1、功能说明:
在Flink 自定义源算子中封装jdbc来读取MySQL中的数据
2、代码示例
Flink版本说明:flink_1.13.0、scala_2.12
自定义Source算子,这里我们继承RichParallelSourceFunction,因为要使用open方法来初始化数据库连接对象
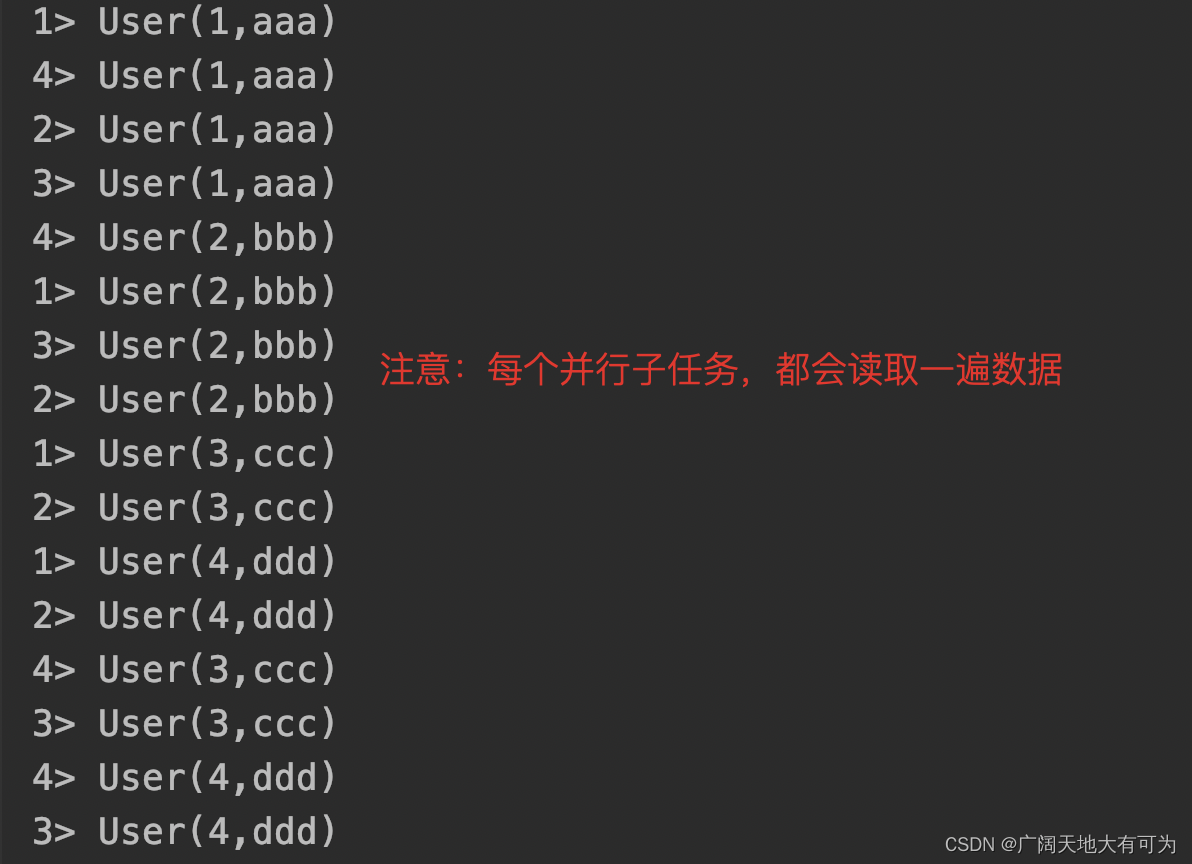
Tips:这种实现方式为可并行算子,当并行度>1时,每个并行任务都会读取相同的数据,使用的时候需要注意
package com.baidu.beancase class User(id: Long, name: String)
class MysqlSource extends RichParallelSourceFunction[User] {// 定义 Connection、PreparedStatement对象var connection: Connection = nullvar ps: PreparedStatement = null// 函数初始化方法,常用来初始化资源对象,常用来做一次性的设置// 当 MysqlSource对象被创建时,调用一次override def open(parameters: Configuration): Unit = {// 初始化 Connection、PreparedStatement对象// 加载数据库驱动Class.forName("com.mysql.jdbc.Driver")// 获取连接connection = DriverManager.getConnection("jdbc:mysql://worker01/flink", "root", "worker123")// 读取user表ps = connection.prepareStatement("select * from user")}override def run(ctx: SourceFunction.SourceContext[User]): Unit = {// 执行查询操作,获取查询结果val resultSet = ps.executeQuery()// 将查询结果封装到user对象while (resultSet.next()) {val user = User(resultSet.getLong(1),resultSet.getString(2))ctx.collect(user)}}// 关闭连接资源override def cancel(): Unit = {connection.close()ps.close()}
}
使用 MysqlSource 来读取数据(作为有界流来处理):
test("使用 自定义Source算子,读取mysql数据") {// 1. 获取流执行环境val env = StreamExecutionEnvironment.getExecutionEnvironment// 2. 将 自定义数据源 作为数据源val ds: DataStream[User] = env.addSource(new MysqlSource).setParallelism(4)// 3. 打印DataStreamds.print()// 4. 出发程序执行env.execute()}
执行结果: