ClinicalMamba:长距离不垮,超模也望尘莫及;定制化信息提取,个性化精确到点
- 1. 引言
- 2. 相关工作
- 早期临床语言模型的局限性
- Clinical BERT和ClinicalBERT等模型的进步
- GatorTron和NYUTron等大模型的贡献
- 提出长文本处理的需求和之前方法的不足
- 3. 方法
- 3.1 预训练
- 数据收集:MIMIC-III数据库的使用
- 数据预处理:如何处理和准备数据
- 模型架构:ClinicalMamba的设计和特点
- 3.2 基于提示的微调
- 微调策略:如何适应特定临床NLP任务
- 3.3 微调任务
- 临床试验队列选择
- ICD编码
- 性能评估指标:精确度、召回率、F1得分、AUC
- 4. 结果与讨论
- 模型性能比较:ClinicalMamba与其他模型的对比
- 长文本处理:ClinicalMamba处理长达16k词的临床笔记的能力
- 语言建模能力与推理速度的平衡
- ClinicalMamba在临床NLP任务上的突破和优势
论文:https://arxiv.org/pdf/2403.05795.pdf
代码:https://github.com/whaleloops/ClinicalMamba
1. 引言
在当今医疗保健领域,自然语言处理(NLP)技术的进步为处理和理解大量临床数据开辟了新的可能性。随着电子健康记录(EHR)系统的广泛采用,医疗保健专业人员每天都会产生大量的临床笔记,包括病人的症状、治疗历程、诊断结果以及随访计划等信息。
这些文档通常详细记录了病人的医疗历程,包含大量跨越不同时间点的信息。有效地理解和处理这些长文本需要能够跨越整个文档的上下文进行推理,这超出了大多数现有NLP技术的能力范围。
传统的临床语言模型往往在处理这种长篇幅文本时遇到性能瓶颈,难以捕捉到文档中分散的、相关联的信息点。
为了解决这一问题,我们引入了ClinicalMamba,这是一种专门为处理临床领域的长文本设计的先进语言模型。
ClinicalMamba利用了最新的NLP技术,能够理解和处理长达数千词的临床笔记。
它的设计考虑了医疗文本的独特性,包括专业术语的使用和信息的复杂性。
ClinicalMamba的创新之处在于其能力强大的预训练和微调机制,使其能够在各种临床NLP任务上展现出色的性能,从而支持更精准的病人护理和更有效的医疗决策。
ClinicalMamba的目的是通过其特殊设计的模型架构和训练方法,提高在医疗保健领域处理长文本的能力。
通过这种方式,它旨在帮助医疗专业人员更好地理解病人的病情,优化治疗计划,以及加速临床研究的进展。
在本文中,我们将详细介绍ClinicalMamba的开发过程、其在不同临床任务上的应用,以及它如何显著提高从长临床文本中提取信息的准确性和效率。
2. 相关工作
在深入探讨ClinicalMamba的开发和性能之前,理解临床语言模型发展的历史背景和现有技术的局限性是非常重要的。
