目录
一、实验
1.环境
2.Linux 部署 MapReduce
3.Linux 部署 Yarn
4.Linux 调用大数据集群分析数据
二、问题
1.hadoop 的启动和停止命令
2.HDFS 使用命令
一、实验
1.环境
(1)主机
表1 主机
| 主机 | 架构 | 软件 | 版本 | IP | 备注 |
| hadoop | NameNode (已部署) SecondaryNameNode (已部署) ResourceManager | hadoop | 2.7.7 | 192.168.204.50 | |
| node01 | DataNode(已部署) NodeManager | hadoop | 2.7.7 | 192.168.204.51 | |
| node02 | DataNode(已部署) NodeManager | hadoop | 2.7.7 | 192.168.204.52 | |
| node03 | DataNode(已部署) NodeManager | hadoop | 2.7.7 | 192.168.204.53 |
(2) 查看jps进程
NameNode节点查看
[root@hadoop hadoop]# jps

DataNode节点查看(node01)

DataNode节点查看(node02)

DataNode节点查看(node03)

(3) web页面访问
http://192.168.204.50:50070/
http://192.168.204.50:50090/
http://192.168.204.51:50075/
访问系统

2.Linux 部署 MapReduce
(1)备份
[root@hadoop hadoop]# cp mapred-site.xml.template mapred-site.xml

(2)查看mapreduce配置文件
https://hadoop.apache.org/docs/r2.7.7/
https://hadoop.apache.org/docs/r2.7.7/hadoop-mapreduce-client/hadoop-mapreduce-client-core/mapred-default.xml![]()
(3)修改配置文件
[root@hadoop hadoop]# vim mapred-site.xml

修改前:
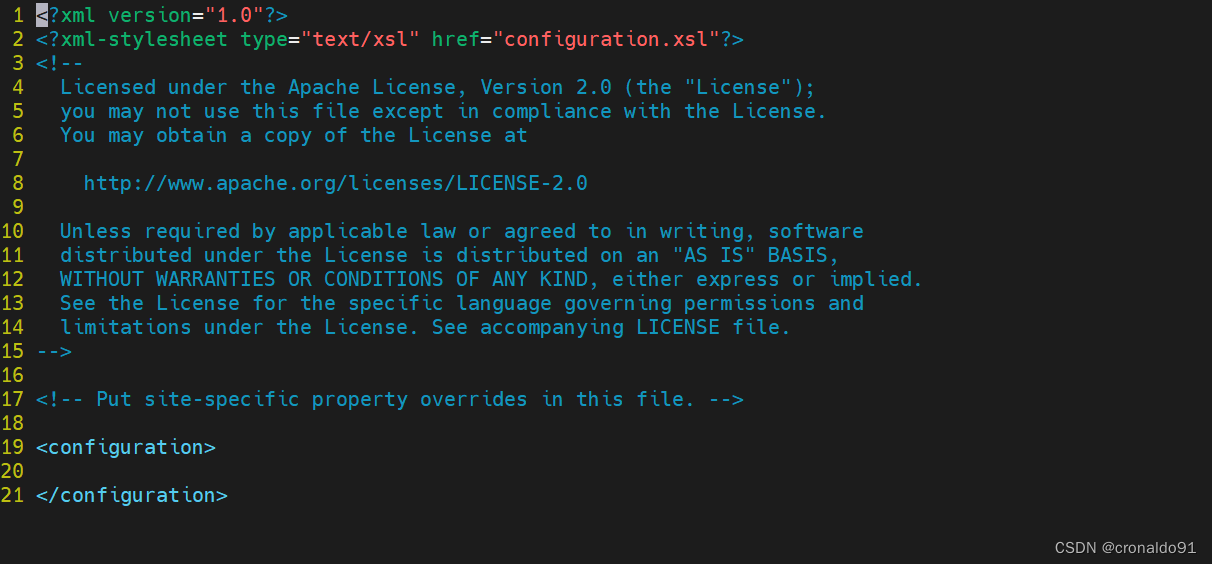
修改后:
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property>
</configuration>
[root@hadoop hadoop]# vim yarn-site.xml
3.Linux 部署 Yarn
(1) 查看yarn配置文件
https://hadoop.apache.org/docs/r2.7.7/hadoop-yarn/hadoop-yarn-common/yarn-default.xml服务:

