间段)==>但没关系!!因为当 当前时刻已经到 k 时,小于 k 的部分的数据已经读取并利用在神经元的计算中了,因此虽然在一个数组中以 k 为分界线并不在一个时间段内(就理解为不在一个维度里面吧)但是在使用中并不会有混淆,因为前一部分数据在本时段内也不会再次使用了
其实也即,以当前时刻k为划分,后半部分数据用于读取(直接读取 || 存储后!当前时刻扫描到时,又再次读取); 而前半部分只可能用于存储(用于后一时间段的读取)
下为满分代码:
#include<iostream>
#include<iomanip>
#include<algorithm>
#include<cstring>
using namespace std;
const int M = 2010;
int N, S, P, T; //N个神经元, S个突触, P个脉冲源, T时刻
double deltaT; //间隔时间struct cell{double u, v;double a, b, c, d;
};
double r[M]; //存放脉冲源的信息
cell neuron[M / 2]; //存放神经元的信息
double timePulse[1024][M / 2]; //在每个时刻,哪些神经元收到了多少信号
int res[M / 2];//用邻接表的形式存储脉冲信息
double w[M / 2];
int h[M], e[M / 2], D[M / 2], ne[M / 2], idx = 0;
static unsigned long next_1 = 1;/* RAND_MAX assumed to be 32767 */
int myrand(void) {next_1 = next_1 * 1103515245 + 12345;return((unsigned)(next_1/65536) % 32768);
}void add(int from, int to, double ww, int dt)
{w[idx] = ww;e[idx] = to;D[idx] = dt;ne[idx] = h[from];h[from] = idx;idx ++;
}
int main()
{ios::sync_with_stdio(false);cin.tie(0);memset(h, -1, sizeof h);cin >> N >> S >> P >> T >> deltaT;int cnt = 0, Rn;while(cnt < N){double v, u, a, b, c, d;cin >> Rn >> v >> u >> a >> b >> c >> d;for(int i = cnt; i < cnt + Rn; i ++){neuron[i].a = a; neuron[i].b = b; neuron[i].c = c; neuron[i].d = d;neuron[i].v = v; neuron[i].u = u;}cnt += Rn;}for(int i = 0;i < P; i ++){ //输入脉冲源信息cin >> r[i + N];}int mod = 0;for(int i = 0;i < S; i ++){ //输入突触信息int from, to, dt;double ww;cin >> from >> to >> ww >> dt;add(from, to, ww, dt);mod = max(mod, dt + 1);}double MAXV = -1 * 0x3f3f3f3f, MINV = 0x3f3f3f3f;for(int k = 1;k <= T; k ++){int t = k % mod;for(int i = 0;i < P; i ++){int rand = myrand();//cout << rand << "\n";if(r[i + N] > rand){ //该脉冲源在该时刻将发送脉冲for(int j = h[i + N];j != -1; j = ne[j]){int to = e[j];timePulse[(t + D[j]) % mod][to] += w[j];}}}for(int i = 0;i < N;i ++){double Ik = timePulse[t][i];double cur_v = neuron[i].v;double cur_u = neuron[i].u;double a = neuron[i].a, b = neuron[i].b, c = neuron[i].c, d = neuron[i].d;double v, u;v = cur_v + deltaT * (0.04*cur_v*cur_v + 5*cur_v + 140 - cur_u) + Ik;u = cur_u + deltaT * a * (b * cur_v - cur_u);if(v >= 30){for(int j = h[i];j != -1; j = ne[j]){int to = e[j];timePulse[(t + D[j]) % mod][to] += w[j];}res[i] ++;v = c;u += d;}if(k == T){MAXV = max(v, MAXV);MINV = min(v, MINV);}//cout << v <<"\n";neuron[i].v = v; neuron[i].u = u;}memset(timePulse[t], 0, sizeof timePulse[t]);}int MAXS = 0, MINS = 0x3f3f3f3f;for(int i = 0;i < N;i ++){if(res[i] > MAXS) MAXS = res[i];if(res[i] < MINS) MINS = res[i];}cout << fixed << setprecision(3) << MINV << " " << MAXV << "\n" << MINS << " " << MAXS;return 0;
}
这里还有一个点,时间卡的实在是太严了,所以在这里用万能头文件反而会加重编译过程中的耗时。所以修改了头文件部分
over!! 难,实在是难(苦涩.jpg)