-
ELFK的组成:
-
- Elasticsearch: 它是一个分布式的搜索和分析引擎,它可以用来存储和索引大量的日志数据,并提供强大的搜索和分析功能。 (java语言开发,)
- logstash: 是一个用于日志收集,处理和传输的工具,它可以从各种数据源收集日志数据,对数据进行处理和过滤,将数据发送到Elasticsearch。 java
- kibana: 是一个用于数据可视化和分析的工具,它可以与Elasticsearch集成,帮助用户通过图表、仪表盘等方式直观地展示和分析日志数据。 java
- filebeat: 轻量级日志收集工具,一般安装在客户端服务器上负责收集日志,传输到ES或logstash go
-
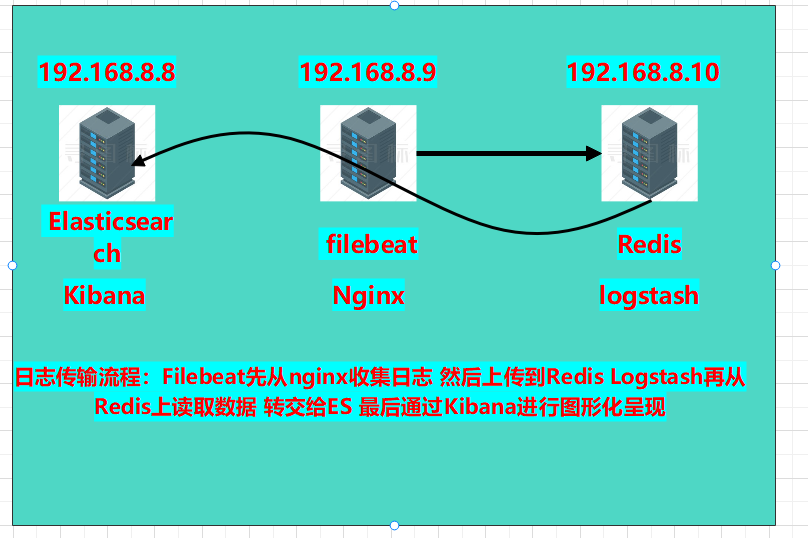
本章实验环境拓扑图:
-
- 版本介绍:
- Elasticsearch:6.6.0
- kibana:6.6.0
- filebeat:6.6.0
- nginx:1.18.0
- Redis:5.0.7
- logstash:6.6.0
- 开始部署:
- 部署8.8服务器的es和Kibna:a
- 复制软件包至服务器下安装:
- rpm -ivh elasticsearch-6.6.0.rpm
- 修改配置文件:
- vim /etc/elasticsearch/elasticsearch.yml
-
node.name: es1 path.data: /data/elasticsearch path.logs: /var/log/elasticsearch bootstrap.memory_lock: true network.host: 192.168.8.8,127.0.0.1 http.port: 9200
-
- vim /etc/elasticsearch/elasticsearch.yml
- 创建数据目录,并修改权限
-
mkdir -p /data/elasticsearch chown -R elasticsearch.elasticsearch /data/elasticsearch/
-
- 启动es:systemctl start elasticsearch
- 部署安装kibana:
- 安装kibana:rpm -ivh kibana-6.6.0-x86_64.rpm
- 修改配置文件:
- 修改项:
-
server.port: 5601 server.host: "192.168.8.8" server.name: "db01" #自己所在主机的主机名 elasticsearch.hosts: ["http://192.168.8.8:9200"] #es服务器的ip,便于接收日志数据 保存退出
-
- 修改项:
- 启动kibana:systemctl start kibana
- 查看两个服务的端口是否存在:
- netstat -anpt | grep 5601
- netstat -anpt | grep 9200
- 复制软件包至服务器下安装:
- 部署8.9服务器山的nginx和filebeat:
- 安装filebeat:
- rpm -ivh filebeat-6.6.0-x86_64.rpm
- 修改配置文件:
- vim /etc/filebeat/filebeat.yml (清空源内容,直接覆盖)
-
filebeat.inputs: (日志来源) - type: log (日志格式)enabled: true (开机自启)paths: (日志路径)- /var/log/nginx/access.logoutput.elasticsearch: (日志传送到那)hosts: ["192.168.8.8:9200"]
-
-
启动filebeat服务:
-
systemctl start filebeat
-
- vim /etc/filebeat/filebeat.yml (清空源内容,直接覆盖)
-
安装nginx:
-
yum -y install nginx
-
启动nginx:nginx
-
- 安装filebeat:
-
在8.8服务器上安装网站压力测试工具:
-
yum -y install httpd-tools
-
-
2.使用ab压力测试工具测试访问
-
ab -c 1000 -n 20000 http://192.168.8.9/
-c(并发数) -n(请求数)
-
- 部署8.8服务器的es和Kibna:a
-
使用浏览器扩展程序登录es查看索引是否有访问数:
-
-
修改nginx的日志格式为json格式:
-
vim /etc/nginx/nginx.conf
-
添加在http{}内:
-
log_format log_json '{ "@timestamp": "$time_local", ' '"remote_addr": "$remote_addr", ' '"referer": "$http_referer", ' '"request": "$request", ' '"status": $status, ' '"bytes": $body_bytes_sent, ' '"agent": "$http_user_agent", ' '"x_forwarded": "$http_x_forwarded_for", ' '"up_addr": "$upstream_addr",' '"up_host": "$upstream_http_host",' '"up_resp_time": "$upstream_response_time",' '"request_time": "$request_time"' ' }';access_log /var/log/nginx/access.log log_json;
-
