本次分享由中国人民大学、微软亚洲研究院联合投稿于AAAI 2023的一篇专门为视频配音任务定制的机器翻译的工作《VideoDubber: Machine Translation with Speech-Aware Length Control for Video Dubbing》。这个工作将电影或电视节目中的原始语音翻译成目标语言。
论文地址:
https://arxiv.org/pdf/2211.16934.pdf
Demo地址:
https://speechresearch.github.io/videodubbing/
代码地址:
https://github.com/microsoft/NeuralSpeech/tree/master/VideoDubber/fairseq
0 Abstract
视频配音指将电影或电视节目中的原始语音翻译成目标语言的语音,这可以通过一种级联系统来实现,该系统由语音识别、机器翻译和语音组成。为了确保翻译后的语音与相应的视频完美对齐,翻译后的语音的时长/对话应尽可能接近原始语音,这需要严格的长度控制。以往的工作通常控制机器翻译模型生成的单词或字符的数量,使其与原句相似,而不考虑由于不同语言中单词/字符的语音持续时间不同而导致语音的等时性。本文提出了VideoDubber,这是一个专门针对视频配音任务的机器翻译系统,该系统直接考虑到了翻译中每个token的语音时长,以匹配源语言和目标语言的语音长度。具体来说,我们使用时长信息来指导每个单词的预测,来控制生成句子的语音长度,这包括单词本身的语音时长和还有多少时长留给剩余的单词。我们对四种语言方向(German→ English, Spanish → English, Chinese ↔ English)进行了实验,并且结果表明,与baseline methods相比,VideoDubber在生成的语音上达到了更好的长度控制能力。为了弥补现实世界数据集的不足,我们还构建了从电影中收集的真实测试数据集,来对视频配音任务进行全面评价。
1 Introduction
视频配音指将在电影或电视节目中的原始语音从源语言翻译到目标语言的语音。一般来说,自动视频配音任务由三个级联的子任务组成,即自动语音识别(Automatic Speech Recognition, ASR),神经机器翻译(Neural Machine Translation, NMT)以及语音合成(Text-to-Speech, TTS)。具体来说,ASR将源语言中的原始语音转写为文本,当字幕存在时,这一步可以省略。NMT旨在将源语言中的文本翻译到目标语言,TTS最终将翻译后的文本合成为目标语言的语音。与speech-to-speech翻译不同,视频配音需要在原始语音与合成的目标语音保持严格的登时约束,以确保语音在长度方面与原始视频画面匹配,从而提供沉浸式的观影体验,这带来了额外的挑战。
