leetcode 76. 最小覆盖子串
- leetcode 76. 最小覆盖子串 | 困难难度
- 1. 题目详情
- 1. 原题链接
- 2. 基础框架
- 2. 解题思路
- 1. 题目分析
- 2. 算法原理
- 3. 时间复杂度
- 3. 代码实现
- 4. 知识与收获

leetcode 76. 最小覆盖子串 | 困难难度
1. 题目详情
给你一个字符串 s 、一个字符串 t 。返回 s 中涵盖 t 所有字符的最小子串。如果 s 中不存在涵盖 t 所有字符的子串,则返回空字符串 “” 。
注意:
对于 t 中重复字符,我们寻找的子字符串中该字符数量必须不少于 t 中该字符数量。
如果 s 中存在这样的子串,我们保证它是唯一的答案。
示例 1:
输入:s = “ADOBECODEBANC”, t = “ABC”
输出:“BANC”
解释:最小覆盖子串 “BANC” 包含来自字符串 t 的 ‘A’、‘B’ 和 ‘C’。
示例 2:
输入:s = “a”, t = “a”
输出:“a”
解释:整个字符串 s 是最小覆盖子串。
示例 3:
输入: s = “a”, t = “aa”
输出: “”
解释: t 中两个字符 ‘a’ 均应包含在 s 的子串中,
因此没有符合条件的子字符串,返回空字符串。
提示:
m == s.length
n == t.length
1 <= m, n <= 105
s 和 t 由英文字母组成
进阶:你能设计一个在 o ( m + n ) o(m+n) o(m+n)时间内解决此问题的算法吗?
1. 原题链接
leetcode 76. 最小覆盖子串
2. 基础框架
● Cpp代码框架
class Solution {
public:string minWindow(string s, string t) {}
};
2. 解题思路
1. 题目分析
( 1 ) (1) (1) 本题要求 找s中涵盖t中所有字符的最短子串。这里涵盖的意思就是不小于,即大于等于的意思。只要找到s的子串满足t中字符频次小于等于s子串字符频次,对于存在于s子串中而在t中不存在的字符则没有要求。
( 2 ) (2) (2) 本题要求返回的结果是一个字符串,为了方便表示一个字符串,我们使用起始下标begin,字符串长度minlen就能表示在s中的任意一个子串。
( 3 ) (3) (3) 首先想到暴力枚举 + 字符哈希表思路:
哈希表1hash1记录t串中字符频次;哈希表2hash2记录s的子串中字符频次;
对字符串s,下标left从[0, s.size-1]依次作为子串的起始位置,下标right以left开始遍历s,每次字符放入哈希表2hash2;
然后遍历两个哈希表,以哈希表2hash2为标准,判断hash2中字符频次是否小于等于hash1:
——如果小于说明当前[left, right]子串是满足要求的
————在子串满足要求的基础上再次判断当前子串的长度是否比记录的最小长度minlen小,如果小就更新minlen = right - left + 1,begin = l,如果大就不更新;
————在这种情况下,以当前left为起始,right之后的位置为结束的子串也一定是符合题意的,串的长度一定都是大于当前串right-left+1的,所以没有了判断的必要,left可以直接右移,right也回到left位置开始下一次遍历;
——如果大于则当前子串不满足要求,right继续向右移动;
( 4 ) (4) (4)
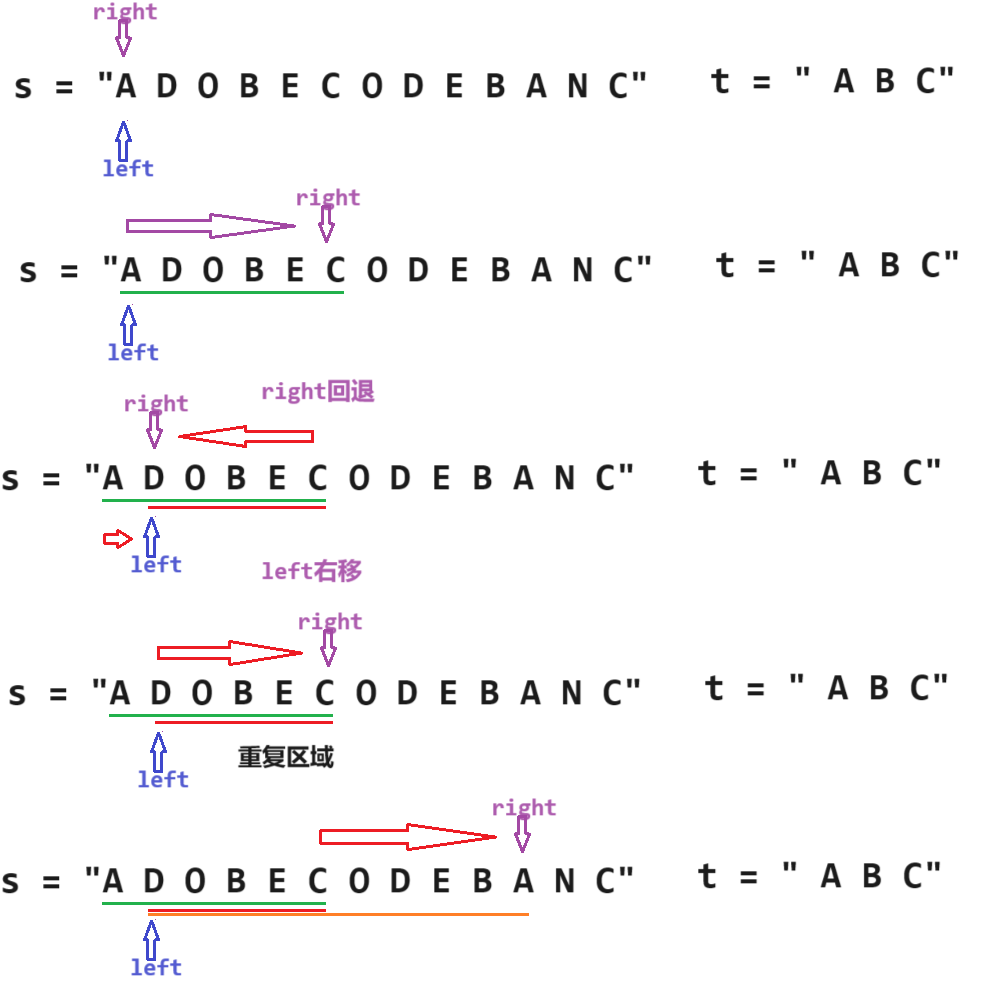
2. 算法原理
( 1 ) (1) (1) 单调性 - 引出滑动窗口
在以left为起点,right为末尾的s子串中,假设在某一个位置right元素加入到哈希表2hash2中后子串恰好满足了t字符频次都小于子串对应字符频次的要求。
之后left会向右移动1位,我们来讨论一下right是否需要回退到新left位置:
已知在[left, right]的s子串恰好满足要求,之后left右移1位,假设left先不右移,那么[left + 1, right]只有2种情况:
left位置元素恰好是t中字符,且hash2[s[left]] == hash1[s[left]],那么left右移将会导致hash2中left位置字符频次小于t对应字符。所以right回退到left之后还是会遍历到元来的位置且会继续向后遍历,此时right没有回退的必要;left位置元素不是t中字符,那么left +1, righ]的子串依然是恰好满足要求的,所以right回退left位置继续遍历还是会回到原来的位置并且right不需要继续向后移,因为会继续以[left+1,right]子串更新结果。