-
重启服务:systemctl restart nginx
-
-
修改filebeat.yml文件,区分nginx的访问日志和错误日志
-
vim /etc/filebeat/filebeat.yml
-
修改为: filebeat.inputs: - type: logenabled: truepaths:- /var/log/nginx/access.logjson.keys_under_root: truejson.overwrite_keys: truetags: ["access"]- type: logenabled: truepaths:- /var/log/nginx/error.logtags: ["error"]output.elasticsearch:hosts: ["192.168.8.8:9200"]indices:- index: "nginx-access-%{+yyyy.MM.dd}"when.contains:tags: "access"- index: "nginx-error-%{+yyyy.MM.dd}"when.contains:tags: "error"setup.template.name: "nginx" setup.template.patten: "nginx-*" setup.template.enabled: false setup.template.overwrite: true
-
-
重启服务:systemctl restart filebeat
-
-
使用ab工具压力测试一下网站:
-
测试访问数据:ab -c 1000 -n 20000 http://192.168.8.9/
-
测试错误数据:ab -c 1000 -n 20000 http://192.168.8.9/444.html
-
可以看到es收集到了两个索引:
-
-
-
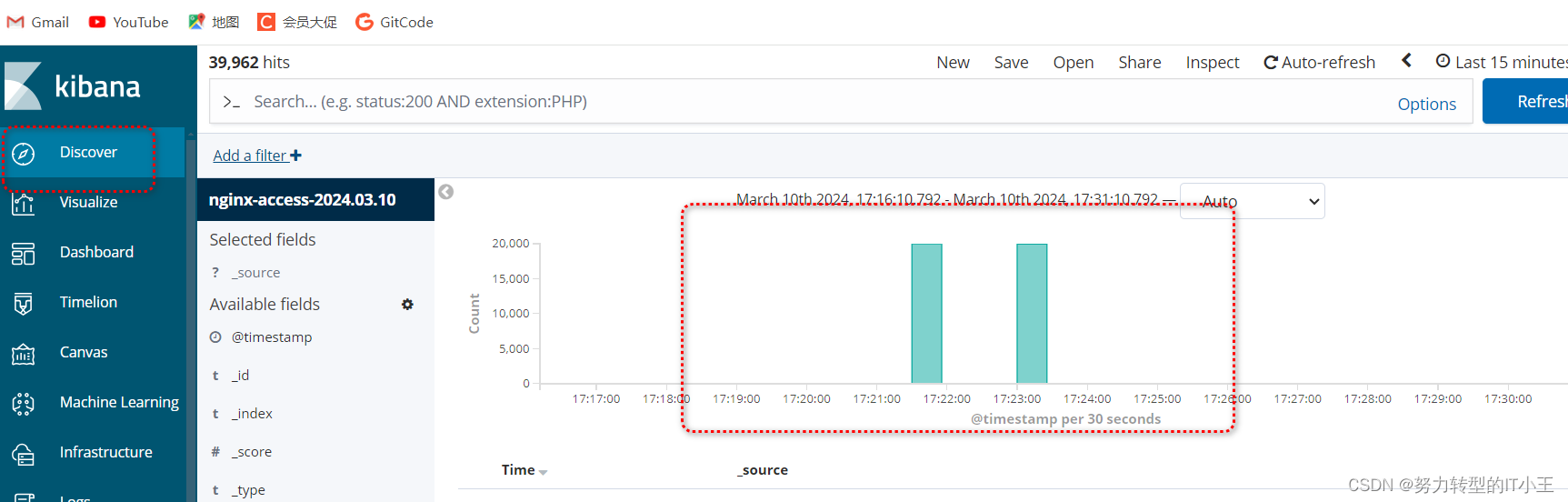
使用kibana图形化展示日志访问数据:
-
http://192.168.8.8:5601/
-
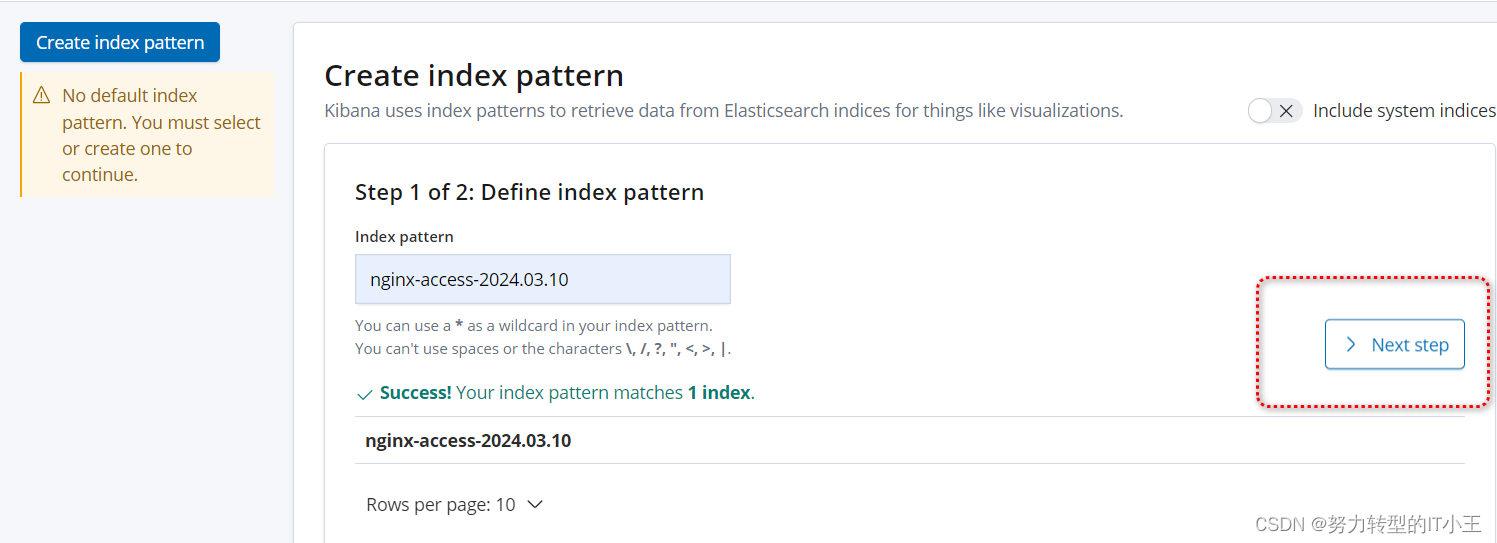
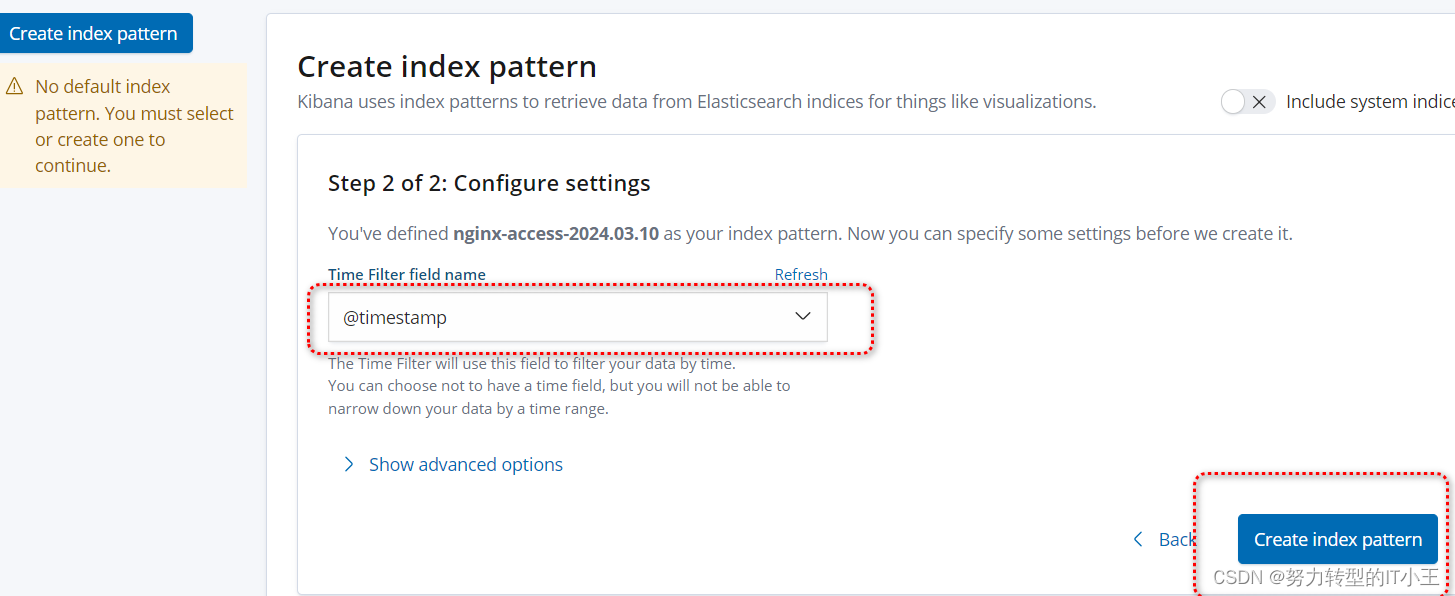
创建索引,图形化展示:
-
-
按照此步骤 将error错误索引页创建一下即可
-
-
虽然以上环境也可以进行日志收集,但只适用于中小型公司,以下再多增加一台服务器,安装redis实现消息队列,和logstash日志采集,增加吞吐量。
-
在8.10服务器上部署redis和logstash:
-
准备安装目录和数据目录:
-
mkdir -p /data/soft mkdir -p /opt/redis_cluster/redis_6379/{conf,logs,pid}
-
-
下载redis安装包:
-
