一日读书一日功,一日不读十日空
书中自有颜如玉,书中自有黄金屋
一、双链表
1、双链表的结构
2、双链表的实现
1)、双向链表中节点的结构定义
2)、初始化函数 LTInit
3)、尾插函数 LTPushBack
4)、头插函数 LTPushFront
5)、尾删函数 LTPopBack
6)、头删函数 LTPopFront
7)、查找函数 LTFind
8)、在指定位置之后插入数据函数 LTInsert
9)、删除指定位置数据函数 LTErase
10)、销毁函数 LTDesTroy
二、双链表完整代码
三、顺序表和链表的优缺点对比
四、完结撒❀
前言
学习前先思考3个问题:
| 1.顺序表和链表的关系是什么? | |
|---|---|
| 2.链表的分类有哪些? | |
| 3.顺序表和链表的优缺点有哪些? |
–❀–❀–❀–❀–❀–❀–❀–❀–❀–❀–❀–❀–❀–❀–❀–❀–❀–❀–❀–❀–❀–❀–❀–❀–❀–❀–❀–❀–❀–
1.顺序表和链表的关系是什么
我们之前学习了“顺序表”,“单链表”。
链表和顺序表都是线性表。
线性表是指
逻辑结构:一定是线性的。
物理结构:不一定是线性的。
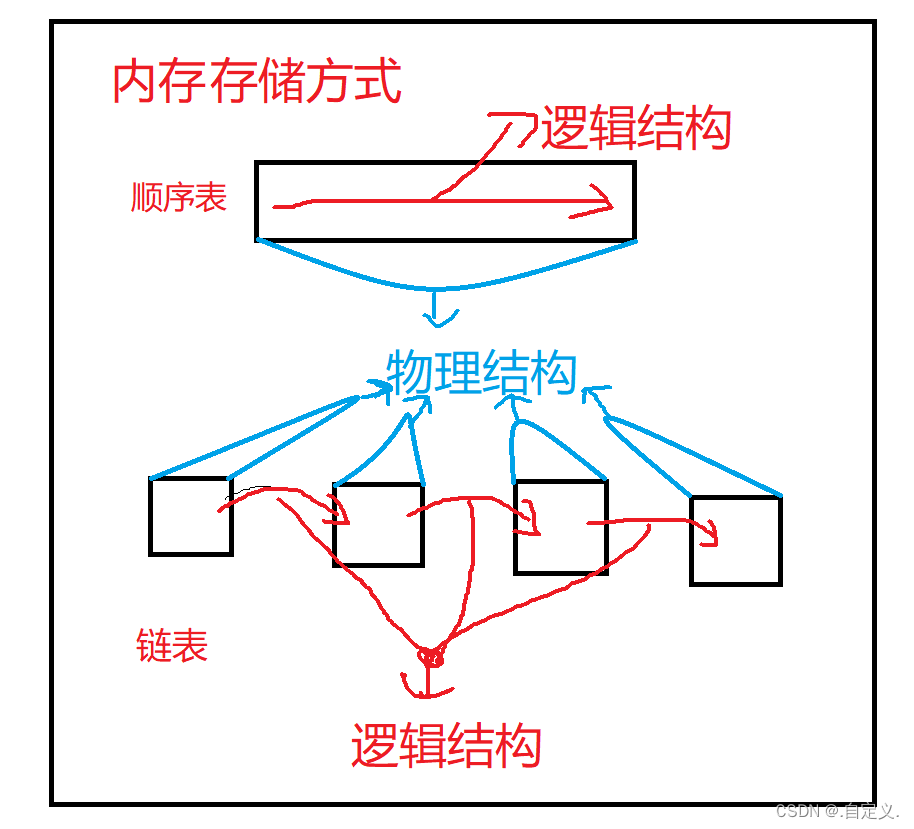 物理结构是指表在内存中开辟的空间结构,顺序表的物理结构是连续的,而链表的物理结构是不连续的,但它们的逻辑结构都是连续的。
物理结构是指表在内存中开辟的空间结构,顺序表的物理结构是连续的,而链表的物理结构是不连续的,但它们的逻辑结构都是连续的。
2.链表的分类有哪些?