自然语言处理技术在医疗保健领域的应用已经取得了显著的进步,但同时也面临着不少挑战。
早期临床语言模型的局限性
早期的临床语言模型大多基于传统的机器学习技术,它们依赖于大量的手工特征工程和专家知识。
虽然这些模型在特定任务上取得了一定的成功,但它们往往难以泛化到复杂的临床语境中,特别是在处理长文本和理解临床叙述的复杂性方面。
此外,这些模型的性能在很大程度上受限于训练数据的规模和质量,难以捕捉临床文本中的细微差别和丰富的语义信息。
Clinical BERT和ClinicalBERT等模型的进步
随着BERT(Bidirectional Encoder Representations from Transformers)及其变种模型的出现,临床NLP领域迎来了新的发展。
Clinical BERT和ClinicalBERT通过预训练在大规模临床文本上捕捉丰富的语言特征,显著提高了临床信息提取、文本分类和实体识别等任务的性能。
这些模型利用双向Transformer架构,能够更好地理解语言的上下文关系,为临床文本分析提供了一种强大的工具。
GatorTron和NYUTron等大模型的贡献
近年来,随着模型规模的不断扩大,GatorTron和NYUTron等大型临床语言模型的开发,标志着临床NLP领域的又一次飞跃。
这些模型训练了数十亿甚至更多的参数,能够更深入地理解复杂的医疗语言和临床知识。
它们在各种临床NLP任务上都展示了前所未有的性能,推动了医疗数据分析和患者护理的进步。
提出长文本处理的需求和之前方法的不足
尽管上述模型在临床NLP领域取得了巨大进步,但处理长文本仍是一个重大挑战。
长文本临床记录,如出院小结或完整的病历,包含了病人健康状况的重要信息,其信息量和复杂度远远超过了短文本。
现有模型在处理这些长文本时往往受限于其预训练结构的限制,难以有效捕捉和整合文档中分布广泛的关键信息。
因此,开发能够有效处理长文本且能够理解临床叙述复杂性的模型,成为了临床NLP研究的一项迫切需求。
正是在这样的背景下,ClinicalMamba应运而生。
它旨在解决现有临床语言模型在处理长文本方面的不足,通过其创新的预训练和微调机制,为复杂的临床文本分析提供了新的解决方案。
3. 方法
本研究的核心在于开发和评估ClinicalMamba,一个专为临床领域设计的语言模型,以提升长文本处理和临床信息提取的能力。
针对临床领域中处理长文本临床笔记的具体问题,ClinicalMamba采取了一系列解决方案,这些解决方案进一步分解为更具体的子解法。
解决方案:开发ClinicalMamba以提高临床NLP任务的性能,特别是在处理长文本上
子解决方案1:采用大规模预训练
- 特征:临床文本的复杂性和长文本的信息密度。
- 原因:大规模预训练能够让模型学习到更深层次的语言特征和临床知识,提高对复杂文本的理解能力。
