通过量化可以减少大型语言模型的大小,但是量化是不准确的,因为它在过程中丢失了信息。通常较大的llm可以在精度损失很小的情况下量化到较低的精度,而较小的llm则很难精确量化。
什么时候使用一个小的LLM比量化一个大的LLM更好?
在本文中,我们将通过使用GPTQ对Mistral 7B、Llama 27b和Llama 13B进行8位、4位、3位和2位量化实验来回答这个问题。我们将使用optimum-benchmark比较它们的内存消耗,并使用LLM Evaluation Harness比较它们的准确性。
在最后我们还要介绍一个大模型的最新研究1.58 Bits,它只用 -1,0,1来保存权重,这样就不会再有浮点数,虽然不是量化的方法,但是这样保存模型的权重应该是模型极限了。
llm的核心是深度学习模型,本质上是深度神经网络。这些网络由多层神经元组成,深度堆叠在一起处理和解释大量数据。
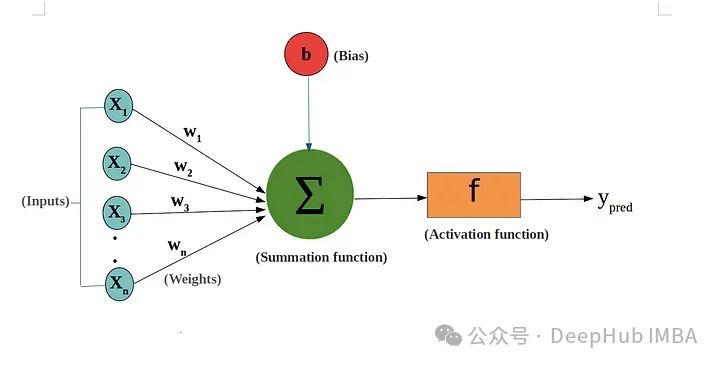
这些网络的运作取决于一种叫做“权重”的东西。这些权重在训练过程中进行训练,以类似于矩阵乘法的方式进行相乘。
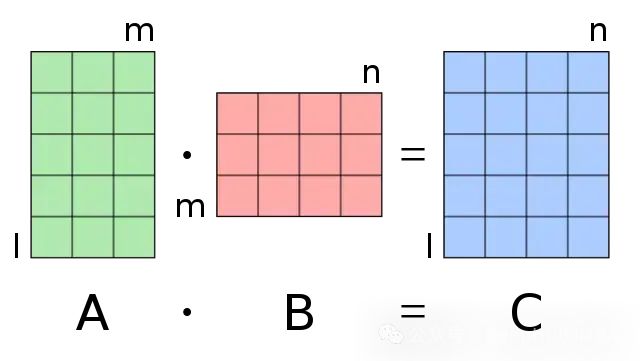
这个过程需要大量的计算资源,通常需要使用gpu,特别是那些配备了CUDA技术的Nvidia产品来处理密集的高性能矩阵乘法。
传统llm主要构建为32位或16位模型。这意味着模型中的每个参数都由32位或16位浮点数表示。浮点数本质上是小数点值,不同于表示整数的整数。位深度(32位或16位)表示这些浮点数的精度级别。但是这种高精确度是有代价的:它需要大量的计算能力和内存,使llm资源密集且不易访问。
为了进一步减少模型的存储需求和计算复杂度。量化意味着将参数表示为比32位或16位更少位的整数或小数。通过这种方式,可以在几乎不损失精度的情况下显著减少模型的大小,从而使得在嵌入式设备或边缘设备上部署深度学习模型变得更加可行。同时量化还可以提高模型的计算效率,因为在大多数硬件上,对整数操作的支持要优于浮点数操作。
下面我们先对比下目前经常用到的一些量化方法
目前量化方法的测试
我们这里使用GPTQ是因为AWQ虽然更准确能够产生更快的推理模型。但是它最低只能支持到只4位量化。
而AutoGPTQ支持使用GPTQ进行2、3、4和8位量化,为了对比测试,所以我们选择了GPTQ来进行这个测试,下面是量化的代码:
fromtransformersimportAutoModelForCausalLM, AutoTokenizerfromoptimum.gptqimportGPTQQuantizerimporttorchmodel_path='meta-llama/Llama-2-7b-hf'forwin [2,3,4,8]:quant_path='Llama-2-7b-hf-gptq-'+str(w)+'bit'# Load model and tokenizertokenizer=AutoTokenizer.from_pretrained(model_path, use_fast=True)model=AutoModelForCausalLM.from_pretrained(model_path, torch_dtype=torch.float16)quantizer=GPTQQuantizer(bits=w, dataset="c4", model_seqlen=4096)quantized_model=quantizer.quantize_model(model, tokenizer)