cd /data/soft wget http://download.redis.io/releases/redis-5.0.7.tar.gz
-
-
将软件包解压到/opt/redis_cluster文件夹中:
-
tar xf redis-5.0.7.tar.gz -C /opt/redis_cluster/ ln -s /opt/redis_cluster/redis-5.0.7 /opt/redis_cluster/redis
-
-
切换目录编译安装redis:
-
cd /opt/redis_cluster/redis make && make install
-
-
编写redis配置文件:
-
vim /opt/redis_cluster/redis_6379/conf/6379.conf
-
bind 127.0.0.1 192.168.8.10 port 6379 daemonize yes pidfile /opt/redis_cluster/redis_6379/pid/redis_6379.pid logfile /opt/redis_cluster/redis_6379/logs/redis_6379.log databases 16 dbfilename redis.rdb dir /opt/redis_cluster/redis_6379
-
-
启动redis服务:redis-server /opt/redis_cluster/redis_6379/conf/6379.conf
-
-
修改8.9的filebeat文件(将filebeat收集的日志转发给redis):
-
vim /etc/filebeat/filebeat.yml
-
filebeat.inputs: - type: logenabled: truepaths:- /var/log/nginx/access.logjson.keys_under_root: truejson.overwrite_keys: truetags: ["access"]- type: logenabled: truepaths:- /var/log/nginx/error.logtags: ["error"]setup.template.settings:index.number_of_shards: 3setup.kibana:output.redis:hosts: ["192.168.8.10"]key: "filebeat"db: 0timeout: 5
-
- 重启服务:systemctl restart filebeat
- 再次在8.8上使用压力测试工具访问网站:ab -c 1000 -n 20000 http://192.168.8.9/
- 登录redis数据库:redis-cli
- 查看是否有以filebeat命名的键:
- filebeat与redis关联成功!