链表根据带头或者不带头,单向或者双向,循环或者不循环一共分为8种。
我们之前所学的单链表全名是叫:不带头单向不循环链表,而现在要学习的双链表是叫带头双向循环链表。
双链表:
 掌握单链表和双链表对于其他链表的实现也就不那么困难了。
掌握单链表和双链表对于其他链表的实现也就不那么困难了。
3.顺序表和链表的优缺点有哪些?
这里涉及到顺序表和链表的对比,先讲解双向链表,这放到博客末尾为大家对比讲解
一、双链表
1、双链表的结构
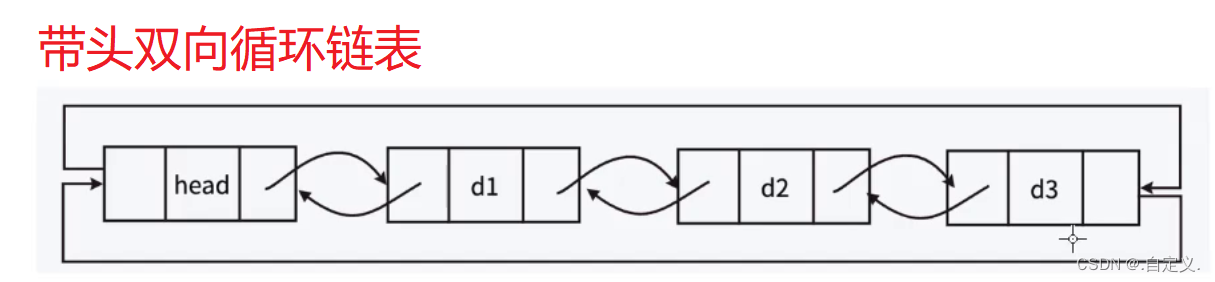 注意:这里的“带头”跟前面我们说的“头节点”是两个概念。
注意:这里的“带头”跟前面我们说的“头节点”是两个概念。
带有节点里的头节点实际为“哨兵位”,哨兵位节点不存储任何有效元素,只是站在这里“放哨的”
“哨兵位”存在的意义:
遍历循环链表避免出现死循环。
2、双链表的实现
对于双向链表的实现,我们依然使用List.h,List.c,test.c,三个文件进行实现。
1)、双向链表中节点的结构定义
上面我们简单介绍过双链表,其全名为:带头双向循环链表。
带头:指链表中带有哨兵位。
双向:双链表的每个节点内含有两个链表指针变量,分别指向前一个节点和后一个节点,所以就可以通过一个节点找到这个节点前后的两个节点。
循环:链表中的每个节点互相连接,最后一个节点与哨兵位相连构成一个环,整体逻辑结构可以进行循环操作。
代码如下:
//定义双向链表中节点的结构
typedef int LTDataType;
typedef struct ListNode
{struct ListNode* prev;LTDataType data;struct ListNode* next;
}LTNode;
这里将结构体进行了重命名为LTNode。
2)、初始化函数 LTInit
在创建双链表中的哨兵位时我们需要对其进行初始化,防止意料之外的情况发生。
根据所传形参的类型不同,我们有两种写法
代码如下:
方案1
//方案1
void LTInit(LTNode** pphead)
{(*pphead) = (LTNode*)malloc(sizeof(LTNode));if (*pphead == NULL){perror("mallic:");exit(1);}(*pphead)->data = -1;(*pphead)->prev = (*pphead)->next = *pphead;
}
方案2
LTNode* LTBuyNode(LTDataType x)
{LTNode* newnode = (LTNode*)malloc(sizeof(LTNode));if (newnode == NULL){perror("malloc:");exit(1);}newnode->data = x;newnode->next = newnode->prev = newnode;return newnode;
}//方案2
