| 分类 | 内容 |
|---|---|
| 论文题目 | RLHF-V: Towards Trustworthy MLLMs via Behavior Alignment from Fine-grained Correctional Human Feedback |
| 作者 | 作者团队:由来自清华大学和新加坡国立大学的研究者组成,包括Tianyu Yu, Yuan Yao, Haoye Zhang, Taiwen He, Yifeng Han, Ganqu Cui, Jinyi Hu, Zhiyuan Liu, Hai-Tao Zheng, Maosong Sun, Tat-Seng Chua。 |
| 发表年份 | CVPR 2024 |
| 摘要 | 文章针对多模态大型语言模型(MLLMs)在生成与图片不符的文本(即幻觉问题)提出了RLHF-V框架。通过从细粒度的人类反馈中学习,显著减少基础MLLM的幻觉率,提高了模型的可信度和实用性。 |
| 引言 | 强调了MLLMs在多模态理解、推理和交互方面的能力,同时指出其存在的幻觉问题,即生成与关联图片不符的文本,这一问题限制了MLLMs在实际应用中的可信度。 |
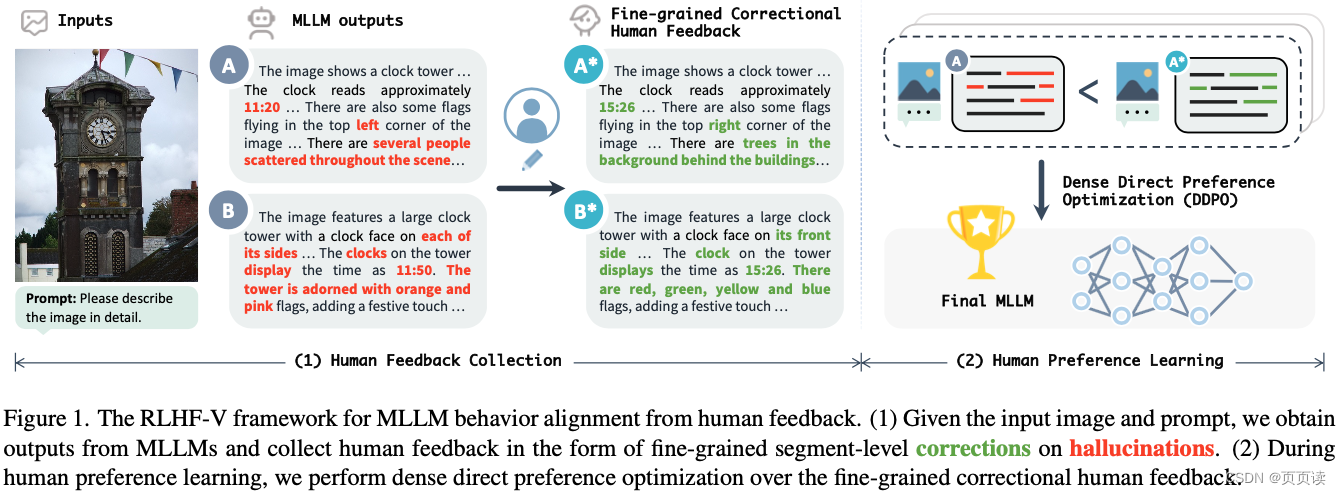