这段代码将创建Llama 27b的2、3、4和8位GPTQ版本。
基准内存效率和准确性
对于量化来说我们主要想知道2个结果:
1、节省了多少内存;2、在下游任务中损失了多少准确性
为了回答第一个问题,我将使用Optimum-benchmark,我将使用它来测量量化模型的峰值内存消耗。
为了回答第二个问题,我将使用 Evaluation Harness,因为Evaluation Harness可以运行许多基准来评估llm在下游任务中的能力。它特别推动了Open LLM排行榜,所以说对于指标测试来说他还是非常有权威性的。
使用Optimum-benchmark进行基准测试,使用的是这个配置文件。
defaults:- backend: pytorch # default backend- benchmark: inference # we will monitor the inference- launcher: process- experiment # inheriting from experiment config- _self_ # for hydra 1.1 compatibility- override hydra/job_logging: colorlog # colorful logging- override hydra/hydra_logging: colorlog # colorful logginghydra:run:dir: experiments_ob/${experiment_name} #The results will be reported in this directory. Note that "experiment_name" refers to the configuration field name "experiment_name" belowsweep:dir: experiments_ob/${experiment_name}job:chdir: trueenv_set: #These are environment variable that you may want to set before running the benchmarkCUDA_VISIBLE_DEVICES: 0CUDA_DEVICE_ORDER: PCI_BUS_IDexperiment_name: Llama-2-13b-hf-16bitmodel: meta-llama/Llama-2-13b-hf #The model that we want to evaluate. It can be from the Hugging Face Hub or local directorydevice: cuda #Which device to use for the benchmark. We will use CUDA, i.e., the GPUbackend:torch_dtype: float16benchmark:memory: true #We will monitor the memory usagewarmup_runs: 10 #Before the monitoring starts, the inference will be run 10 times for warming upnew_tokens: 1000 #Inference will generate 1000 tokensinput_shapes:sequence_length: 512 #Prompt will have 512 tokensbatch_size: 2
而运行Evaluation Harness,则只要运行下面的命令:
lm_eval --model hf --model_args pretrained=meta-llama/Llama-2-13b-hf --tasks winogrande,hellaswag,arc_challenge --device cuda:0 --num_fewshot 5 --batch_size 2 --output_path ./eval_harness/Llama-2-13b-hf-16b
让我们来看看峰值内存使用情况,即模型在GPU上运行所需的最大内存,对于Llama 27b, 13B和Mistral 7B,使用2,3,4,8和16位精度。

精度降低1倍但是内存峰值消耗并不会降低1倍。这是因为并不是所有的参数都是量化的,而且内存也会被推理批数据消耗(不仅仅是加载模型)。例如,对于Llama 27b, 16位消耗15.5 GB, 8位消耗9.0 GB, 4位消耗5.9 GB。Mistral 7B在8位(9.5 GB)和16位(16.5 GB)精度上比Llama 27b稍微消耗更多的VRAM。
对于下游任务上的准确性,我选择了3个任务:
- Winogrande:评估常识性推理的基准。
- Arc挑战:一组小学科学问题。
- HellaSwag:评估常识性推理的基准。
这三个基准也被Open LLM排行榜使用。
结果如下:
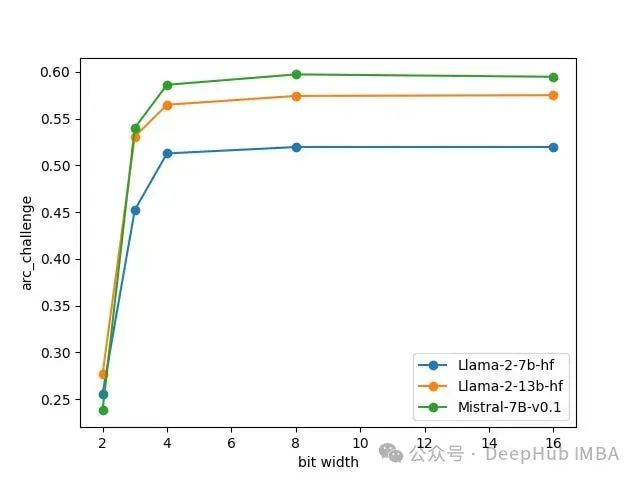
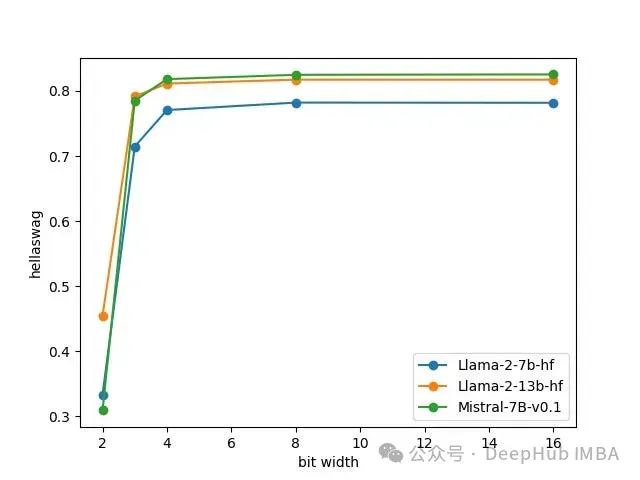
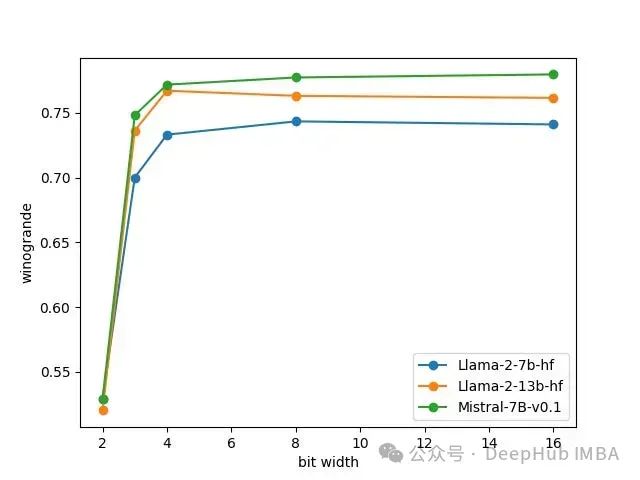
对于这三种模型,从16位到8位,这些任务的准确率没有下降,从8位到4位,准确率也是只有略有下降。它很好地说明了今天的4位量化算法还是非常给力的。并且这里我们用的是GPTQ,AWQ会产生更接近8位量化的结果。
选择4而不选择3位量化是非常好i的选择,因为峰值内存消耗只减少了一点点,但是准确性就显著降低了。对于2位量化,模型基本已经不能用了。
可以说目前来说量化的极限是4bit,因为使用4bit准确性不会有太多的损失。但是4bit并不是模型的极限,这就引出了我们要介绍的这篇新的论文
The Era of 1-bit LLMs:All Large Language Models are in 1.58 Bits
这是一项非常令人兴奋的技术。这种由微软开发的创新方法有望显著改变处理大型语言模型(llm)的计算效率和能耗。与将每个参数表示为32位或16位浮点数不同,1-bit 将llm的权重表示为三元值:-1、0或+1。