- 查看是否有以filebeat命名的键:
-
-
- 继续在8.10服务器上部署logstash:
- rpm -ivh logstash-6.6.0.rpm
- 修改logstash配置文件,实现access和error日志分离
- vim /etc/logstash/conf.d/redis.conf
-
input {redis {host => "192.168.8.10"port => "6379"db => "0"key => "filebeat"data_type => "list"} }filter {mutate {convert => ["upstream_time","float"]convert => ["request_time","float"]} }output {stdout {}if "access" in [tags] {elasticsearch {hosts => ["http://192.168.8.8:9200"]index => "nginx_access-%{+YYYY.MM.dd}"manage_template => false}}if "error" in [tags] {elasticsearch {hosts => ["http://192.168.8.8:9200"]index => "nginx_error-%{+YYYY.MM.dd}"manage_template => false}} }
-
- 最后重启logstash:
-
/usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/redis.conf
-
-
过程需等待,启动较慢(大约2-3分钟)
- vim /etc/logstash/conf.d/redis.conf
-
最后通过kibana图形化界面,可以看到nginx的access日志和error错误日志即可,最终效果和仅部署elk效果一致,只不过添加了redis数据库和filebeat日志收集工具,有了redis可以实现了消息队列为es服务器减轻了压力。
-
ELFK 分布式日志收集系统





本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.hqwc.cn/news/529357.html
如若内容造成侵权/违法违规/事实不符,请联系编程知识网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章
基于Java+springboot+VUE+redis实现的前后端分类版网上商城项目
