1.什么是线程?
- 在一个程序里的一个执行路线就叫做线程(thread)。更准确的定义是:线程是“一个进程内部的控制序列”
- 一切进程至少都有一个执行线程
- 线程在进程内部运行,本质是在进程地址空间内运行
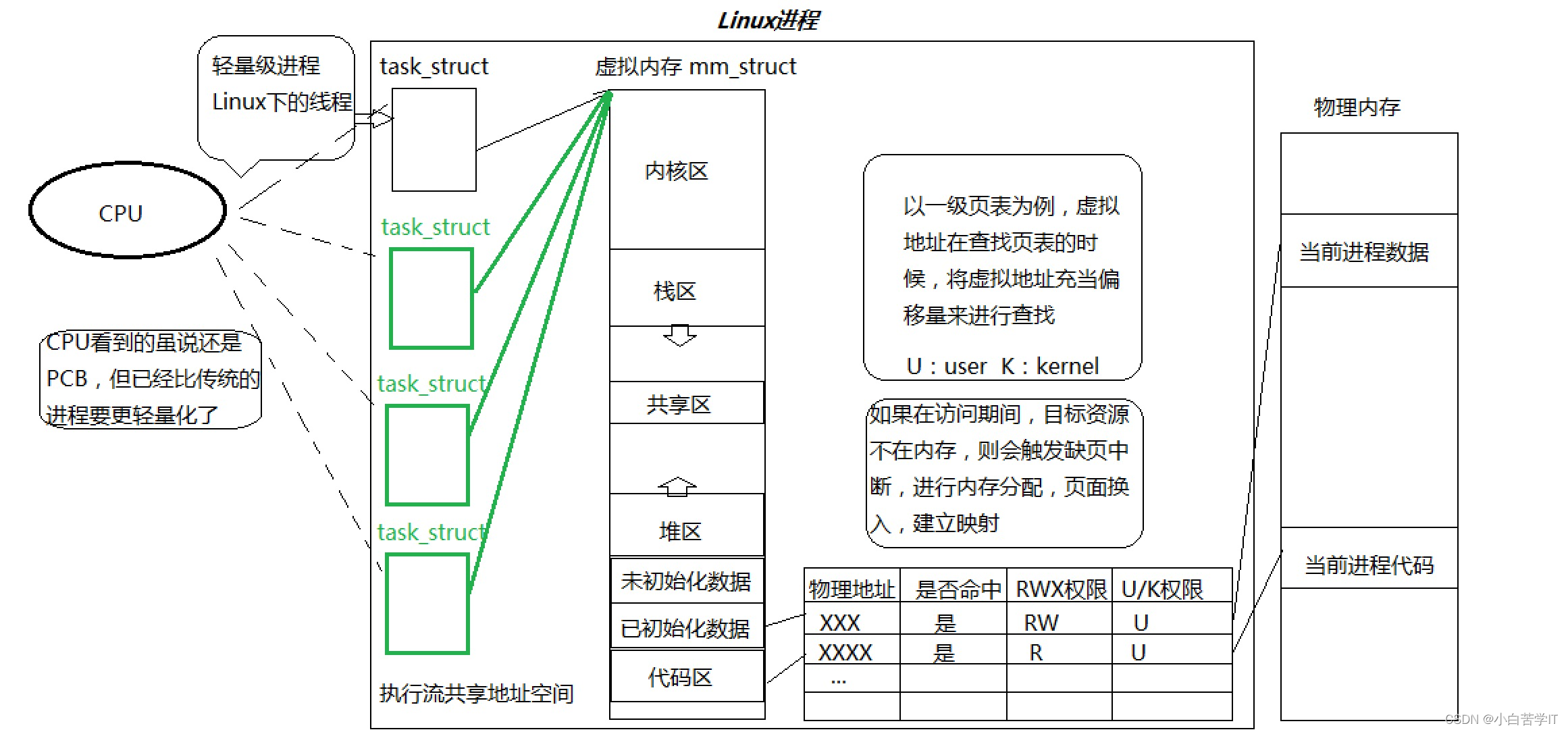
- 在Linux系统中,在CPU眼中,看到的PCB都要比传统的进程更加轻量化
- 透过进程虚拟地址空间,可以看到进程的大部分资源,将进程资源合理分配给每个执行流,就形成了线程执行流
2.线程的理解——如何看待进程/线程
下面我们用一个故事来理解:系统当中是以内存,CPU为资源的,但是分配这些资源是以进程为单位的,社会中像房子车子土地这些都是社会上的资源,而我们现实社会中分配资源的基本单位是以谁为基本实体的呢?是以家庭为单位的。虽然现在我们并不是所有人都买得起房子车子的,但是绝大多数人还是有这些社会资源的,假设我们构建出一个理想国,一个家庭比如说5口人在一栋房子里,爷爷奶奶,爸爸妈妈,我自己,在这一栋房子里住着这么多人都有各自的任务,比如说爷爷奶奶的任务就是好好度过自己的晚年生活,保证自己身体健康就可以了。爸爸妈妈呢就是好好工作,养家,多赚钱,保证我上学没有后顾之忧将来给我娶媳妇的时候买一栋房子等等,我自己现在是学习的阶段,所以我的任务呢就是好好学习。虽然一家五口人每一个人都做着不同的工作,但我们有没有一件共同的工作呢?共同的工作就是让家庭的日子过好,而这里说到的五口人就是5个线程,而这个家庭就是一个进程。
用代码进行验证:
写这段代码之前我们先来认识一下man手册中pthread_create这个接口是用来创建线程的:

这个接口是需要我们传四个参数,第一个参数,第二个参数都是一个指针,第三个参数是叫我们传一个返回值为void * ,参数为void *的函数指针其实就是一个函数的入口,第四个参数就是给第三个参数提供需要传的参数,是一个void *类型的指针。
#include<iostream>
#include<pthread.h>
#include<unistd.h>void * ThreadRoutine(void * arg)
{const char* threadname = (const char *)arg;while(true){std::cout<<"I am a new thread: "<<threadname<<std::endl;sleep(1);}
}int main()