子解决方案2:使用选择性状态空间模型
- 特征:长文本中关键信息的分散性和文本长度的变化。
- 原因:选择性状态空间模型能够有效压缩和选择关键信息,提高模型在处理极长文本时的准确性和效率。
子解决方案3:基于提示的微调策略
- 特征:临床NLP任务的多样性和特定性。
- 原因:基于提示的微调能够让模型更好地适应具体任务的需求,通过引入任务相关的提示来提高模型在特定临床任务上的性能。
子解决方案4:针对特定任务优化模型性能
- 特征:临床试验队列选择和ICD编码等任务对精确度的高要求。
- 原因:通过在特定临床NLP任务上进行细致的优化和调整,ClinicalMamba能够更精确地执行任务,如提高疾病编码的准确率和优化临床试验的患者筛选过程。
子解决方案5:平衡模型的复杂性和推理速度
- 特征:在实际临床环境中应用时对模型推理速度的要求。
- 原因:通过优化模型架构和计算方法,ClinicalMamba在保持高性能的同时提高了推理速度,使其更适合在实际临床环境中快速使用。
通过这种方法,ClinicalMamba能够有效提升在处理长篇临床记录和执行复杂信息提取任务时的性能,为医疗保健领域提供了一个强大的工具。
3.1 预训练
数据收集:MIMIC-III数据库的使用
我们从MIMIC-III数据库中收集了82,178次医院访问记录,涵盖了46,520名病人的2,083,180条去标识化的自由文本临床笔记。
MIMIC-III是一个公开的临床数据库,包含了丰富的临床信息,是进行临床NLP研究的理想资源。
数据预处理:如何处理和准备数据
为了优化模型的学习效率,我们对收集到的数据进行了预处理,包括文本清洗(去除无关字符、标准化术语等)和分词。
与传统方法不同,我们没有将笔记分解成较小的512词块,而是将一次访问中的所有笔记整合为一个长文本实例,以保持信息的完整性和上下文的连贯性。
模型架构:ClinicalMamba的设计和特点
ClinicalMamba模型基于Mamba模型架构,特别针对长文本的处理进行了优化。
它通过使用选择性状态空间模型来精确地选择和压缩关键信息,同时保持了对长篇临床笔记中细节的敏感性和理解能力。
预训练过程在4个Nvidia A100-80GB GPU上进行,使用因果语言模型目标来学习生成文本的能力。
3.2 基于提示的微调
微调策略:如何适应特定临床NLP任务
为了使模型能够适应具体的临床NLP任务,我们采用了基于提示的微调策略。
这种方法涉及定义一组能够概括临床任务关键方面的提示语(如病人的酒精消费情况),并在每个输入的临床笔记后附加这些提示语。
通过这种方式,模型学习在有限的数据集上基于提示生成标签令牌(如“是”/“否”)。
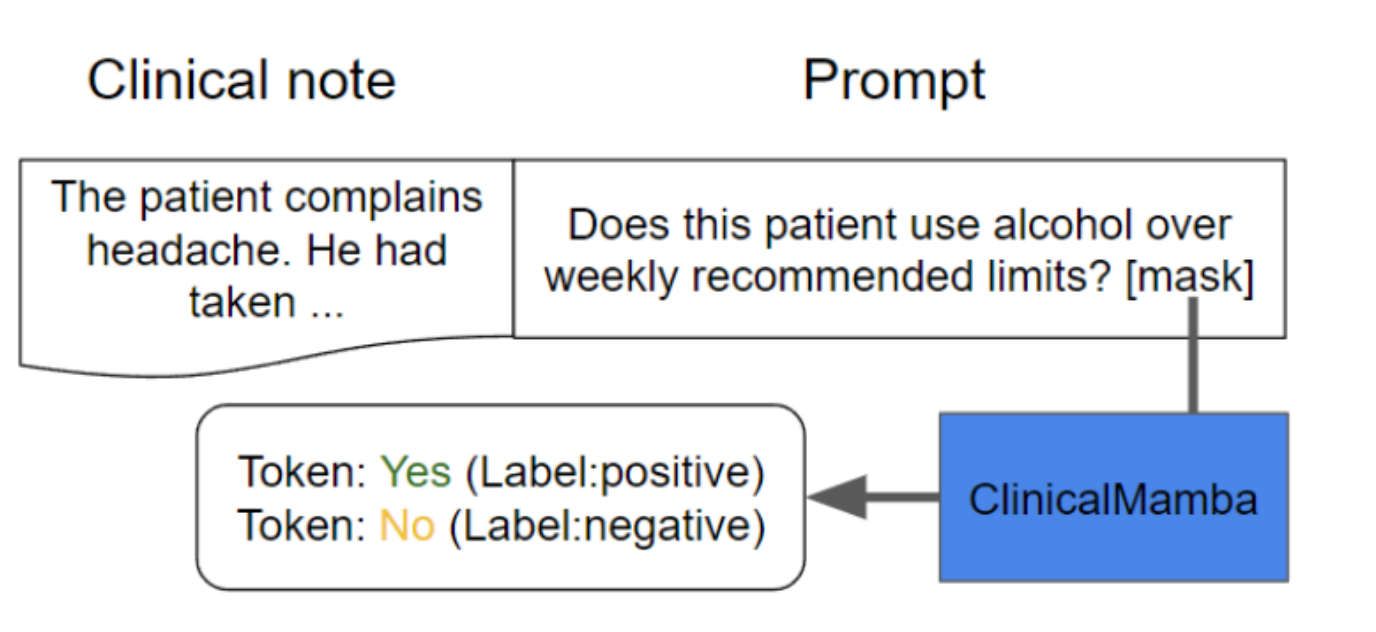
医生需要决定一个病人是否过量饮酒。
医生会阅读病人的医疗记录,然后提出一个问题:“这个病人是否超过每周推荐的酒精限量?”