| 主要内容 | RLHF-V框架:论文提出了RLHF-V,一种旨在通过细粒度人类反馈对多模态大型语言模型(MLLMs)行为进行校准的框架,以解决模型产生的幻觉问题,即生成的文本与关联图片不符。这种框架的关键思想是通过人类偏好的形式收集细粒度的反馈,并利用这些反馈来优化模型,从而提高其在处理多模态输入时的可靠性和准确性。 细粒度的人类反馈收集:RLHF-V的一个创新之处在于其收集人类反馈的方式。不同于以往依赖粗粒度或整体排名的反馈,RLHF-V要求人类注释者对模型输出中的具体错误或幻觉部分进行细节级的校正。这种细粒度的反馈不仅提供了更明确的学习信号,而且还避免了因语言多样性或偏见而引起的误导。 密集直接偏好优化(DDPO):为了有效利用收集到的细粒度人类反馈,RLHF-V采用了一种名为密集直接偏好优化(DDPO)的技术。DDPO是一种新的优化策略,专门设计用来处理细粒度的反馈,并能够直接在偏好数据上进行模型训练。通过强化学习方法,DDPO能够精确地调整模型的行为,以减少幻觉产生,增强模型输出的事实依据。 |
| 实验 | 实验设计:为了验证RLHF-V的有效性,作者在五个基准数据集上进行了广泛的实验。这些实验旨在评估RLHF-V在减少幻觉、提高模型可靠性方面的性能。实验包括自动评估和人类评估两部分,分别从模型的准确性、可信度以及与人类偏好的一致性进行评价。 