{pthread_t tid;pthread_create(&tid,nullptr,ThreadRoutine,(void*)"thread 1"); //主线程while(true){std::cout<<"I am a main thread"<<std::endl;sleep(1);}return 0;
}运行结果:
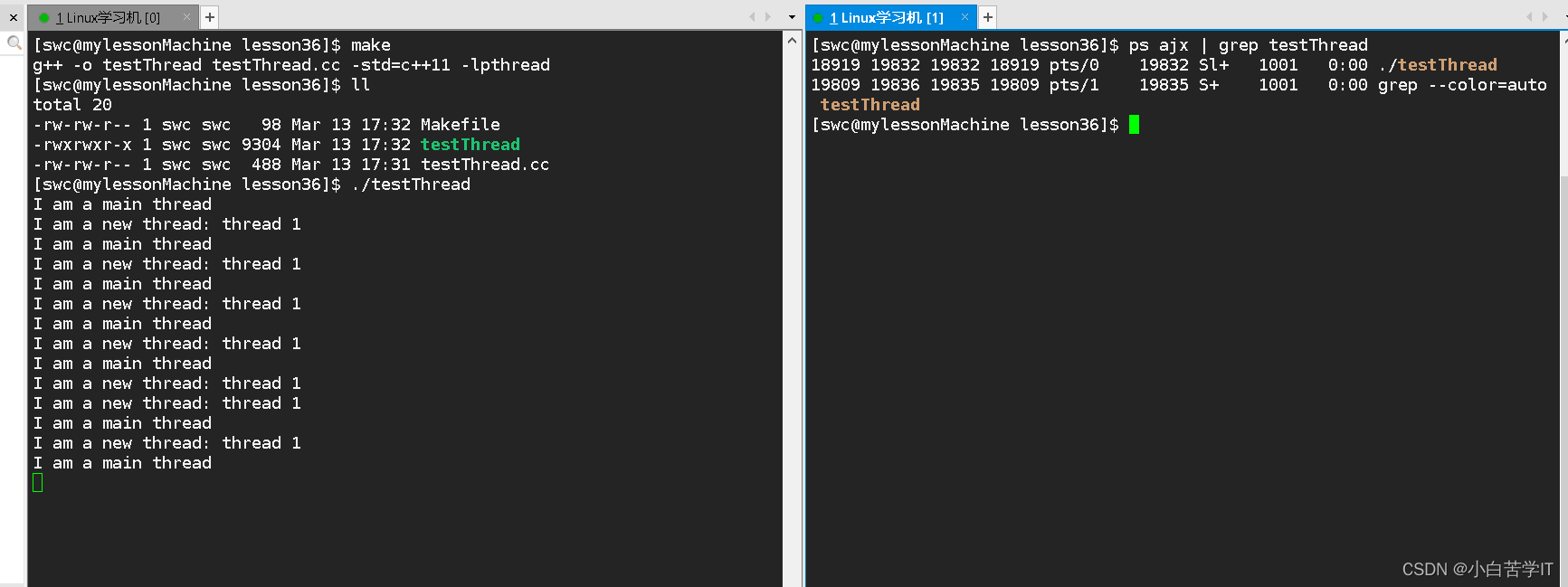
按照我们之前的单执行流来看待代码的话,这段代码是不可能连续执行两段死循环的,但是我们这里通过创建了一个线程让它去跑对应函数的死循环,而主线程跑main函数中的死循环使得两个死循环都在跑,然后我们检测发现只有一个进程在跑,这也就排除了多进程的清空,所以这也就验证了只有一个进程在跑这段代码,为了进一步验证,我们可以把他们的pid打出来看看:
把副线程执行死循环的打印语句改成:
std::cout<<"I am a new thread: "<<threadname<<", pid: "<<getpid()<<std::endl;把主线程打印语句改成:
std::cout<<"I am a main thread, pid: "<<getpid()<<std::endl;然后重新编译执行:
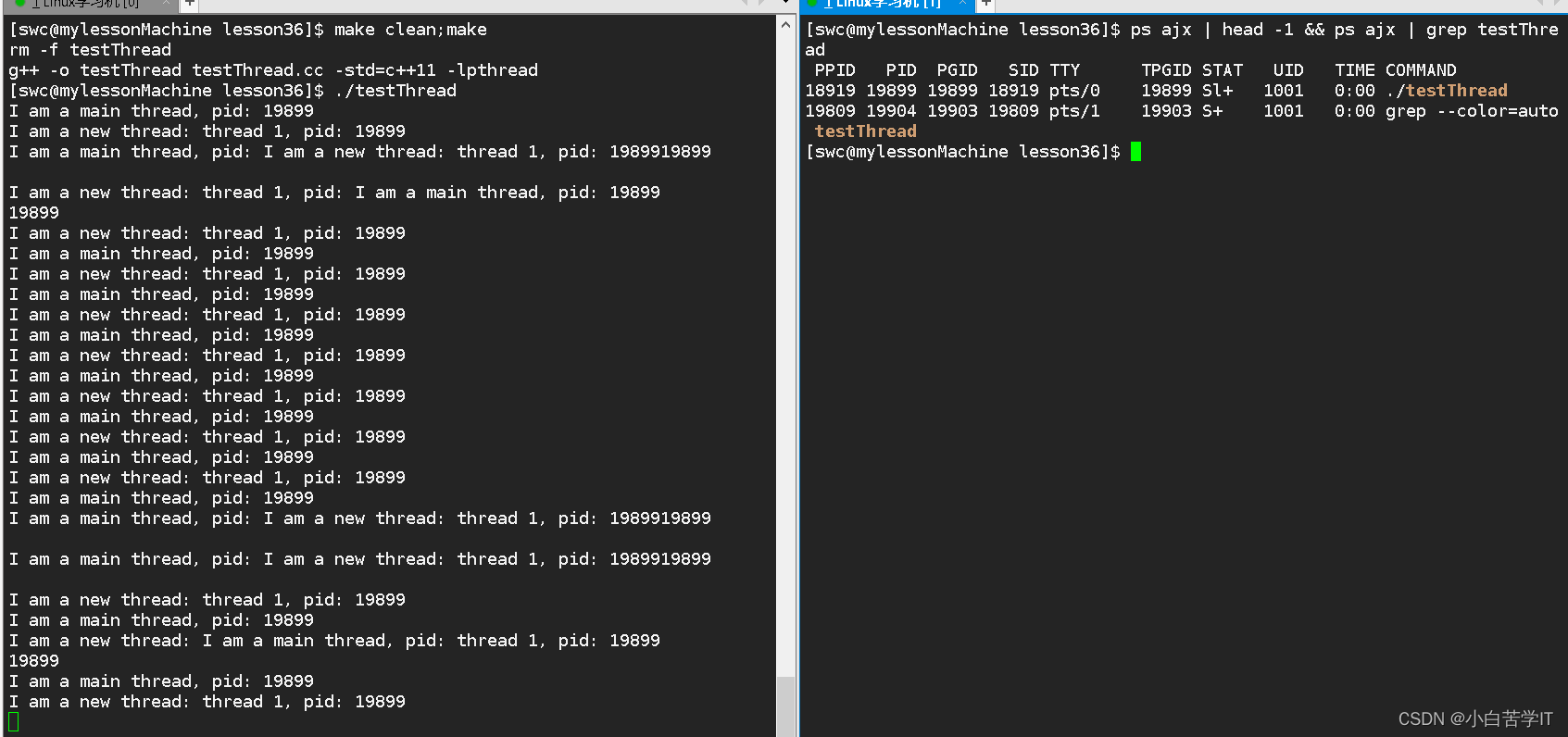
我们发现他们的pid是一样的,这也就说明了这两个线程是同一个进程的两个线程,所以他们两个线程获取的pid是同一个pid是合理的。
我们如何看出这两个线程的区别呢?下面我们学习一条新的指令来查看线程:
ps -aL

我们发现这两个线程(linux下是叫轻量级进程)的PID,TTY,TIME,CMD都是一样的,唯独LWP不一样:

而LWP就是轻量级进程(Light Weight Processes)的缩写。在操作系统层面上识别这两个轻量级进程是通过LWP来识别的,所以在操作系统调度的时候是看的是PID还是LWP呢?CPU调度的基本单位是线程,在linux系统上叫做轻量级进程,真实的操作系统调度的时候看的是LWP,而判断是否是主线程是通过判断PID是否等于LWP来进行判断的。
下面我们再修改一下代码:
#include<iostream>
#include<pthread.h>
#include<unistd.h>
#include<sys/types.h>
void * ThreadRoutine(void * arg)
{const char* threadname = (const char *)arg;while(true){std::cout<<"I am a new thread: "<<threadname<<", pid: "<<getpid()<<std::endl;sleep(1);}
