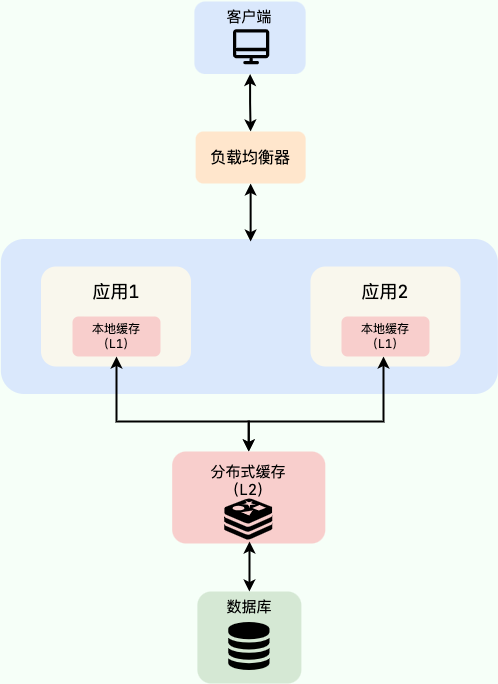
欢迎来到本系列的第二篇文章,我们将从头开始构建一个深度学习库。
本博客系列的代码可以在这个Github仓库中找到。
上一篇文章
在上一篇文章中(链接见这里),我们实现了线性层和常见的激活函数,并成功构建了神经网络的前向传递。
到目前为止,我们的模型只能进行预测,但没有能力训练和纠正其预测。这正是我们今天要讲解的内容,通过实现一个称为反向传播的过程。
反向传播的工作概述
当神经网络进行训练时,它会被给定一个包含输入及其对应输出的数据集。
网络会根据数据集的输入产生预测,并计算其预测与数据集中给出的真实输出之间的偏差(这称为损失)。
训练神经网络的目标是最小化这个损失。
在计算出损失后,网络的权重和偏差会以某种方式进行调整,以减少损失值。记住在上一篇文章中提到,权重和偏差是我们可调节的网络参数,用于计算网络输出。
这个过程会重复数次,希望每次重复时损失都会减少。每次重复被称为一个时代(epoch)。
损失函数
虽然有许多不同的损失函数,但在这篇文章中,我们只会关注均方误差函数。未来的文章中会讨论更多损失函数。
损失函数接收网络的原始错误(通过预测输出 - 实际输出计算得出)并产生一个关于错误严重程度的度量。
均方误差(MSE)接收错误向量,并返回向量中所有平方值的平均值。
例如…
Network output: [1, 2, 3]
Actual outputs: [3, 2, 1]
Error: [-2, 0, 2]
Loss: 2.6666666 ( ( (-2)**2 + (0)**2 + (2)**2 ) / 3 )
在计算平均值之前先对误差进行平方的原因是为了使误差向量中的负值与正值同等对待(因为负数的平方是正数)。
下面是我们的Python类,用于实现均方误差(MSE)…
#loss.pyimport numpy as npclass MSE:def __call__(self, pred, y):self.error = pred - yreturn np.mean(self.error ** 2)
反向传播
反向传播是网络的训练过程。
神经网络训练的目标是最小化损失。
这可以被视为一个优化问题,其解决方案在很大程度上依赖于微积分——更具体地说,是微分。
计算梯度
反向传播的第一步是找到网络中所有权重和偏差相对于损失函数的梯度。
我们用一个例子来演示…
我们的小型示例网络由以下部分组成:
- 线性层
- Sigmoid层
所以整个网络的输出计算如下:
x- 网络输入w- 线性层的权重b- 线性层的偏差a- 线性层输出pred- 网络输出 / Sigmoid输出
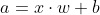
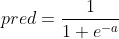
现在让我们计算损失
y- 对于输入x的期望输出
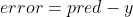
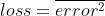
现在我们需要找到相对于损失的权重/偏差的梯度。
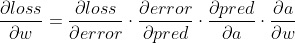
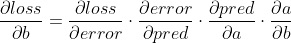
这一步使用了链式法则。
我们现在已经计算出了参数相对于损失的梯度。
计算某一层相对于损失的权重/偏差梯度的一般规则是:
- 对每一层的输出相对于其输入进行微分(从最后一层开始,直到达到你想要调整参数的那一层)
- 将所有这些结果相乘,称之为
grad - 一旦到达所需的层,对其输出相对于其权重进行微分(称这个为
w_grad),并对其偏差进行微分(称这个为b_grad)。 - 将
w_grad和grad相乘以获得相对于该层权重的损失梯度。对b_grad做同样的操作,以获得相对于该层偏差的损失梯度。
有了这个思路,下面是我们所有层和MSE的代码。
#loss.pyimport numpy as npclass MSE:def __call__(self, pred, y):self.error = pred - yreturn np.mean(self.error ** 2)def backward(self):return 2 * (1 / self.error.shape[-1]) * self.error
#layers.pyimport numpy as npclass Activation:def __init__(self):passclass Layer:def __init__(self):passclass Model: def __init__(self, layers):self.layers = layersdef __call__(self, x):output = xfor layer in self.layers:output = layer(output)return outputclass Linear(Layer):def __init__(self, units):self.units = unitsself.initialized = Falsedef __call__(self, x):self.input = xif not self.initialized:self.w = np.random.rand(self.input.shape[-1], self.units)self.b = np.random.rand(self.units)self.initialized = Truereturn self.input @ self.w + self.bdef backward(self, grad):self.w_gradient = self.input.T @ gradself.b_gradient = np.sum(grad, axis=0)return grad @ self.w.Tclass Sigmoid(Activation):def __call__(self, x):self.output = 1 / (1 + np.exp(-x))return self.outputdef backward(self, grad):return grad * (self.output * (1 - self.output))class Relu(Activation):def __call__(self, x):self.output = np.maximum(0, x) return self.outputdef backward(self, grad):return grad * np.clip(self.output, 0, 1)class Softmax(Activation):def __call__(self, x):exps = np.exp(x - np.max(x))self.output = exps / np.sum(exps, axis=1, keepdims=True)return self.outputdef backward(self, grad):m, n = self.output.shapep = self.outputtensor1 = np.einsum('ij,ik->ijk', p, p)tensor2 = np.einsum('ij,jk->ijk', p, np.eye(n, n))dSoftmax = tensor2 - tensor1dz = np.einsum('ijk,ik->ij', dSoftmax, grad) return dzclass Tanh(Activation):def __call__(self, x):self.output = np.tanh(x)return self.outputdef backward(self, grad):return grad * (1 - self.output ** 2)
每个类中的 backward 方法是一个函数,用于对层的输出相对于其输入进行微分。
随意查阅每个激活函数的导数,这将使代码更加易于理解。
线性层的 backward 函数不同,因为它不仅计算了输出相对于输入的梯度,还计算了相对于其参数的梯度。
注意
矩阵乘法的微分规则如下,其中 x 和 y 是被相乘的矩阵。
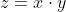
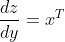
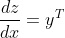
使用随机梯度下降优化参数
优化网络参数的方法有很多,但在这篇文章中,我们将介绍最基本的方法,即随机梯度下降(SGD)。
SGD非常简单。它将每个参数计算出的梯度乘以一个指定的学习率。然后,相应的参数减去这个结果。
使用学习率的原因是为了控制网络学习的速度。
最佳学习率值在少量的时代内最小化成本。
过小的学习率也能最小化成本,但需要经过多个时代,因此会花费时间。
过大的学习率会使损失逼近一个非最小值,因此网络无法正确训练。
下面是MSE的代码。
#optim.pyimport layers
import tqdm
#Tqdm是一个进度条,所以我们可以看到代码运行的进度class SGD:def __init__(self, lr = 0.01):self.lr = lrdef __call__(self, model, loss):grad = loss.backward()for layer in tqdm.tqdm(model.layers[::-1]):grad = layer.backward(grad) #计算图层参数梯度if isinstance(layer, layers.Layer):layer.w -= layer.w_gradient * self.lrlayer.b -= layer.b_gradient * self.lr
随着网络训练所需的一切都已准备就绪,我们可以在我们的模型中添加一个训练函数。
#layers.pyimport numpy as np
import loss
import optim
np.random.seed(0)#...class Model: def __init__(self, layers):self.layers = layersdef __call__(self, x):output = xfor layer in self.layers:output = layer(output)return outputdef train(self, x, y, optim = optim.SGD(), loss=loss.MSE(), epochs=10):for epoch in range(1, epochs + 1):pred = self.__call__(x)l = loss(pred, y)optim(self, loss)print (f"epoch {epoch} loss {l}")#...
