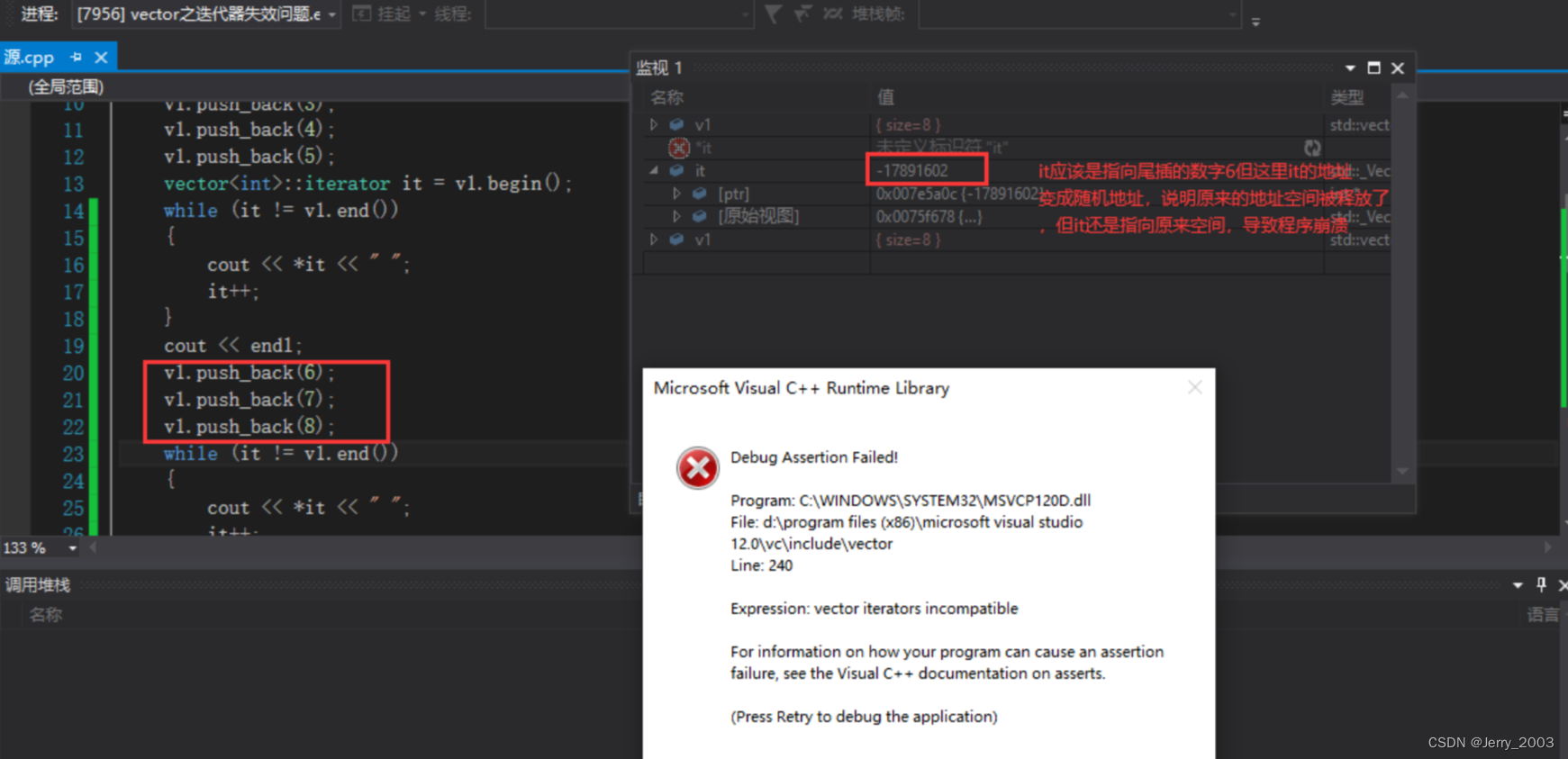
在我之前的文章 “Elasticsearch:如何提高查询性能” 及 “Elasticsearch:提升 Elasticsearch 性能” 里,我详细描述了如何提高搜索的性能。在今天的文章里,我从另外一个视角来描述如何调整搜索的速度。希望对大家有所帮助!