在级联视频配音系统中,NMT和TTS都可以决定翻译后语音的时长,即由NMT决定翻译后单词的数量,而通过调整单词的停顿和时长,TTS可以控制语音的长度。以往的自动视频配音系统独立地控制语音等时性,首先控制生成目标单词/字符的数量来接近源单词,接着调整说话速度来确保合成后的语音时长与原语音相似。然而,由于不同语言中单词/字符的语音时长存在差异,源语言和目标语言中单词/字符的相同数量并不能保证语音语音长度相同。因此,TTS需要在较大范围内调整每个单词的说话速度来匹配总的语音长度,这将影响合成语音的流畅性和自然度(例如,说话速度可能与相邻句子的速度不一致)。
在本文中,我们系统地解决了长度控制问题。将合成的语音长度与原始语音匹配,同时避免相邻句子之间的说话速度不一致。为了保证高质量的听觉质量,我们应该将更多的长度控制责任交给NMT而减少对TTS的控制。这要求NMT可以被原始语音进行控制同时保持语音翻译质量。为了实现这一目标,我们提出了以下技术。首先,在翻译目标句子时控制语音持续时间,我们使模型意识到每个时间步的剩余语音时长以及每个单词的语音时长。为此,我们使用两种不同的位置嵌入来表示它,并将其与原始嵌入相加,作为解码器的输入。其次,我们引入了一个特殊的停顿词[P],它被插入在每个目标单词之间,通过调整[P]的时长来考虑语音的韵律(与语言有关的节奏、韵律和停顿),以更平滑地控制语音的长度。最终,在训练过程中,我们计算目标语音和文本之间的对齐,以获取每个目标词语的语音持续时间,而不仅仅使用单词/字符的数量。此外,我们引入了一个名为“时长预测器”的神经网络组件,用于明确建模每个单词的语音持续时间。在推理过程中,给定源语音的的长度,时长预测器与解码器共同工作,生成与原语音长度相似的高质量翻译。此外,考虑到现实世界中真实视频配音数据集的稀缺性(即,带有黄金跨语言源和目标语音的电影),我们构建了一个从配音电影中收集的测试集,用以全名评估配音系统的性能。
本研究的主要贡献总结如下:
-
我们提出了VideoDubber,这是一个专为视频配音任务定制的机器翻译系统。该系统通过计算并将每个单词的语音持续时间编码到模型中,直接控制生成句子的语音长度。
-
我们在四种语言方向上进行了实验,使用客观和主管评估指标。实验结果表明,与baseline 方法相比 ,VideoDubber在所有语言中都实现了更好的长度控制。
-
由于视频配音测试数据集的稀缺性,我们构建了一个从电影中收集的真实世界测试集,以对视频配音任务进行全面评估。
2 Background
Problem Definition 我们首先提供了视频配音任务的定义。在给定源语音 s,其持续时间 T_s 和其转录 x = (x_1, ..., x{T_x}) 的情况下,我们的目标是生成翻译文本序列 y = (y_1, ..., y{T_y}),同时生成持续时间为 T_t 的合成语音 ( t )。其中,( T_t ) 应尽可能接近 ( T_s ),同时保持 ( y ) 的高质量翻译以及 ( t ) 的韵律和流畅性。
现有的视频配音工作通常基于级联的语音到语音翻译系统,具有临时设计,主要集中在NMT和TTS阶段。在NMT阶段,相关研究通过相似数量的单词/字符应该具有相似的语音长度,因此鼓励模型生成与源序列相似单词/字符数量的目标序列,以实现长度控制。在训练过程中,它们计算源文本和目标序列之间的长度比作为冗余信息,并在推理过程中将长度比设置为1,以控制翻译后语音的长度。Lakew等人(2022年)引入了字符级别的长度约束到NMT模型中,通过使用带有长度控制的回译来扩充训练集。此外,先前的研究把将要生成的字符数量编码到位置嵌入中,以融入长度控制的正则项。这些方法仅仅控制生成的单词/字符数量,使其源序列相似,而没有考虑源语音和目标语音中单词/字符的语音时长的差异。
