开发反应式API
- 开发反应式API
- 1 使用SpringWebFlux
- 1.1 Spring WebFlux 简介
- 1.2 编写反应式控制器
- 2 定义函数式请求处理器
- 3 测试反应式控制器
- 3.1 测试 GET 请求
- 3.2 测试 POST 请求
- 3.3 使用实时服务器进行测试
- 4 反应式消费RESTAPI
- 4.1 获取资源
- 4.2 发送资源
- 4.3 删除资源
- 4.4 处理错误
- 4.5 交换请求
- 5 总结
开发反应式API
在已经了解了反应式编程和 Reactor项目的基础上,现在可以开始在 Spring 应用程序中使用这些技术了。在本文中,我们将利用 Spring 的反应式编程模型重新讨论在Restful 风格的控制器。
具体来讲,我们将一起探讨 Spring 中新添加的反应式 Web框架,即 Spring WebFlux。
很快你就会发现,Spring WebFlux与Spring MVC非常相似,这使得它非常易于使用。
我们已经掌握的在 Spring 中构建 RESTAPI的知识依然有用。
1 使用SpringWebFlux
传统的基于 Servlet 的 Web框架,如 Spring MVC,本质上都是阻塞式和多线程的,每个连接都会使用一个线程。在请求处理的时候,会在线程池中拉取一个工作者(worker)线程来对请求进行处理。同时,请求线程是阻塞的,直到工作者线程提示它已经完成。
这样的后果就是阻塞式 Web 框架面临大量请求时无法有效地扩展。缓慢的工作者线程带来的延迟会使情况变得更糟,因为它需要花费更长的时间才能将工作者线程送回池中,以处理另外的请求。在某些场景中,这种设计完全可以接受。事实上,十多年来,大多数 Web 应用程序的开发方式基本上都是这样的,但是时代在变化。
以前,这些 Web 应用程序的客户是偶尔浏览网站的人,而现在这些人会频繁消费内容并使用与 HTTP API协作的应用程序。如今,所谓的物联网中有汽车、喷气式发动机和其他非传统的客户端(甚至不需要人类),它们会持续地与 Web API交换数据。随着消费 Web 应用的客户端越来越多,可扩展性比以往任何时候都更加重要。
相比之下,异步 Web 框架能够以更少的线程获得更高的可扩展性,通常它们只需要与 CPU 核心数量相同的线程。通过使用所谓的事件轮询 (event looping) 机制(如图所示 ),这些框架能够用一个线程处理很多请求,使得每次连接的成本更低。
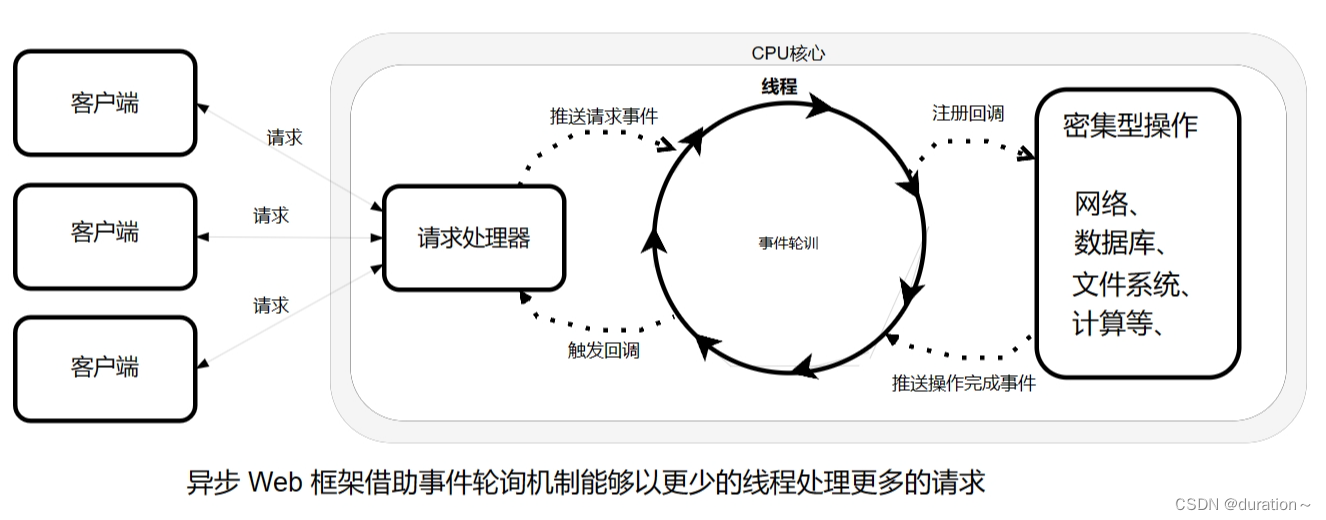
在事件轮询中,所有事情都是以事件的方式来处理的,包括请求以及密集型操作(如数据库和网络操作)的回调。当需要执行成本高昂的操作时,事件轮询会为该操作注册个回调,这样一来,操作可以被并行执行,而事件轮询则会继续处理其他的事件。
当操作完成时,事件轮询机制会将其作为一个事件,这与请求是类似的。这样的效果是,在面临大量请求负载时,异步 Web框架能够以更少的线程实现更好的可扩展性从而减少线程管理的开销。
Spring提供了一个主要基于 Reactor 项目的非阻塞、异步 Web 框架,以解决 Web 应用和 API中更多的可扩展性需求。接下来我们看一下 Spring WebFlux,一种面向 Spring的反应式 Web 框架。
1.1 Spring WebFlux 简介
当 Spring 团队在思考如何向 Web 层添加反应式编程模型时,很快就发现如果不在 Spring MVC 中做大量工作,就很难实现这一点。这涉及在代码中产生分支以决定是否要以反应式的方式来处理请求。本质上,这样做会将两个Web框架打包成一个,并用 if 语句来区分反应式和非反应式。
与其将反应式编程模型硬塞进Spring MVC 中,还不如创建一个单独的反应式 web框架,并尽可能多地借鉴 Spring MVC。Spring WebFlux 应运而生。spring 定义的完整开发技术站如图。
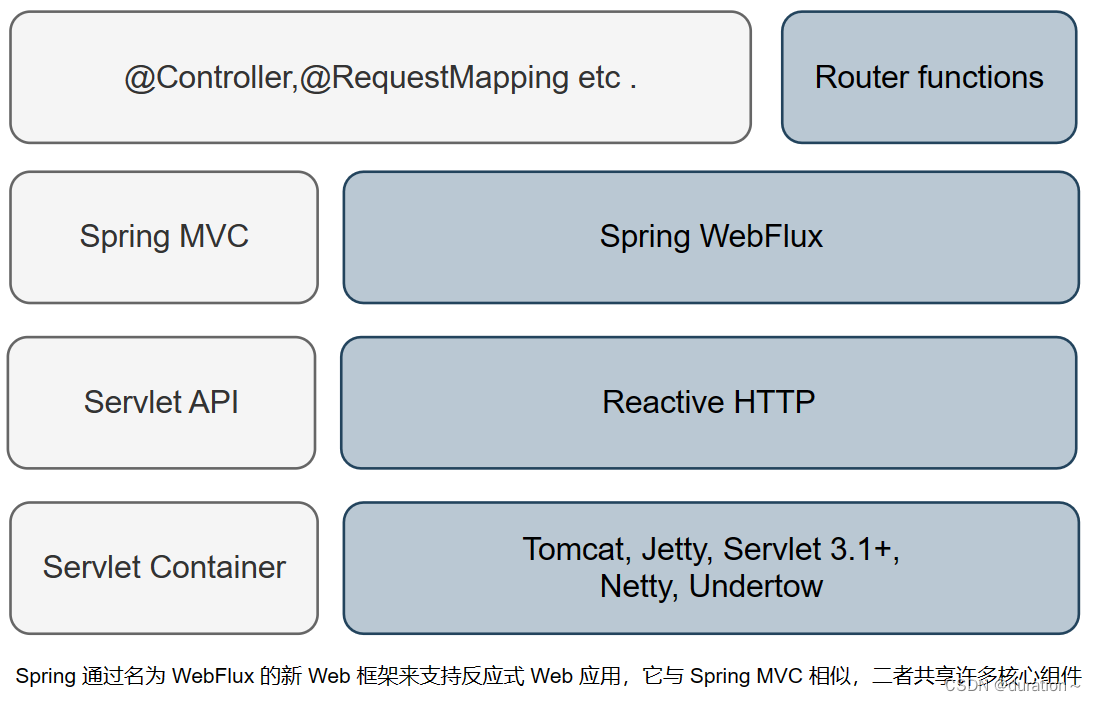
在图的左侧,我们会看到 Spring MVC 技术栈,这是 Spring 框架 2.5 版本就引人的。SpringMVC建立在 Java Servlet API 之上,因此需要 Servlet 容器(比如 Tomcat )才能执行。
与之不同,Spring WebFlux (在图右侧)并不会绑定 Servlet API,所以它构建在 Reactive HTTP API之上,这个 API 与 Servlet API具有相同的功能,只不过是采用了反应式的方式。因为 Spring WebFlux 没有与 Servlet API 耦合,所以它的运行并不需要 Servlet 容器。它可以运行在任意非阻塞 Web 容器中,包括 Netty、Undertow、Tomcat、Jetty 或任意 Servlet 3.1 及以上的容器。
在上图中,最值得注意的是左上角,它代表了 Spring MVC 和 Spring WebFlux 公用的组件,主要用来定义控制器的注解。因为 Spring MVC 和 Spring WebFlux 会使用相同的注解,所以 Spring WebFlux 与 Spring MVC 在很多方面并没有区别。
右上角的方框表示另一种编程模型,它使用函数式编程范式来定义控制器,而不是使用注解。在第2节中,我们会详细地讨论 Spring 的函数式 Web 编程模型。
Spring MVC 和 Spring WebFlux 最显著的区别在于需要添加到构建文件中的依赖项不同。在使用Spring WebFlux 时,我们需要添加 Spring Boot WebFlux starter 依赖项,而不是标准的 Web starter(例如,spring-boot-starter-web)。在项目的 pom.xml 文件中,如下所示:
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-webflux</artifactId>
</dependency>
使用 WebFlux 有一个很有意思的副作用,即 WebFlux 的默认嵌人式服务器是 Netty 而不是 Tomcat。Netty 是一个异步、事件驱动的服务器,非常适合 Spring WebFlux 这样的反应式 Web 框架。
除了使用不同的 starter 依赖,Spring WebFlux 的控制器方法通常要接受和返回反应式类型,如 Mono 和 Flux,而不是领域类型和集合。Spring WebFlux 控制器也能处理 RxJava 类型,如Observable、Single 和 Completable。
反应式 Spring MVC
尽管 Spring WebFlux 控制器通常会返回 Mono 和 Flux,但是这并不意味着使用 SpringMVC 就无法体验反应式类型的乐趣。如果你愿意,那么 SpringMVC 也可以返回 Mono 和 Flux 。
它们的区别在于反应式类型的使用方法。Spring WebFlux 是真正的反应式 Web 框架,允许在事件轮询中处理请求,而 Spring MVC 是基于 Servlet 的,依赖多线程来处理多个请求。
接下来,我们让 Spring WebFlux 运行起来,借助 Spring WebFlux 重新编写 Taco Cloud 的 API 控制器。
1.2 编写反应式控制器
平常我们会为一个项目( Taco Cloud )的 REST API 创建一些控制器,这些控制器中包含请求处理方法,这些方法会以领域类型(如 TacoOrder 和 Taco )或领域类型集合的方式处理输入和输出。作为提醒,我们平常要编写一个 TacoController 的片段是这样的:
@RestController
@RequestMapping(path = "/api/tacos", produces = "application/json")
@CrossOrigin(origins = "*")
public class TacoController {
...@GetMapping(params = "recent")public Iterable<Taco> recentTacos() {PageRequest page = PageRequest.of(0,12,Sort.by("createdAt").descending());return tacoRepo.findAll(page).getContent();}