}int main()
{pthread_t tid;pthread_create(&tid,nullptr,ThreadRoutine,(void*)"thread 0"); sleep(3);pthread_t tid1;pthread_create(&tid1,nullptr,ThreadRoutine,(void*)"thread 1"); sleep(3);pthread_t tid2;pthread_create(&tid2,nullptr,ThreadRoutine,(void*)"thread 2"); sleep(3);pthread_t tid3;pthread_create(&tid,nullptr,ThreadRoutine,(void*)"thread 3"); sleep(3);//主线程while(true){std::cout<<"I am a main thread, pid: "<<getpid()<<std::endl;sleep(1);}return 0;
}运行结果:

之前我们所看到的都是进程只有一个执行流的代码,但是今天是一个进程有多执行流的代码。其实线程就是CPU调度的基本单位,Linux内核服用了进程代码,用进程PCB模拟充当了线程,Linux中所有的线程都叫做轻量级进程,如果谈进程那就不能只谈执行流,还需要谈进程地址空间和页表。
下面再用一段代码来看看 现象:
#include<iostream>
#include<pthread.h>
#include<unistd.h>
#include<sys/types.h>int gcnt = 100;void * ThreadRoutine(void * arg)
{const char* threadname = (const char *)arg;while(true){std::cout<<"I am a new thread: "<<threadname<<", pid: "<<getpid()<<"gcnt: "<<gcnt<<"&gcnt: "<<&gcnt<<std::endl;gcnt--;sleep(1);}
}int main()
{pthread_t tid;pthread_create(&tid,nullptr,ThreadRoutine,(void*)"thread 0"); sleep(3);while(true){std::cout<<"I am a main thread, pid: "<<getpid()<<"gcnt: "<<gcnt<<"&gcnt: "<<&gcnt<<std::endl;sleep(1);}return 0;