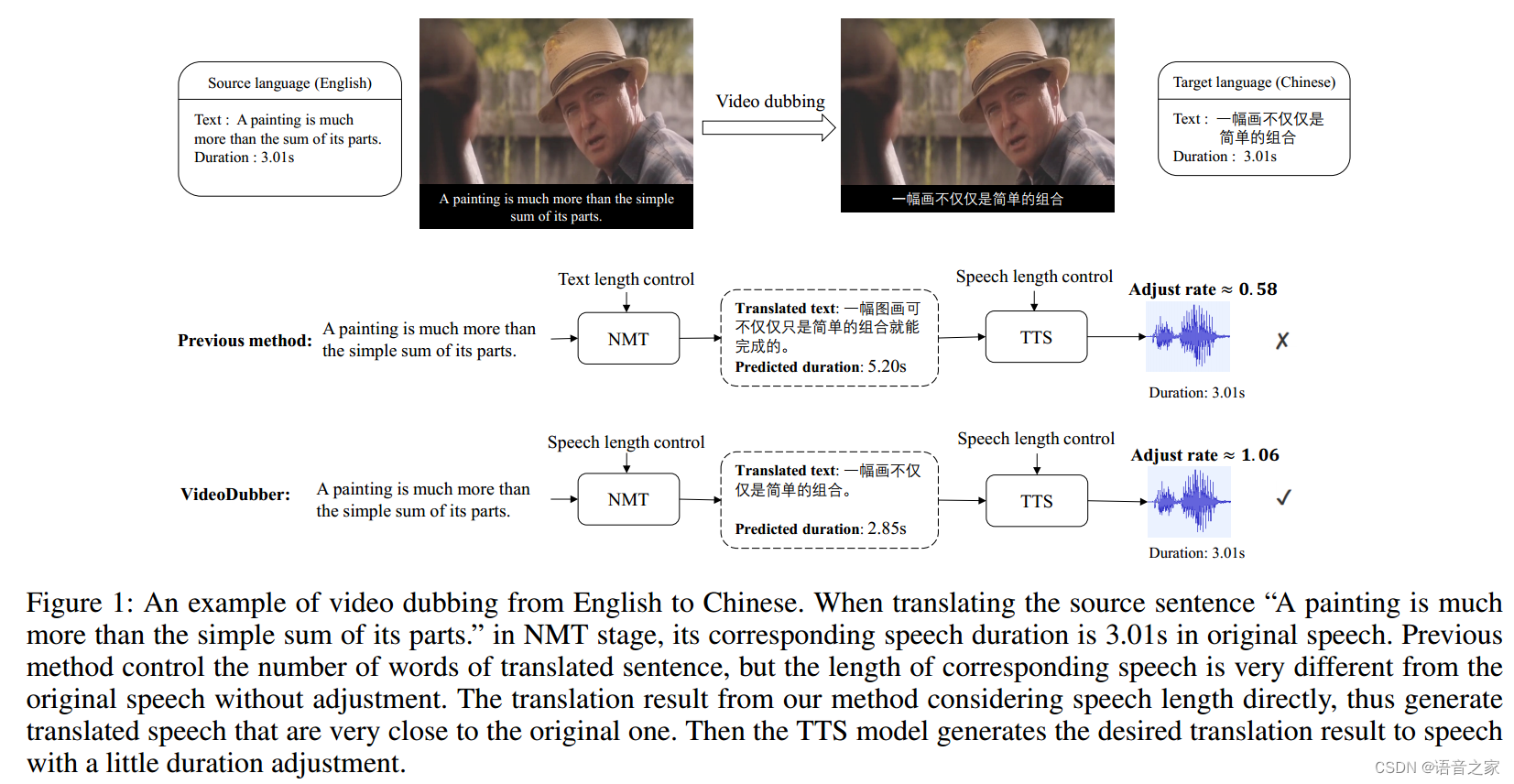
从TTS阶段,通过调整语速以确保生成语音的持续时间与源语音相匹配,TTS阶段将翻译后的文本序列合成为语音,并加入等时约束。此外,Effendi等人(2022年)提出了一个时长模型,可以通过均一标准化或非弹性标准化来预测和调整音素的持续时间。为了减轻时长调整的工作量,并将目标语音中的停顿和短语与原语音匹配,一些研究(Federico等人,2020a,b;Virkar等人,2021)在TTS阶段之前引入了额外的韵律对齐模块。它在翻译的文本中插入暂停标记,考虑到相应源-目标短语之间的语速匹配以及所选分割点的语言合理性。然而,这种两阶段基于规则的方法无法直接利用语音中的自然停顿和节奏。而且,它只在短语之间插入了停顿,忽略了不同粒度的停顿通常对应不同的持续时间。由于听众对语速变化非常敏感,相邻句子之间不一致的语速,例如,前一句较快,而当前句子较慢,会破坏语音的韵律和流畅性。因此,在本文中,我们试图减轻TTS阶段上的长度控制负担,将重点放在NMT阶段,提出了一个语音感知的长度控制模型,直接控制生成的目标序列的语音持续时间,而不是token的数量。
3 Proposed Method
在本节中,我们介绍了VideoDubber。具体来说,我们通过使用持续时间引导每个单词的预测,来控制生成的句子的语音长度。模型架构的示意图如图2所示。

3.1 Overview
为了使合成的语音长度与原始语音相匹配,同时保持流畅和自然,我们应该将长度控制的责任更多地分配给NMT,而减少TTS的干预。因此,我们的目标就是如何在保持高质量翻译的同时,在NMT阶段实现语音感知的长度控制。为了实现这个目标,我们首先获取每个目标单词的语音持续时间 d = (d_1, ..., d_{T_y}) ,然后将其整合到NMT模型中。
具体来说,我们通过设计两种类型的基于时长位置嵌入,来将时长信息整合到模型中。其中一种是绝对时长位置嵌入,它指示了当前时间步骤累计的时长信息,另一种是相对时长位置嵌入,它计算为绝对时长和总时长的位置嵌入的比率,表示未来的tokens还有多少时长。通过这种方式,模型在进行预测时被训练为同时考虑语义和时长信息。我们还考虑了停顿,通过引入特殊的暂停token[P],以更灵活地控制语音长度。
为了在训练过程中获取每个目标单词的语音时长,我们首先通过Montrea强制对齐(Montreal forced alignment, MFA)在音素级别计算语音和文本之间的对齐。然后,我们引入一个时长预测器,它是由一个卷积层组成的神经网络组件,插入在解码器的顶部,用于在给定解码器的隐藏输出的条件下预测每个单词的时长。接下来,在推理阶段,给定总督语音长度(即源语音的长度),解码器将以自回归的方式在每个步骤根据语义表示和时长信息确定适当的翻译,如图2所示。我们将在接下来的部分详细讨论这一过程。