LTNode* LTInit()
{LTNode* phead = LTBuyNode(-1);return phead;
}
方案2里面包含了节点空间申请的函数,只是简单的创建双链表的节点,这里就不展开讲解了。
3)、尾插函数 LTPushBack
老规矩,我们开始实现管理链表数据的函数,这里讲的是头插。
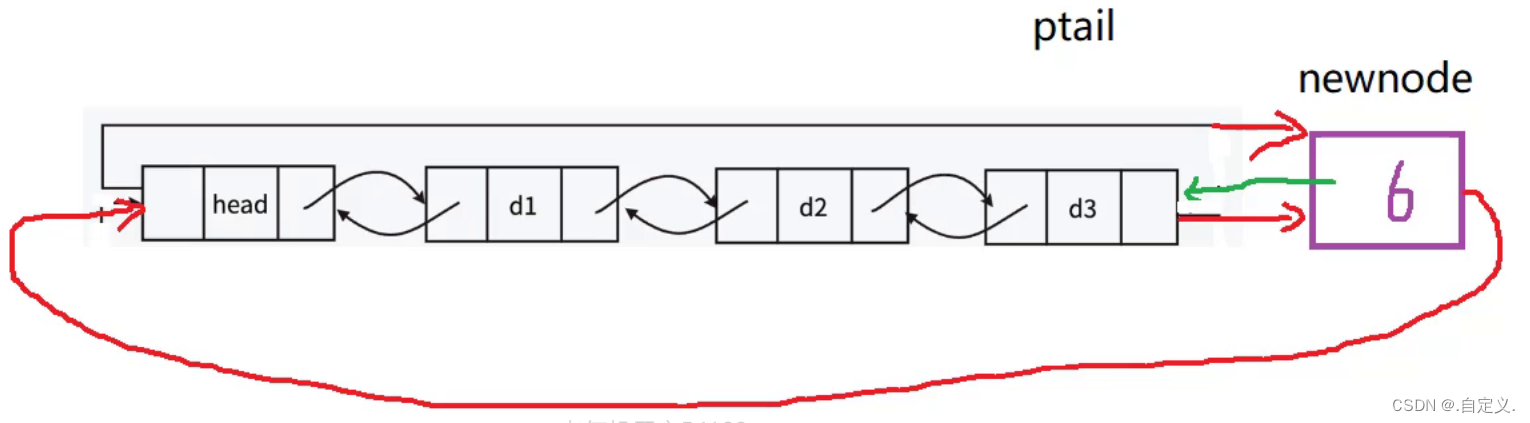 假如我们要在链表中尾插一个6,那么我们是需要先创建一个节点来存储6,下面分两步:
假如我们要在链表中尾插一个6,那么我们是需要先创建一个节点来存储6,下面分两步:
1.将6的节点里面前(prev)后(next)链表指针变量对应与原链表的尾节点d3和哨兵位head进行连接
2.将原链表尾节点d3的后链表指针变量(next)指向6的节点,再将哨兵位head的前链表指针变量(prev)指向6的节点
完成上面两部就实现了节点的插入。
代码如下:
//尾插
void LTPushBack(LTNode* phead, LTDataType x)
{assert(phead);LTNode* newnode = LTBuyNode(x);newnode->prev = phead->prev;newnode->next = phead;phead->prev->next = newnode;phead->prev = newnode;
}
这里的LTBuyNode函数在初始化函数中提到过。
4)、头插函数 LTPushFront
实现了尾插,头插也是大同小异。
头插是指在哨兵位后面的进行插入,第一个有效节点之前插入,即为头插。
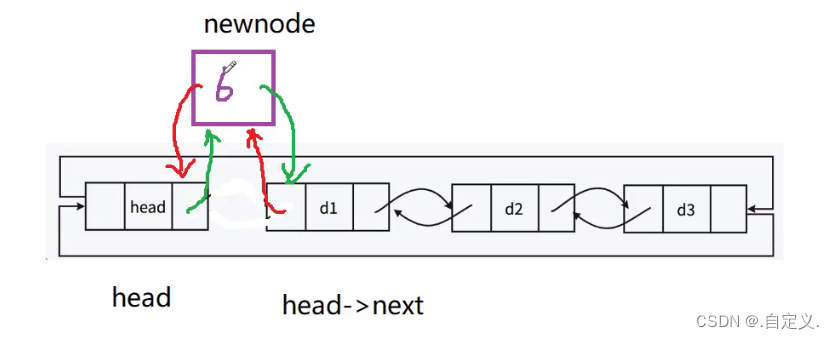 根据上图,进行头插
根据上图,进行头插
1.改变插入节点6的前后链表指针变量的指向。
2.再分别改变哨兵位head后链表指针变量(next)和第一个有效节点d1的前链表指针变量(prev)的指向。
代码如下:
//头插
void LTPushFront(LTNode* phead, LTDataType x)
{assert(phead);LTNode* newnode = LTBuyNode(x);newnode->next = phead->next;newnode->prev = phead;phead->next->prev = newnode;phead->next = newnode;
}
也是简简单单。
5)、尾删函数 LTPopBack
尾删函数的操作如下图:

1.改变哨兵位的前链表指针变量,指向原链表(还没尾删时的链表)尾节点d3的前链表指针变量(即倒数第二个节点d2的地址)。
2.相反,再将d2节点的后链表指针变量(next)指向哨兵位head。
代码如下:
//尾删
void LTPopBack(LTNode* phead)