基准数据集:实验涉及的基准数据集包括图像描述、视觉问答和多模态对话等任务,旨在全面评估RLHF-V在多种多模态交互场景下的表现。通过与当前最先进的MLLMs(包括未使用RLHF-V优化的基线模型)进行对比,实验结果展示了RLHF-V在这些任务上的显著改进。 主要结果:实验结果表明,使用RLHF-V框架进行优化的MLLMs在减少幻觉、提高文本与图片一致性方面表现出色。具体而言,与基线模型相比,RLHF-V能够显著降低幻觉率,改善模型输出的可信度和准确性。在人类评估方面,RLHF-V优化后的模型产生的输出更加符合人类的偏好和期望,显示出对复杂多模态输入的更好理解。 效率与性能:除了提升模型性能,RLHF-V还显示出良好的数据和计算效率。即使在有限的标注数据下,RLHF-V也能通过其细粒度的反馈学习机制有效地改进模型行为,证明了其在实际应用中的可行性和效率。 |
| 结论 | RLHF-V通过细粒度的人类反馈校准MLLMs的行为,显著提高了模型的可信度,并在开源MLLMs中取得了最先进的性能。 |
| 阅读心得 | 亮点:
|
【Paper Reading】6.RLHF-V 提出用RLHF的1.4k的数据微调显著降低MLLM的虚幻问题
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.hqwc.cn/news/540107.html
