前言
今天开始正式的数仓搭建,所谓 ODS 层的工作就是把我们各种数据源采集发送来的各种类型的数据(Json、tsv类型)映射到 Hive 表中,映射时可以进行一些简单的处理,比如简单的数据清洗,舍弃一些没有必要的字段。
1、ODS 层开发
ODS层的设计要点如下:
(1)ODS层的表结构设计依托于从业务系统同步过来的数据结构(JSON/CSV/TSV)。
(2)ODS层要保存全部历史数据,故其压缩格式应选择高压缩比的算法,此处选择gzip。
(3)ODS层表名的命名规范为:ods_表名_单分区增量全量标识(inc/full)。
注意:ODS 层的表都是分区表,因为我们每天都会有数据被采集到数仓,所以我们的表是按照日期分区的,每天一张表。
我们当前保存在 HDFS 路径下的数据主要有两类:log 和 db,log 目录下存放是我们从 Flume 传过来的用户行为日志文件,我们已经用 gzip 压缩过了,可以通过下面的命令查看:
hadoop fs -cat /origin_data/gmall/log/topic_log/2020-06-14/* | zcat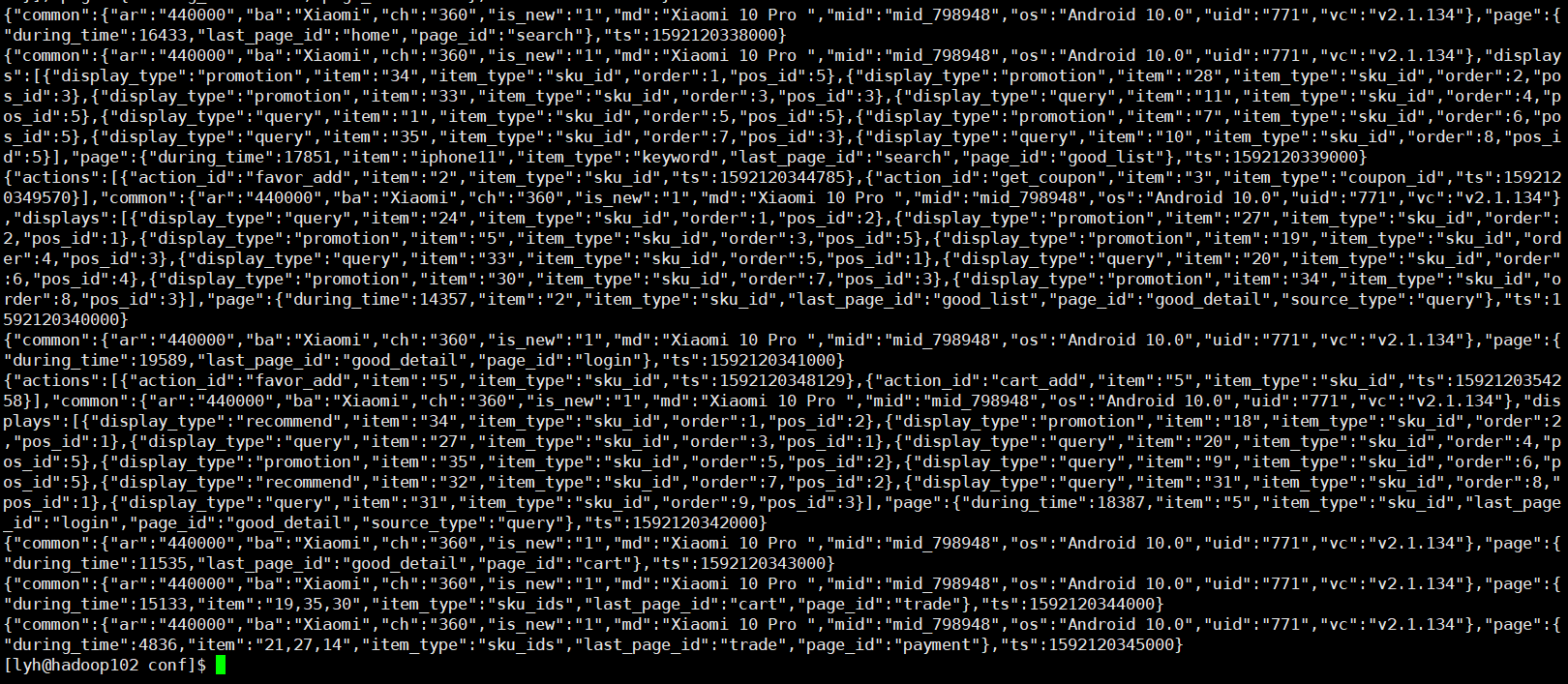
可以看到我们的格式是一个 JSON 格式,那我们要建表的话就得考虑怎么把 JSON 格式的数据映射到我们的 Hive 表中了。
对于 db 目录下的文件主要有两类:DataX 同步过来的以 "full" 为目录后缀的全量业务数据和 Maxwell 同步过来的首日全量数据和以 "inc" 为目录后缀的增量业务数据。
hadoop fs -cat /origin_data/gmall/db/activity_rule_full/2020-06-14/* | zcat
可以看到 DataX 传输过来的文件是 ".tsv" 文件,我们将来只要拿 "\t" 分隔即可。
hadoop fs -cat /origin_data/gmall/db/comment_info_inc/2020-06-14/* | zcat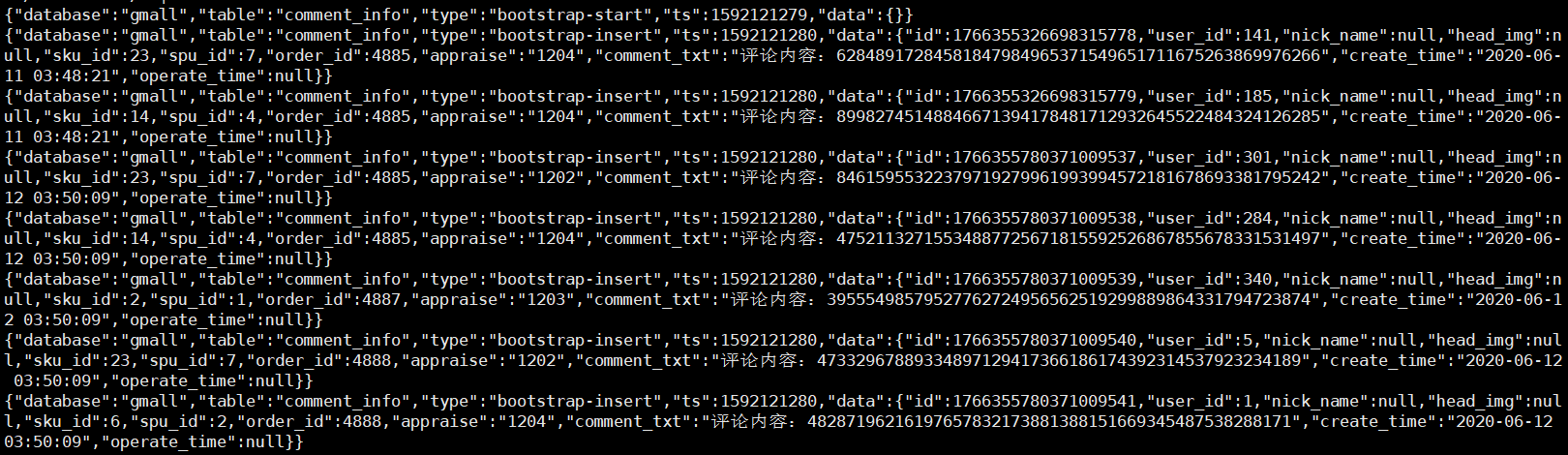
可以看到,拿 Maxwell 同步过来的数据和 Flume 一样,都是 JSON 格式的。
1.1、用户行为日志表
1.1.1、ROW FORMAT 和 STORE AS
打开 Hive 官网 -> LanguageManual -> DDL -> JSON