...
}
按照上述编写形式,recentTacos() 控制器会处理对"/api/tacos?recent"的 HTTP GET 请求,返回最近创建的 taco 列表。具体来讲,它会返回 Taco 类型的 Iterable 对象。这主要是因为存储库的 findAIl() 方法返回的就是该类型,或者更准确地说,这个结果来自 findAll() 方法所返回的 Page 对象的 getContent() 方法。
这样的形式运行起来很顺畅,,但 Iterable 并不是反应式类型。我们不能对它使用任何反应式操作,也不能让框架将它视为反应式类型,从而将工作切分到多个线程中。我们希望 recentTacos() 方法能够返回 Flux<Taco>。
这里有一个简单但效果有限的方案:重写 recentTacos() ,将 Iterable 转换为 Flux。而且,在重写的时候,我们可以去掉分页代码,将其替换为调用 Flux 的 take() :
@GetMapping(params = "recent")
public Flux<Taco> recentTacos() {return Flux.fromIterable(tacoRepo.findA1l()).take(12);
}
借助 Flux.fromIterable(),我们可以将 Iterable<Taco> 转换为 Flux<Taco>。既然我们可以使用 Flux,那么就能使用 take 操作将 Flux 返回的值限制为最多 12 个 Taco 对象。这样不仅使代码更加简洁,也使我们能够处理反应式的 Flux,而不是简单的 Iterable。到目前为止,我们编写反应式代码一切都很顺利。但是,如果存储库一开始就给我们一个 Flux 那就更好了————这样就没有必要进行转换了。如果是这样,那么 recentTacos() 将会写成如下形式:
@GetMapping(params="recent")
public Flux<Taco>recentTacos() {return tacoRepo.findAll().take(12);
}
这样就更好了!在理想情况下,反应式控制器会位于反应式端到端栈的顶部,这个栈包括了控制器、存储库、数据库,以及任何可能介于两者之间的服务。这样的端到端反应式栈如图所示。
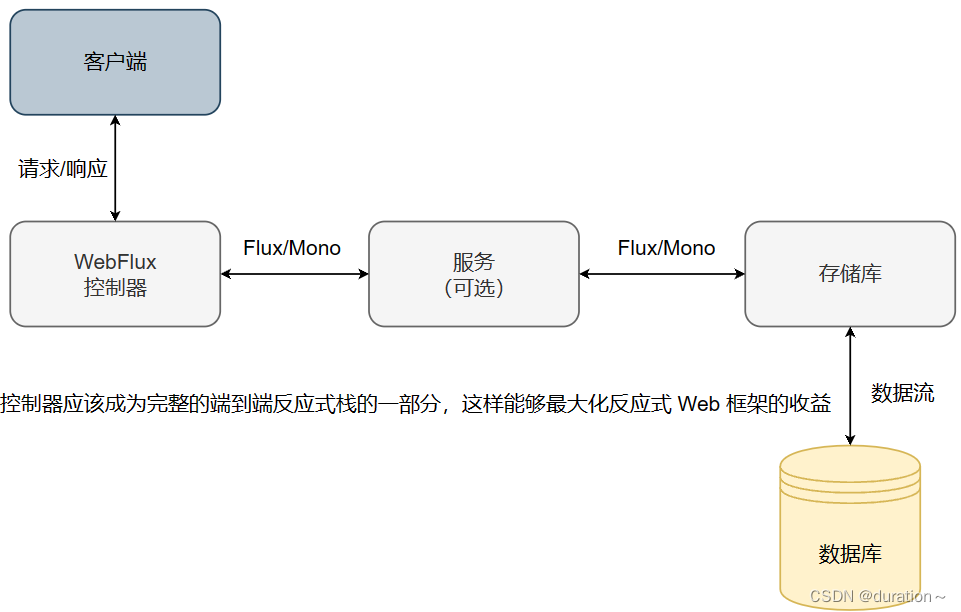
这样的端到端技术栈要求存储库返回 Flux,而不是 Iterable。反应式存储库并不是本次我们研究的重点,这里可以先看一下反应式 TacoRepository 大致是什么样子的:
import org.springframework.data.repository.reactive.ReactiveCrudRepository;
import tacos.Taco;
public interface TacoRepository extends ReactiveCrudRepository<Taco,Long>{
}
此时,最需要注意的事情在于, 除了使用 Flux 来替换 Iterable 以及获取 Flux 的方法外, 定义反应式 webFlux 控制器的编程模型与非反应式 Spring MVC 控制器并没有什么差异。它们都使用了@RestController 注解以及类级别的 @RequestMapping 注解。在方法级别,它们都有使用@GetMapping 注解的请求处理函数。真正重要的是处理器方法返回了什么类型。
另外值得注意的是,尽管我们从存储库得到了 Flux<Taco>,但是我们直接将它返回了并没有调用 subscribe()。框架将会为我们调用 subscribe() 。这意味着处理"/apitacos?recent"请求时,recentTacos() 方法会被调用,且在数据真正从数据库取出之前就能立即返回。
返回单个值
作为另外一个样例,我们思考一下 TacoController 的 tacoByld() 方法:
@GetMapping("/{id}")
public Taco tacoById(@PathVariable("id") Long id) {Optional<Taco> optTaco = tacoRepo.findById(id);if (optTaco.isPresent()) {return optTaco.get();}return null;
}
在这里,该方法处理对"/tacos/{id}" 的GET请求并返回单个 Taco 对象。因为存储库的 findById() 返回的是 Optional,所以我们必须编写一些笨拙的代码去处理它。但设想一下,findById() 返回的是 Mono<Taco>,而不是 Optional<Taco>,那么我们可以按照如下的方式重写控制器的 tacoById():
@GetMapping("/{id}")
public Mono<Taco> tacoById(@PathVariable("id") Long id) {return tacoRepo.findById(id);
}
这样看上去简单多了。更重要的是,通过返回 Mono<Taco> 来替代 Taco,我们能够让 Spring WebFlux 以反应式的方式处理响应。这样做的结果就是我们的 API在面临高负载的时候可以更灵活。
使用 RxJava 类型
值得一提的是,在使用 Spring WebFlux 时,虽然使用 Flux 和 Mono 是自然而然的选择,但是我们也可以使用像 Observable 和 Single 这样的 RxJava 类型。例如,假设在 TacoController 和后端存储库之间有一个服务处理RxJava类型,那么 recentTacos() 方法可以编写为:
@GetMapping(params = "recent")
public Observable<Taco> recentTacos() {return tacoService.getRecentTacos();
}
类似地,tacoById() 方法可以编写成处理 RxJava Single 类型,而不是 Mono 类型::
@GetMapping("/{id}")
public Single<Taco> tacoById(@PathVariable("id") Long id) {return tacoService.lookupTaco(id);
}
除此之外,Spring WebFlux 控制器方法还可以返回 RxJava 的 Completable,后者等价于 Reactor 中的Mono<Void>。WebFlux也可以返回 RxJava 的 Flowable ,以替换 Observable 或 Reactor 的 Flux。
实现输入的反应式
到目前为止,我们只关心了控制器方法返回什么样的反应式类型。但是,借助 Spring WebFlux,我们还可以接受 Mono 或 Flux 以作为处理器方法的输入。为了阐述这一点,我们看一下 TacoController 中原始的 postTaco() 实现:
@PostMapping(consumes ="application/json")
@ResponseStatus(HttpStatus.CREATED)
public Taco postTaco(@RequestBody Taco taco) {return tacoRepo.save(taco);
}
按照原始的编写方式,postTaco() 不仅会返回一个简单的Taco对象,还会接受一个绑定了请求体中内容的 Taco 对象。这意味着在请求载荷完成解析并初始化为 Taco 对象之前 postTaco() 方法不会被调用,也意味着在对存储库的 save() 方法的阻塞调用返回之前 postTaco() 不能返回。简言之,这个请求阻塞了两次,分别在进入 postTaco() 时和在 postTaco() 调用的过程中发生。通过为 postTaco() 添加一些反应式代码,我们能够将它变成完全非阻塞的请求处理方法:
@PostMapping(consumes = "application/json")
@ResponseStatus(HttpStatus.CREATED)
public Mono<Taco> postTaco(@RequestBody Mono<Taco> tacoMono) {return tacoRepo.saveAll(tacoMono).next();
