目录
一.项目介绍
二.项目流程详解
2.1.构建网络模型
2.2.数据集处理
2.3.训练模块
2.4.测试模块
三.测试网络
一.项目介绍
EDSR全称Enhanced Deep Residual Networks,是SRResnet的升级版,其对网络结构进行了优化(去除了BN层),省下来的空间可以用于提升模型的size来增强表现力。
为什么要去除BN层:
Batch Norm是深度学习中非常重要的技术,不仅可以使训练更深的网络变容易,加速收敛,还有一定正则化的效果,可以防止模型过拟合。
但对于图像超分辨率来说,网络输出的图像在色彩、对比度、亮度上要求和输入一致,改变的仅仅是分辨率和一些细节,而Batch Norm,对图像来说类似于一种对比度的拉伸,任何图像经过Batch Norm后,其色彩的分布都会被归一化,也就是说,它破坏了图像原本的对比度信息,所以Batch Norm的加入反而影响了网络输出的质量。
网络结构及对比:


移除BN层后,模型更加轻量,BN层所消耗的存储空间等同于上一层CNN层所消耗的,作者指出相比于SRResNet,EDSR去掉BN层之后节约了40%的存储资源。
同时在BN腾出来的空间下插入更多的类似于残差块等CNN-based子网络来增加模型的表现力。
论文地址:
[1707.02921] Enhanced Deep Residual Networks for Single Image Super-Resolution (arxiv.org)![]() https://arxiv.org/abs/1707.02921源码地址:
https://arxiv.org/abs/1707.02921源码地址:
developer0hye/EDAR: PyTorch implementation of Deep Convolution Networks based on EDSR for Compression(Jpeg) Artifacts Reduction (github.com)![]() https://github.com/developer0hye/EDAR
https://github.com/developer0hye/EDAR
二.项目流程详解
2.1.构建网络模型