基于Java springbootVUEredis实现的前后端分类版网上商城项目 博主介绍:多年java开发经验,专注Java开发、定制、远程、文档编写指导等,csdn特邀作者、专注于Java技术领域 作者主页 央顺技术团队 Java毕设项目精品实战案例《1000套》 欢迎点赞 收藏 ⭐留言…

Babel:现代JavaScript的桥梁
🤍 前端开发工程师、技术日更博主、已过CET6 🍨 阿珊和她的猫_CSDN博客专家、23年度博客之星前端领域TOP1 🕠 牛客高级专题作者、打造专栏《前端面试必备》 、《2024面试高频手撕题》 🍚 蓝桥云课签约作者、上架课程《Vue.js 和 E…

力扣--动态规划/回溯算法131.分割回文串
思路分析:
动态规划 (DP): 使用动态规划数组 dp,其中 dp[i][j] 表示从字符串 s[i] 到 s[j] 是否为回文子串。预处理动态规划数组: 从字符串末尾开始,遍历每个字符组合,判断是否为回文子串,填充…
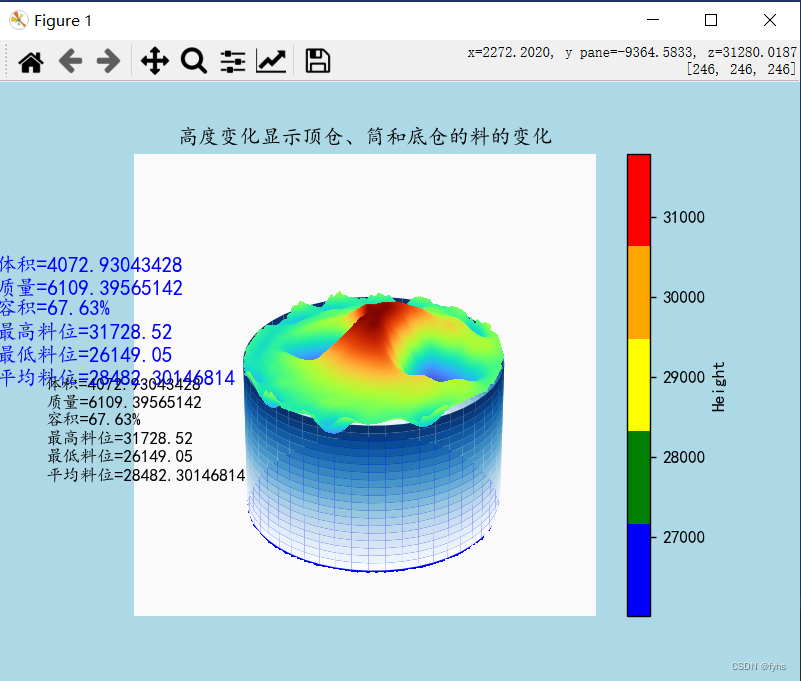
python 导入excel空间三维坐标 生成三维曲面地形图 5-3、线条平滑曲面且可通过面观察柱体变化(三)
环境 python:python-3.12.0-amd64
包:
matplotlib 3.8.2 pandas 2.1.4 openpyxl 3.1.2 scipy 1.12.0
import pandas as pd
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from scipy.interpolate import griddata
from matplotlib.c…
2024年最新指南:如何订阅Midjourney(详尽步骤解析)
前言: Midjourney是一个基于人工智能的图像生成工具,它使用高级算法来创建独特和复杂的图像。这个工具能够根据用户输入的文字描述生成对应的图片。Midjourney的特点在于它能够处理非常抽象或者具体的描述,生成高质量、富有创意的视觉内容。M…
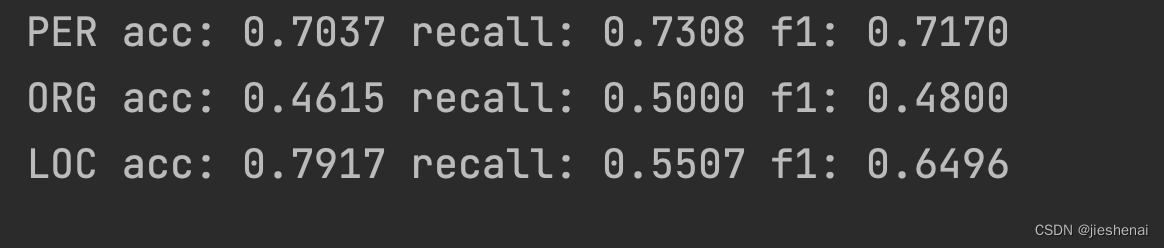
命名实体识别,根据实体计算准确率、召回率和F1
文章目录 简介数据格式介绍准确率、召回率和F1评估评估代码评估结果 进一步阅读参考 简介
使用大模型训练完命名实体识别的模型后,发现不知道怎么评估实体识别的准确率、召回率和F1。于是便自己实现了代码,同时提供了完整可运行的项目代码。
完整代码&…
java SSM科研管理系统myeclipse开发mysql数据库springMVC模式java编程计算机网页设计