3.2 Model Architecture
Duration-aware Position Embedding 为了在翻译中考虑语音的时长,我们通过为每个token设计时长感知位置嵌入来整合时长信息。在这里,我们设计了两种类型的位置嵌入,分别提供绝对和相对的语音感知时长信息。
我们将Transformer中的原始位置嵌入(Vaswani等人,2017b)表示为 ( p_o )。然后,给定第 ( i ) 个目标标记 ( y_i ) 及其持续时间 ( d_i ),我们定义绝对持续时间位置嵌入 ( p_{a_i} ) 为截至当前为止的累积语音持续时间,可以表示为:

其中,其中,PE(⋅) 表示对正弦位置嵌入矩阵的查找函数。引入的 ( p_{a_i} ) 告诉模型已生成单词的截至当前的语音长度。此外,为了让模型知道剩余多少时长,从而通过选择时长适当的单词来规划生成,我们还引入了一个相对时长嵌入p_r,以整合全局的时长信息。它的计算方法是累积时长与总时长之间的比率:

其中,q_N(x) =[x x N] 将浮点数持续时间比率从 [0, 1] 映射为 [0, N] 范围内的整数。最后,给定第 ( i ) 个目标标记 ( w_i ) 的词嵌入,我们将这三个位置嵌入与它相加,构建解码器的输入:

所提出的这两种位置嵌入方法互补,并且我们在实验中评估了它们的有效性。
Pause Token 我们进一步考虑了单词之间的停顿,并调整了它们的持续时间,以确保长度控制的灵活性。也就是说,我们可以自动增加或减少暂停的持续时间,以分担长度控制的责任,这样可以避免相邻句子之间的语速不均匀,对语音的流畅至关重要。作为副产品,停顿也可以用来建模语音的韵律。具体而言,我们通过引入一个特殊标记[P]来明确地模拟语音中的停顿,该token被插入在源句子和目标句子的每个单词之间(而不是子词之间)。例如,在进行了字节对编码(BPE)(Senrich, Haddow和Birch 2015)之后,短语"A painting"被分词为"A pain@@ting", 然后在插入停顿token后变为"A[P]pain@@ting"。这样,模型就学会了在每个上下文中的单词后面预测一个具有适当时长的暂停token,为语音长度控制提供了更灵活的方式。
Duration Predictor 我们遵循FastSpeech2(Ren等人2021)的方法,使用MFA工具计算训练的真实单词时长。为了使模型在推理的时候能够在没有真实时长的情况下预测每个token的语音时长,我们引入了一个额外的神经网络组件,称为时长预测器,它是建立在解码器上的。在训练过程中,时长预测器以每个token的隐藏表示作为输入,并预测每个token的golden时长,表示这个token对应多少个mel帧,并且为了方便预测,将其转为对数域。时长预测器使用均方误差(MSE)损失进行优化,将真实时长作为训练目标。将持续时间序列表示为d = (d1, ..., dTy ), 预测可以写为:
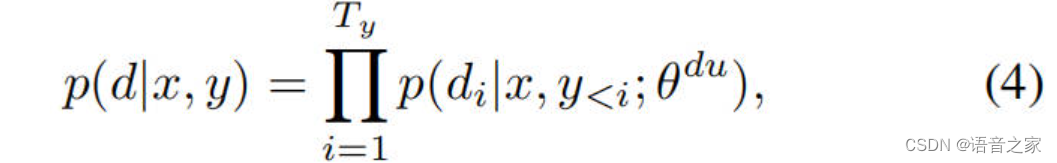
其中,θ_du 表示持续时间预测器的参数。
3.3 Model Architecture