}
在这里,postTaco() 接受一个 Mono<Taco> 并调用了存储库的 saveAIl() 方法,该方法能够接受任意的 Reactive Streams Publisher 实现,包括 Mono 或 Flux。saveAIl() 方法返回 Flux<Taco>,但由于我们提供的是 Mono,我们知道该 Flux 最多只能发布一个Taco,所以调用 next() 方法之后,posTaco() 方法返回的就是我们需要的 Mono<Taco>。
通过接受 Mono<Taco> 作为输人,该方法会立即调用,而不再等待 Taco 从请求体中解析生成。另外,存储库也是反应式的,它接受一个 Mono 并立即返回 Flux<Taco> ,所以我们调用 Flux 的 next() 来获取最终的 Mono<Taco>。方法在请求真正处理之前就能返回。
我们也可以像这样实现 postTaco():
@PostMapping(consumes = "application/json")
@ResponseStatus(HttpStatus.CREATED)
public Mono<Taco> postTaco(@RequestBody Mono<Taco> tacoMono) {return tacoMono.flatMap(tacoRepo::save);
}
这种方法颠倒了事情的顺序,使 tacoMono 成为行动的驱动者。tacoMono 中的 Taco 通过 flatMap()方法交给了存储库中的 save() 方法,并返回一个新的 Mono<Taco> 作为结果。
上述两种方法都是可行的。可能还有其他方式来实现 postTaco()。请自行选择对你来说运行效果最好、最合理的方式。
Spring WebFlux 是一个非常棒的 Spring MVC 替代方案,提供了与 Spring MVC相同的开发模型,用于编写反应式 Web 应用。其实 Spring 还有另外一项技巧,下面让我们看看如何使用 Spring 的函数式编程风格创建反应式 API。
2 定义函数式请求处理器
Spring MVC基于注解的编程模型从 Spring 2.5 就存在了,而且这种模型非常流行但是它也有一些缺点。
首先,所有基于注解的编程方式都会存在注解该做什么以及注解如何做之间的制裂。注解本身定义了该做什么,而具体如何去做则是在框架代码的其他部分定义的。如果想要进行自定义或扩展,编程模型就会变得很复杂,因为这样的变更需要修改注解之外的代码。除此之外,调试这种代码也是比较麻烦的,因为我们无法在注解上设置断点。
其次,随着 Spring 变得越来越流行,很多熟悉其他语言和框架的 Spring 新手会觉得基于注解的 Spring MVC(和 WebFlux)与他们之前掌握的工具有很大的差异。作为注解式 WebFlux 的一种替代方案,Spring 引人了定义反应式 API的新方法:函数式编程模型。
这个新的编程模型使用起来更像是一个库,而不是一个框架,能够让我们在不使用注解的情况下将请求映射到处理器代码中。使用Spring的函数式编程模型编写API会及4个主要的类型:
RequestPredicate,声明要处理的请求类型:RouterFunction,声明如何将请求路由到处理器代码中;ServerRequest,代表一个HTTP请求,包括对请求头和请求体的访问:ServerResponse,代表一个HTTP 响应,包括响应头和响应体信息。
下面是一个将所有类型组合在一起的 Hello World 样例:
package hello;/*** @author shenyang* @version 1.0* @Date 2024/3/6 11:18*/import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.reactive.function.server.RouterFunction;import static org.springframework.web.reactive.function.server.RequestPredicates.GET;
import static org.springframework.web.reactive.function.server.RouterFunctions.route;
import static org.springframework.web.reactive.function.server.ServerResponse.ok;
import static reactor.core.publisher.Mono.just;@Configuration
public class RouterFunctionConfig {@Beanpublic RouterFunction<?> helloRouterFunction() {return route(GET("/hello"),request -> ok().body(just("Hello World!"), String.class));}}
需要注意的第一件事情是,这里静态导人了一些辅助类,可以使用它们来创建前文所述的函数式类型。我们还以静态方式导人了Mono,从而能够让剩余的代码更易于阅读和理解。
在这个 @Configuration 类中,我们有一个类型为 RouterFunction<?> 的 @Bean 方法。按照前文所述,RouterFunction 能够声明一个或多个 RequestPredicate 对象,并处理与之匹配的请求的函数之间的映射关系。
RouterFunctions 的 route() 方法接受两个参数: RequestPredicate 和处理与之匹配的请求的函数。在本例中,RequestPredicates 的GET() 方法声明一个 RequestPredicate,后者会匹配针对 “hello” 的 HTTP GET 请求。
至于处理器函数,则写成了lambda表达式的形式,当然它也可以使用方法引用。尽管这里没有显式声明,但是处理器lambda表达式会接受一个 ServerRequest 作为参数。它通过 ServerResponse 的 ok() 方法和 BodyBuilder 的 body() 方法返回了一个ServerResponse。BodyBuilder 对象是由 ok() 所返回的。这样一来,就会创建出状态码为 HTTP 200(OK)并且响应体载荷为 “Hello World!” 的响应。
按照这种编写形式,helloRouterFuncion() 方法所声明的 RouterFunction 只能处理一种类型的请求。如果想要处理不同类型的请求,那么我们没有必要编写另外一个 @Bean(当然也可以这样做),仅需调用 andRoute() 声明另一个RequestPredicate 到函数的映射。例如,为 “bye” 的 GET 请求添加一个处理器:
@Bean
public RouterFunction<?> helloRouterFunction() {return route(GET("/hello"),request -> ok().body(just("Hello World!"), String.class)).andRoute(GET("/bye"),request -> ok().body(just("See ya!"), String.class));
}
Helo World 这种级别的样例只能用来简单体验一些新东西。接下来,我们看一下如何使用 Spring 的函数式 Web 编程模型处理接近真实场景的请求。
为了阐述如何在真实应用中使用函数式编程模型,我们会使用函数式风格重塑 TacoController 的功能。如下的配置类是 TacoController 的函数式实现:
package tacos.web.api;/*** @author shenyang* @version 1.0* @Date 2024/3/6 11:18*/import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.reactive.function.server.RouterFunction;
import org.springframework.web.reactive.function.server.ServerRequest;