主机:
![]()
(2) 修改配置文件
[root@hadoop hadoop]# vim yarn-site.xml

修改前:
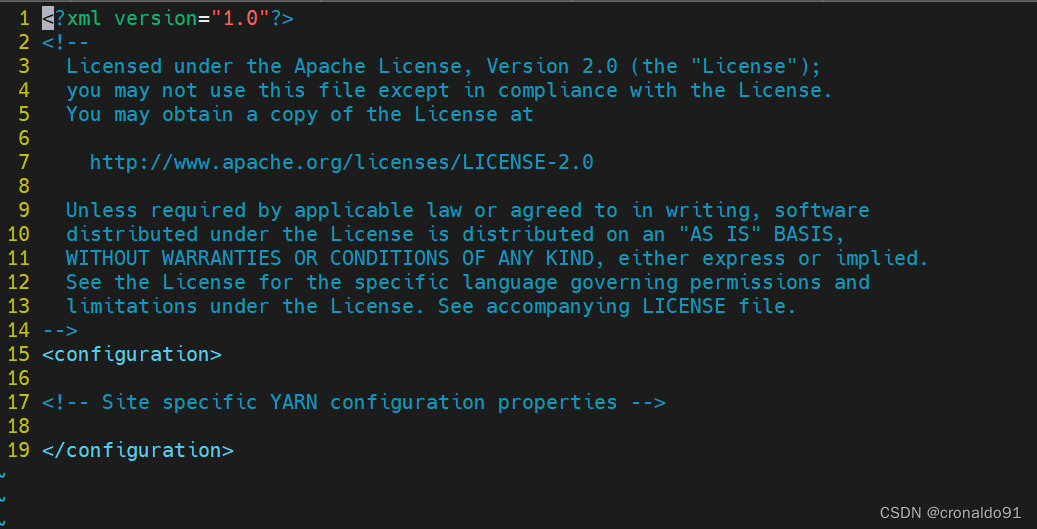
修改后:
<configuration><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property>
<!-- Site specific YARN configuration properties --><property><name>yarn.resourcemanager.hostname</name><value>hadoop</value></property>
</configuration>

(3) 同步配置
[root@hadoop ~]# rsync -aXSH --delete /usr/local/hadoop/etc node01:/usr/local/hadoop/
[root@hadoop ~]# rsync -aXSH --delete /usr/local/hadoop/etc node02:/usr/local/hadoop/
[root@hadoop ~]# rsync -aXSH --delete /usr/local/hadoop/etc node03:/usr/local/hadoop/

(4)启动yarn服务
[root@hadoop ~]# cd /usr/local/hadoop/
[root@hadoop hadoop]# ./sbin/start-yarn.sh

(5)查看jps
新增ResourceManager
[root@hadoop hadoop]# jps

node01节点

node02节点
node03节点
(6)查看节点
[root@hadoop hadoop]# ./bin/yarn node -list
24/03/14 13:40:21 INFO client.RMProxy: Connecting to ResourceManager at hadoop/192.168.204.50:8032
Total Nodes:3Node-Id Node-State Node-Http-Address Number-of-Running-Containersnode01:40551 RUNNING node01:8042 0node02:46073 RUNNING node02:8042 0node03:40601 RUNNING node03:8042 0