如若内容造成侵权/违法违规/事实不符,请联系编程知识网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章
WOA-GRU多输入分类预测 | 鲸鱼优化算法-门控循环单元神经网络 | Matlab
目录
一、程序及算法内容介绍:
基本内容:
亮点与优势:
二、实际运行效果:
三、部分程序:
四、完整程序下载: 一、程序及算法内容介绍:
基本内容: 本代码基于Matlab平台编译&a…

会声会影2023旗舰版VideoStudio Ultimate 2023 v26.1.0.268 中文免费版(附激活补丁)
Corel VideoStudio Ultimate 2023(会声会影2023)是Corel旗下一款功能强大的专业视频制作软件的视频编辑软件及视频剪辑软件,非常专业的使用效果,会声会影2023中文版可以针对剪辑电影进行使用,非常强大的色彩校正方式&a…
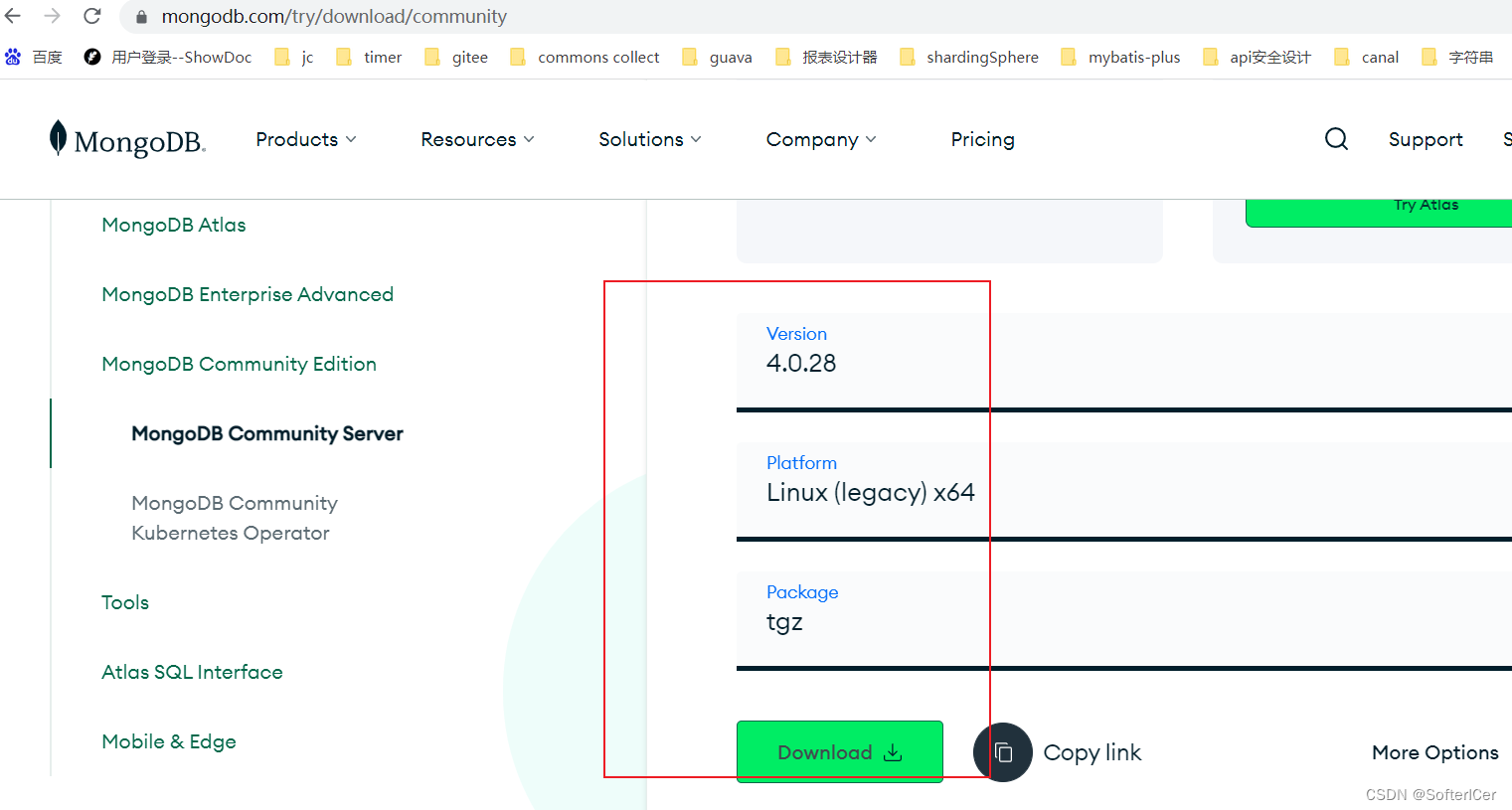
mongodb-linux下载安装
下载地址
Download MongoDB Community Server | MongoDB 选择 下载 下载后是 mongodb-linux-x86_64-4.0.28.tgz 解压 tar -zxvf mongodb-linux-x86_64-4.0.28.tgz 创建data 和 log目录 cd /data/xxx/mongodb/mongodb-linux-x86_64-4.0.28