为文件系统缓存提供内存
Elasticsearch 严重依赖文件系统缓存来提高搜索速度。 一般来说,你应该确保至少一半的可用内存用于文件系统缓存,以便 Elasticsearch 可以将索引的热区域保留在物理内存中。
在 Linux 上使用适度的预读值来避免页面缓存抖动
搜索可能会导致大量随机读取 I/O。 当底层块设备具有较高的预读值时,可能会执行大量不必要的读取 I/O,特别是当使用内存映射访问文件时(请参阅存储类型)。
大多数 Linux 发行版对单个普通设备使用 128KiB 的合理预读值,但是,当使用软件 raid、LVM 或 dm-crypt 时,生成的块设备(支持 Elasticsearch path.data)最终可能会具有非常大的预读值(在 几个 MiB 的范围)。 这通常会导致严重的页面(文件系统)缓存抖动,从而对搜索(或更新)性能产生不利影响。
你可以使用 lsblk -o NAME,RA,MOUNTPOINT,TYPE,SIZE 检查当前值(以 KiB 为单位)。 有关如何更改此值的信息,请参阅发行版的文档(例如,使用 udev 规则在重新启动后保持不变,或通过 blockdev --setra 作为瞬态设置)。 我们建议预读值为 128KiB。
警告:blockdev 期望值以 512 字节扇区为单位,而 lsblk 报告值以 KiB 为单位。 例如,要将 /dev/nvme0n1 的预读临时设置为 128KiB,请指定 blockdev --setra 256 /dev/nvme0n1。
使用更快的硬件
如果你的搜索受 I/O 限制,请考虑增加文件系统缓存的大小(见上文)或使用更快的存储。 每次搜索都涉及跨多个文件的顺序和随机读取的混合,并且每个分片上可能同时运行许多搜索,因此 SSD 驱动器的性能往往比旋转磁盘更好。
直连(本地)存储通常比远程存储性能更好,因为它更易于配置并避免通信开销。 通过仔细调整,有时使用远程存储也可以获得可接受的性能。 使用实际工作负载对你的系统进行基准测试,以确定任何调整参数的效果。 如果你无法达到预期的性能,请与存储系统的供应商合作找出问题。
如果你的搜索受 CPU 限制,请考虑使用更多更快的 CPU。
文档建模
应该对文档进行建模,以便尽可能减少搜索时间操作。
特别是应该避免 joins。 nested 可以使查询慢几倍,而父子关系可以使查询慢数百倍。 因此,如果可以通过非规范化文档来回答相同的问题,而无需 joins,则可以预期显着的加速。
搜索尽可能少的字段
query_string 或 multi_match 查询的目标字段越多,速度就越慢。 提高多个字段搜索速度的常用技术是在索引时将它们的值复制到单个字段中,然后在搜索时使用该字段。 这可以通过映射的 copy_to 指令来自动化,而无需更改文档的源。 下面是一个包含电影的索引示例,该索引通过将两个值索引到 name_and_plot 字段来优化搜索电影名称和情节的查询。
PUT movies
{"mappings": {"properties": {"name_and_plot": {"type": "text"},"name": {"type": "text","copy_to": "name_and_plot"},"plot": {"type": "text","copy_to": "name_and_plot"}}}
}索引前数据
你应该利用查询中的模式来优化数据索引方式。 例如,如果你的所有文档都有 price 字段,并且大多数查询在固定的范围列表上运行 range 聚合,则可以通过将range 预先索引到索引中并使用 terms 聚合来加快聚合速度。
例如,如果文档如下所示:
PUT index/_doc/1
{"designation": "spoon","price": 13
}搜索请求如下所示:
GET index/_search
{"aggs": {"price_ranges": {"range": {"field": "price","ranges": [{ "to": 10 },{ "from": 10, "to": 100 },{ "from": 100 }]}}}
}然后可以在索引时通过 price_range 字段来丰富文档,该字段应该映射为 keyword:
PUT index
{"mappings": {"properties": {"price_range": {"type": "keyword"}}}
}PUT index/_doc/1
{"designation": "spoon","price": 13,"price_range": "10-100"
}然后搜索请求可以聚合这个新字段,而不是在 price 字段上运行 range 聚合。
GET index/_search
{"aggs": {"price_ranges": {"terms": {"field": "price_range"}}}
}考虑将映射标识符作为关键字
并非所有数值数据都应映射为 numeric 字段数据类型。 Elasticsearch 优化 range 查询的数字字段,例如 integer 或 long。 但是,keyword 字段更适合 term 和其他term-level查询。
ISBN 或产品 ID 等标识符很少在 range 查询中使用。 然而,它们通常是使用 term-level 级查询来检索的。
如果出现以下情况,请考虑将数字标识符映射为 keyword:
- 你不打算使用 range 查询来搜索标识符数据。
- 快速检索很重要。 keyword 字段上的 term 查询搜索通常比数字字段上的术语搜索更快。
如果你不确定使用哪个,可以使用 multi-field 将数据映射为 keyword 和数字数据类型。
避免脚本
如果可能,请避免使用基于脚本的排序、聚合中的脚本和 script_score 查询。 请参阅 Scripts、caching 和 search speed。