Overall Length Control Pipeline 在我们在第3.2介绍的具有语音感知长度控制的文本翻译后,我们通过TTS阶段的时长调整进一步实现更精确的长度控制。我们采用了AdaSpeech4(Wu等人,2022),这是一个零样本语音TTS模型,它可以直接调整语音的时长。与统一的时长调整方法不同,后者通过相同的因子来缩放每个音素的时长,我们仅调整元音的时长,保证福音的长度不变。这是因为在自然语音中,当人们放慢或加快语速时,辅音的持续时间通常不会发生显著变化(Kruspe 2015)。通过在NMT和TTS上采用这种系统化的方法,我们可以实现精确和灵活的语音长度控制,以确保的语音与视频配音场景中相应视频保持良好的对齐。
About the Pause Token 一些相关工作(Federico等人,2021a, Virkar等人, 2021)也在视频配音框架中引入了暂停标记,通过动态规划算法在翻译文本的短语之间插入暂停标记。VideoDubber与它们的方法在两个方面不同。首先,我们通过在每个单词而不是短语中插入暂停token,提供了更精细的暂停控制。其次,每个暂停token标记的语音时长可以在不同上下文中不同,并且由模型端到端学习,这提供了更好的长度控制和合成语音的韵律建模灵活性。
About Video Dubbing Dataset 由于视频配音数据集的稀缺性,通常我们会在语音到语音翻译数据集上进行,其中训练和测试数据中的源语音和目标语音的长度不能保证相似。因此,这实际上与真实世界的视频配音不同,真实世界的视频配音中,源语音和目标语音的长度是完全匹配。使用与源语音长度不同的参考翻译(即,在NMT模型中进行控制的语音长度)来评估视频配系统的语义翻译质量是不准确的。因此,我们试图在两个方面缓减这个问题: 1) 在评估中,我们分别使用源语音和目标语音的长度来控制NMT模型,其中源语音的长度与我们在实际视频配音中使用的长度一致,而目标语音的长度用于评估当参考句子的长度与控制长度相同时,我们的模型的性能如何。2) 此外,我们还从配音电影中构建了一个真实的视频配音测试测试集,其中源语音和目标语音的长度完全相同。通过这种方式,构建的测试机可以用来评估实际场景中的视频配音系统。
另一个潜在问题是,NMT模型被训练为生成具有目标语音长度 的文本(与源语言长度不同),但在推理的时候,它被用来生成具有目标语音长度的文本(与源语音长度不同),但在推理中,它被用来生成具有源语音长度的文本,这导致了不匹配。然而,要缓解这个问题确实非常困难,因为很难收集到具有相同源语音和目标语音长度的大规模训练数据。尽管如此,我们计划通过知识蒸馏构建一个训练数据集,其中通过我们的NMT模型控制蒸馏后的目标句子与源句子具有相同的语音长度,我们将这个问题留待将来的研究。
4 Real-World Video Dubbing Test Set
考虑到真实视频配音数据的稀缺性(即,具有黄金跨语言语音和目标语音的运动片段),我们构建了一个从配音电影中收集的测试集,一遍对视频配音系统进行全面评估。