mkdir data
mkdir log 创建配置文件…

【危化品泄漏源定位】基于改进哈里斯鹰优化算法的危化品泄漏源定位算法 溯源定位算法【Matlab代码#63】
文章目录 【获取资源请见文章第7节:资源获取】1. 算法概述2. 原始哈里斯鹰算法(HHO)3. 改进哈里斯鹰算法(IHHO)3.1 动态自适应逃逸能量3.2 动态扰动策略 4. 构建源强和位置反算模型5. 部分代码展示6. 仿真结果展示7. 资…

【JavaEE -- 多线程3 - 多线程案例】
多线程案例 1.单例模式1.1 饿汉模式的实现方法1.2 懒汉模式的实现方法 2. 阻塞队列2.1 引入生产消费者模型的意义:2.2 阻塞队列put方法和take方法2.3 实现阻塞队列--重点 3.定时器3.1 定时器的使用3.2 实现定时器 4 线程池4.1 线程池的使用4.2 实现一个简单的线程池…
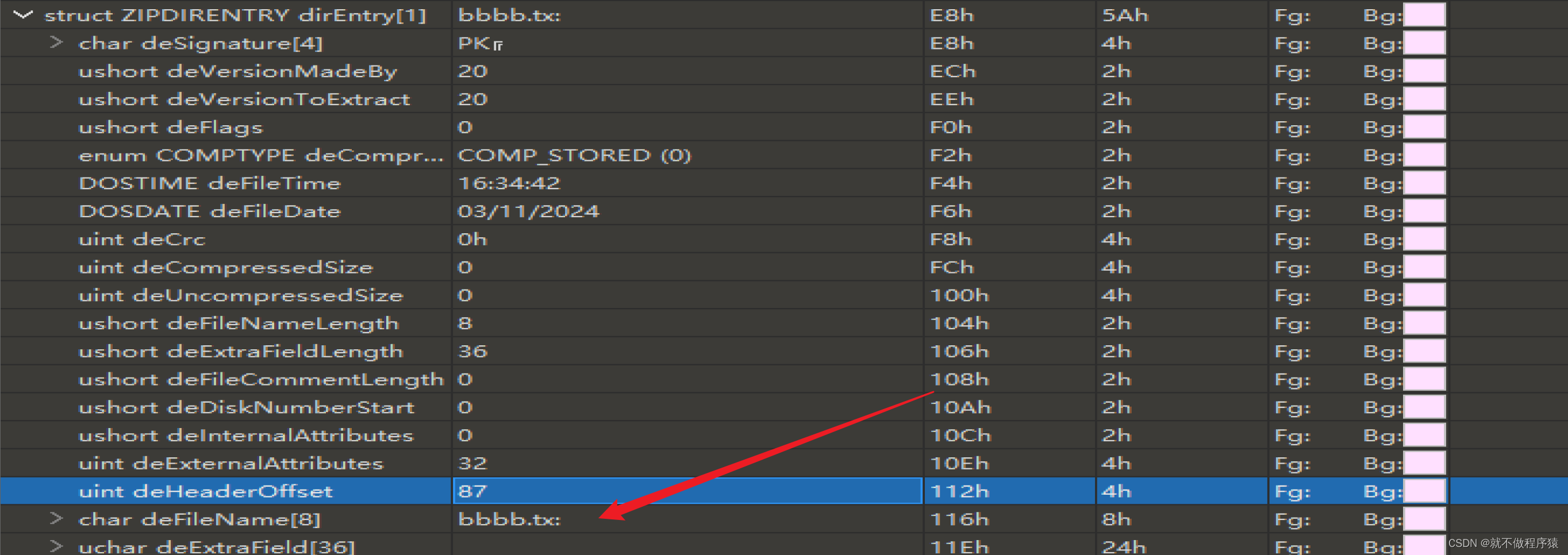
phpcms上传漏洞
原始漏洞
漏洞原理:我们上传一个zip的压缩包,它会解压然后删除其中不是.jpg .gig .png的文件 function check_dir($dir):这是一个PHP函数的定义,它接受一个参数 $dir,代表要检查的目录路径。 $handle opendir($dir)…