一、源码特点 java SSM科研管理系统是一套完善的web设计系统(系统采用SSM框架进行设计开发,springspringMVCmybatis),对理解JSP java编程开发语言有帮助,系统具有完整的源代码和数据库,系统主要采用B/S…

【JAVA】基于HTML与CSS的尚品汇项目
1.代码
index.html
<html lang"en">
<head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><!-- 引入页签图标 --><link rel"shortcut icon"…

深入了解 AVL 树
引言: AVL 树是一种自平衡二叉搜索树,它能够保持树的平衡性,从而提高了搜索、插入和删除操作的效率。在本文中,我们将深入探讨 AVL 树的概念、使用场景,并通过 Java 实现一个简单的 AVL 树。 一、AVL 树的概念 AVL 树是…
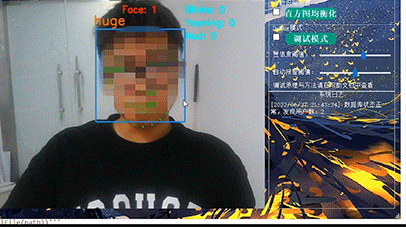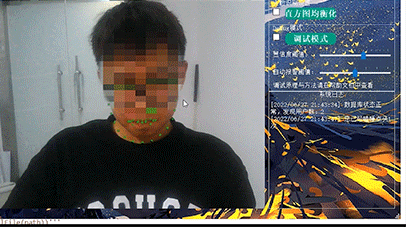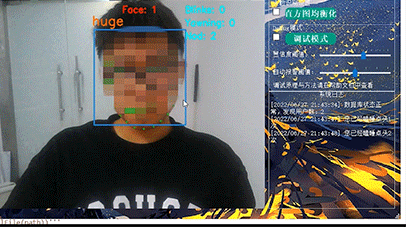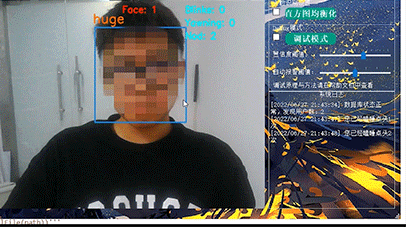
计算机设计大赛 疲劳驾驶检测系统 python
文章目录 0 前言1 课题背景2 Dlib人脸识别2.1 简介2.2 Dlib优点2.3 相关代码2.4 人脸数据库2.5 人脸录入加识别效果 3 疲劳检测算法3.1 眼睛检测算法3.2 打哈欠检测算法3.3 点头检测算法 4 PyQt54.1 简介4.2相关界面代码 5 最后 0 前言
🔥 优质竞赛项目系列&#x…
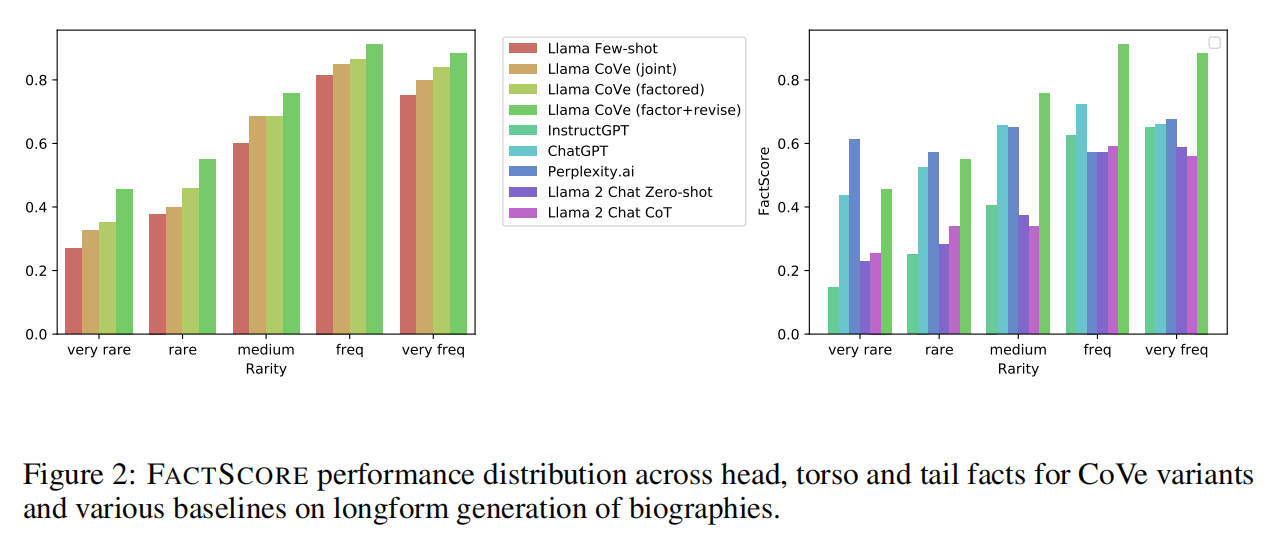
【RAG】Chain-of-Verification Reduces Hallucination in LLM
note
百川智能还参考Meta的CoVe(Chain-of-Verification Reduces Hallucination in Large Language Models)技术,将真实场景的用户复杂问题拆分成多个独立可并行检索的子结构问题,从而让大模型可以针对每个子问题进行定向的知识库…
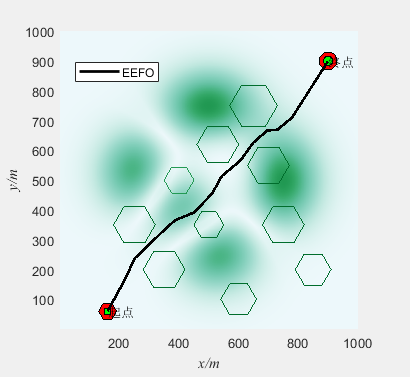
基于电鳗觅食优化算法(Electric eel foraging optimization,EEFO)的无人机三维路径规划(提供MATLAB代码)
一、无人机路径规划模型介绍
无人机三维路径规划是指在三维空间中为无人机规划一条合理的飞行路径,使其能够安全、高效地完成任务。路径规划是无人机自主飞行的关键技术之一,它可以通过算法和模型来确定无人机的航迹,以避开障碍物、优化飞行…