import org.springframework.web.reactive.function.server.ServerResponse;
import reactor.core.publisher.Mono;
import tacos.Taco;
import tacos.data.TacoRepository;import java.net.URI;import static org.springframework.web.reactive.function.server.RequestPredicates.*;
import static org.springframework.web.reactive.function.server.RouterFunctions.route;@Configuration
public class RouterFunctionConfig {@Autowiredprivate TacoRepository tacoRepo;@Beanpublic RouterFunction<?> routerFunction() {return route(GET("/api/tacos").and(queryParam("recent", t -> t != null)), this::recents).andRoute(POST("/api/tacos"), this::postTaco);}public Mono<ServerResponse> recents(ServerRequest request) {return ServerResponse.ok().body(tacoRepo.findAll().take(12), Taco.class);}public Mono<ServerResponse> postTaco(ServerRequest request) {return request.bodyToMono(Taco.class).flatMap(taco -> tacoRepo.save(taco)).flatMap(savedTaco -> {return ServerResponse.created(URI.create("http://localhost:8080/api/tacos/" +savedTaco.getId())).body(savedTaco, Taco.class);});}
}
我们可以看到,routerFunction() 方法声明了一个 RouterFunction<?>bean ,这与 HelloWorld 样例类似。但是,它们之间的差异在于要处理什么类型的请求、如何处理。在本例中,我们创建的 RouterFunction 处理针对 “/api/tacos?recent” 的 GET 请求和针对 “/api/tacos” 的 POST 请求。
更明显的差异在于,路由是由方法引用处理的。如果 RouterFunction 背后的行为相对简捷,那么 lambda 表达式是很不错的选择。在很多场景下,最好将功能提取到一个单独的方法中( 甚至提取到一个独立类的方法中 ),以保持代码的可读性。
就我们的需求而言,针对 “/apitacos?recent” 的GET请求将由 recents() 方法来处理。它使用注入的 TacoRepository 得到一个 Flux<Taco>,然后从中得到 12 个数据项。随后,它将Flux<Taco>包装到一个 Mono<ServerResponse> 中,这样我们就可以通过调用 ServerResponse 中的 ok() 来返回一个 HTTP 200(OK) 状态的响应。有很重要的一点需要我们注意:即使有多达12个 Taco 需要返回,我们也只会有一个服务器响应,这就是为什么它会以 Mono 而不是 Flux的形式返回。在内部,Spring仍然会将 Flux<Taco> 作为 Flux 流向客户端。
针对 “/api/tacos” 的 POST请求由 postTaco() 方法处理,它从传入的 ServerRequest 的请求体中提取 Mono<Taco>。随后 postTaco()方法使用一系列 flatMap() 操作将该 taco 保存到 TacoRepository 中,并创建一个状态码为 HTTP 201(CREATED) 的 ServerResponse,在响应体中包含了已保存的 Taco 对象。
flatMap() 操作能够确保在流程中的每一步中映射的结果都包装在一个 Mono 中,从第一个 flatMap()之后的 Mono<Taco>开始,以 postTaco()返回的 Mono<ServerResponse> 结束。
3 测试反应式控制器
在反应式控制器的测试方面,Spring并没有忽略我们的需求。实际上,Spring引人了 WebTestClient。这是一个新的测试工具类,让 Spring WebFlux 编写的反应式控制器的测试代码变得非常容易。为了了解如何使用 WebTestClient 编写测试,我们首先使用它测试 1.2 中编写的 TacoController 中的 recentTacos() 方法。
测试依赖
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId>
</dependency>
3.1 测试 GET 请求
对于 recentTacos() 方法,我们想断言,如果针对 “/api/tacos?recent” 路径发送 HTTP GET请求,那么会得到 JSON 载荷的响应并且 taco 的数量不会超过12个。下面的测试类是一个很好的起点。
import static org.mockito.ArgumentMatchers.any;
import static org.mockito.Mockito.when;
import java.util.ArrayList;
import java.util.List;
import org.junit.jupiter.api.Test;
import org.mockito.Mockito;
import org.springframework.http.MediaType;
import org.springframework.test.web.reactive.server.WebTestClient;
import reactor.core.publisher.Flux;
import reactor.core.publisher.Mono;
import tacos.Ingredient;
import tacos.Ingredient.Type;
import tacos.Taco;
import tacos.data.TacoRepository;
/*** @author shenyang* @version 1.0* @Date 2024/3/6 17:41*/
public class TacoControllerTest {@Testpublic void shouldReturnRecentTacos() {Taco[] tacos = {//创建测试数据testTaco(1L), testTaco(2L),testTaco(3L), testTaco(4L),testTaco(5L), testTaco(6L),testTaco(7L), testTaco(8L),testTaco(9L), testTaco(10L),testTaco(11L), testTaco(12L),testTaco(13L), testTaco(14L),testTaco(15L), testTaco(16L)};Flux<Taco> tacoFlux = Flux.just(tacos);TacoRepository tacoRepo = Mockito.mock(TacoRepository.class);when(tacoRepo.findAll()).thenReturn(tacoFlux);//模拟 TacoRepositoryWebTestClient testClient = WebTestClient.bindToController(new TacoController(tacoRepo)).build();//创建 WebTestClienttestClient.get().uri("/api/tacos?recent").exchange() //请求最近的 tacos.expectStatus().isOk().expectBody().jsonPath("$").isArray().jsonPath("$").isNotEmpty().jsonPath("$[0].id").isEqualTo(tacos[0].getId().toString()).jsonPath("$[0].name").isEqualTo("Taco 1").jsonPath("$[1].id").isEqualTo(tacos[1].getId().toString()).jsonPath("$[1].name").isEqualTo("Taco 2").jsonPath("$[11].id").isEqualTo(tacos[11].getId().toString()).jsonPath("$[11].name").isEqualTo("Taco 12").jsonPath("$[12]").doesNotExist();}...}