搜索四舍五入的日期
对使用 now 的日期字段的查询通常不可缓存,因为匹配的范围一直在变化。 然而,就用户体验而言,切换到四舍五入日期通常是可以接受的,并且具有更好地利用查询缓存的好处。
例如下面的查询:
PUT index/_doc/1
{"my_date": "2016-05-11T16:30:55.328Z"
}GET index/_search
{"query": {"constant_score": {"filter": {"range": {"my_date": {"gte": "now-1h","lte": "now"}}}}}
}可以替换为以下查询:
GET index/_search
{"query": {"constant_score": {"filter": {"range": {"my_date": {"gte": "now-1h/m","lte": "now/m"}}}}}
}在这种情况下,我们四舍五入到分钟,因此如果当前时间是 16:31:29,范围查询将匹配 my_date 字段值在 15:31:00 和 16:31:59 之间的所有内容。 如果多个用户在同一分钟内运行包含此范围的查询,则查询缓存可以帮助加快速度。 用于舍入的间隔越长,查询缓存的帮助就越大,但请注意,过于激进的舍入也可能会损害用户体验。
注意:为了能够利用查询缓存,将范围分割为大的可缓存部分和较小的不可缓存部分可能很诱人,如下所示:
GET index/_search
{"query": {"constant_score": {"filter": {"bool": {"should": [{"range": {"my_date": {"gte": "now-1h","lte": "now-1h/m"}}},{"range": {"my_date": {"gt": "now-1h/m","lt": "now/m"}}},{"range": {"my_date": {"gte": "now/m","lte": "now"}}}]}}}}
}然而,这种做法在某些情况下可能会使查询运行速度变慢,因为 bool 查询引入的开销可能会抵消更好地利用查询缓存所节省的成本。
强制合并只读索引
只读索引可能会受益于合并到单个段。 基于时间的索引通常就是这种情况:只有当前时间范围的索引正在获取新文档,而旧索引是只读的。 已强制合并为单个分段的分片可以使用更简单、更高效的数据结构来执行搜索。
重要:不要强制合并你仍在写入或将来将再次写入的索引。 相反,依靠自动后台合并进程根据需要执行合并,以保持索引平稳运行。 如果你继续写入强制合并索引,那么它的性能可能会变得更糟。
热身全局序数
全局序数(global ordinals)是一种用于优化聚合性能的数据结构。 它们是惰性计算的,并作为字段数据缓存的一部分存储在 JVM 堆中。 对于大量用于分桶聚合的字段,你可以告诉 Elasticsearch 在收到请求之前构建并缓存全局序号。 应该谨慎执行此操作,因为它会增加堆使用量并使刷新时间更长。 通过设置 eager global ordinals 映射参数,可以在现有映射上动态更新该选项:
PUT index
{"mappings": {"properties": {"foo": {"type": "keyword","eager_global_ordinals": true}}}
}预热文件系统缓存
如果运行 Elasticsearch 的机器重新启动,文件系统缓存将为空,因此操作系统需要一些时间才能将索引的热区域加载到内存中,以便搜索操作快速。 你可以使用 index.store.preload 设置显式告诉操作系统哪些文件应根据文件扩展名立即加载到内存中。
警告:如果文件系统缓存不够大,无法容纳所有数据,则在太多索引或太多文件上急切地将数据加载到文件系统缓存中将使搜索速度变慢。 谨慎使用。
使用索引排序来加速连词
索引排序(index sorting)很有用,可以使连接 (conjunctions) 速度更快,但代价是索引速度稍慢。 请在索引排序文档中相关信息。
使用 preference 项来优化缓存利用率
有多种缓存可以帮助提高搜索性能,例如文件系统缓存、请求缓存或查询缓存。 然而,所有这些缓存都是在节点级别维护的,这意味着如果你连续两次运行相同的请求,有 1 个或更多副本并使用默认路由算法 round-robin,那么这两个请求将转到不同的分片副本 ,阻止节点级缓存发挥作用。
由于搜索应用程序的用户通常会相继运行类似的请求,例如为了分析索引的较小子集,因此使用标识当前用户或会话的 preference 项值可以帮助优化缓存的使用。
副本可能有助于提高吞吐量,但并不总是如此
除了提高弹性之外,副本还可以帮助提高吞吐量。 例如,如果你有一个单分片索引和三个节点,则需要将副本数设置为 2,以便总共拥有 3 个分片,以便利用所有节点。
现在假设你有一个 2 分片(2-shard)索引和两个节点。 在一种情况下,副本数为 0,这意味着每个节点拥有一个分片。 在第二种情况下,副本数为 1,这意味着每个节点有两个分片。 哪种设置在搜索性能方面表现最佳? 通常,每个节点总共具有较少分片的设置会表现更好。 原因是它为每个分片提供了更大份额的可用文件系统缓存,并且文件系统缓存可能是 Elasticsearch 的第一大性能因素。 同时,请注意,如果单个节点发生故障,没有副本的设置可能会失败,因此在吞吐量和可用性之间需要进行权衡。
那么正确的副本数量是多少? 如果您的集群总共有 num_nodes 个节点、num_primaries 个主分片,并且你希望能够一次最多处理 max_failures 个节点故障,那么适合你的副本数量是 max(max_failures, ceil(num_nodes / num_primaries) - 1).