具体而言,我们选择了九部从英语翻译成中文的热门电影,这些电影的手工翻译和配音质量很高,包含了爱情、动作、科技等丰富题材。我们从这些电影中选取了42个对话片段,符合以下标准:1)片段持续时间约为1-3分钟。2)每个片段包含超过10个句子,其中既包括长句子又包括短句子。3)在说话期间,说话人的脸部大部分是可见的,特别是在讲话结束时,嘴唇是可见的。
随后,我们从视频片段提取音频并去除背景声音,获得清晰的语音。然后,我们进行语音识别并进行手动矫正,以获得源语言和目标语言的文本转录。此外,我们根据语义和说话人将片段分成句子。我们丢弃了句子之间的静默帧,以确保每个分割的开头和结尾都不超过0.5秒的静默。最终,我们获得了总时长为1小时的测试数据集,包括原始电影、带有文本转录的源语音以及带有文本转录的人工配音语音。其中包含892个句子用于句子级别的评估。
5 Experimental Setup
5.1 Datasets
Training Data 我们在四个语言方向上进行了VideoDubber的训练:中文 → 英语(Zh-En),英语 → 中文(En-Zh),德语 → 英语(De-En),西班牙语 → 英语(Es-En)。由于缺乏真实的视频配音数据集,我们在语音翻译数据集上训练和测试VideoDubber。对于从其他语言到英语的语言方向,我们使用公开的语音到语音翻译数据集CVSS(Jia等人,2022年),该数据集包含从CoVoST2数据集(Wang等人,2021年)派生出的多语言到英语的语音到语音翻译语料库。对于从英语到中文的方向,我们使用MuST-C(Cattoni等人,2021年)的En-Zh子集,这是一个由英语TED演讲构建的英语到其他语言的语音翻译语料库。由于MuST-C数据集没有目标语言中的对应语音,我们使用了一个经过良好训练的中文文本到语音(TTS)模型,FastSpeech2(Ren等人,2022),来从翻译的文本中生成中文语音。
Evaluation Data 在评估中,我们考虑了两个数据集。一个是来语音翻译数据集的标准数据集,遵循了先前的研究设置;另一个是针对视频配音场景构建的真实世界测试机,用于现实场景中测试整理性能。
5.2 Evaluation Metrics
我们采用主观和客观评估指标来评估比较的视频配音系统。
Objective Metrics 我们使用BLEU和符合语音长度来评估翻译文本的语义质量和模型的长度控制能力。
1)BLEU (Paineni等人, 2002)分数是机器翻译任务中广泛使用的自动评估指标。我们报告标记化的BLEU分数,以保持与先前研究一致。
2)Speech Length Compliant 为了评估语音长度控制性能,受Lavkew(2022)等人的启发,我们设计了语音长度符合(Speech Length Compliant, SLC_p)分数。SLCp表示句子比例,其比率 ∈ [1 − p, 1 + p],其中比率定义为:

其中,di和dj分别表示源语音和翻译语音中标记i和j的持续时间。SLCp指的是比率 ∈ [1 − p, 1 + p] 的句子的百分比。Federico等人(2020b)将p设置为0.4,用于评估合成音频的流畅性,而我们发现p = 0.2是用户研究中更为合理的区间(即,语速加速1.4倍或减慢0.6倍将导致较大的不一致性,影响用户的观看体验)。因此,我们同时使用了p = 0.2和p = 0.4,并在实验中分别比较它们的对应SLCp。
Subjective Metrics 除了客观指标,我们还引入了一些主观指标来评估VideoDubber在真实世界的视频配音场景中的表现。
1)Translation quality 翻译质量是通过人工评估来衡量配音视频翻译文本的质量。需要注意的是,评审人员将根据原始视频来评价翻译质量,这更适用于视频配音场景。
2)Isochronism 等时性分数用于衡量在视频配音场景中原始视频是否与翻译的语音相匹配。
3)Naturalness 自然度分数用于评估带有配音语音的视频的整体表现。评审人员将同时考虑翻译质量和等时性。
5.3 Model Configuration
我们采用Transformer(Vaswani等人,2017b)为基础的编码器-解码器框架作为我们翻译模型的主干。在所有设置中,我们将模型的隐藏维度设置为512,前馈层的维度设置为2048。对于编码器和解码器,我们使用6层和8个头的多头注意力机制。持续性感知的位置嵌入仅添加在解码器堆栈的输入处,编码器的架构与原始Transformer保持一致。
时长预测器由两层带有ReLU激活函数的卷积网络组成,每一层后面都跟着层归一化和dropout层。额外的线性层输出一个标量,即预测的token的时长。需要注意的是,这个模块是与Transformer模型一块进行联合训练,用均方误差(MSE)损失来预测每个token的时长。我们在对数域中预测持续时间,这样更容易训练。值得一提的是,时长预测器仅在推理的时候使用,因为在训练中可以直接使用真实的token时长。
在文本到语音(TTS)阶段,我们使用了一个预训练的零样本TTS模型,AdaSpeech 4(Wu等人,2022年)。给定参考语音,它可以为之前未见过的说话人合成语音。在这里,我们将源语音视为参考,生成带有持续时间调整的语音。
5.4 Baseline
我们将VideoDubber与一个广泛应用的基线方法(Federico等人,2020a)进行比较。该基线方法通过使用单词数量来控制NMT中翻译文本的长度。在训练阶段,该方法将来自训练数据集的句子分成三组(短、普通、长),然后在训练阶段,它将相应的长度比例标记伪装为源序列。在推断阶段,所需的长度标记(即普通)被伪装为源序列,以控制翻译文本的长度。
6 Results
6.1 Automatic Evaluation
我们在表格1中展示了相关模型在四个语言方向上的机器翻译质量和长度控制能力。如3.3节所讨论的,我们还列出了使用黄金目标语音长度控制翻译时的结果,以展示我们模型的性能上限。在考虑SLCp(句子长度一致性比率)衡量的长度控制能力时,VideoDubber始终以较大的优势胜过所考虑的baseline方法,表明所提出的语音感知长度控制比控制单词/字符数量(Federico等人,2020a)实现了更好的语音持续一致性。特别是在En-Zh方向上,我们发现VideoDubber相对于控制token数量的baseline带来了显著的改进。这个原因可能是在中文中,token数量和语音时长存在较大的不一致性,即中文中的一个token可能包含多个汉字,而不是英文中的一个子词。因此,即使token数量有小的不匹配,也可能在中文中导致较大语音时长的差异。VideoDubber通过直接控制语音长度缓解了这个问题。