shouldReturnRecentTacos() 方法做的第一件事情就是以 Flux<Taco> 的形式创建了一些测试数据。这个 Flux 随后作为 mock TacoRepository 的 findAll()方法的返回值。
Flux 发布的 Taco 对象是由一个名为 testTaco() 的方法创建的。这个方法会根据一个数字生成一个 Taco,其ID和名称都是基于该数字生成的。testTaco() 方法的实现如下所示:
private Taco testTaco(Long number) {Taco taco = new Taco();taco.setId(number != null ? number.toString() : "TESTID");taco.setName("Taco " + number);List<Ingredient> ingredients = new ArrayList<>();ingredients.add(new Ingredient("INGA", "Ingredient A", Type.WRAP));ingredients.add(new Ingredient("INGB", "Ingredient B", Type.PROTEIN));taco.setIngredients(ingredients);return taco;
}
为简单起见,所有的测试 taco 都有两种相同的配料,但是它们的 ID 和名称是根据传人的数字确定的。
回到 shouldReturnRecentTacos() 方法,我们实例化了一个 TacoController 并将 mock 的TacoRepository 注人构造器。这个控制器传递给了 WebTestClient.bindToController() 方法,以便生成 WebTestClient 实例。
所有的环境搭建工作完成后,就可以使用 WebTestClient 提交GET请求至 “/api/tacos?recent”,并校验响应是否符合我们的预期。对 get().uri("api/tacos?recent") 的调用描述了我们想要发送的请求。随后,对 exchange() 的调用会真正提交请求,这个请求将会由 WebTestClient 绑定的控制器( TacoController )来进行处理。
最后、我们可以验证响应是否符合预期。通过调用 expectStatus(),我们可以断言响应具有 HTTP 200(OK) 状态码。然后,我们多次调用 jsonPath() 断言响应体中的 JS0N 包含它应该具有的值。最后一个断言检查第12个元素(在从0开始计数的数组中)是真的不存在,以此判断结果不超过12个元素。
如果返回的 JSON 比较复杂,比如有大量的数据或多层嵌套的数据,那么使用 jsonPath() 会变得非常烦琐。实际上,为了节省空间,在上面的程序中,我省略了很多对 jsonPath() 的调用。在这种情况下,使用 jsonPath() 会变得非常枯燥烦琐,WebTestClient 提供了 json() 方法。这个方法可以传入一个 String 参数(包含响应要对比的JSON)。
举例来说,假设我们在名为 recent-tacos.json 的文件中创建了完整的响应 JSON 并将它放到了类路径的 “/tacos” 路径下,那么可以按照如下的方式重写 WebTestClient 断言:
ClassPathResource recentsResource =new ClassPathResource("/tacos/recent-tacos.json");
String recentsJson = StreamUtils.copyToString(recentsResource.getInputStream(), Charset.defaultCharset());
testClient.get().uri("/api/tacos?recent").accept(MediaType.APPLICATION_JSON).exchange().expectStatus().isOk().expectBody().json(recentsJson);
因为 json() 接受的是一个 String,所以我们必须先将类路径资源加载为 String。借助 Spring 中 StreamUtils 的 copyToString()方法,这一点很容易实现。copyToString() 方法返回的 String 就是我们的请求所预期响应的 JSON 内容。我们将其传递给 json()方法,就能验证控制器的输出。
WebTestClient 提供的另一种可选方案就是它允许将响应体与值的列表进行对比。expectBodyList() 方法会接受一个代表列表中元素类型的 Class 或 ParameterizedTypeReference,并且会返回 ListBodySpec 对象,来基于该对象进行断言。借助 expectBodyList(),我们可以重写测试类,使用创建 mock TacoRepository 时的测试数据的子集来进行验证:
testClient.get().uri("/api/tacos?recent").accept(MediaType.APPLICATION_JSON).exchange().expectStatus().isOk().expectBodyList(Taco.class).contains(Arrays.copyOf(tacos,12));
在这里,我们断言响应体包含测试方法开头创建的原始 Taco 数组的前 12 个元素。
3.2 测试 POST 请求
WebTestClient 不仅能对控制器发送GET 请求,还能用来测试各种 HTTP 方法,包括 GET、POST、PUT、PATCH、DELETE 和HEAD方法。下表表明了 HTTP 方法与 WebTestClient 方法的映射关系。
WebTestClient 能够测试针对 Spring WebFlux 控制器的各种请求。
| HTTP 方法 | WebTestClient 方法 |
|---|---|
| GET | .get() |
| POST | .post() |
| PUT | .put() |
| PATCH | .patch() |
| DELETE | .delete() |
| HEAD | .head() |
作为测试 Spring WebFlux 控制器其他 HTTP 请求方法的样例,我们看一下针对TacoController 的另一个测试。这一次,我们会编写一个对 taco 创建 API的测试,提交POST请求到 “/api/tacos”:
@SuppressWarnings("unchecked")
@Test