{assert(phead);//链表只有一个哨兵位也不行assert(phead != phead->next);LTNode* del = phead->prev;//要进行尾删的节点LTNode* ddel = del->prev;//要进行删除的前一节点phead->prev = ddel;ddel->next = phead;free(del);del = NULL;
}
记得最后将尾删的节点空间进行释放。
6)、头删函数 LTPopFront
头删函数的操作如下图:
 与尾删也是大同小异
与尾删也是大同小异
代码如下:
//头删 在哨兵位之后进行删除
void LTPopFront(LTNode* phead)
{assert(phead);assert(phead != phead->next);LTNode* del = phead->next;//要进行删除的节点LTNode* ddel = del->next;//要进行删除节点的下一个节点phead->next = ddel;ddel->prev = phead;free(del);del = NULL;
}
7)、查找函数 LTFind
既然要查找,那么肯定需要遍历链表并且也要保证链表不为空。
在双链表中,当链表中只剩下哨兵位,那么这个链表即为空链表。
代码如下:
//查找
LTNode* LTFind(LTNode* phead, LTDataType x)
{assert(phead);assert(phead != phead->next);//遍历链表LTNode* pcur = phead->next;while (pcur != phead){if (pcur->data == x){return pcur;}pcur = pcur->next;}return NULL;
}
断言时进行的assert(phead != phead->next);便是判断链表是否为空的条件。
而while (pcur != phead)是判断是否将链表遍历完的条件。
找到的话就返回给节点的地址,没有找到就返回空指针。
8)、在指定位置之后插入数据函数 LTInsert
操作过程如下图所示:
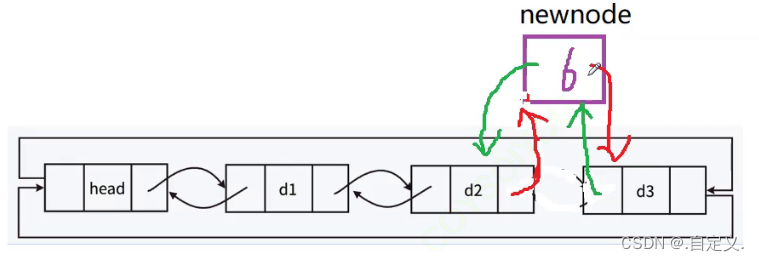 假设我们在节点d2后面进行节点的插入,那么会受到影响的就是d2节点的后链表指针变量(next)和d3节点的前链表指针变量(prev),需要执行的操作:
假设我们在节点d2后面进行节点的插入,那么会受到影响的就是d2节点的后链表指针变量(next)和d3节点的前链表指针变量(prev),需要执行的操作:
1.将newnode节点的前链表指针变量(prev)指向d2节点,再将newnode节点的后链表指针变量(next)指向d3节点
2.将d3节点的前链表指针变量(prev)指向newnode’节点,再将d2节点的后链表指针变量(next)指向newnode节点。
注意! 第2步指针变量改变指向的先后顺序不能改变,不然指向地址不正确!