}运行结果:

这段代码的运行结果说明对于全局变量,有一个线程修改了该全局变量的值,另一个线程立马就能看到,为什么呢?因为这些线程共享同一个进程地址空间,其实还有堆栈,共享区都是可以共享的。而相对于进程间通信是需要满足让不同的进程看到同一份资源的,但是让线程看到同一份资源比进程看到同一份资源更简单,当然线程通信是不安全的,但是确实更简单。
从上面的讲解我们知道了,创建进程是需要创建PCB,进程地址空间,页表的,而创建线程是需要在进程的基础上创建PCB就可以了,所以说叫做轻量级进程,但是在调度上谈进程与线程又有什么区别呢?调度的话切换的时候存在同一个进程里的线程间切换,也就是切换后下一个线程是该进程里的一个线程,这种切换像地址空间,页表这些东西都是不用切换的,只需要把进程中产生保存在寄存器中的一些临时性数据就可以了,而还有就是当前进程的线程切换后是另一个进程的主线程这种情况是需要把所有的寄存器全部切换的,将保存的上下文交给进程,这就也就是叫做我们之前理解的进程间切换。但是这并不是把线程叫做轻量级进程的主要原因,主要原因其实是CPU里面其实还有一个cache缓存,下面我们可以用一条命令来查看:
这是cpu集成的一个硬件级别的cache,比如说当前访问的是我们的第10行代码,那么有较大概率下一次访问的是第11行代码,也有较大概率访问第12行的代码,也就是cpu会有较大的概率访问正在访问的代码附近的代码,虽然有存在一些特殊情况像函数跳转,程序替换,但这些都是少量情况,我们把这种特性叫做局部性原理。我们之前说会有一个非常大的应用程序是目前加载一部分的,但是如何知道该加载的是哪一部分呢?其实这就需要用到我们的局部性原理了,就是按代码顺序加载,这给我们的预加载机制提供了理论基础,同样的cpu也有cache缓存,所以也可以先加载一部分附近的代码,这样会使cpu执行效率更高。我们一般把放到cpu缓存的数据叫做热数据,我们的线程间 切换是不用重新预加载cache里面的热数据的,而进程间 切换需要重新预加载cache中的热数据,所以这就是为什么线程间切换比进程间切换更高效的主要原因。时间片是以进程为单位进行分配的,所以进程内部的线程要对进程分配的时间片进行瓜分,因为时间片也是资源。
3.重谈一次地址空间——虚拟地址->物理地址
我们前面谈文件系统IO的时候说过,文件系统IO的基本单位大小是4KB,叫做文件块。