public void shouldSaveATaco() {TacoRepository tacoRepo = Mockito.mock(TacoRepository.class);//模拟 TacoRepositoryWebTestClient testClient = WebTestClient.bindToController( //创建 WebTestClientnew TacoController(tacoRepo)).build();Mono<Taco> unsavedTacoMono = Mono.just(testTaco(1L));Taco savedTaco = testTaco(1L);Flux<Taco> savedTacoMono = Flux.just(savedTaco);when(tacoRepo.saveAll(any(Mono.class))).thenReturn(savedTacoMono);//创建测试数据testClient.post()//POST taco 请求.uri("/api/tacos").contentType (MediaType.APPLICATION_JSON).body(unsavedTacoMono,Taco.class).exchange().expectStatus().isCreated()//校验响应是否符合预期.expectBody(Taco.class).isEqualTo(savedTaco);
}
与上面的测试方法类似,shouldSaveATaco() 首先创建一些测试数据和mock TacoRepository,创建 WebTestClient,并将其绑定到控制器。随后,它使用 WebTestClient 提交 POST 请求到 “/design” ,并且将请求体声明为appication/json 类型,请求载荷为 Taco 的JSON序列化形式,放到未保存的 Mono 中。
在执行 exchange() 之后,该测试断言响应状态为 HTTP 201 (CREATED)并且响应体中的载荷与已保存的 Taco 对象相同。
3.3 使用实时服务器进行测试
到目前为止,我们所编写的测试都依赖于 Spring WebFlux的mock实现,所以并不需要真正的服务器。但是,我们可能需要在服务器(如Netty或 Tomcat)环境中测试 WebFlux 控制器,也许还会需要存储库或其他的依赖。换句话说,我们有可能要编写集成测试。
编写 WebTestClient 的集成测试与编写其他 Spring Boot 集成测试类似,首先需要我们为测试类添加@RunWith和@SpringBootTest 注解:
import java.io.IOException;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.ExtendWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.boot.test.context.SpringBootTest.WebEnvironment;
import org.springframework.http.MediaType;
import org.springframework.test.context.junit.jupiter.SpringExtension;
import org.springframework.test.web.reactive.server.WebTestClient;
@ExtendWith(SpringExtension.class)
@SpringBootTest(webEnvironment = WebEnvironment .RANDOM_PORT)
public class TacoControllerWebTest{@Autowiredprivate WebTestClient testClient;
}
通过将 webEnvironment 属性设置为 WebEnvironment.RANDOM_PORT,我们要求 Spring 启动一个运行时服务器并监听任意选择的端口。
你可能也注意到,我们将 WebTestClient 自动装配到了测试类中。这意味着我们不仅不用在测试方法中创建它,而且在发送请求的时候也不需要指定完整的URL。这是因为 WebTestClient 能够知道测试服务器在哪个端口上运行。现在,我们可以使用自动装配的 WebTestClient 将 shouldReturnRecentTacos()重写为集成测试 :
@Test
public void shouldReturnRecentTacos() throws IOException {testClient.get().uri("/api/tacos?recent").accept(MediaType.APPLICATION_JSON).exchange().expectStatus().isOk().expectBody().jsonPath("$").isArray().jsonPath("$.length()").isEqualTo(3).jsonPath("$[?(@.name =='Carnivore')]").exists().jsonPath("$[?(@.name == 'Bovine Bounty')]").exists().jsonPath("$[?(@.name =='Veg-Out')]").exists();
}
我们发现,这个版本的 shouldRetunRecentTacos() 代码要少得多。我们不再需要创建 WebTestClient,因为可以使用自动装配的实例。另外,也不需要 mockTacoRepository因为 Spring 会创建 TacoController 实例并注人真正的 TacoRepository 实例。在这个版本的测试方法中,我们使用 JSONPath 表达式来校验数据库提供的值。
WebTestClient 在测试的时候非常有用,我们可以使用它消费 WebFlux 控制器所暴露的 API。但是,如果应用本身要消费某个 API,又该怎样处理呢?接下来,我们将注意力转向 Spring 反应式 Web 的客户端,看一下 WebClient 如何通过 REST 客户端来处理反应式类型,如 Mono 和Flux。
4 反应式消费RESTAPI
之前我们学习使用 RestTemplate 将客户端请求发送到其他服务的 API 上。RestTemplate 有着很久的历史,从Spring 3.0版本开始引入。我们曾经使用它为应用发送了无数的请求,但是 RestTemplate 提供的方法处理的都是非反应式的领域类型和集合。这意味着,我们如果想要以反应式的方式使用响应数据,就需要使用 Flux 或 Mono 对其进行包装。如果已经有了 Flux 或Mono,想要通过 POST 或 PUT请求发送它们,那么需要在发送请求之前将数据提取到一个非反应式的类型中。
如果能够有一种方式让 RestTemplate 原生使用反应式类型就好了。不用担心,Spring提供了 WebClient,它可以作为反应式版本的 RestTemplate。WebClient 能够让我们请求外部 API 时发送和接收反应式类型。WebClient的使用方式与RestTemplate有很大的差别。RestTemplate 有多个方法处理不同类型的请求,而 WebClient有一个流畅(uent)的构建者风格接口,能够让我们描述和发送请求。WebClient的通用模式如下:
- 创建 WebClient 实例(或注入 WebClient bean );
- 指定要发送请求的 HTTP 方法;
- 指定请求中 URI 和头信息;
- 提交请求;
- 消费响应。
接下来,我们实际看几个 WebClient 的例子,首先是如何使用 WebClient 发送的 GET 请求。
4.1 获取资源
作为使用 WebClient 的样例,假设我们需要通过 Taco Cloud API 根据 ID 获取
Ingredient对象。如果使用 RestTemplate,那么我们可能会使用 getForObject() 方法。但借助 WebClient ,我们会构建请求、获取响应并提取一个会发布 Ingredient对象的 Mono。
Mono<Ingredient> ingredient= WebClient.create().get().uri("http://localhost:8080/ingredients/{id}",Ingredient.class).retrieve().bodyToMono(Ingredient.class);
ingredient.subscribe(i-> {...});
在这里,我们首先使用 create() 创建了一个新的 WebClient 实例,然后使用 get() 和uri() 定义对 http://localhost:8080/ingredients/{id} 的 GET 请求,其中{id}占位符会被ingredientId 的值替换。接着,retrieve() 会执行请求。最后,我们调用 bodyToMono()将响应体的载荷提取到 Mono<Ingredient>中,就可以继续执行 Mono 的其他操作了。