使用搜索分析器调整你的查询
Profile API 提供有关查询和聚合的每个组件如何影响处理请求所需时间的详细信息。
Kibana 中的 Search Profiler 可以轻松导航和分析分析结果,并让你深入了解如何调整查询以提高性能并减少负载。
由于 Profile API 本身会显着增加查询开销,因此此信息最好用于了解各种查询组件的相对成本。 它不提供实际处理时间的可靠测量。
使用 index_phrases 加快短语查询速度
Text 字段有一个索引 2-shingles 的 index_phrases 选项,并由查询解析器自动利用来运行没有倾斜的短语查询。 如果你的用例涉及运行大量短语查询,这可以显着加快查询速度。
使用 constant_keyword 来加速过滤
一般规则是过滤器的成本主要是匹配文档数量的函数。 想象一下你有一个包含 cycles 的索引。 自行车 (bicycle) 数量很多,许多搜索都会对 cycle_type: bycycle 进行过滤。 不幸的是,这种非常常见的过滤器也非常昂贵,因为它与大多数文档匹配。 有一种简单的方法可以避免运行此过滤器:将 bycycles 移动到自己的索引并通过搜索此索引来过滤自行车,而不是向查询添加过滤器。
不幸的是,这可能会使客户端逻辑变得棘手,而这正是 constant_keyword 可以发挥作用的地方。 通过将 cycle_type 映射为 constant_keyword,并在包含 bicycles 的索引上使用值 bicycle,客户端可以继续运行与在整体索引上运行完全相同的查询,并且 Elasticsearch 将通过忽略 cycle_type 上的过滤器来对 bicycles 索引执行正确的操作,如果该值是 bycycle,否则不返回任何命中。
映射可能如下所示:
PUT bicycles
{"mappings": {"properties": {"cycle_type": {"type": "constant_keyword","value": "bicycle"},"name": {"type": "text"}}}
}PUT other_cycles
{"mappings": {"properties": {"cycle_type": {"type": "keyword"},"name": {"type": "text"}}}
}我们将索引一分为二:一个仅包含 bicycles,另一个包含其他 cycles:独轮车、三轮车等。然后在搜索时,我们需要搜索这两个索引,但不需要修改查询 。
GET bicycles,other_cycles/_search
{"query": {"bool": {"must": {"match": {"description": "dutch"}},"filter": {"term": {"cycle_type": "bicycle"}}}}
}在 bicycles 索引上,Elasticsearch 将简单地忽略 cycle_type 过滤器并将搜索请求重写为以下请求:
GET bicycles,other_cycles/_search
{"query": {"match": {"description": "dutch"}}
}在 other_cycles 索引上,Elasticsearch 会很快发现 cycle_type 字段的术语字典中不存在 bicycle 并返回没有命中的搜索响应。
通过将通用值放入专用索引中,这是一种降低查询成本的强大方法。 这个想法也可以跨多个领域组合:例如,如果你跟踪每个自行车的颜色并且你的 bicycles 索引最终包含大多数黑色自行车,你可以将其分为 bicycles-black 索引和 bicycles-other-colors 索引 。
此优化并不严格需要 constant_keyword:还可以更新客户端逻辑,以便根据过滤器将查询路由到相关索引。 然而,constant_keyword 使其变得透明,并允许将搜索请求与索引拓扑解耦,以换取很少的开销。