(7)web页面访问
ResourceManager
http://192.168.204.50:8088/
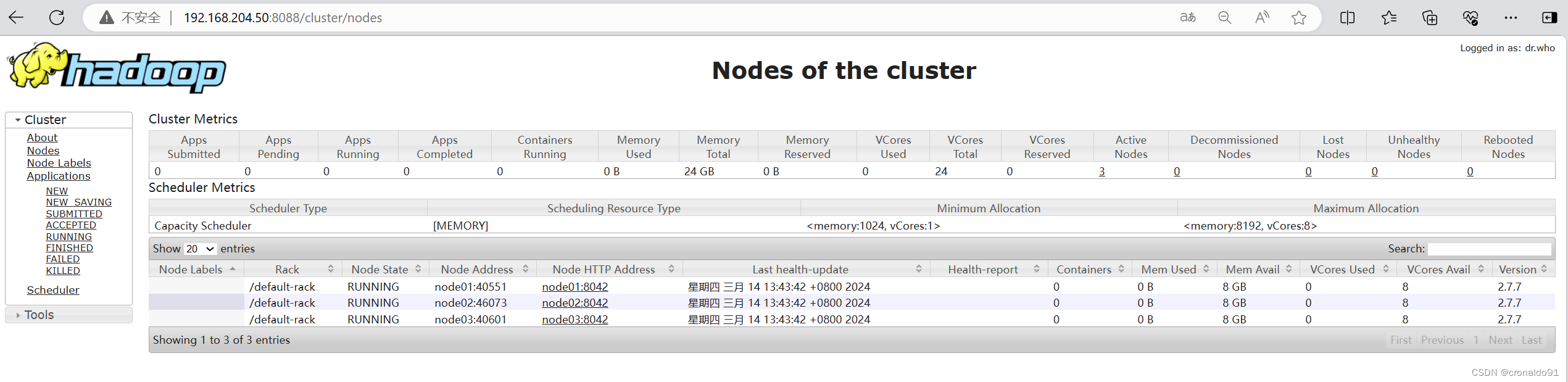
NodeManager
http://192.168.204.51:8042/
4.Linux 调用大数据集群分析数据
(1)查看
[root@hadoop hadoop]# ./bin/hadoop fs -ls /