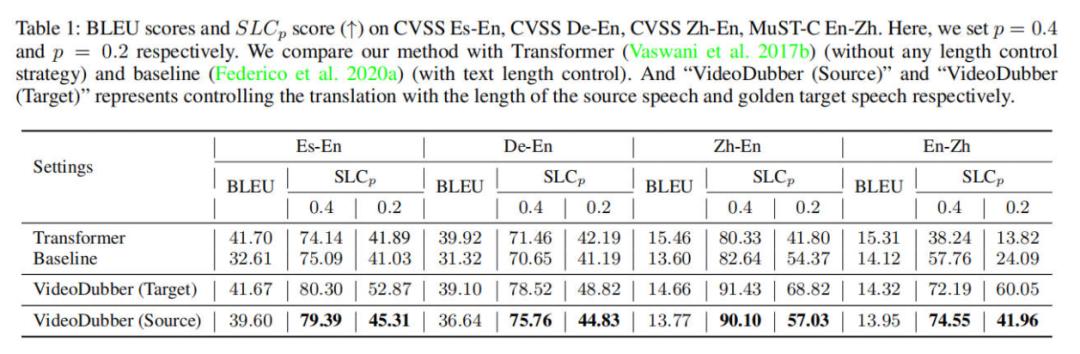
关于BLEU分数,尽管与原始Transformer模型相比略微下降,但是VideoDubber在Es-En和De-En方向上优于长度控制的baseline。baseline方法执行较粗的长度控制,所有句子使用相同的长度控制嵌入。这可能导致在某些数据集中翻译能力不稳定。此外,值得注意的是,测试集中的源语句和目标语句的语音长度并不相同。使用BLEU分数来评判翻译质量是不公平的。因此,我们提出了一个新的真实世界测试集,并在其中进行了公平的比较,正如在第6.3节中所说明的那样。
6.2 Ablation Study
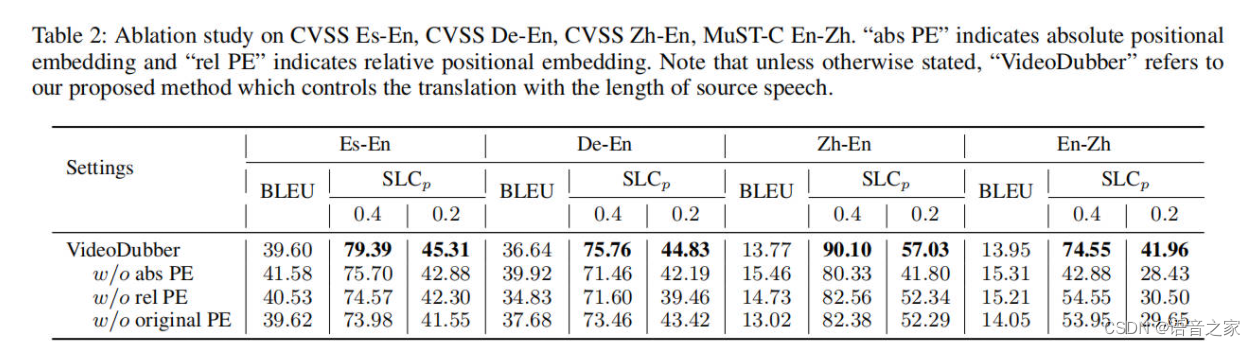
为了验证时长感知位置嵌入的有效性,我们在四个语言方向上进行了三种类型的位置嵌入的消融实验,如图表2所示。我们可以发现绝对和相对时长位置嵌入都是实现更好的语音感知长度控制结果的关键。
6.3 Results on Real-world Test Set
为了比较相关方法在真实世界视频配音场景中的性能,我们在我们构建的真实世界测试集上进行了实验。结果如表3所示。
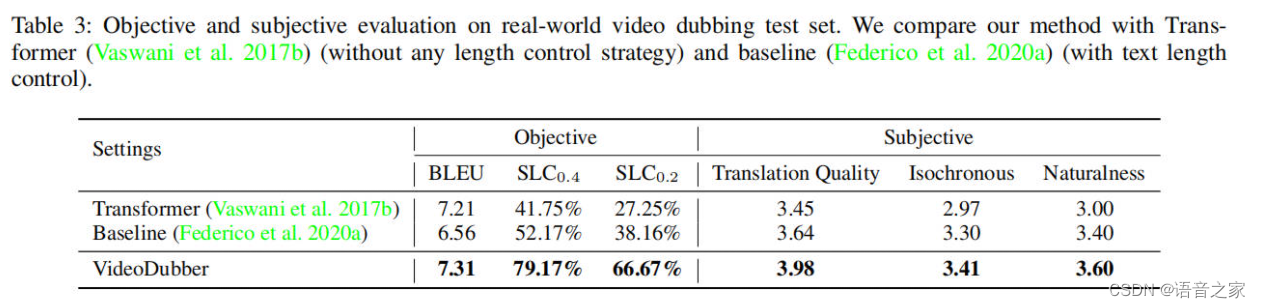
在客观评估中,与Transformer和标记数量控制基线相比,VideoDubber取得了最高的BLEU和SLCp分数。这证明了在考虑语音等时性的真实测试集中,提出的带有语音感知长度的NMT模型可以实现更好的等时性控制能力以及翻译质量。此外,我们进行了主观评估,评估翻译质量、与原始电影画面的同步性以及合成语音的整体质量。我们聘请了8位擅长中英文的评审员,要求他们对不同方法生成的样本进行5分制的评分。从表3可以看出,与客观评估结果一致,我们观察到VideoDubber在翻译质量和语音等时性方面表现最好。此外,我们的方法在自然度评分方面表现出色,这反映了自动配音视频的整体质量。演示样本可在 https://speechresearch.github.io/videodubbing/ 查看。
7 Conclusion
在本文中,我们提出了VideoDubber,这是一个用于视频配音任务的具有语音感知长度控制的机器翻译模型。为了确保翻译的语音与原始视频保持良好的对齐,我们在翻译中直接考虑了每个token的语音时长。首先,我们通过每个单词的时长信息表示为两种类型的位置嵌入,引导每个单词的预测。其次,我们引入了一个特殊的暂停词[P],它被插入到每个词之间,以便通过考虑韵律来更平滑地控制语音长度。第三,我们构建了一个从配音电影中收集的真实测试集,以便提供更加实际的视频配音系统评估。实验结果,VideoDubber在翻译质量和等时性控制能力方面优于相关工作。在未来的工作中,我们计划通过知识蒸馏构建一个训练数据集,其中通过我们的NMT模型控制的蒸馏目标句子将与源句子具有相同的语音长度。
文章转载于智能语音新青年