zookeeper入门学习
zookeeper应用场景
- 分布式
协调组件
客户端第一次请求发给服务器2,将flag值修改为false,第二次请求被负载均衡到服务器1,访问到的flag也会是false
一旦有节点发生改变,就会通知所有监听方改变自己的值,保持数据的一致性(watch机制) => 会不会改变的太频繁了
- 分布式锁
后面讲述
- 无状态化的实现
比如我的登录信息,单独放在哪一台主机都不合适,这时,就可以将登录信息放在zookeeper中
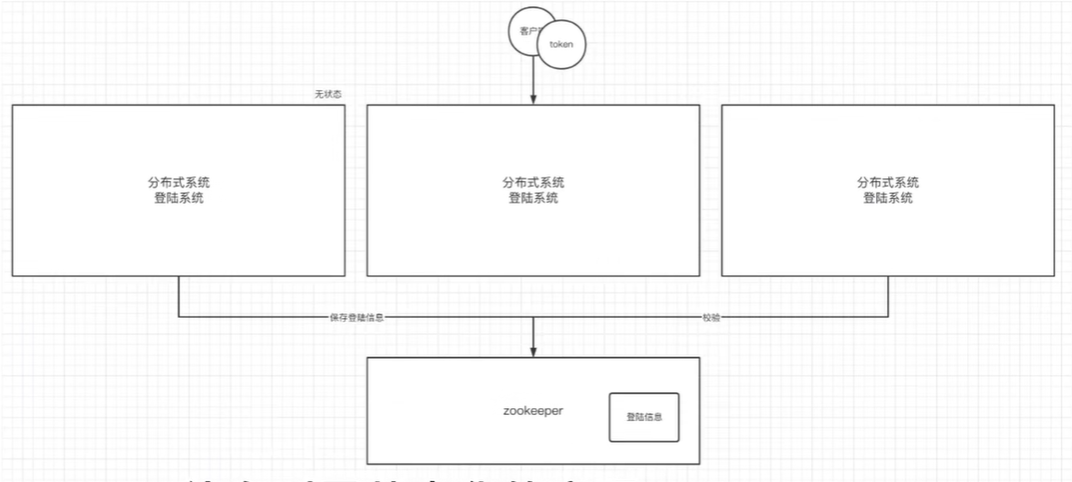
配置与命令
- zoo.cfg配置文件说明(单节点)

dataDir: zookeeper的数据存储在内存中,为防止数据丢失,需持久化到磁盘
- 事务持久化:保存执行命令
- 快照持久化:保存内存快照
与Redis不同,这两种模式zk都默认开启了,在恢复时,先恢复快照文件中的数据到内存中,再用日志文件做增量恢复。
- 操作命令
内部数据模型
zk结构
类似Linux的文件目录:
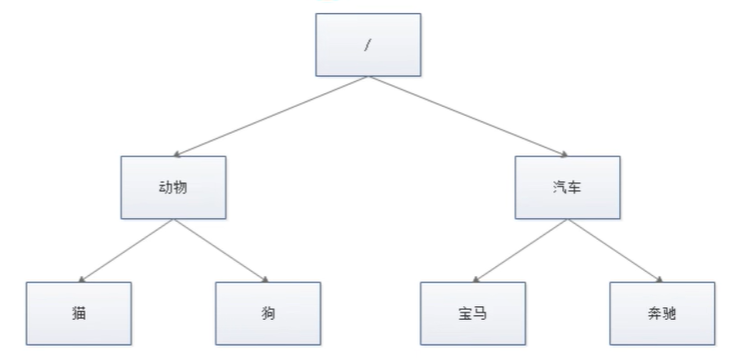
zk的数据存储基于节点,这种节点叫做Znode,但不同于树的节点,Znode节点的引用方式是路径引用,类似文件路径:/动物/猫
创建节点:create /test1,create /test1/sub1
存储数据(如上文说的存储session信息):create /test2 session
获取数据: get /test2
Znode结构
包含4部分:
- data:保存数据
- acl:权限
- c、d: create、delete权限,允许在该节点下创建、删除子节点
- w、r:读写权限
- a:允许对该节点进行acl权限设置
- stat:描述当前znode的
元数据(get -s /tets2可查看,创建时间、版本号等) - child:当前节点的子节点
Znode类型
zk节点创建(本文都是通过zkCli客户端创建,java有一个curator客户端,这里不做记录)
- 持久节点:创建出的节点,在会话结束后依然存在
- 持久序号节点:创建的节点会有一个数值,越晚创建数值越大,适用于分布式锁场景
create /test3会提示/test3已存在create -s /test3会创建/test300000000001节点
- 临时节点:会话结束后自动删除,通过这个特性,zk可以实现
服务注册与发现(注册中心)的效果
临时节点不断发送会话续约心跳,当停止发送心跳后,zk服务器的定时任务会发现这些未续约的session并删除:
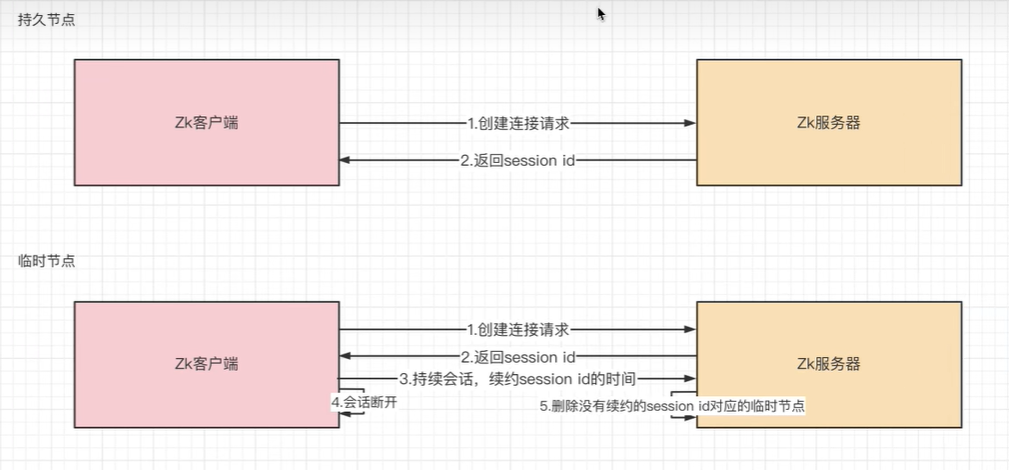
服务注册与发现:服务停供者P连接zk,创建临时的znode,这样客户端C就可以访问到这个服务了,但如果这个服务P下线了,临时znode节点被删除,客户端就不能访问服务P了
临时节点创建:create -e /test4
- 临时序号节点: 用于分布式临时锁场景,
create -e -s /tets4 - 容器节点:容器节点中没有任何子节点,则该容器会被删除(60s后)
- TTL节点:指定节点的到期时间,到期后zk被定时删除
znode删除
- 普通删除
- 乐观锁删除:
delete -v 0 /test2,删除前不上锁,删除时如果发现版本号变化,则删除失败
zk分布式锁
分布式锁:一个请求发送服务器1,zk服务器对资源A上锁,后续当请求负载均衡到服务器2,服务器2
上的资源A也需要被锁
读锁:上读锁的前提是资源A没有上写锁
写锁:上写锁的前提是资源A没有上任何锁
- zk上读锁:
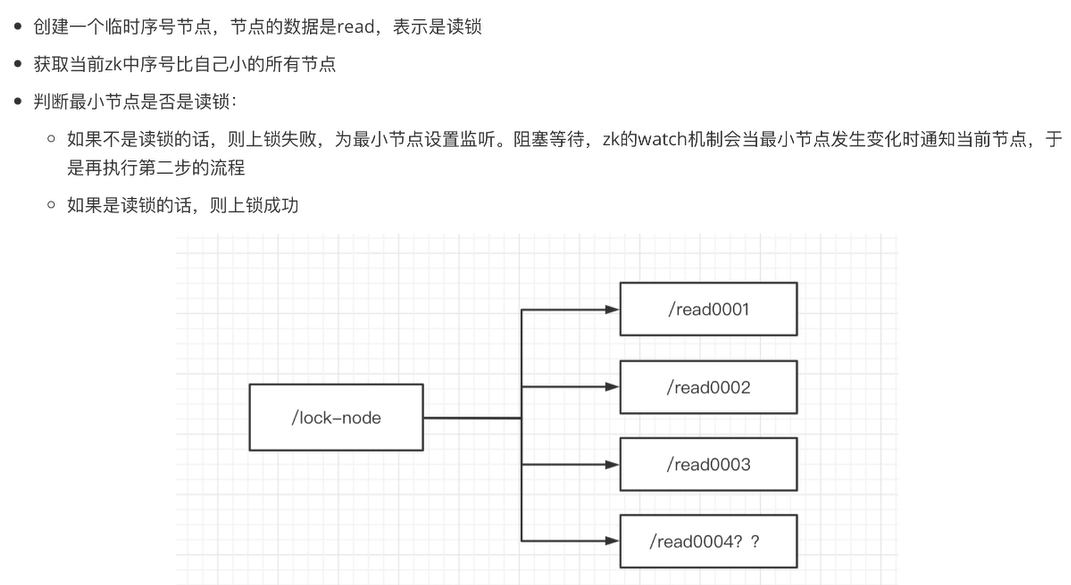
如:
- 请求1访问服务器(不论是1还是2)上的资源A, 这个请求被线程池中的x号线程接管
- /lock_node(该节点专门用来上锁的)创建子节点 read0001(这个节点的数据应该就是资源A),表示资源A已被上读锁了
- 然后第二个并发请求过来,被线程池中的y号线程接管,如果判断1号节点(最小节点)上的是写锁,则上读锁失败
- 如果1号节点是写锁,2号节点将向1号节点注册一个watch,监听1号节点被释放
- zk上写锁:
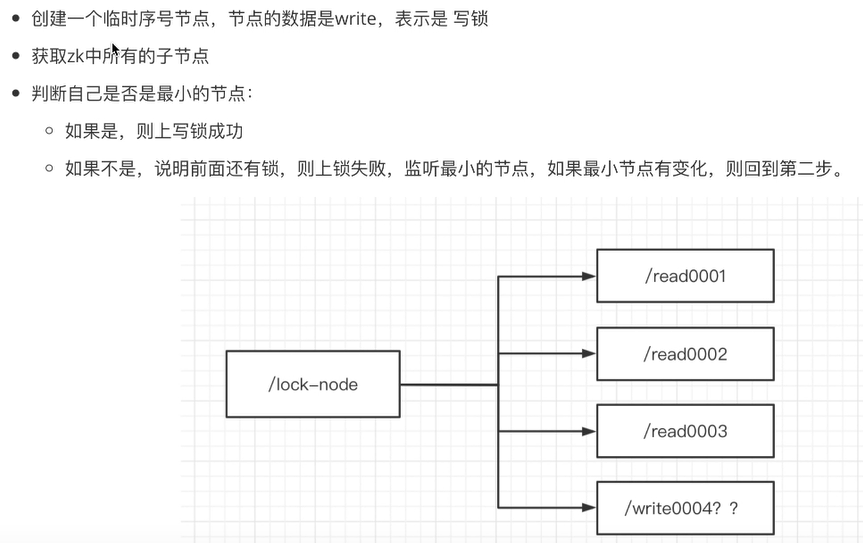
- 羊群(惊群)效应
如果有100个并发,都在上写锁,那么后面的99个节点都要监听第一个节点,等1号节点释放了,另外的98个节点又要监听2号节点
解决:链式监听,当前节点监听上一个节点是否释放
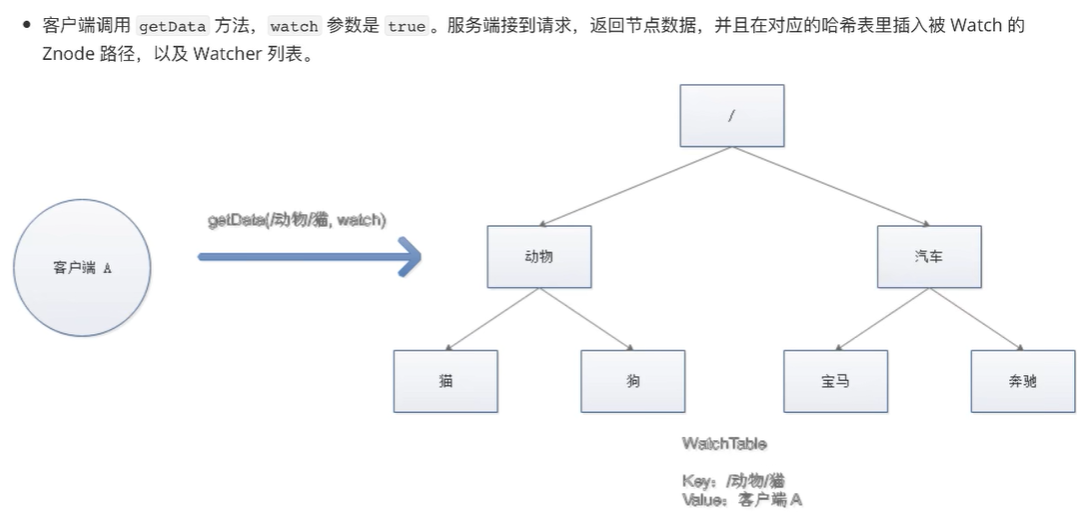
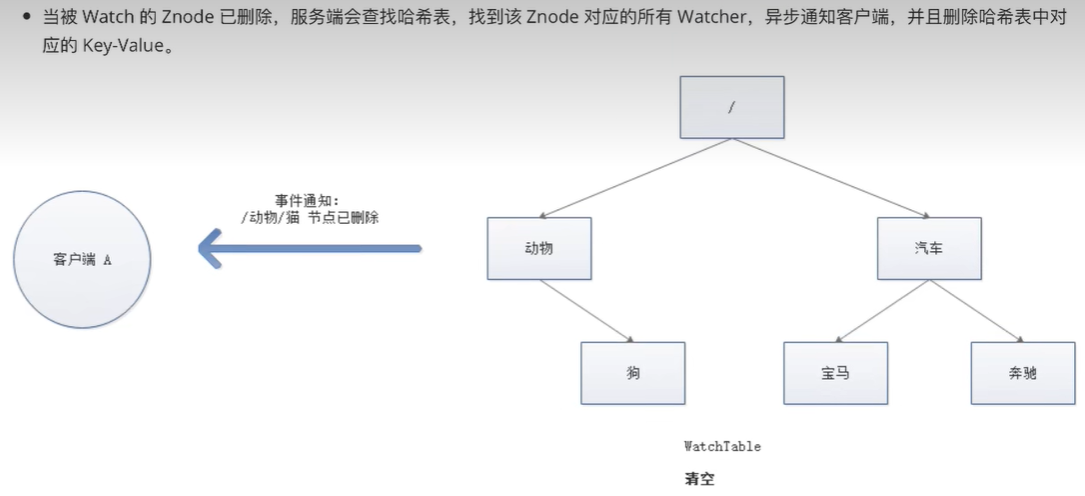
watch机制
watch机制:可以理解成注册再特定znode上的触发器,当这个znode改变时,也就是调用了create、delete、setDate
等命令时,会触发znode上注册的对应事件,请求watch的客户端会接受到异步通知。
具体交互:
zk集群
主要讲述集群的选举和数据同步
集群角色
- leader:处理集群的所有事务请求,一个集群只能有一个leader
- follower:只能处理读请求,参与leader选举
- observer:只能处理读请求,提升集群读的性能,不参与leader选举
搭建集群
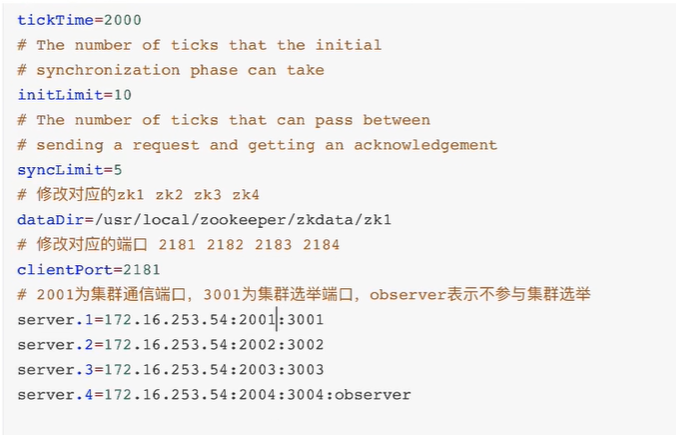
搭建4个节点,其中一个observer
- 创建节点的myid

- 编写4个zoo.cfg
注意配置三类端口:
- clientPort:开放给客户端的端口
- server.2001:集群通信端口,主要用于同步
- server.3001:集群选举端口
- 启动4台zk
- 客户端链接zk集群

如果只填一个zk服务器,那就和单机集群没区别了,zk服务器挂了后,就不会连其他zk服务器了
ZAB协议
原子广播协议:zk为了保证数据的一致性,使用了ZAB(Zookeeper Atomic Broadcast)协议,这个协议解决了zk崩溃恢复和主从数据同步的问题
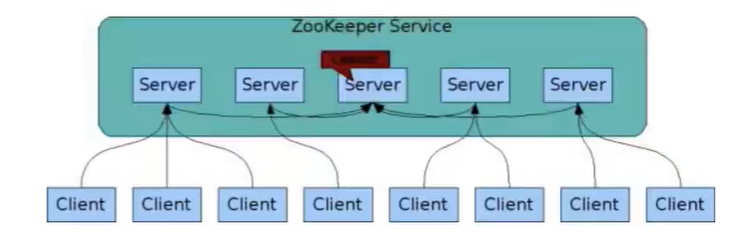
zk集群的主节点一般不给客户端直接连,而是用于服务器数据同步
ZAB协议定义的四种节点状态
- looking(巡视):选举状态,zk集群的节点在上线时,会进入到looking状态
- following:follower节点所处的状态
- leading:leader节点所处的状态
- observing:observer节点所处的状态
集群上线时的Leader选举过程
节点成为leader的条件,投票箱中有超半数的投票,所以zk集群中的结点数量一般是奇数个。
如三台zk服务器,主要票数达到2就能完成leader选举,而如果是4台,则需要票数达到3。
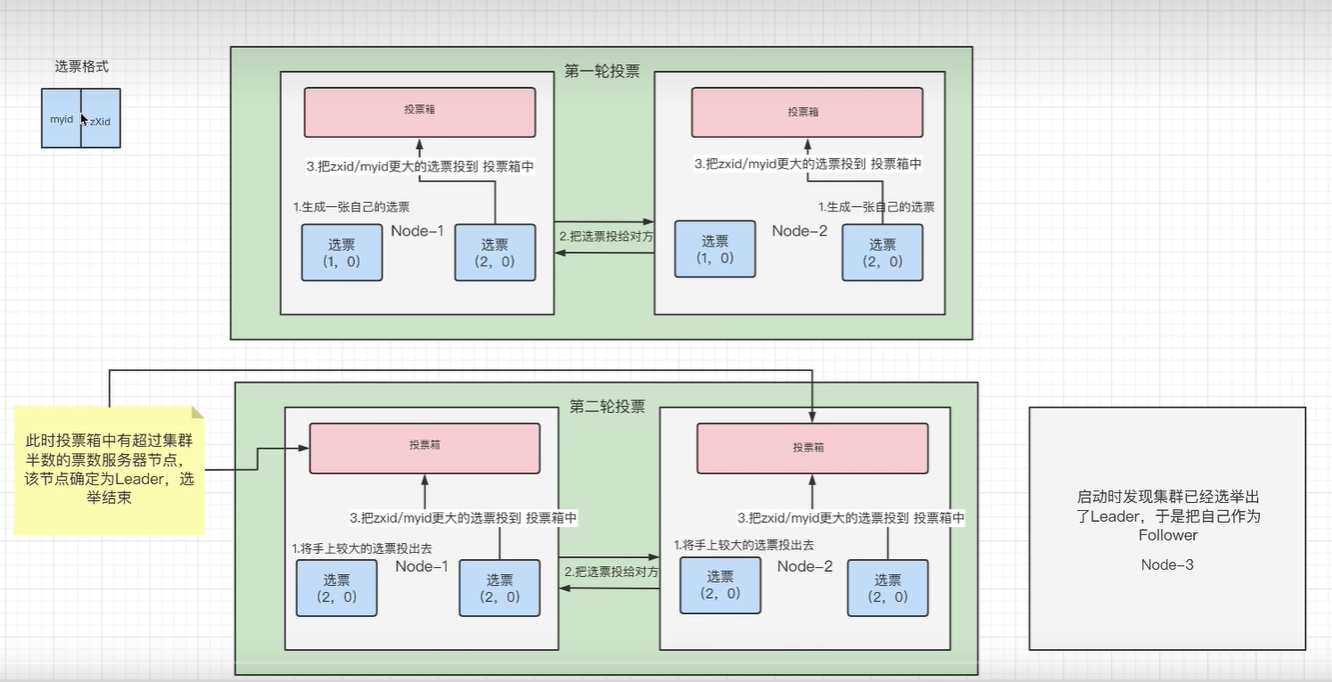
对于上文的集群配置,第二台服务器会成为leader,选举过程如下:
- 选票格式:
- myid:
- 选举时,如果事务id一样,就投myid比较大的
- zXid:
- 节点每进行一次增删改,这个事务id就会加1,因此这个事务id就描述了这个节点发生了多少次的变化
- 每次选举先比较zXid,因为如果zXid大,就表示这个节点的数据更新
- 开始选举
- 第一台服务器上线,不会进行选举
- 第二台服务器上线,开始选举
-
第一轮:
-
第二轮:第一轮还没选出票数过半的节点,继续选举
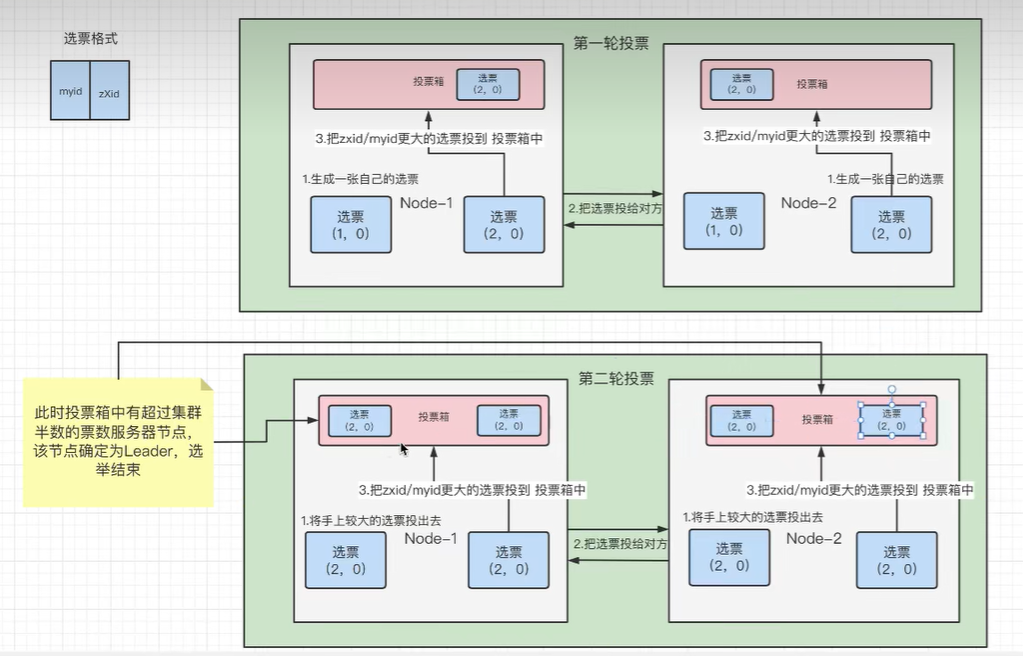
- 此时,节点3可能也启动了,那么节点1和节点2也会收到节点3的投票,第二轮结束后,如果没选出leader则还会进行第三轮选举(这种情况暂不考虑)
- 第二轮投票结束后,leader选举成功,选举过程结束
-
- 第三台服务器上线,发现leader已经存在了,自动成为follower
崩溃时的leader选举
leader建立完成后,leader周期性地向follower发送心跳(ping命令),当leader崩溃后,follower发现通道已关闭,
于是进入到looking状态,重新进行选举,此时集群不能对外提供服务
主从数据同步
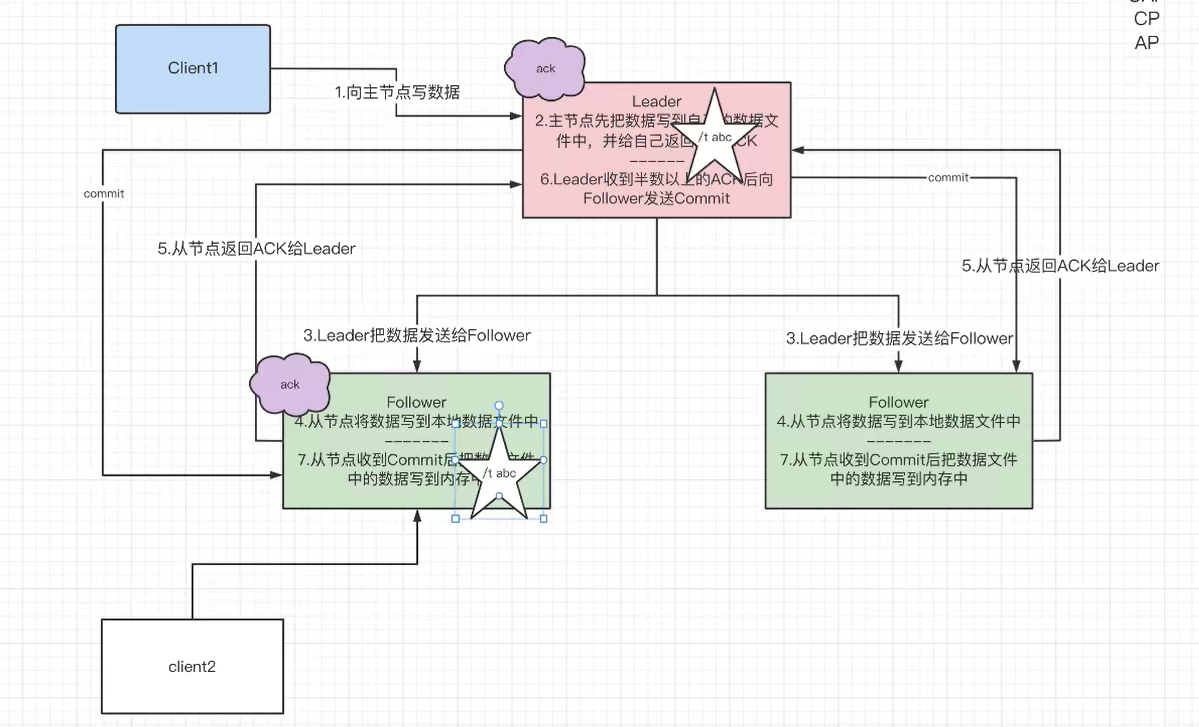
客户端连接一个zk服务器(follower),向该服务器写了一个数据DA,那么这个数据需要同步到所有服务器
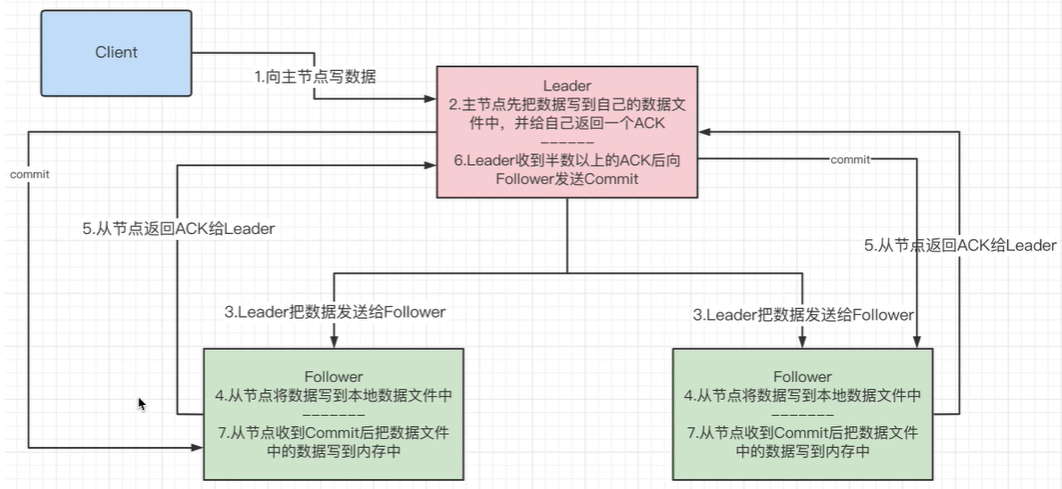
按步骤解释:
- 第2步:leader先将该数据
DA存储到自己的磁盘,而不能直接写内存,要写就所有服务器一起写- 这里的
所有是指集群一切正常的情况下
- 这里的
- 第4步:follower收到数据后,不能直接写内存,会造成有的follower中有数据
DA,有的却没有,造成数据不同步 - 第5,6,7步:只有leader收到的ack消息达到服务器数量的
半数以上,才能将数据写到内存- 为什么leader收到ack消息数量达到半数以上即可:
- 假设leader需要收到全部follower的ack消息,如果有少数几台服务器网络卡了,甚至掉线了,那么zk集群的写效率将会很低
- 为什么leader收到ack消息数量达到半数以上即可:
两阶段提交:写数据文件,再写内存的方式,防止有的服务器有数据,有的却没有
强一致性: 如果集群中的一台服务器与leader的通信出现故障了,那么这台服务器将暂时无法同步数据DA,但是等通信恢复了,数据DA还是会同步到这台服务器,现实各个服务器数据的顺序一致性
zk数据一致性
CAP理论
- 一致性(Consistency): 更新操作成功并返回客户端完成后,所有节点在同一时间的数据完全一直
- 可用性(Availability): 即服务一直可用,且是正常响应时间
- 分区容错性(Partition tolerance): 分布式系统在遇到某节点或网络分区故障时,仍能对外提供满足一致性或可用性的服务。 => 避免单点故障,就要进行冗余部署,冗余部署就相当于服务的分区,这样分区就具备了容错性。
这三项最多只能满足两项:
- CA: 比如银行、金融行业,发生网络故障时,宁愿停止服务(但其实不满足P,而不叫分布式系统了,因为不存在分区了)
- CP: 发生故障时,只读不写
- AP: 分布式系统一般都是尽量满足AP,舍弃C(退而求其次保证最终一致性)
如我向银行服务A存储了5k元,在服务器B同步服务器A的过程中(如网络阻塞),我查询资金的请求可能经过分布式网关被转发到了服务B:
- 若允许访问,则是追求AP,但此时两台服务器的数据是不一致
- 若不允许访问,则是追求CP,则此时银行系统是不可用的
BASE理论
CAP的一致性是强一致性,而Base理论的核心思想是即使无法做到强一致性,但可以采用适合的方式达到最终一致性
- 基本可用性:分布式系统出现故障时,允许损失部分可用性,保证核心可用。
- 双十一为了应对激增的流量,只提供浏览、下单功能,注册、评论等功能关闭
- 软状态:系统允许存在中间状态,而该中间状态不影响系统整体可用性。分布式存储中,一般一份数据会有至少三个副本,允许不同节点间副本同步的演示就是软状态的体现。
- 如双十一处于可用又不可用的中间状态
- 又比如客户端向zk的leader写了数据,但立马查询follower时数据查询不到,这个同步的过程系统就处于软状态,同步完后,就能查询到数据了
- 最终一致性:系统中所有副本经过一定时间后,最终能达到一致的状态。最终一致性是弱一致性的一种特殊情况
- 双十一过去后,电商系统会恢复如初
zk追求的一致性