在操作系统层面上,物理内存与磁盘进行IO交互的时候,在硬件层面上,磁盘可以把数据导入内存,内存也可以把数据写入磁盘,其实从硬件角度就是把数据从一个设备拷贝到另一台设备,拷贝的过程其实在硬件上是支持的,至于怎么支持就跟设备自身的特征有关系,比如说磁盘内部是有盘片的,盘片是有对应的磁极的,我们可以通过磁头修改盘片特定的南北极就可以修改磁盘的01序列, 在计算机组成原理里面,有最基本的硬件电路,硬件电路里面有一个叫触发器,门电路,物理内存我们可以想象成由无数个充电的门电路或者是触发器构成,说白了物理内存就是无数个小的可以存01的高低电平的硬件电路,所以我们把数据写入物理内存本质是给物理内存进行充放电的过程,所以物理不能断电,一旦断电就会使数据丢失,所以数据从一个设备写入到另一个设备本质就是将电路信号从一个设备给另一个设备进行充电的过程,比如说内存将数据写入磁盘就是通过向物理内存的指定位置发送一个电脉冲的过程。这是最基本的,我们之前在谈冯诺依曼体系结构的时候说过,计算机里整机的效率,数据从一个设备到另一个设备,每一个设备都有各自的特性,本质就是一次充放电的过程,所以我们承认数据是可以在设备间进行移动的。
可是呢,从哪里开始读取呢?在磁盘的什么位置,加载对应的数据加载多少呢?它的大小是多少呢?它的权限是多少呢?它的类型是多少呢?它的特征属性是什么?什么时候加载?所有的这些东西都与硬件无关,这是更上层的东西,是通过文件系统来进行管理的,所以呢我们就需要有一个文件系统的东西,文件系统就会允许我们根据文件路径找到对应的文件打开,然后就可以通过文件的属性和内容通过inode和datablock把我们的属性和内容就可以加载到内存中,这就是我们文件加载或读取的过程,一个inode对应一个文件,一个文件的属性都在文件系统特定的分区的分组里面的特定的inode,所以inode也是数据,而文件内容也是数据,所以无论是属性还是内容都是数据,而物理内存和磁盘进行数据交互的时候是以4KB为基本单位的,所以说在文件系统层面上,你用户看这个文件是一个可执行程序,可是在文件系统的角度上来看其实是这个可执行程序是由多个4KB的块组成的,这种我们一般就称之为ELF数据段,也就是说这个文件的数据块每一个都是4KB,而对于我们的文件系统来说呢,它根本就不关心是文件的内容还是属性,它首先考虑的是把4KB大小的块先加载到内存当中,数据在写入修改时都是以4KB为基本单位的, 实际上文件属性和内容是分开存的,但是在用户看来文件属性和内容是一起的,所以将来我们想要读取文件的大小的时候对于操作系统来说,它根本就不关心我读到的是文件的属性还是内容,或者不直接关系,它首先要解决的是我们4KB的大小先换入内存当中,如果数据有修改就再写入对应的内容中,所以呢,计算机在设计的时候可执行程序也用4KB的大小分好了,同样的,可执行程序都按照4KB的大小分成了一块块的,所以物理内存同样的也是以4KB的大小将物理内存一块一块的分好的。