def default_conv(in_channels, out_channels, kernel_size, bias=True):return nn.Conv2d(in_channels, out_channels, kernel_size,padding=(kernel_size//2), bias=bias)class MeanShift(nn.Conv2d):def __init__(self, rgb_mean, rgb_std, sign=-1):super(MeanShift, self).__init__(3, 3, kernel_size=1)std = torch.Tensor(rgb_std)self.weight.data = torch.eye(3).view(3, 3, 1, 1)self.weight.data.div_(std.view(3, 1, 1, 1))self.bias.data = sign * torch.Tensor(rgb_mean)self.bias.data.div_(std)self.requires_grad = Falseclass ResBlock(nn.Module):def __init__(self, conv, n_feat, kernel_size,bias=True, act=nn.ReLU(True)):super(ResBlock, self).__init__()m = []for i in range(2):m.append(conv(n_feat, n_feat, kernel_size, bias=bias))if i == 0: m.append(act)# m是设置好的conv层# 设置网络内部层次结构为bodyself.body = nn.Sequential(*m)def forward(self, x):# 获取当前的结果res = self.body(x)# 当前得到的网络和最初的网络融合res += xreturn res
class EDAR(nn.Module):def __init__(self, conv=common.default_conv):super(EDAR, self).__init__()# 参数设置n_resblock = 8 # resnet长度n_feats = 64kernel_size = 3 # 卷积核大小#DIV 2K meanrgb_mean = (0.4488, 0.4371, 0.4040)rgb_std = (1.0, 1.0, 1.0)self.sub_mean = common.MeanShift(rgb_mean, rgb_std)# define head module# 经过卷积,特征图数由3->n_featsm_head = [conv(3, n_feats, kernel_size)]# define body module# Residual Block设置m_body = [common.ResBlock(conv, n_feats, kernel_size) for _ in range(n_resblock)]m_body.append(conv(n_feats, n_feats, kernel_size))# define tail module# 经过卷积,特征图数由n_feats->3m_tail = [conv(n_feats, 3, kernel_size)]self.add_mean = common.MeanShift(rgb_mean, rgb_std, 1)# 设置网络的三个层次self.head = nn.Sequential(*m_head)self.body = nn.Sequential(*m_body)self.tail = nn.Sequential(*m_tail)前向传播过程:
def forward(self, x):x = self.sub_mean(x)x = self.head(x)res = self.body(x)res += xx = self.tail(res)x = self.add_mean(x)# 将输入input张量每个元素的范围限制到区间 [min,max],返回结果到一个新张量。# 及输出一个新张量值x,并限制他的值在0~1之间return torch.clamp(x,0.0,1.0)2.2.数据集处理
import os
import io
import random
from PIL import Image
from PIL import ImageFile
ImageFile.LOAD_TRUNCATED_IMAGES = Trueclass Dataset(object):def __init__(self, images_dir, patch_size=48, jpeg_quality=40, transforms=None):self.images = os.walk(images_dir).__next__()[2]self.images_path = []for img_file in self.images:if img_file.endswith((".ppm")):try:#print(os.path.join(images_dir, img_file))label = Image.open(os.path.join(images_dir, img_file))self.images_path.append(os.path.join(images_dir, img_file))except:print(f"Image {os.path.join(images_dir, img_file)} didn't get loaded")self.patch_size = patch_sizeself.jpeg_quality = jpeg_qualityself.transforms = transformsself.random_rotate = [0, 90, 180, 270]def __getitem__(self, idx):label = Image.open(self.images_path[idx]).convert('RGB')label = label.rotate(self.random_rotate[random.randrange(0,4)])# randomly crop patch from training setcrop_x = random.randint(0, label.width - self.patch_size)crop_y = random.randint(0, label.height - self.patch_size)# 使用crop函数对图片进行裁剪label = label.crop((crop_x, crop_y, crop_x + self.patch_size, crop_y + self.patch_size))# additive jpeg noisebuffer = io.BytesIO()label.save(buffer, format='jpeg', quality=random.randrange(self.jpeg_quality+1))input = Image.open(buffer).convert('RGB')if self.transforms is not None:input = self.transforms(input)label = self.transforms(label)#print("Image transformed")return input, labeldef __len__(self):return len(self.images_path)
2.3.训练模块
import argparse
import osfrom dataset import Dataset
from edar import EDARimport torch
from torch import nn
from torch.utils.data.dataloader import DataLoader
import torch.backends.cudnn as cudnn
import torch.optim as optim
from torchvision import transforms
from torchvision.models.vgg import vgg16from utils import AverageMeter
from tqdm import tqdmif __name__ == '__main__':'''It enables benchmark mode in cudnn.benchmark mode is good whenever your input sizes for your network do not vary. This way, cudnn will look for the optimal set of algorithms for that particular configuration (which takes some time). This usually leads to faster runtime.But if your input sizes changes at each iteration, then cudnn will benchmark every time a new size appears, possibly leading to worse runtime performances.'''cudnn.benchmark = Truedevice = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")# 参数设置parser = argparse.ArgumentParser()# required为true的参数则是必须要设置的参数parser.add_argument('--images_dir', type=str, required=True)parser.add_argument('--outputs_dir', type=str, required=True)parser.add_argument('--jpeg_quality', type=int, default=40)parser.add_argument('--patch_size', type=int, default=48)parser.add_argument('--batch_size', type=int, default=16)parser.add_argument('--num_epochs', type=int, default=400)parser.add_argument('--lr', type=float, default=1e-4)parser.add_argument('--threads', type=int, default=1)parser.add_argument('--seed', type=int, default=123)parser.add_argument('--resume', default='', type=str, metavar='PATH',help='path to latest checkpoint (default: none)')opt = parser.parse_args()# 如果输出文件夹不存在,则自动创建一个文件夹if not os.path.exists(opt.outputs_dir):os.makedirs(opt.outputs_dir)torch.manual_seed(opt.seed)transforms_train = transforms.Compose([transforms.ToTensor()])# 模型设置model = EDAR().to(device)print("Model loaded")if opt.resume:if os.path.isfile(opt.resume):state_dict = model.state_dict()for n, p in torch.load(opt.resume, map_location=lambda storage, loc: storage).items():if n in state_dict.keys():state_dict[n].copy_(p)else:raise KeyError(n)# 损失函数设置criterion = nn.L1Loss()# 优化器设置optimizer = optim.Adam(model.parameters(), lr=opt.lr)print("Data processing started")# 数据集设置dataset = Dataset(opt.images_dir, opt.patch_size, opt.jpeg_quality,transforms=transforms_train)dataloader = DataLoader(dataset=dataset,batch_size=opt.batch_size,shuffle=True,num_workers=opt.threads,pin_memory=True,drop_last=True)print("Data loading completed")#vgg = vgg16(pretrained=True).cuda()#loss_network = nn.Sequential(*list(vgg.features)[:31]).eval()
# for param in loss_network.parameters():
# param.requires_grad = False# 开始训练for epoch in range(opt.num_epochs):epoch_losses = AverageMeter()print("Length of the dataset is", len(dataset))with tqdm(total=(len(dataset) - len(dataset) % opt.batch_size)) as _tqdm:_tqdm.set_description('epoch: {}/{}'.format(epoch + 1, opt.num_epochs))# 按照dataloader的格式取出datafor data in dataloader:inputs, labels = datainputs = inputs.to(device)labels = labels.to(device)#print(inputs.size(), labels.size())outs = model(inputs)# 损失值计算,参数是预测值和实际值loss = criterion(outs, labels)#perception_loss = criterion(loss_network(outs), loss_network(labels))#loss = loss + perception_loss*0.06epoch_losses.update(loss.item(), len(inputs))# 梯度清零optimizer.zero_grad()# 反向传播loss.backward()# 更新参数optimizer.step()_tqdm.set_postfix(loss='{:.6f}'.format(epoch_losses.avg))_tqdm.update(len(inputs))torch.save(model.state_dict(), os.path.join(opt.outputs_dir, '{}_epoch_{}.pth'.format("EDAR_", epoch)))2.4.测试模块
import argparse
import os
import io
import torch
import torch.backends.cudnn as cudnn
from torchvision import transforms
import PIL.Image as pil_image
import globfrom edar import EDARcudnn.benchmark = True
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")if __name__ == '__main__':# 参数设置parser = argparse.ArgumentParser()parser.add_argument('--weights_path', type=str, required=True)parser.add_argument('--image_path', type=str, required=True)parser.add_argument('--outputs_dir', type=str, required=True)parser.add_argument('--jpeg_quality', type=int, default=40)parser.add_argument('--input_dir', type=str, required=False)opt, unknown = parser.parse_known_args()model = EDAR()state_dict = model.state_dict()# 参数获取for n, p in torch.load(opt.weights_path, map_location=lambda storage, loc: storage).items():if n in state_dict.keys():state_dict[n].copy_(p)else:raise KeyError(n)model = model.to(device)print(device)model.eval()if opt.input_dir:filenames = [os.path.join(opt.input_dir, file) for file in os.listdir(opt.input_dir) if file.endswith(("ppm", "jpeg", "png", "jpg"))]print(filenames)else:filenames = opt.image_pathif not os.path.exists(opt.outputs_dir):os.makedirs(opt.outputs_dir)# 处理单个测试图片时使用:filename = filenamesprint("file is", filename)input = pil_image.open(filename).convert('RGB')print("Input size:", input.size)print("file is", filename)input = pil_image.open(filename).convert('RGB')print("Input size:", input.size)#buffer = io.BytesIO()#input.save(buffer, format='jpeg', quality=opt.jpeg_quality)#input = pil_image.open(buffer)#input.save(os.path.join(opt.outputs_dir, '{}_jpeg_q{}.png'.format(filename, opt.jpeg_quality)))input = transforms.ToTensor()(input).unsqueeze(0).to(device)output_path = os.path.join(opt.outputs_dir, '{}-{}.jpeg'.format(filename.split("/")[-1].split(".")[0], "edar"))if not os.path.exists(output_path):with torch.no_grad():pred = model(input)[-1]pred = pred.mul_(255.0).clamp_(0.0, 255.0).squeeze(0).permute(1, 2, 0).byte().cpu().numpy()output = pil_image.fromarray(pred, mode='RGB')print("Output size", output.size)print("Output dir is", opt.outputs_dir)output.save(output_path)#print(os.path.join(opt.outputs_dir, '{}_{}.png'.format(filename, "EDAR")))#print("Output saved")'''处理多个测试图片时使用:for filename in filenames:print("file is", filename)input = pil_image.open(filename).convert('RGB')print("Input size:", input.size)# buffer = io.BytesIO()# input.save(buffer, format='jpeg', quality=opt.jpeg_quality)# input = pil_image.open(buffer)# input.save(os.path.join(opt.outputs_dir, '{}_jpeg_q{}.png'.format(filename, opt.jpeg_quality)))input = transforms.ToTensor()(input).unsqueeze(0).to(device)output_path = os.path.join(opt.outputs_dir, '{}-{}.jpeg'.format(filename.split("/")[-1].split(".")[0], "edar"))if not os.path.exists(output_path):with torch.no_grad():pred = model(input)[-1]pred = pred.mul_(255.0).clamp_(0.0, 255.0).squeeze(0).permute(1, 2, 0).byte().cpu().numpy()output = pil_image.fromarray(pred, mode='RGB')print("Output size", output.size)print("Output dir is", opt.outputs_dir)output.save(output_path)# print(os.path.join(opt.outputs_dir, '{}_{}.png'.format(filename, "EDAR")))# print("Output saved")'''三.测试网络
参数设置:
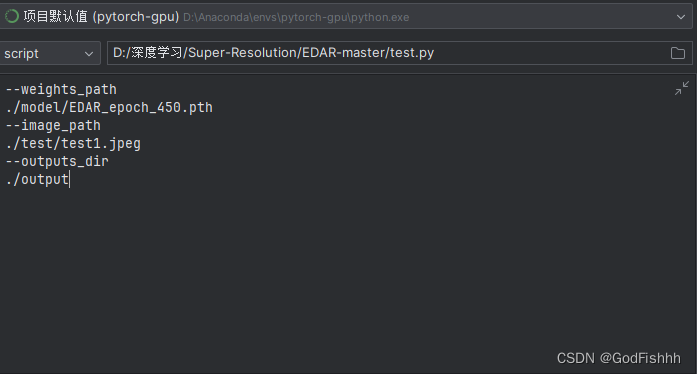
输入图片:

输出图片:

输入图片:

输出图片:



![使用ChatGPT高效完成简历制作[中篇]-有爱AI实战教程(五)](https://img-blog.csdnimg.cn/direct/62a31875744f41368b9da06a6c04736a.png)