[root@hadoop hadoop]# ./bin/hadoop fs -ls /devops/

(2)分析
[root@hadoop hadoop]# ./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount /devops /output
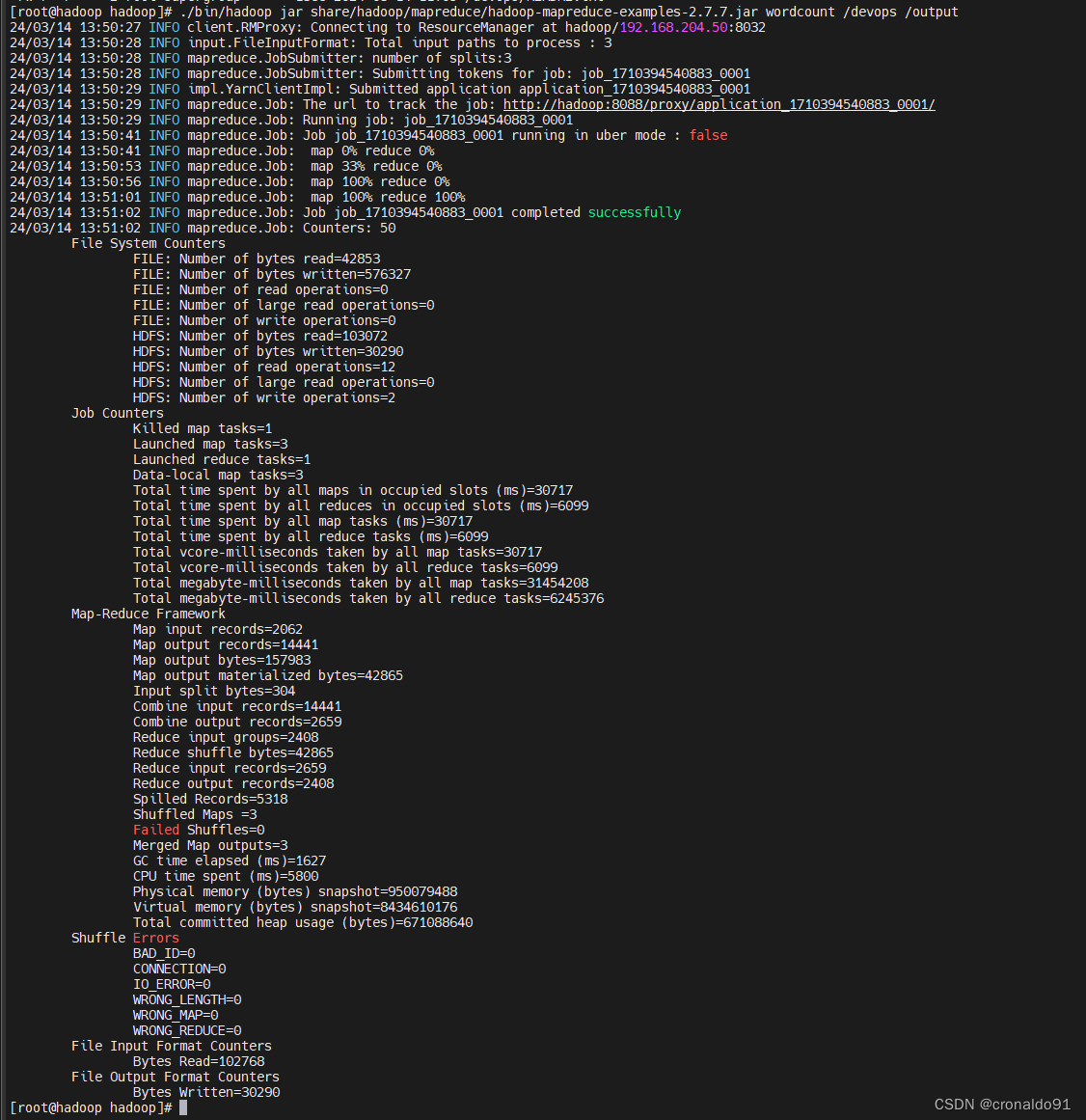
(3)查看
生成output
[root@hadoop hadoop]# ./bin/hadoop fs -ls /