( 2 ) (2) (2) 滑动窗口 + 哈希表
( 3 ) (3) (3) 初始化:left = 0, right = 0, begin = -1, minlen = INT_MAX;
( 4 ) (4) (4) 进窗口:in = s[right], hash2[in]++;
( 5 ) (5) (5) 判断:遍历两个哈希表,判断相等时
( 6 ) (6) (6) 更新结果:在minlen > right - left + 1时,begin = l, minlen = right - left + 1;
( 7 ) (7) (7) 出窗口:out = s[left], hash2[left]- -, left- -;
( 8 ) (8) (8)right++;
( 2 ) (2) (2) 滑动窗口 + 哈希表 + 有效字符种类计数
有效字符种类计数的引入是为了优化判断时总是遍历哈希表的:
我们定义有效字符种类计数count:
只有在s子串对应字符频次等于t中对应字符频次时count才计数。而其他大于小于或者字符直接不在t中都不进行计数。
( 3 ) (3) (3) 初始化:left = 0, right = 0, begin = -1, minlen = INT_MAX, count =0;
( 4 ) (4) (4) 进窗口:in = s[right], hash2[in]++;
在hash2[in] == hash1[in]时,count++;//维护count
( 5 ) (5) (5) 判断:count == hash1.size时
( 6 ) (6) (6) 更新结果:在minlen > right - left + 1时,begin = l, minlen = right - left + 1;
( 7 ) (7) (7) 出窗口:
out = s[left];
在hash2[out] == hash1[out] 时,count–;//维护count
hash2[left]- -, left- -;
( 8 ) (8) (8)right++;
3. 时间复杂度
暴力枚举 + 哈希表 O ( n 2 ∗ m ) O(n^2*m) O(n2∗m)
枚举所有子串,需要两层循环,n^2,每次循环内需要判断两个哈希表是否相等,通过遍历长度为m的哈希表判断。
滑动窗口 + 哈希表 O ( n + m ) O(n+m) O(n+m)
left和right遍历一遍s字符串,是n;每次遍历都要判断两个哈希表是否相等,是m;
滑动窗口 + 哈希表 + 有效字符计数 O ( n ) O(n) O(n)
left和right遍历一遍s字符串,是n,判断时通过有效字符种类计数count变量直接判断;
3. 代码实现
class Solution {
public:string minWindow(string s, string t) {string ret;int hash1[128] = { 0 };int kinds = 0;for(auto& e : t) if(hash1[e]++ == 0) kinds++;int hash2[128] = { 0 };int n = s.size();int l = 0, r = 0;int count = 0;// 有效字符的种类int begin = -1, minlen = INT_MAX;while(r < n){char in = s[r];hash2[in]++;// 进窗口if(hash2[in] == hash1[in]) count++;//维护countwhile(count == kinds){// 判断if(minlen > r - l + 1) {// 更新结果minlen = r - l + 1;begin = l;}char out = s[l++];if(hash2[out]-- == hash1[out]) count--;// 维护count}r++;}cout << begin << " " << minlen << " ";return begin != -1 ? s.substr(begin, minlen) : "";}
};
4. 知识与收获
( 1 ) (1) (1)
( 2 ) (2) (2)
( 3 ) (3) (3)
T h e The The E n d End End