所以我们把磁盘上文件以4KB为单位的块叫做页帧,而把物理内存划分成4KB的块叫做页框,把文件系统IO的基本单位4KB叫做page size.其实正是文件管理,内存管理,进程管理,背后的编译器所促成的一个文件系统IO的基本单位和内存划分的基本单位为4KB.而文件除了内容和属性,还有一个就是对应的文件缓冲区,所以文件的缓冲区的本质是本质就是把一个文件相关的一些内容或者属性放在内存不同位置的关联起来,所以文件的缓冲区就是struct file与内存中属于该文件的数据所构成的关联关系。如果我们要把比如说4GB的物理内存划分成页框可以划分成100多万个页框。所以操作系统怎么知道内存分配了多少页框,以及这些页框的使用情况?那么这些情况操作系统要不要知道呢?答案是要的,如何管理?先描述再组织。把页框描述成一个struct page里面有描述一个page的使用情况,以及page的属性等等,然后组织一个struct page pages[1048576];这么大的数组,数组下标与页框就有一个对应的映射关系,所以对内存进行管理就变成了对数组内容的增删查改。但是实际的内存管理肯定是要比这个例子更复杂的。我们知道进程的虚拟地址空间是通过页表来进行映射的,但是地址空间可是有2^32个地址,如果每一个地址都在页表上进行映射的话,关页表当中的页表项,但是如果我们的页表项要用到10个字节的话,那么物理内存都装不下页表,因为这样的页表太大了,算下来关存页表就需要40GB的空间。那么虚拟地址与物理地址之间到底是如何转化的呢?我们所知道的虚拟地址是32个比特位的。整个虚拟地址不是用一个整体来看的,而是将他拆成了三个部分,前十个比特位称之为页目录有1024个页目录中的内容存放的是对应的页表,中间十个比特位称之为页表也是1024个,而页表的内容存放的是物理内存的页框的起始地址。接下来还有12个比特位就是4096个比特位也就是4KB,这12个比特位我们可以用来当偏移量,用起始地址+偏移量就可以找到对应的物理地址了。页表其实不会被全部一次性使用完,也就是进程地址空间的4GB大小的地址并不会全都使用,而是通过需要执行所需要的指令的时候通过发生缺页中断来进行加载所需要的内容再创建对应的页表,然后把地址写入对应的页表当中去,CPU当中有寄存器保存当前进程使的页目录起始地址,eip寄存器保存的虚拟地址,而MMU完成虚拟地址到物理地址的转化,所以虚拟地址到物理地址的转化工作是在CPU内部转化的。