论文里面最主要内容是1-bit 的llm的性能与传统llm相当。这意味着我们可以用更少的资源支出达到相似的效率和准确性水平。
论文通过将0与+1和-1一起作为潜在值,我们从纯二进制表示(论文:1-bit LLMs)转换为三元表示。这种从1bit到1.58bit的转变不仅仅是数值上的调整;它给模型的学习能力带来了根本性的改变。
数学解释

在传统的深度学习神经网络中,计算的关键在于矩阵乘法,通常表示为点积。这涉及到将模型的权重(W)与输入(X)相乘和相加,按照方程Y = f(W, X)。这个过程虽然有效,但计算量很大,并且构成了传统llm中GPU依赖的支柱。
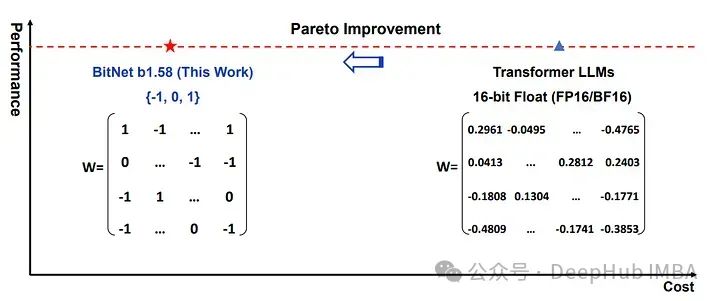
三元值(+1,-1,0)的引入从根本上改变了这个方式。使用这些整数表示,模型可以显著减少,或者在某些情况下完全消除对乘法的需要,主要依赖于加法。这种简化不仅仅是计算上的方便;它代表了LLM结构和执行方式的范式转变。
另外就是包含零作为值允许参数的更细微的表示,导致潜在的更有效的学习过程。这种效率并不是以性能为代价的;这些1.58位模型的性能可以与更高位的模型相媲美。
我们来看看性能、延迟和能效测试
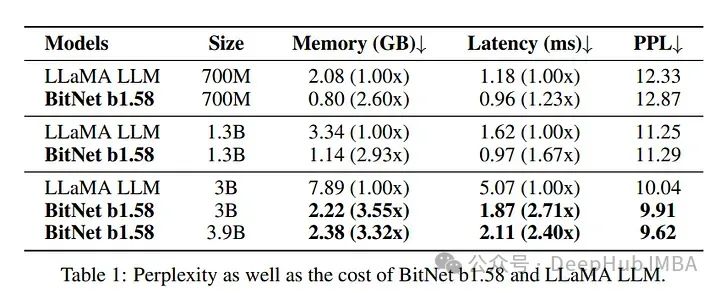
研究人员将1.58位模型与基于llama架构的LLM进行了比较。为了确保公平性,他们在类似于Llama数据集的数据集上从头开始训练模型。在分析1.58位llm的性能时,不仅在生成连贯的文本(以困惑度来衡量)方面,而且在执行诸如问答之类的下游任务方面,1.58位模型不仅匹配甚至超过了等效Llama模型的性能。
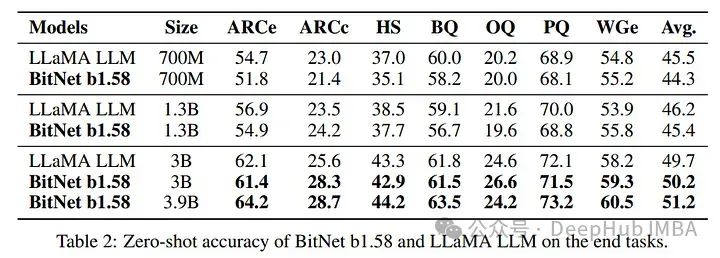
还使用ARCe、HS等指标在各种下游任务(如问答和文本摘要)上进行了测试。1.58位模型在这些方面也表现出优异的性能。
bitnet模型架构
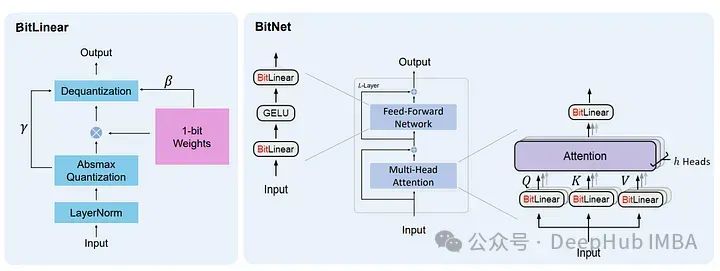
Llama和1.58位模型都是基于Transformer架构的。关键的区别在于权重内的数字表示和计算方法。1.58位模型使用所谓的“位线性”来代替传统的矩阵乘法大大简化了计算过程。
延迟和吞吐量的改进

1.58位模型最显著的优点之一是延迟和吞吐量的改进。延迟提高了2.7到2.4倍,吞吐量提高了惊人的9倍,能够为700亿个参数模型每秒生成2,977个令牌。这一性能明显高于目前的行业标准,包括Groq设定的标准。
总结
模型量化是深度学习领域一个重要的研究方向,它不仅可以帮助减小模型的存储和计算开销,还可以使得深度学习模型更容易在资源有限的设备上部署,推动了深度学习技术在边缘计算和物联网等领域的应用。但是目前4位的量化是目前研究的极限了,如果再缩小精度,会导致准确率大幅降低。
但是1.58位llm的出现标志着人工智能技术发展又出现了一个新的方向。这些模型具有令人印象深刻的性能指标、更低的硬件要求,虽然这种方法还无法应用到现有的模型上,我想以后如果有什么方法能将其应用到现有的模型上那么对于人工智能来说将是一个巨大的飞跃。
以下是2篇微软的论文:
https://avoid.overfit.cn/post/9a067e1d895240e9a82827edab45549f