[root@hadoop hadoop]# ./bin/hadoop fs -ls /output/

查看内容
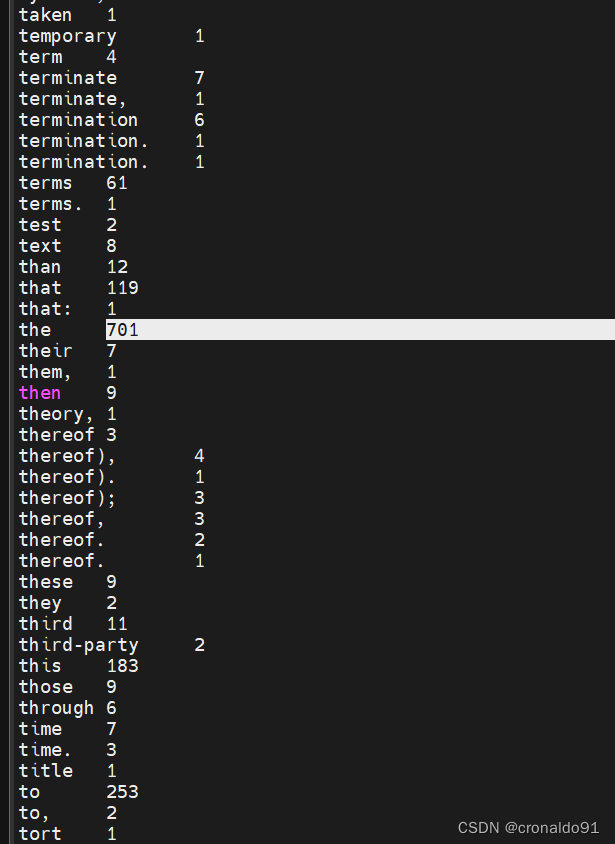
[root@hadoop hadoop]# ./bin/hadoop fs -cat /output/*
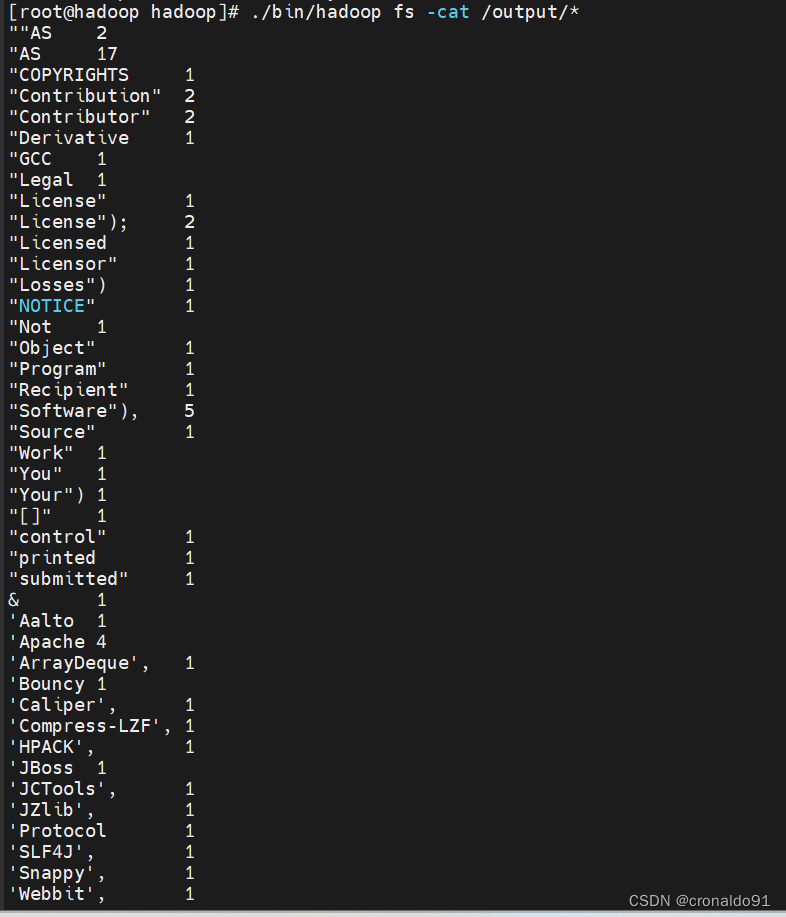
the的次数最多
二、问题
1.hadoop 的启动和停止命令
(1)命令
sbin/start-all.sh 启动所有的Hadoop守护进程。包括NameNode、 Secondary NameNode、DataNode、ResourceManager、NodeManager
sbin/stop-all.sh 停止所有的Hadoop守护进程。包括NameNode、 Secondary NameNode、DataNode、ResourceManager、NodeManager
sbin/start-dfs.sh 启动Hadoop HDFS守护进程NameNode、SecondaryNameNode、DataNode
sbin/stop-dfs.sh 停止Hadoop HDFS守护进程NameNode、SecondaryNameNode和DataNode
sbin/hadoop-daemons.sh start namenode 单独启动NameNode守护进程
sbin/hadoop-daemons.sh stop namenode 单独停止NameNode守护进程
sbin/hadoop-daemons.sh start datanode 单独启动DataNode守护进程
sbin/hadoop-daemons.sh stop datanode 单独停止DataNode守护进程
sbin/hadoop-daemons.sh start secondarynamenode 单独启动SecondaryNameNode守护进程
sbin/hadoop-daemons.sh stop secondarynamenode 单独停止SecondaryNameNode守护进程
sbin/start-yarn.sh 启动ResourceManager、NodeManager
sbin/stop-yarn.sh 停止ResourceManager、NodeManager
sbin/yarn-daemon.sh start resourcemanager 单独启动ResourceManager
sbin/yarn-daemons.sh start nodemanager 单独启动NodeManager
sbin/yarn-daemon.sh stop resourcemanager 单独停止ResourceManager
sbin/yarn-daemons.sh stopnodemanager 单独停止NodeManager
sbin/mr-jobhistory-daemon.sh start historyserver 手动启动jobhistory
sbin/mr-jobhistory-daemon.sh stop historyserver 手动停止jobhistory2.HDFS 使用命令
(1)命令
ls 查看文件或目录cat 查看文件内容put 上传get 下载