Gartner最新生成式AI报告:300个行业用例揭示GenAI垂直行业发展的五个关键的不确定性
我们对各行业 GenAI 用例的分析揭示了高管在规划工作时面临的五个关键不确定性。首席信息官可以利用这项研究来战略性地应对这些不确定性,并最大限度地提高 GenAI 投资的成果。 主要发现 我们对 300 多个特定行业的生成式 AI 用例的分析揭示了五个关键的不确定性&am…

java将oss链接打包成压缩包并返回
博主介绍: 22届计科专业毕业,来自湖南,主要是在CSDN记录一些自己在Java开发过程中遇到的一些问题,欢迎大家一起讨论学习,也欢迎大家的批评指正。 文章目录 前言解决注意结果展示 前言
需求:在用户列表中的…
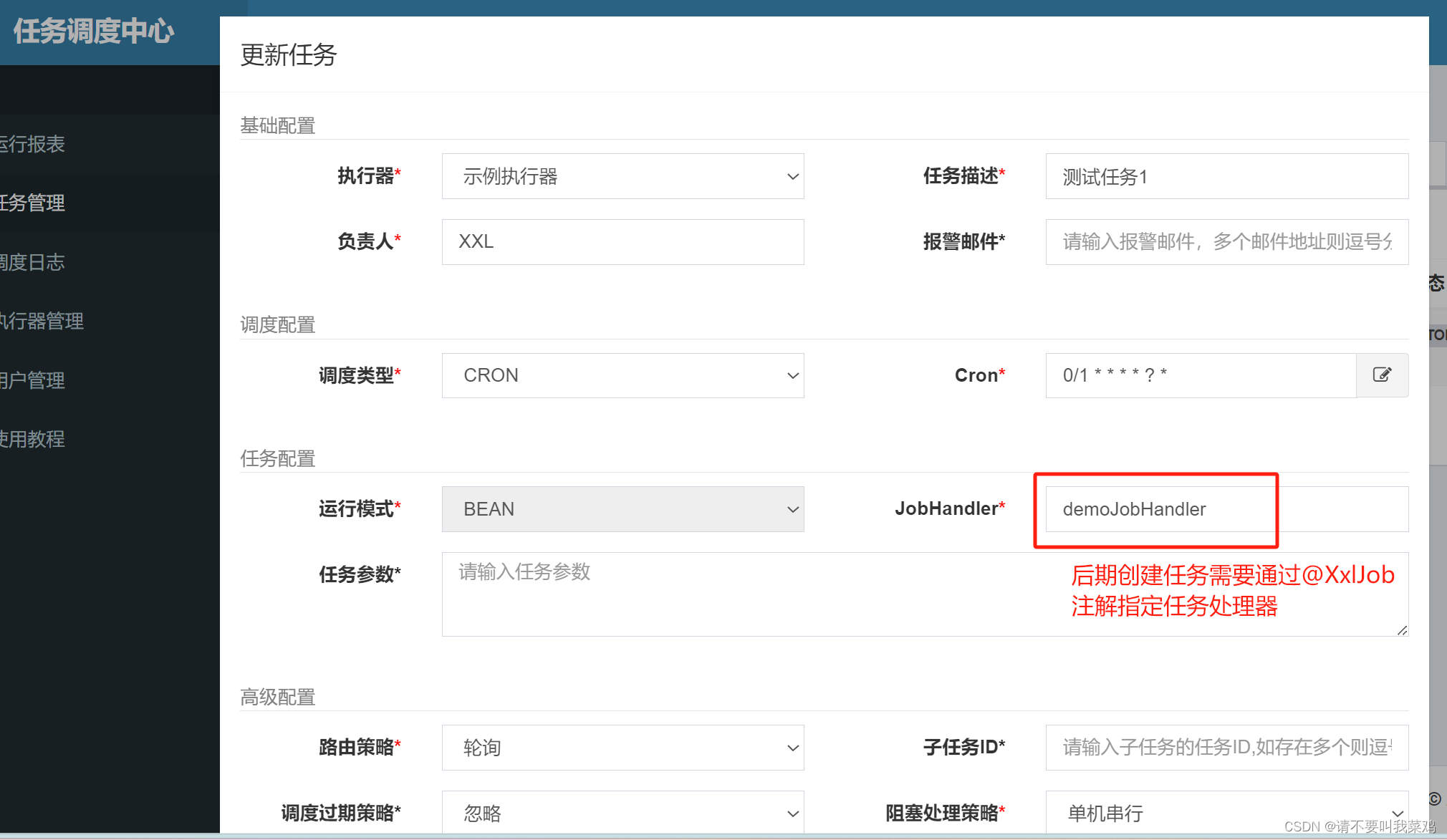
SpringTask实现的任务调度与XXL-job实现的分布式任务调度【XXL-Job工作原理】
目录 任务调度
分布式任务调度 分布式任务调度存在的问题以及解决方案
使用SpringTask实现单体服务的任务调度
XXL-job分布式任务调度系统工作原理
XXL-job系统组成
XXL-job工作原理
使用XXL-job实现分布式任务调度