测试一下!
我们将构建并训练一个神经网络,使其能够作为异或门(XOR gate)。
异或门接收两个输入。输入可以是 0 或 1(代表假或真)。
如果两个输入相同,则门输出 0。
如果两个输入不同,则门输出 1。
#main.pyimport layers
import loss
import optim
import numpy as npx = np.array([[0, 1], [0, 0], [1, 1], [0, 1]])
y = np.array([[1],[0],[0], [1]]) net = layers.Model([layers.Linear(8),layers.Relu(),layers.Linear(4),layers.Sigmoid(),layers.Linear(1),layers.Sigmoid()
])net.train(x, y, optim=optim.SGD(lr=0.6), loss=loss.MSE(), epochs=400)print (net(x))`` Output ... epoch 390 loss 0.0011290060124405485 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 6/6 [00:00<?, ?it/s] epoch 391 loss 0.0011240809175767955 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 6/6 [00:00<?, ?it/s] epoch 392 loss 0.0011191976855805586 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 6/6 [00:00<?, ?it/s] epoch 393 loss 0.0011143557916784605 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 6/6 [00:00<?, ?it/s] epoch 394 loss 0.0011095547197546522 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 6/6 [00:00<?, ?it/s] epoch 395 loss 0.00110479396217416 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 6/6 [00:00<?, ?it/s] epoch 396 loss 0.0011000730196106248 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 6/6 [00:00<?, ?it/s] epoch 397 loss 0.0010953914008780786 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 6/6 [00:00<?, ?it/s] epoch 398 loss 0.0010907486227668803 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 6/6 [00:00<?, ?it/s] epoch 399 loss 0.0010861442098835058 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 6/6 [00:00<?, ?it/s] epoch 400 loss 0.0010815776944942087 [[0.96955654] [0.03727081] [0.03264158] [0.96955654]] ``
正如您所见,结果非常好,与真实输出相差不远(0.001 的损失非常低)。
我们还可以调整模型,使其适用于其他激活函数。
#main.pyimport layers
import loss
import optim
import numpy as npx = np.array([[0, 1], [0, 0], [1, 1], [0, 1]])
y = np.array([[0, 1], [1, 0], [1, 0], [0, 1]]) net = layers.Model([layers.Linear(8),layers.Relu(),layers.Linear(4),layers.Sigmoid(),layers.Linear(2),layers.Softmax()
])net.train(x, y, optim=optim.SGD(lr=0.6), loss=loss.MSE(), epochs=400)print (net(x))
Output
epoch 390 loss 0.00045429759266240227
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 6/6 [00:00<?, ?it/s]
epoch 391 loss 0.0004524694487356741
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 6/6 [00:00<?, ?it/s]
epoch 392 loss 0.000450655387643655
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 6/6 [00:00<?, ?it/s]
epoch 393 loss 0.00044885525012255907
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 6/6 [00:00<00:00, 6236.88it/s]
epoch 394 loss 0.00044706887927775473
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 6/6 [00:00<?, ?it/s]
epoch 395 loss 0.0004452961205401462
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 6/6 [00:00<00:00, 5748.25it/s]
epoch 396 loss 0.0004435368216234964
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 6/6 [00:00<?, ?it/s]
epoch 397 loss 0.00044179083248269265
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 6/6 [00:00<?, ?it/s]
epoch 398 loss 0.00044005800527292425
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 6/6 [00:00<?, ?it/s]
epoch 399 loss 0.00043833819430972714
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 6/6 [00:00<?, ?it/s]
epoch 400 loss 0.0004366312560299245
[[0.01846441 0.98153559][0.97508489 0.02491511][0.97909267 0.02090733][0.01846441 0.98153559]]
我们已经成功构建了一个有效的神经网络。这可以成功应用于更有用的事物,比如MNIST数据集,我们很快会在另一篇文章中使用它。
下一篇文章将介绍更多的损失函数和更多的优化函数。
感谢阅读!