为了对 bodyToMono() 返回 Mono 执行其他的操作,很重要的一点是要在请求发送之前订阅。发送请求来获取值的集合是非常容易的。例如,如下的代码片段将获取所有配料:
Flux<Ingredient> ingredients = WebClient.create().get().uri("http://localhost:8080/ingredients").retrieve().bodyToFlux(Ingredient.class);
ingredients.subscribe(i -> {...});
获取多个条目与获取单个条目的大部分代码都是相同的。最大的差异在于我们不再使用 bodyToMono() 将响应体提取为Mono,而是使用 bodyToFlux() 将其提取为一个Flux。
与bodyToMono()类似,bodyToFlux() 返回的 Flux还没有被订阅。在数据流过之前我们可以对 Flux 添加一些额外的操作(过滤、映射等)。因此,非常重要的一点就是要订阅结果所形成的 Flux,否则请求将始终不会发送。
使用基础 URI 发送请求
你可能会发现,很多请求都会使用一个通用的基础URI。这样一来,创建 WebClient bean 的时候设置一个基础 URI 并将其注人所需的位置就是非常有帮助的。这样的bean 可以按照如下的方式来声明:
@Bean
public WebClient webClient(){return WebClient.create("http://localhost:8080");
}
然后,在想要使用基础 URI 的任意地方,我们都可以将WebClient bean 注人,并按照如下的方式来使用:
@Autowired
WebClient webClient;
public Mono<Ingredient> getIngredientById(String ingredientId){Mono<Ingredient>ingredient=webClient.get().uri("/ingredients/{id}",ingredientId).retrieve().bodyToMono(Ingredient.class);ingredient.subscribe(i->(...));
}
因为 WebClient 已经创建好了,所以我们可以通过 get() 方法直接使用它。对于 URI来说,我们只需要调用 uri() 指定相对于基础 URI 的相对路径。
对长时间运行的请求进行超时处理
我们需要考虑的一件事情就是,网络并不是始终可靠的,或者并不像我们预期的那么快,远程服务器在处理请求时有可能会非常缓慢。理想情况下,对远程服务的请求会在一个合理的时间内返回。即使无法正常返回,我们也希望客户端能够避免陷人长时间等待响应的窘境。
为了避免客户端请求被缓慢的网络或服务阻塞,我们可以使用 Flux 或 Mono 的timeout() 方法,为等待数据发布的过程设置一个时长限制。作为样例,我们考虑一下如何为获取配料数据使用 timeout() 方法:
Flux<Ingredient> ingredients = webClient.get().uri("/ingredients").retrieve().bodyToFlux(Ingredient.class);
ingredients.timeout(Duration.ofSeconds(1)).subscribe(i -> { ···},e -> {// handle timeout error});
可以看到,在订阅 Flux 之前,我们调用了timeout()方法,将持续时间设置成了1 秒。如果请求能够在1秒内返回,就不会有任何问题。如果请求耗时超过1秒,程会超时,从而调用传递给subscribe()的第二个参数——错误处理器。
4.2 发送资源
使用 WebClient 发送数据与接收数据并没有太大的差异。作为样例,假设我们有个Mono<Ingredient>,并且想要将 Mono发布的 Ingredient 对象以 POST 请求的形式发送到相对路径为"Ingredients"的URI上。我们需要做的就是使用 post() 方法来替换 get() 并通过 body() 方法指明要使用 Mono 来填充请求体:
Mono<Ingredient> ingredientMono=Mono.just(new Ingredient("INGC","Ingredient C",Ingredient.Type.VEGGIES));
Mono<Ingredient>result=webClient.post().uri("/ingredients").body(ingredientMono,Ingredient.class).retrieve().bodyToMono(Ingredient.class);
result.subscribe(i->{...});
如果没有要发送的 Mono 或 Flux,而只有原始的领域对象,那么可以使用 bodyValue()方法。例如,假设我们没有 Mono<Ingredient>,而有一个想要在请求体中发送的 Ingredient 对象,那么可以这样做:
Ingredient ingredient=...;
Mono<Ingredient>result=webClient.post().uri("/ingredients").bodyValue(ingredient).retrieve().bodyToMono(Ingredient.class);
result.subscribe(i->{...});
如果我们不使用 POST 请求,而是使用 PUT 请求更新一个 Ingredient ,就可以用 put() 来替换 post(),并相应地调整 URI 路径:
Ingredient ingredient =...;
Mono<Void> result = webClient.put().uri("/ingredients/{id}", ingredient.getId()).bodyValue(ingredient).retrieve().bodyToMono(Void.class);
result.subscribe();
PUT 请求的响应载荷一般是空的,所以我们必须要求 bodyToMono() 返回一个 Void 类型的 Mono。一旦订阅该Mono,请求就会立即发送。
4.3 删除资源
WebClient 还支持通过其 delete() 方法移除资源。例如,根据 ID 删除配料:
Mono<Void> result = webClient.delete().uri("/ingredients/{id}", ingredientId).retrieve().bodyToMono(Void.class);
result.subscribe();
与PUT请求类似,DELETE请求的响应不会有载荷。同样,返回并订阅Mono<Void>就会发送请求。
4.4 处理错误
到目前为止,所有的 WebClient 样例都假设有正常的结果,而没有 400 级别和 500 级别的状态码。如果出现这两种类型的错误状态,WebClient会记录失败信息,然后继续执行后续的操作。
如果我们需要处理这种错误,那么可以调用onStatus()来指定处理各种类型HTTP状态码的方式。onStatus() 接受两个函数,其中一个断言函数来匹配 HTTP 状态,另一个函数会得到 ClientResponse 对象,并返回 Mono<Throwable>。
为了阐述如何使用 onStatus() 创建自定义的错误处理器,请参考如下使用 WebClient根据 ID 获取配料的样例:
Mono<Ingredient> ingredientMono = webClient.get().uri("http://localhost:8080/ingredients/{id}",ingredientId).retrieve().bodyToMono(Ingredient.class);
如果 ingredientId 的值能够匹配已知的资源,那么结果得到的 Mono 在订阅时会发布一个 Ingredient。如果找不到匹配的配料呢?