配置调度中心XXL-job
登录调度中心创建执行器和任务 …
渗透测试实战思路分析
免责声明:文章来源真实渗透测试,已获得授权,且关键信息已经打码处理,请勿利用文章内的相关技术从事非法测试,由于传播、利用此文所提供的信息或者工具而造成的任何直接或者间接的后果及损失,均由使用者本人…
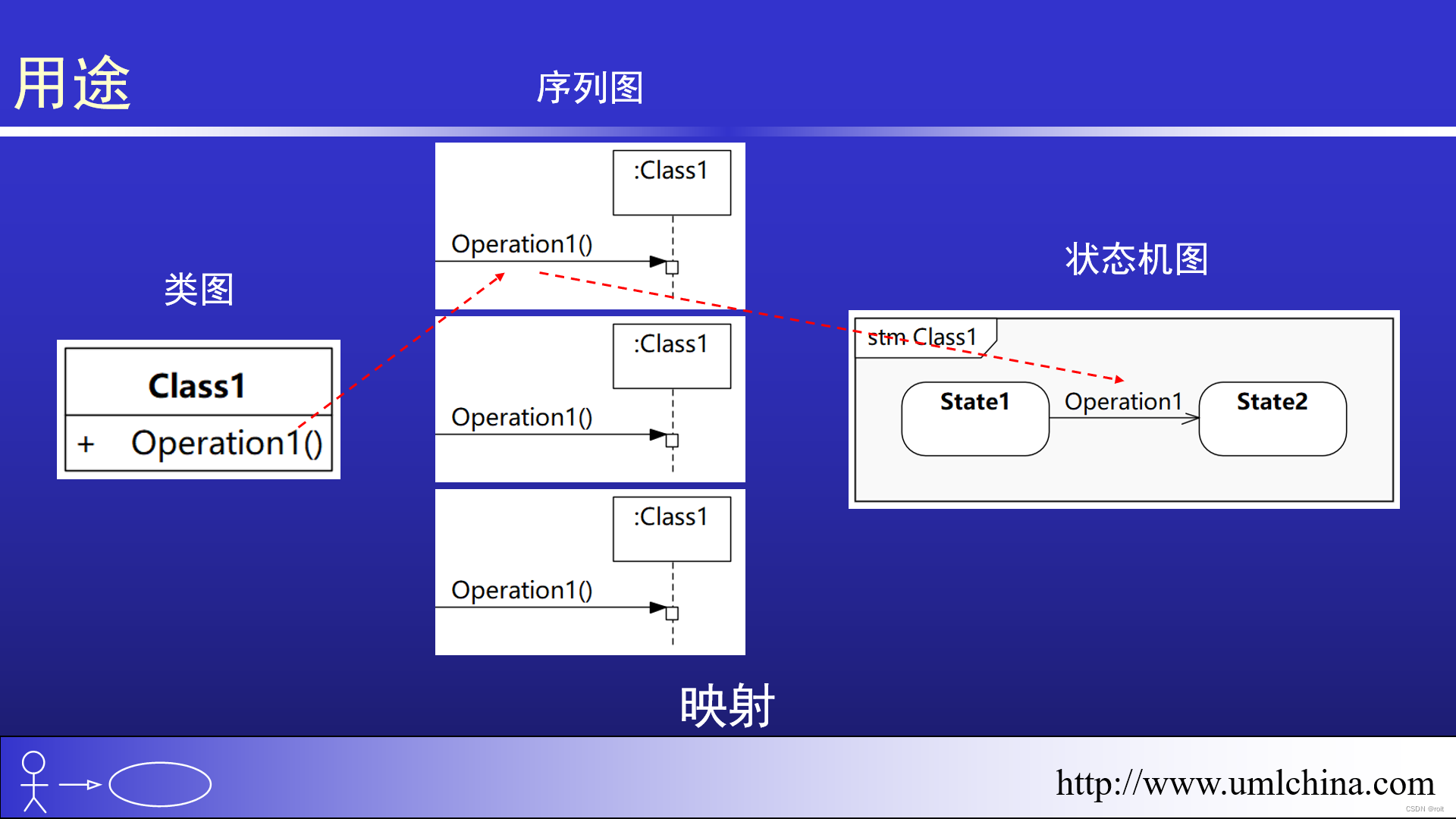
状态机高阶讲解-05
887 00:38:03,240 --> 00:38:04,330 在外面
888 00:38:05,130 --> 00:38:06,120 有
889 00:38:06,400 --> 00:38:08,475 请求进来的时候
890 00:38:08,475 --> 00:38:10,550 有消息进来的时候
891 00:38:11,630 --> 00:38:14,000 那么经过我们状态机
892 0…
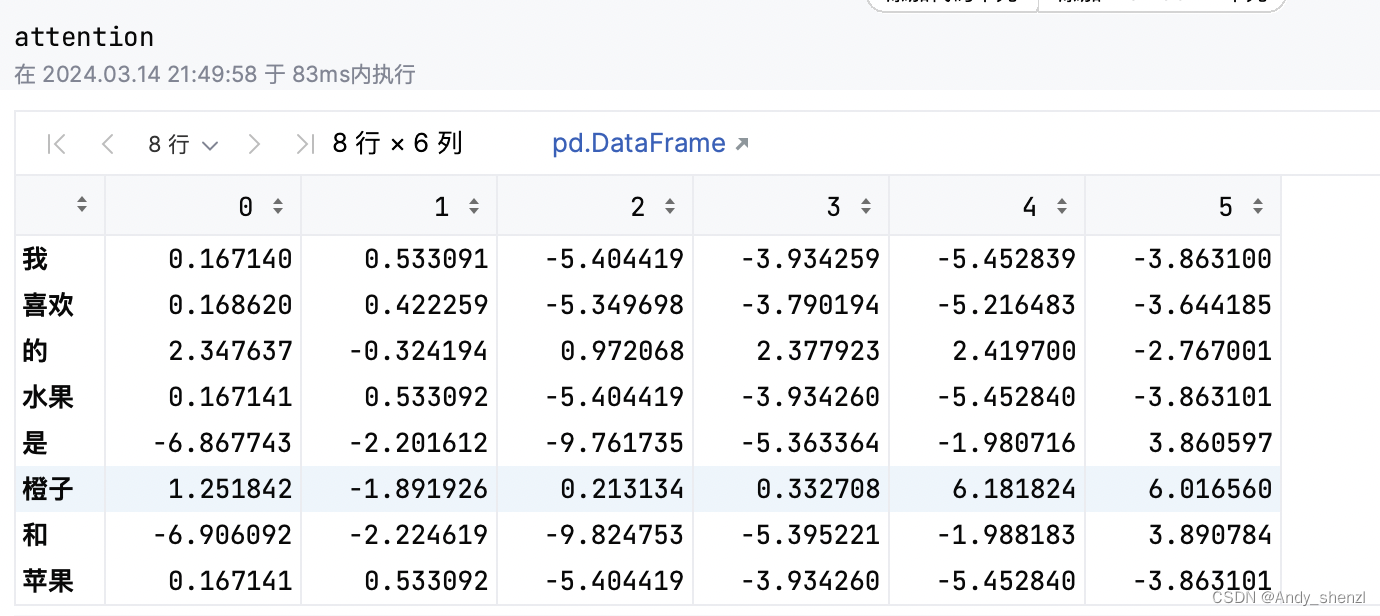
白话transformer(三):Q K V矩阵代码演示
在前面文章讲解了QKV矩阵的原理,属于比较主观的解释,下面用简单的代码再过一遍加深下印象。
B站视频 白话transformer(三) 1、生成数据
我们呢就使用一个句子来做一个测试,
text1 "我喜欢的水果是橙子和苹果&…