zk追求的是CP,在进行选举时,集群不对外开放,选举完成后要进行数据同步,这一不可用的过程通常在30s~120s之间。
zk在收到半数以上的ack后(如果要收到全部follower的ack,会降低集群的同步效率),就会写内存,因此会造成部分follower没有同步数据:
zk在数据同步时,追求的并不是强一致性,而是顺序一致性(事务id的单调递增),如集群启动后,写如第一个数据后,写成功的服务器事务id为1,而写失败的服务器事务id为0,等再写第二个数据时,
网络阻塞的服务器一定会同步第一个数据,再同步第二个数据。也就是如果一个事务A在事务B之前执行,那么任何情况下,事务A都必须在事务B之前执行。
如果不保证顺序执行,同步失败过的服务器SA可能会产生旧值,比如第一个同步a=1失败,后续同步a=2,此时各个服务的a都应该是2,但SA由于错序执行,a又变成1了。
个人猜想:在分布式锁中,当服务在同步/znode时,各个服务器都加了锁/znode/write001,然后又释放了,如果SA同步失败后,又乱序执行,会导致这台服务器永远也访问不了这个数据了。
zk的NIO与BIO
早期zk用NIO,后面的版本用netty
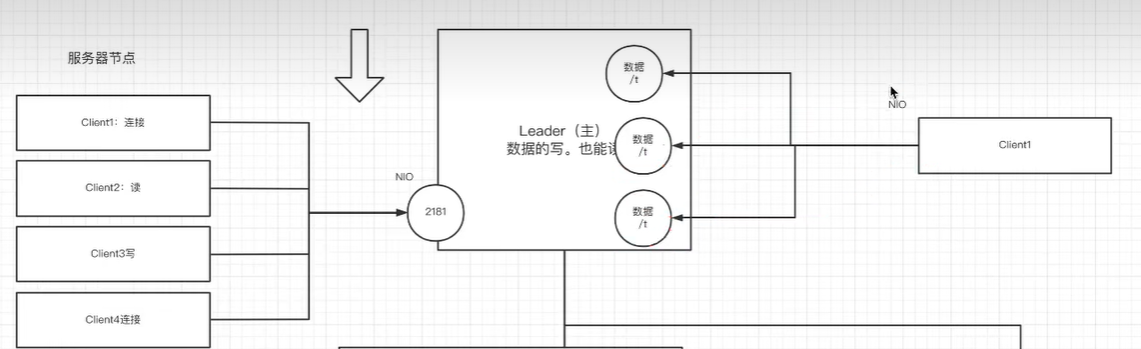
NIO:同步非阻塞的网络模型(类似多路复用)
- zk服务器连接多个客户端:所有客户端的请求发送给zk服务后,就继续执行其他动作
- 客户端监听多个zk节点:zk服务的多个事件发送客户端后,客户端处理这些事件的同时,继续监听
BIO:
- 在选举投票时,各个服务器需要建立socket连接
- leader向follower发送心跳,也需要建立socket连接