代码如下;
//删除pos位置的数据
void LTErase(LTNode* pos)
{assert(pos);LTNode* del = pos->next;//pos之后的数据LTNode* front = pos->prev;//pos之前的数据front->next = del;del->prev = front;free(pos);pos = NULL;
}
9)、删除指定位置数据函数 LTErase
操作过程如下图所示:
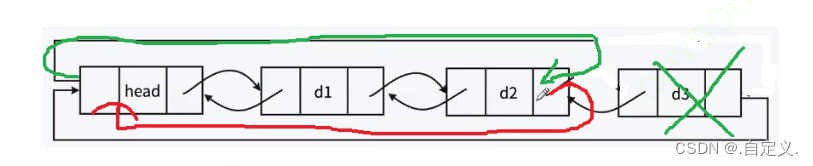 假设删除d3节点,很明显这就是尾删操作,所以删除指定位置数据与其他删除函数也是一样的原理,其影响到的就是删除节点前后的节点链表指针的指向。
假设删除d3节点,很明显这就是尾删操作,所以删除指定位置数据与其他删除函数也是一样的原理,其影响到的就是删除节点前后的节点链表指针的指向。
代码如下:
//删除pos位置的数据
void LTErase(LTNode* pos)
{assert(pos);LTNode* del = pos->next;//pos之后的数据LTNode* front = pos->prev;//pos之前的数据front->next = del;del->prev = front;free(pos);pos = NULL;
}
重要的是最在要记得将删除的节点空间进行销毁。
10)、销毁函数 LTDesTroy
那么最后的一个函数,销毁函数。
创建双建表使用后我们一定不要忘记进行销毁,将开辟的内存空间归还给计算机,不然在以后中可能会出现内存泄漏的工作事故。
销毁函数也根据传参类型不同有两种方案
代码如下:
方案1
//方案1
void LTDesTroy(LTNode* phead)
{assert(phead);assert(phead != phead->next);LTNode* pcur = phead->next;while (pcur != phead){LTNode* next = pcur->next;free(pcur);pcur = next;}
}
方案2
//方案2
void LTDesTroy(LTNode** pphead)
{assert(pphead);assert(*pphead);LTNode* pcur = (*pphead)->next;while (pcur != (*pphead)){LTNode* next = pcur->next;free(pcur);pcur = next;}free((*pphead));(*pphead) = NULL;
}
对比之下方案1所传的形参为一级指针,而方案2为二级指针,因此我们是可以在方案2中直接对形参解引用得到双链表的哨兵位进行释放,而方案1并不行。
所以大家评判一下是那种方案更好呢?