当订阅可能会出现错误的 Mono 或 Flux 时,很重要的一点就是在调用subscribe()注册数据消费者的同时注册一个错误消费者:
ingredientMono.subscribe(ingredient -> {// handle the ingredient data...}, error -> {// deal with the error...});
如果能够找到配料资源,则调用传递给 subscribe() 的第一个 lambda 表达式(数据消费者),并且将匹配的 ingredient 对象传递过来。但是,如果找不到资源,那么请求常得到一个HTTP 404(NOT FOUND) 状态码的响应,它将会导致第二个 lambda 表达式(错误消费者)被调用,并且传递默认的 WebClientResponseException。
WebClientResponseException 最大的问题在于它无法明确指出导致 Mono 失败的原因。它的名字表明在 WebClient 发起的请求中出现了响应错误,但是我们需要深人WebClientResponseException 才能知道哪里出现了错误。如果给错误信息的消费者所提供的异常能够更加专注业务领域而不是专注WebClient,那就更好了。
我们可以添加一个自定义的错误处理器,并在这个处理器中提供将状态码转换为自已所选择的 Throwable 的代码。如果请求配料资源时试图获取 Mono 失败,就生成一个UnknownIngredientException。可以在调用 retrieve() 之后添加一个对 onStatus() 的调用从而实现这一点:
Mono<Ingredient> ingredientMono =webClient.get().uri("http://localhost:8080/ingredients/{id}",ingredientId).retrieve().onStatus(HttpStatus::is4xxClientError,response ->Mono.just(new UnknownIngredientException())).bodyToMono(Ingredient.class);
调用 onStatus() 时第一个参数是断言,它接收 HttpStatus,如果状态码是我们想要处理的,则会返回 true。如果状态码匹配,响应将会传递给第二个参数的函数并按需处理,最终返回 Throwable 类型的 Mono。
在样例中,如果状态码是 400 级别的(比如客户端错误),则会返回包含UnknownIngredientException 的 Mono。这会导致 ingredientMono 因为该异常而失败。
需要注意,HttpStatus::is4xxClientError 是对 HttpStatus 的 is4xxClientError 的方法引用。这意味着此时会基于 HttpStatus 对象调用该方法。我们也可以使用 HttpStanus 的其他方法作为方法引用,还可以以 lambda 表达式或方法引用的形式提供其他能够返回 boolean 值的函数。
例如,在错误处理中,我们可以更加精确地检查 HTTP404 (NOTFOUND)状态,只需将对 onStatus() 的调用修改成如下形式:
Mono<Ingredient> ingredientMono = webClient.get().uri("http://localhost:8080/ingredients/{id}", ingredientId).retrieve().onStatus(status -> status == HttpStatus.NOT_FOUND,response -> Mono.just(new UnknownIngredientException())).bodyToMono(Ingredient.class);
值得注意的是,可以按需调用 onStatus() 任意次,以便处理响应中可能返回的各种HTTP 状态码。
4.5 交换请求
到目前为止,在使用 WebClient 的时候,我们都是使用它的 retrieve() 方法发送请求,在这些场景中,retrieve() 方法会返回一个ResponseSpec 类型的对象,通过调用它的onStatus()、bodyToFlux()和 bodyToMono()方法,我们就能处理响应。对于简单的场景,使用 ResponseSpec 就足够了,但是它在很多方面都有局限性。如果我们想要访问响应的头信息或 cookie 的值,那么 ResponseSpec 就无能为力了。
在使用 ResponseSpec 遇到困难时,可以通过调用 exchangeToMono() 或exchangeToFlux() 方法来代替 retrieve()。exchangeToMono()方法会返回 ClientResponse 类型的Mono,我们可以对它采用各种反应式操作,以便探测和使用整个响应中的数据,包括载荷、头信息和 cookie。exchangeToFlux()方法的工作方式大致与此相同,但为了处理响应中的多个数据项,该方法会返回 ClientResponse 类型的 Flux 对象。
在了解 exchangeToMono() 和 exchangeToFlux() 方法与 retrieve()的差异之前,我们先看一下它们之间的相似之处。如下的代码片段通过 WebClient 和exchangeToMono()方法,根据 ID 获取配料:
Mono<Ingredient> ingredientMono = webClient.get().uri("http://localhost:8080/ingredients/{id}",ingredientId).exchangeToMono(cr->cr.bodyToMono(Ingredient.class));
这几乎与使用 retrieve() 的样例相同:
Mono<Ingredient> ingredientMono = webClient.get().uri("http://localhost:8080/ingredients/{id}",ingredientId).retrieve().bodyToMono(Ingredient.class);
在 exchangeToMono() 样例中,我们不是使用 ResponseSpec 对象的 bodyToMono() 方法来获取 Mono<Ingredient>,而是得到了一个 Mono<ClientResponse>,通过调用它的 bodyToMono() 获取到我们想要的 Mono。
现在,我们看一下 exchangeToMono() 与 retrieve() 的差异在什么地方。假设请求的响应中包含一个名为 X_UNAVAILABLE 的头信息,如果它的值为 true ,则表明该配料是不可用的(因为某种原因)。为了讨论方便,假设我们希望在这个头信息存在的情况下得到空的 Mono,即不返回任何内容。通过添加另外一个 flatMap() 调用,我们就能实现这一点。WebClient的完整调用过程如下所示:
Mono<Ingredient> ingredientMono = webClient.get().uri("http://localhost:8080/ingredients/{id}", ingredientId).exchangeToMono(cr -> {if (cr.headers().header("X_UNAVAILABLE").contains("true")) {return Mono.empty();}return Mono.just(cr);}).flatMap(cr -> cr.bodyToMono(Ingredient.class));
exchangeToMono() 的调用会探查给定 ClientRequest 对象的响应头,查看是否存在值为 true 的 X_UNAVAILABLE 头信息。如果存在,就返回一个空的 Mono;否则,返回一个包含 ClientResponse 的新 Mono。不管是哪种情况,返回的 Mono 都会成为后续flatMap() 操作所要使用的那个 Mono。
5 总结
WebFlux是Spring Framework 5中引入的一个新的响应式编程框架,它提供了构建非阻塞、异步和事件驱动的服务的能力。相比于传统的Spring MVC,WebFlux的一些优点包括:
-
非阻塞和异步:WebFlux基于Reactor库,实现了非阻塞I/O操作。这意味着服务器可以在等待I/O操作(如数据库调用或网络请求)完成时,继续处理其他任务,从而提高了资源利用率和吞吐量。
-
更高的并发处理能力:由于非阻塞的特性,WebFlux可以在相同的硬件资源下处理更多的并发连接,尤其是在I/O密集型应用中表现突出。
-
函数式编程模型:WebFlux支持两种编程模型——注解模型和函数式路由模型。函数式路由模型提供了一种更灵活、更精简的方式来定义路由和处理请求。
-
反应式编程支持:WebFlux提供了对反应式编程的完整支持,允许开发者使用Flux和Mono这样的响应式类型来处理流式的数据。
-
与Spring生态系统的整合:WebFlux与Spring Data、Spring Security等其他Spring项目良好集成,让开发者可以在响应式应用中利用Spring提供的强大功能。
-
更好的资源利用:非阻塞模型意味着更少的线程可以处理同样数量的请求,从而减少了资源消耗,尤其是在资源有限的环境中,比如微服务架构和云平台。
-
适应现代化应用需求:随着单页应用(SPA)、移动应用和微服务架构的流行,系统间需要处理的事件和消息越来越多,WebFlux提供了构建这类应用所需的响应式编程模型。
尽管WebFlux带来了很多优势,但它也不是万能的。选择使用WebFlux还是传统的Spring MVC主要取决于应用的具体需求,以及开发团队对响应式编程的熟悉程度。对于一些简单的、非I/O密集型的应用,传统的Spring MVC可能仍然是一个更好的选择。