然后,医生会根据他阅读的信息判断是(Yes)或否(No)。
在这个图中,ClinicalMamba扮演的角色就像一个正在学习成为医生的计算机程序。
我们给这个程序看一段病人的医疗记录,并问它同样的问题。
这个问题就是所谓的"提示",它告诉程序要寻找什么样的信息。
程序会在一个特殊的空位([mask])处生成一个答案:如果它认为病人确实超量饮酒了,它会说"Yes";如果不是,它会说"No"。
这就是"基于提示的微调"的过程,通过这个过程,程序学习如何根据病人的医疗记录来回答特定的健康相关问题。
3.3 微调任务
临床试验队列选择
我们评估模型在选择符合特定资格标准的临床试验队列方面的性能。
这项任务要求模型基于多项标准(如阿司匹林使用、酒精消费情况、HbA1c值等)分类病人。
ICD编码
另一个评估任务是ICD编码,即将临床笔记翻译成标准化的疾病和手术代码。
这对于准确的账单、统计分析和医疗管理至关重要。
性能评估指标:精确度、召回率、F1得分、AUC
为了全面评估ClinicalMamba在这些任务上的表现,我们报告了模型的微精度、召回率
、F1得分和接收器操作特性曲线下面积(AUC)。
这些指标综合反映了模型在临床信息提取方面的准确性和效率。
通过这一系列方法,ClinicalMamba不仅展示了其在长文本处理方面的卓越能力,还证明了其在临床NLP任务中的应用潜力,为未来的医疗保健研究和实践提供了新的工具和见解。
4. 结果与讨论
本节详细讨论了ClinicalMamba模型的性能表现,特别是与其他领先的临床语言模型的比较,以及在处理长文本临床笔记和平衡语言建模能力与推理速度方面的突破。
模型性能比较:ClinicalMamba与其他模型的对比
在临床试验队列选择任务中,ClinicalMamba模型(尤其是2.8b参数版本)在精确度、召回率、F1得分和AUC指标上均超过了其他模型,包括GPT-4、CLlama2、Hi-CRoberta和CLongformer。
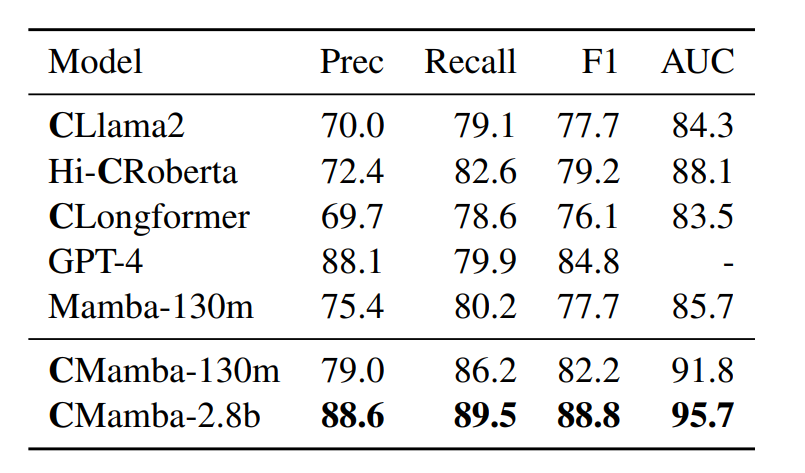
特别是与GPT-4相比,ClinicalMamba-2.8b在F1得分上达到了88.8%,显著高于GPT-4的84.8%。
这一结果凸显了ClinicalMamba在理解临床语言和执行复杂临床信息提取任务方面的强大能力。
长文本处理:ClinicalMamba处理长达16k词的临床笔记的能力
ClinicalMamba的一个关键创新是其在处理长达16k词的临床笔记方面的出色性能。
模型在长文本上的困惑度(perplexity)显著低于其他模型,且随着文本长度的增加,其性能并未显著下降。
这与传统模型在处理大于4k词的文本时性能急剧下降形成鲜明对比,展示了ClinicalMamba在捕捉长篇临床记录中的关键信息上的独特优势。
语言建模能力与推理速度的平衡
在保持高精度的同时,ClinicalMamba还实现了与推理速度之间的有效平衡。
相较于其他大型语言模型,如ClinicalLlama-7b,ClinicalMamba-2.8b在维持相似或更低困惑度的同时,推理速度提升了3至30倍。
这一平衡使得ClinicalMamba能够在实际临床环境中更加高效地部署,为快速且准确的临床决策提供支持。
ClinicalMamba在临床NLP任务上的突破和优势
ClinicalMamba在多个临床NLP任务上的表现突出,尤其是在处理需长文本理解和复杂信息提取的任务上。
模型在少量样本训练(few-shot learning)场景下表现优异,特别是在数据稀缺的情况下,如Code-rare任务,进一步证明了其在处理复杂临床语境方面的强大能力。
ClinicalMamba的成功部署标志着临床NLP领域的一个重要进步,为未来的研究和临床实践提供了新的方向和可能性。