1. 介绍
在之前的文章中,介绍了如何使用 YOLOv8 在不同的编程语言来检测图片中的对象。然而,YOLOv8 还可以把检测到的目标图像分割出来,本篇文章将介绍如何使用YOLOv8做图片分割。
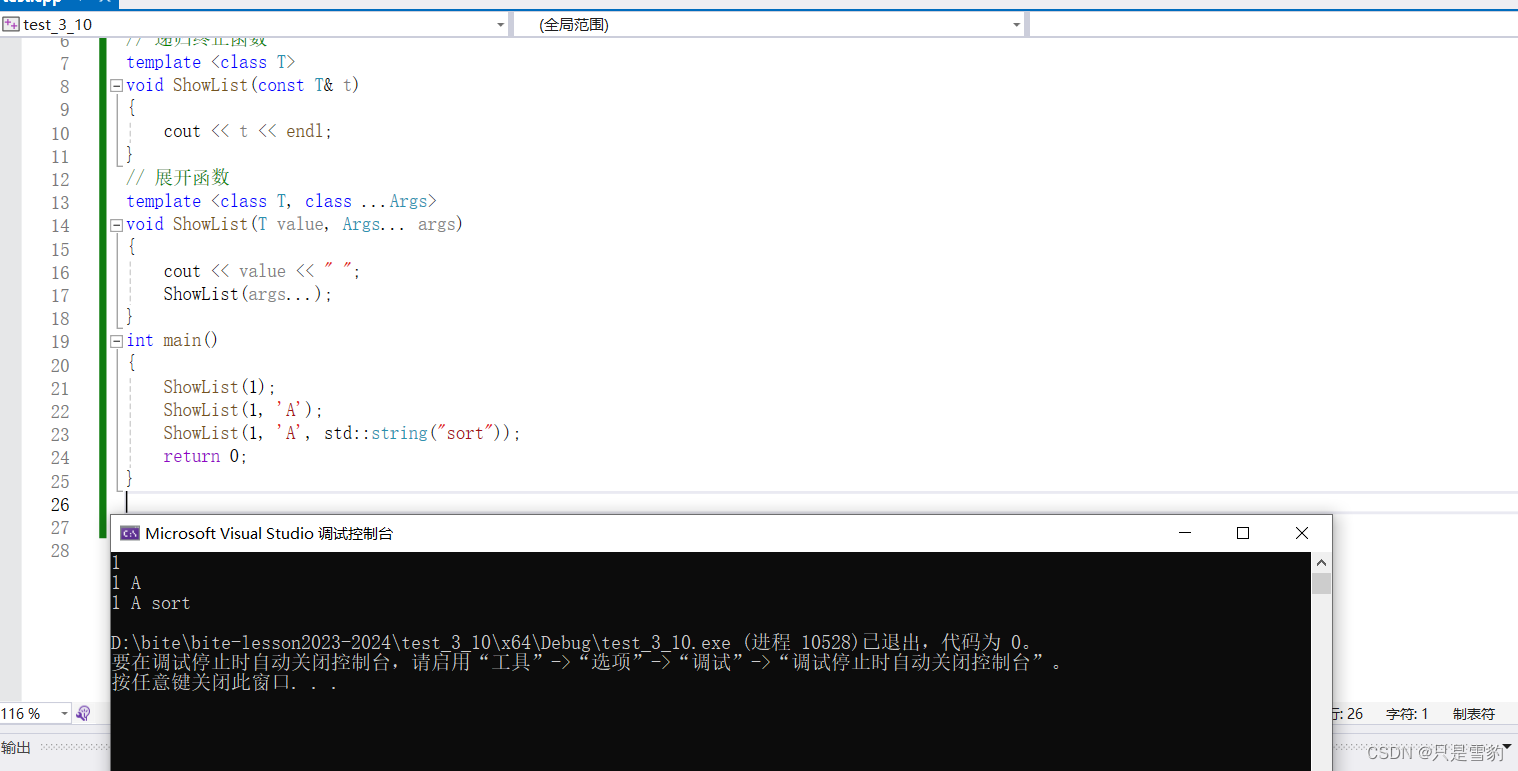
对象检测的结果是所有检测到的对象的边界框。图像分割的结果是所有检测到的对象的蒙版。它是一个黑白图像,其中属于该对象的所有像素都是白色,所有其他像素都是黑色,如下图所示:

得到此蒙版(实际上是一个 2D 数组,其中背景像素值为 0,对象像素值为 255)后,可以将其应用于原始图像,仅绘制在蒙版上显示为白色的像素区域。
例如,可以通过这种方式从图像中删除背景:

并设置新背景:
同样,可以对视频中的每个帧运行实例分割,并从整个视频中删除背景。
此外,有了检测到的对象的这些蒙版,可以计算它们的轮廓。

计算出的轮廓是一个多边形,它是点坐标的数组。该多边形可用于识别现实世界应用中图像上检测到的对象,比仅使用边界框要更精确。
在本文中,我将分享如何使用YOLOv8实现图像分割。分为3个部分:
- 首先,我们将使用默认的 Ultralytics API,其中大部分内部工作都高度封装,在这一步我们将使用 YOLOv8 官方的预训练模型,该模型可从COCO 数据集中检测 80 个对象类。
- 然后介绍如何训练自己的分割模型。
- 最后,我们将替换掉Ultralytics的库,用更底层的方式来处理图像分割的输入和输出。
2. YOLOv8 图像分割入门
在接下来的部分中,所有代码示例和输出都在 Jupyter Notebook 中运行。
运行以下命令安装 Ultralytics 库:
!pip install ultralytics
导入YOLO包:
from ultralytics import YOLO
然后,加载YOLOv8官方的分割模型
model = YOLO("yolov8m-seg.pt")
下午中将使用以下图片作为示例,图片名为cat_dog.jpg:

运行模型并获取图像分割的结果:
results = model.predict("cat_dog.jpg")
分割模型的predict方法与目标检测模型的方法相同,它返回在每个图像的结果数组。可以这样获取结果:
result = results[0]
分割模型还进行对象检测,返回的结果与我们在本系列文章之前介绍的结果内容几乎相同。
同时,它还有一个属性,即检测到的对象掩码的数组,这些掩码被称为mask。
让我们看看检测到了多少个掩码:
masks = result.masks
len(masks)
结果显示为:
2
表示分割了 2 个对象:狗和猫。
现在看看第一个掩码:
mask1 = masks[0]
每个掩码都是一个具有一组属性的对象,我们将使用其中两个属性:
- data物体的分割掩码,它是一个黑白图像矩阵,其中0个元素是黑色像素,1个元素是白色像素。
- xy对象的轮廓多边形,它是点的数组。
该data属性是一个 PyTorch 的张量数组,但是利用 NumPy 数组处理它会更方便点。让我们提取掩码和轮廓多边形:
mask = mask1.data[0].numpy()
polygon = mask1.xy[0]
现在来看看这个mask到底是什么,我们使用Pillow Image 处理它。
安装Pillow:
!pip install pillow
从mask创建图像:
from PIL import Imagemask_img = Image.fromarray(mask,"I")
mask_img
显示以下图像:

这就是原始图片中狗的蒙版。
现在,让我们使用polygon对象,查看轮廓点数组:
polygon
array([[ 280.18, 96.575],[ 275.4, 101.36],[ 275.4, 102.31],[ 274.44, 103.27],[ 274.44, 105.18],[ 273.49, 106.14],[ 273.49, 107.09],[ 272.53, 108.05],[ 272.53, 111.87],[ 271.57, 112.83],[ 271.57, 117.61],[ 272.53, 118.57],[ 272.53, 152.04]
...[ 302.17, 112.83],[ 302.17, 110.92],[ 301.22, 109.96],[ 301.22, 108.05],[ 298.35, 105.18],[ 298.35, 104.22],[ 297.39, 103.27],[ 297.39, 102.31],[ 292.61, 97.531],[ 291.66, 97.531],[ 290.7, 96.575]], dtype=float32)
显示了每一个点的坐标[x,y]。该坐标可以直接参与其他需求的计算,比如,可以将其绘制在原始图像上:
from PIL import ImageDrawimg = Image.open("cat_dog.jpg")
draw = ImageDraw.Draw(img)
draw.polygon(polygon,outline=(0,255,0), width=5)img
此代码加载原始图片,并在其上绘制轮廓polygon。参数outline指定轮廓线条颜色为绿色并设置宽度是5。最后,看到带有狗轮廓的图像:

现在,我们对第二个掩码执行相同的操作:
mask2 = masks[1]
mask = mask2.data[0].numpy()
polygon = mask2.xy[0]
mask_img = Image.fromarray(mask,"I")mask_img

draw.polygon(polygon,outline=(0,255,0), width=5)
img

到目前为止,我们使用YOLOv8官方的分割模型,但在实践中,可能需要针对具体的问题分割特定的对象。例如,可能需要检测超市货架上的特定产品或通过 X 射线发现脑肿瘤。这些信息在官方的分割模型中并没有训练过。因此,我们需要训练自己的分割模型,创建我们自己的训练数据。
3. 创建自己的训练数据
要训练模型,您需要准备带标注的图片,并将其拆分为训练和验证数据集。训练集将用于训练模型,验证集将用于测试训练的结果,以衡量训练模型的质量。可以将 80% 的图片放入训练集,将 20% 放入验证集。
3.1 创建数据集的步骤
- 编码要分割的对象类别。例如,如果您只想检测猫和狗,则可以指定“0”是猫,“1”是狗。
- 为数据集创建一个文件夹,并在其中创建两个子文件夹:“images”和“labels”。
- 将图片放入“images”子文件夹中。图片越多,训练就越好。
- 对于每个图片,在“labels”子文件夹中创建一个标注文本文件。标注文本文件应具有与图片文件相同的名称,并使用“.txt”作为扩展名。在标注文件中,该添加每个对象的记录,格式如下:
{object_class_id} {polygon}
其中
- object_class_id是对象类别的标签,例如,如果是猫,则为 0;如果是狗,则为 1。
- polygon是该对象的边界多边形坐标,格式如下:x1 y1 x2 y2 …
实际上,这是机器学习过程中最耗时的手动工作:测量所有对象的边界多边形坐标并将其添加到标注文件中。
此外,坐标应归一化以适应从 0 到 1 的范围。使用以下方法:
x = x/图像宽度
y = y/图像高度
比如,如果有一个坐标为 (100,100) 的点,并且图像大小为 (612,415),其x和y分别是:
x = 100/612 = 0.163666121
y = 100/415 = 0.240963855
我们要为每个图片上的所有对象设置多边形。例如,如果您有一个具有以下猫和狗多边形的图像:

那么你需要为其创建以下标注文件:
1 0.45781 0.23271 0.45 0.24423 0.45 0.24654 0.44844 0.24884 0.44844 0.25345 0.44687 0.25575 0.44687 0.25806 0.44531 0.26036 0.44531 0.26958 0.44375 0.27188 0.44375 0.2834 0.44531 0.28571 0.44531 0.36636 0.44375 0.36866 0.44375 0.38018 0.44219 0.38248 0.44219 0.3894 0.44062 0.3917 0.44062 0.42857 0.43906 0.43087 0.43906 0.45622 0.44062 0.45852 0.44062 0.48157 0.43906 0.48387 0.43906 0.49309 0.4375 0.49539 0.4375 0.50461 0.43594 0.50691 0.43594 0.51843 0.43437 0.52074 0.43437 0.52765 0.43281 0.52995 0.43281 0.54148 0.43125 0.54378 0.43125 0.58295 0.43281 0.58526 0.43281 0.58986 0.43437 0.59217 0.43437 0.59447 0.4375 0.59908 0.4375 0.60139 0.44219 0.6083 0.44219 0.6106 0.44375 0.61291 0.44375 0.61521 0.44531 0.61752 0.44531 0.61982 0.45156 0.62904 0.45156 0.63134 0.46875 0.65669 0.47031 0.65669 0.47344 0.6613 0.47344 0.6636 0.475 0.6659 0.475 0.67512 0.47344 0.67742 0.47344 0.69816 0.475 0.70047 0.475 0.71199 0.47656 0.71429 0.47656 0.7166 0.48437 0.72812 0.4875 0.72812 0.48906 0.72581 0.49062 0.72581 0.49375 0.7212 0.49375 0.7166 0.49844 0.70968 0.49844 0.70738 0.50156 0.70277 0.50312 0.70277 0.50469 0.70047 0.50937 0.70047 0.51406 0.70738 0.51406 0.70968 0.51562 0.71199 0.51562 0.71429 0.51719 0.7166 0.51562 0.7189 0.51562 0.72351 0.51719 0.72581 0.51875 0.72581 0.52031 0.72812 0.52969 0.72812 0.53281 0.72351 0.54531 0.72351 0.54687 0.72581 0.55156 0. 72581 0.55625 0.73273 0.55781 0.73273 0.55937 0.73503 0.56094 0.73273 0.56875 0.73273 0.57031 0.73503 0.575 0.73503 0.57656 0.73273 0.57812 0.73503 0.58281 0.73503 0.58437 0.73733 0.59375 0.73733 0.59531 0.73964 0.6 0.73964