其实是方案1更好,因为我们需要保持接口一致性,细心的同学可能已经发现了,之前所写的函数形参都为一级指针,所以我们在写代码的时候保持接口一致性也是很重要的,所以方案1更合适一些,至于链表中哨兵位的释放,我们下面在销毁函数外(主函数内)进行销毁即可。
二、双链表完整代码
List.h:
#define _CRT_SECURE_NO_WARNINGS 1
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>//定义双向链表中节点的结构
typedef int LTDataType;
typedef struct ListNode
{struct ListNode* prev;LTDataType data;struct ListNode* next;
}LTNode;//注意双向链表是带有哨兵位的,插入数据之前链表中必须先插入一个哨兵位//void LTInit(LTNode** pphead);
LTNode* LTInit();
void LTDesTroy();//尾插
void LTPushBack(LTNode* phead, LTDataType x);//头插
void LTPushFront(LTNode* phead, LTDataType x);//尾删
void LTPopBack(LTNode* phead);
//头删
void LTPopFront(LTNode* phead);//查找
LTNode* LTFind(LTNode* phead,LTDataType x);//在pos位置之后插入数据
void LTInsert(LTNode* pos, LTDataType x);
//删除pos位置的数据
void LTErase(LTNode* pos);
List.c:
newnode->data = x;newnode->next = newnode->prev = newnode;return newnode;
}//方案1
//void LTInit(LTNode** pphead)
//{
// (*pphead) = (LTNode*)malloc(sizeof(LTNode));
// if (*pphead == NULL)
// {
// perror("mallic:");
// exit(1);
// }
//
// (*pphead)->data = -1;
// (*pphead)->prev = (*pphead)->next = *pphead;
//}//方案2
LTNode* LTInit()
{LTNode* phead = LTBuyNode(-1);return phead;
}//尾插
void LTPushBack(LTNode* phead, LTDataType x)
{assert(phead);LTNode* newnode = LTBuyNode(x);newnode->prev = phead->prev;newnode->next = phead;phead->prev->next = newnode;phead->prev = newnode;
}void LTPrint(LTNode* phead)
{assert(phead);LTNode* pcur = phead->next;while (pcur != phead){printf("%d->", pcur->data);pcur = pcur->next;}printf("\n");
}//头插
void LTPushFront(LTNode* phead, LTDataType x)
{assert(phead);LTNode* newnode = LTBuyNode(x);newnode->next = phead->next;newnode->prev = phead;phead->next->prev = newnode;phead->next = newnode;
}//尾删
void LTPopBack(LTNode* phead)
{assert(phead);//链表只有一个哨兵位也不行assert(phead != phead->next);LTNode* del = phead->prev;//要进行尾删的节点LTNode* ddel = del->prev;//要进行删除的前一节点phead->prev = ddel;ddel->next = phead;free(del);del = NULL;
}//头删 在哨兵位之后进行删除
void LTPopFront(LTNode* phead)
{assert(phead);assert(phead != phead->next);LTNode* del = phead->next;//要进行删除的节点LTNode* ddel = del->next;//要进行删除节点的下一个节点phead->next = ddel;ddel->prev = phead;free(del);del = NULL;
}//查找
LTNode* LTFind(LTNode* phead, LTDataType x)
{assert(phead);assert(phead != phead->next);//遍历链表LTNode* pcur = phead->next;while (pcur != phead){if (pcur->data == x){return pcur;}pcur = pcur->next;}return NULL;
}//删除pos位置的数据
void LTErase(LTNode* pos)
{assert(pos);LTNode* del = pos->next;//pos之后的数据LTNode* front = pos->prev;//pos之前的数据front->next = del;del->prev = front;free(pos);pos = NULL;
}//方案1
void LTDesTroy(LTNode* phead)
{assert(phead);assert(phead != phead->next);LTNode* pcur = phead->next;while (pcur != phead){LTNode* next = pcur->next;free(pcur);pcur = next;}
}//方案2
//void LTDesTroy(LTNode** pphead)
//{
// assert(pphead);
// assert(*pphead);
//
// LTNode* pcur = (*pphead)->next;
// while (pcur != (*pphead))
// {
// LTNode* next = pcur->next;
// free(pcur);
// pcur = next;
// }
// free((*pphead));
// (*pphead) = NULL;
//}
三、顺序表和链表的优缺点对比
学到这里大家会感觉双链表听起来可能比较复杂,但学完之后感觉比顺序表和单链表还容易,事实就是如此。
顺序表和双向链表优缺点分析:
 由上图,并不是双链表一定比顺序表好。
由上图,并不是双链表一定比顺序表好。
顺序表和双链表各有优势,我们在使用中要根据实际情况选择适合的线性表进行存储就是最好的。
四、完结撒❀
如果以上内容对你有帮助不妨点赞支持一下,以后还会分享更多计算机知识,我们一起进步。
最后我想讲的是,据说点赞的都能找到漂亮女朋友