查看 Hive 3.x 版本支持的通过解析 JSON 映射表的语法:
CREATE TABLE my_table(a string, b bigint, ...)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.JsonSerDe' -- 声明行的格式
STORED AS TEXTFILE; -- 声明怎么解析文件这里的 ROW FORMAT 和 STORE AS 都是 Hive 建表是所必须指定的,只不过 Hive 帮我们简化了这部分语法:
ROW FORMAT :用 DELIMITED 关键字表示对文件中的每个字段按照特定分割符进行分割用 SERDE 关键字来指定 Hive 内置的 SERDE 或者 用户自定义的 SERDE。
STORE AS :用 STORED AS + 简写文件格式来指定 InputFormat 和 OutputFormat ,默比如 TextFileInputFormat 和 TextFileOutputFormat 可以用 STORE AS TEXTFILE 来表示。
Hive SerDe

Hive 的 ROW FORMAT 的 SERDE 属性指定了 Hive 的序列化器和反序列化器,映射 HDFS 文件时,使用反序列化器进行解析,写出文件时使用序列化器来封装数据。
1.1.2、复杂数据类型
对于用户行为日志,它的存储格式是 json 格式,那我们就需要把它的每个字段映射到我们 Hive 表中。首先回顾一下 Hive 的三种复杂类型:
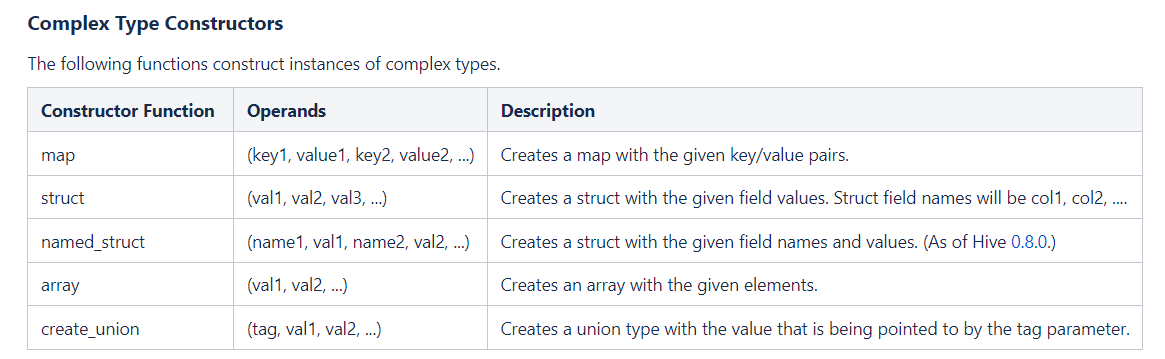
- array
- 声明:array<string>
- 取值:arr[0]
- 构造:array(val1,val2...),split(),collect_set()
- map
- 声明:map<string,bigint>
- 取值:map[key]
- 构造:map(key1,val1,key2,val2...)
- struct
- 声明:struct<id:int,name:strnig>
- 取值:struct.id
- 构造:named_struct(name1,val1,name2,val2...)

对于上面的 common 字段,它虽然是键值对格式,但是我们不能使用 map ,因为 map 的 value 是同一数据类型,而我们这里的 common 字段不同键的值有的是 int 有的是 string。所以我们使用 struct。

对于 displays 字段,由于它存储的是数组类型,然后数组嵌套键值对,所以我们需要使用 array(struct) 的嵌套类型。
1.1.3、设计日志表
DROP TABLE IF EXISTS ods_log_inc;
CREATE EXTERNAL TABLE ods_log_inc
(`common` STRUCT<ar :STRING,ba :STRING,ch :STRING,is_new :STRING,md :STRING,mid :STRING,os :STRING,uid :STRING,vc:STRING> COMMENT '公共信息',`page` STRUCT<during_time :STRING,item :STRING,item_type :STRING,last_page_id :STRING,page_id:STRING,source_type :STRING> COMMENT '页面信息',`actions` ARRAY<STRUCT<action_id:STRING,item:STRING,item_type:STRING,ts:BIGINT>> COMMENT '动作信息',`displays` ARRAY<STRUCT<display_type :STRING,item :STRING,item_type :STRING,`order` :STRING,pos_id:STRING>> COMMENT '曝光信息',`start` STRUCT<entry :STRING,loading_time :BIGINT,open_ad_id :BIGINT,open_ad_ms :BIGINT,open_ad_skip_ms:BIGINT> COMMENT '启动信息',`err` STRUCT<error_code:BIGINT,msg:STRING> COMMENT '错误信息',`ts` BIGINT COMMENT '时间戳'
) COMMENT '活动信息表'PARTITIONED BY (`dt` STRING)ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.JsonSerDe'LOCATION '/warehouse/gmall/ods/ods_log_inc/';
注意:我们数仓建的基本都是外部表,防止误删数据!
这里的分区我们指定了一个 String 类型的分区键:如果我们有一个分区 dt='2020-06-14',那么在 HDFS 上就会有一个目录,路径类似于 /user/hive/warehouse/sales/dt=2020-06-14,这个目录就存放了所有 dt 为 '2020-06-14' 的数据。
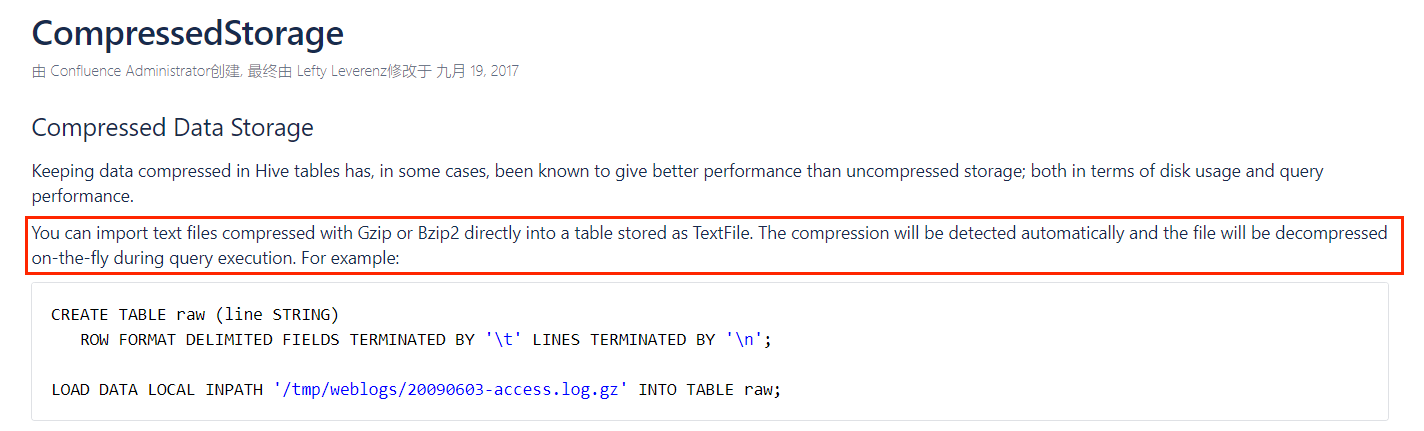
gzip 和 bzip2 格式的文件可以直接以 textfile 的格式来 load ,而不需要在建表时指定压缩格式(其实就是指定 STORE AS )。
但是其他压缩格式是不行的,比如 LZO 压缩的话,必须指定 STORE AS 的 InputFormat 和 OutputFormat :
CREATE EXTERNAL TABLE IF NOT EXISTS hive_table_name (column_1 datatype_1......column_N datatype_N)PARTITIONED BY (partition_col_1 datatype_1 ....col_P datatype_P)ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'STORED AS INPUTFORMAT \"com.hadoop.mapred.DeprecatedLzoTextInputFormat\"OUTPUTFORMAT \"org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat\";1.1.4、装载脚本
我们的日志数据每天都要 load 到一张新的分区表中,装载语句还是比较简单的:
load data inpath '/origin_data/gmall/log/topic_log/2020-06-14' into table ods_log_inc partition(dt='2020-06-14')
思考:load 和 location 的区别?
load data会使数据目录发生改变(数据从源路径"移动"到我们表的路径)
location 则不会,而是以此目录作为源数据
注意:load 尽管是移动数据表但是并没有什么开销,因为它只是修改了我们 HDFS 文件块的在 NameNode 中的元数据路径,并没有真的移动数据。
但是我们不能每天都重复编写命令去执行,我们这里直接写一个 shell 脚本:
#!/bin/bash# 定义变量方便修改
APP=gmall# 如果是输入的日期按照取输入日期;如果没输入日期取当前时间的前一天
if [ -n "$1" ] ;thendo_date=$1
elsedo_date=`date -d "-1 day" +%F`
fiecho ================== 日志日期为 $do_date ==================
sql="
load data inpath '/origin_data/$APP/log/topic_log/$do_date' into table ${APP}.ods_log_inc partition(dt='$do_date');
"
hive -e "$sql"脚本用法:
hdfs_to_ods_log.sh 2020-06-14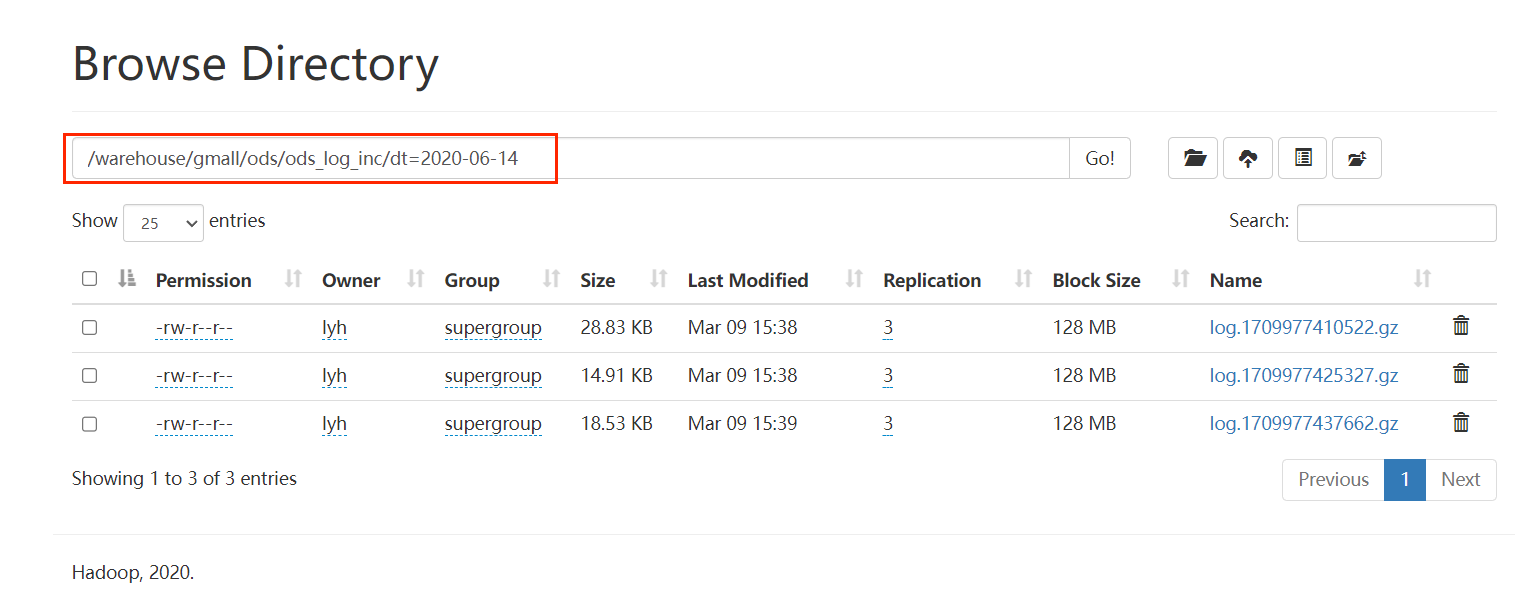
可以看到我们的表被成功 load 。
1.2、业务表(全量 & 增量)
1.2.1、建表分析
因为 DataX 全量采集的结果是 tsv 格式所以我们可以直接对应 MySQL 中这些表格的格式,而 Maxwell 同步过来的增量表我们需要用 json 来序列化和反序列化。
比如全量同步的活动信息表:

DROP TABLE IF EXISTS ods_activity_info_full;
CREATE EXTERNAL TABLE ods_activity_info_full
(`id` STRING COMMENT '活动id',`activity_name` STRING COMMENT '活动名称',`activity_type` STRING COMMENT '活动类型',`activity_desc` STRING COMMENT '活动描述',`start_time` STRING COMMENT '开始时间',`end_time` STRING COMMENT '结束时间',`create_time` STRING COMMENT '创建时间'
) COMMENT '活动信息表'PARTITIONED BY (`dt` STRING)ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'NULL DEFINED AS ''LOCATION '/warehouse/gmall/ods/ods_activity_info_full/';此外,Maxwell 增量同步过来的数据我们需要额外注意,因为 Maxwell 监听到的有三种类型的数据:insert、update 和 delete。其中 update 类型的数据它的 old 字段保存的是修改的数据字段,而 data 字段保存的是全部内容。

比如首日增量同步的购物车表:
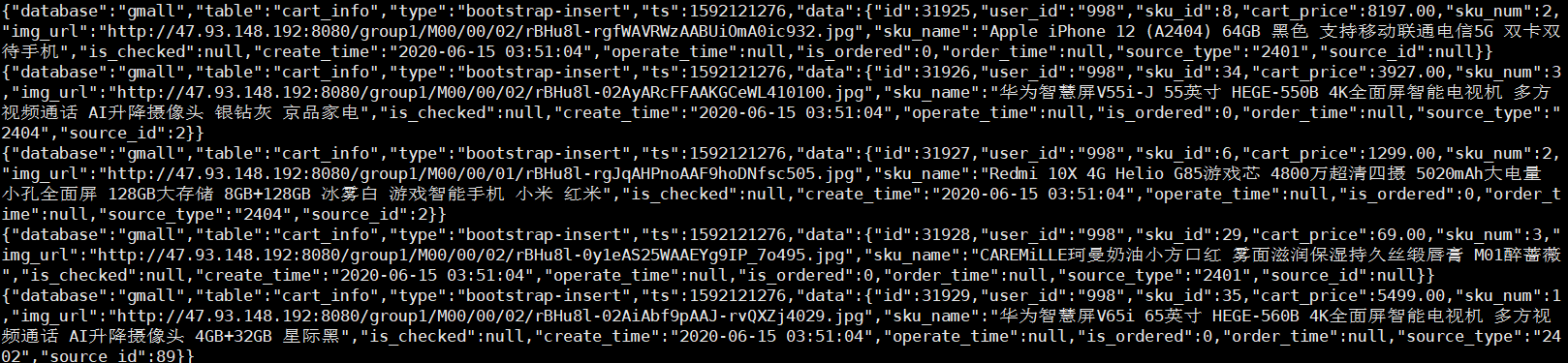

DROP TABLE IF EXISTS ods_cart_info_inc;
CREATE EXTERNAL TABLE ods_cart_info_inc
(`type` STRING COMMENT '变动类型',`ts` BIGINT COMMENT '变动时间',`data` STRUCT<id :STRING,user_id :STRING,sku_id :STRING,cart_price :DECIMAL(16, 2),sku_num :BIGINT,img_url :STRING,sku_name:STRING,is_checked :STRING,create_time :STRING,operate_time :STRING,is_ordered :STRING,order_time:STRING,source_type :STRING,source_id :STRING> COMMENT '数据',`old` MAP<STRING,STRING> COMMENT '旧值'
) COMMENT '购物车增量表'PARTITIONED BY (`dt` STRING)ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.JsonSerDe'LOCATION '/warehouse/gmall/ods/ods_cart_info_inc/';但是我们这里的 database 字段、old 和 table 字段都不需要映射到我们的表中,因为它并没有意义。我们需要保留 type 字段,因为我们要知道用户的操作类型(比如如果这张表是购物车表 cart_info 那 type = 'insert' 就是加入购物车的操作),除此之外,我们还需要保留 old、 ts 和 data 字段,其中 old 我们只能使用 Map<string,string> 来保存,因为 old 字段是发生修改的字段,我们无法确定每个被修改的字段的类型。
注意:对于增量同步的表,我们之前用 Maxwell 做了历史数据首日全量同步,
1.2.2、装载脚本
上面我们的用户行为日志表因为是一张表,所以我们的参数(日期)只有一个就够了,这里我们的全量和增量表需要指定两个参数(日期和表名)
#!/bin/bashAPP=gmallif [ -n "$2" ] ;thendo_date=$2
else do_date=`date -d '-1 day' +%F`
fiload_data(){sql=""for i in $*; do#判断路径是否存在hadoop fs -test -e /origin_data/$APP/db/${i:4}/$do_date#路径存在方可装载数据if [[ $? = 0 ]]; thensql=$sql"load data inpath '/origin_data/$APP/db/${i:4}/$do_date' OVERWRITE into table ${APP}.$i partition(dt='$do_date');"fidonehive -e "$sql"
}case $1 in"ods_activity_info_full")load_data "ods_activity_info_full";;"ods_activity_rule_full")load_data "ods_activity_rule_full";;"ods_base_category1_full")load_data "ods_base_category1_full";;"ods_base_category2_full")load_data "ods_base_category2_full";;"ods_base_category3_full")load_data "ods_base_category3_full";;"ods_base_dic_full")load_data "ods_base_dic_full";;"ods_base_province_full")load_data "ods_base_province_full";;"ods_base_region_full")load_data "ods_base_region_full";;"ods_base_trademark_full")load_data "ods_base_trademark_full";;"ods_cart_info_full")load_data "ods_cart_info_full";;"ods_coupon_info_full")load_data "ods_coupon_info_full";;"ods_sku_attr_value_full")load_data "ods_sku_attr_value_full";;"ods_sku_info_full")load_data "ods_sku_info_full";;"ods_sku_sale_attr_value_full")load_data "ods_sku_sale_attr_value_full";;"ods_spu_info_full")load_data "ods_spu_info_full";;"ods_cart_info_inc")load_data "ods_cart_info_inc";;"ods_comment_info_inc")load_data "ods_comment_info_inc";;"ods_coupon_use_inc")load_data "ods_coupon_use_inc";;"ods_favor_info_inc")load_data "ods_favor_info_inc";;"ods_order_detail_inc")load_data "ods_order_detail_inc";;"ods_order_detail_activity_inc")load_data "ods_order_detail_activity_inc";;"ods_order_detail_coupon_inc")load_data "ods_order_detail_coupon_inc";;"ods_order_info_inc")load_data "ods_order_info_inc";;"ods_order_refund_info_inc")load_data "ods_order_refund_info_inc";;"ods_order_status_log_inc")load_data "ods_order_status_log_inc";;"ods_payment_info_inc")load_data "ods_payment_info_inc";;"ods_refund_payment_inc")load_data "ods_refund_payment_inc";;"ods_user_info_inc")load_data "ods_user_info_inc";;"all")load_data "ods_activity_info_full" "ods_activity_rule_full" "ods_base_category1_full" "ods_base_category2_full" "ods_base_category3_full" "ods_base_dic_full" "ods_base_province_full" "ods_base_region_full" "ods_base_trademark_full" "ods_cart_info_full" "ods_coupon_info_full" "ods_sku_attr_value_full" "ods_sku_info_full" "ods_sku_sale_attr_value_full" "ods_spu_info_full" "ods_cart_info_inc" "ods_comment_info_inc" "ods_coupon_use_inc" "ods_favor_info_inc" "ods_order_detail_inc" "ods_order_detail_activity_inc" "ods_order_detail_coupon_inc" "ods_order_info_inc" "ods_order_refund_info_inc" "ods_order_status_log_inc" "ods_payment_info_inc" "ods_refund_payment_inc" "ods_user_info_inc";;
esac- hadoop fs -test -e 用来判断路径是否存在,存在返回 0
- si{1:4} 返回第 $i 个字符串的4个字符之后的字符串
hdfs_to_ods_db.sh all 2020-06-14执行完毕,查看 hdfs web 端,共 29 张表,说明我们 load 完毕。
总结
至此,ODS 搭建完毕。ODS 层其实就是把我们的采集过来的数据(用户行为数据(json 格式)、业务数据(用 DataX 采集过来的数据是 tsv 格式,用 Maxwell 首日全量和之后增量采集过来的是 json 格式)都按照字段映射到我们的 Hive 表中。尤其是用户行为日志,因为业务数据我们还可以参考 MySQL 中的存储格式,但是对于 json 格式的日志数据我们必须自己去设计,而且一些字段还需要进行舍取。
Shell 脚本的简单编写还需要复习复习。
DataGrip 字段不显示的配置
<property><name>metastore.storage.schema.reader.impl</name><value>org.apache.hadoop.hive.metastore.SerDeStorageSchemaReader</value>
</property>