1、OCR文字识别
FontFile := 'Universal_0-9_NoRej'
dev_update_window ('off')
read_image (bottle, 'bottle2')
get_image_size (bottle, Width, Height)
dev_open_window (0, 0, Width, Height, 'black', WindowHandle)
set_display_font (WindowHandle, 16, 'mono', 'true', 'false')
dev_display (bottle)
disp_continue_message (WindowHandle, 'black', 'true')
stop ()* 1.创建一个用于文本识别的文本模型读取器
* 参数一:auto 表示使用自动模式选择字体
* 参数二:FontFile 是用于识别的字体文件路径
* 参数三:存储文本模型的变量
create_text_model_reader ('auto', FontFile, TextModel)* 2.设置模型参数
* 参数二:min_stroke_width:最小笔画宽度,值为6
set_text_model_param (TextModel, 'min_stroke_width', 6)
* 简化对分段文本内容的特定结构进行提取(例如日期YY-MM-DD) 2 2 2表示文本的显示结构
set_text_model_param (TextModel, 'text_line_structure', '2 2 2')* 3.在图像中查找文本片段并输出到句柄
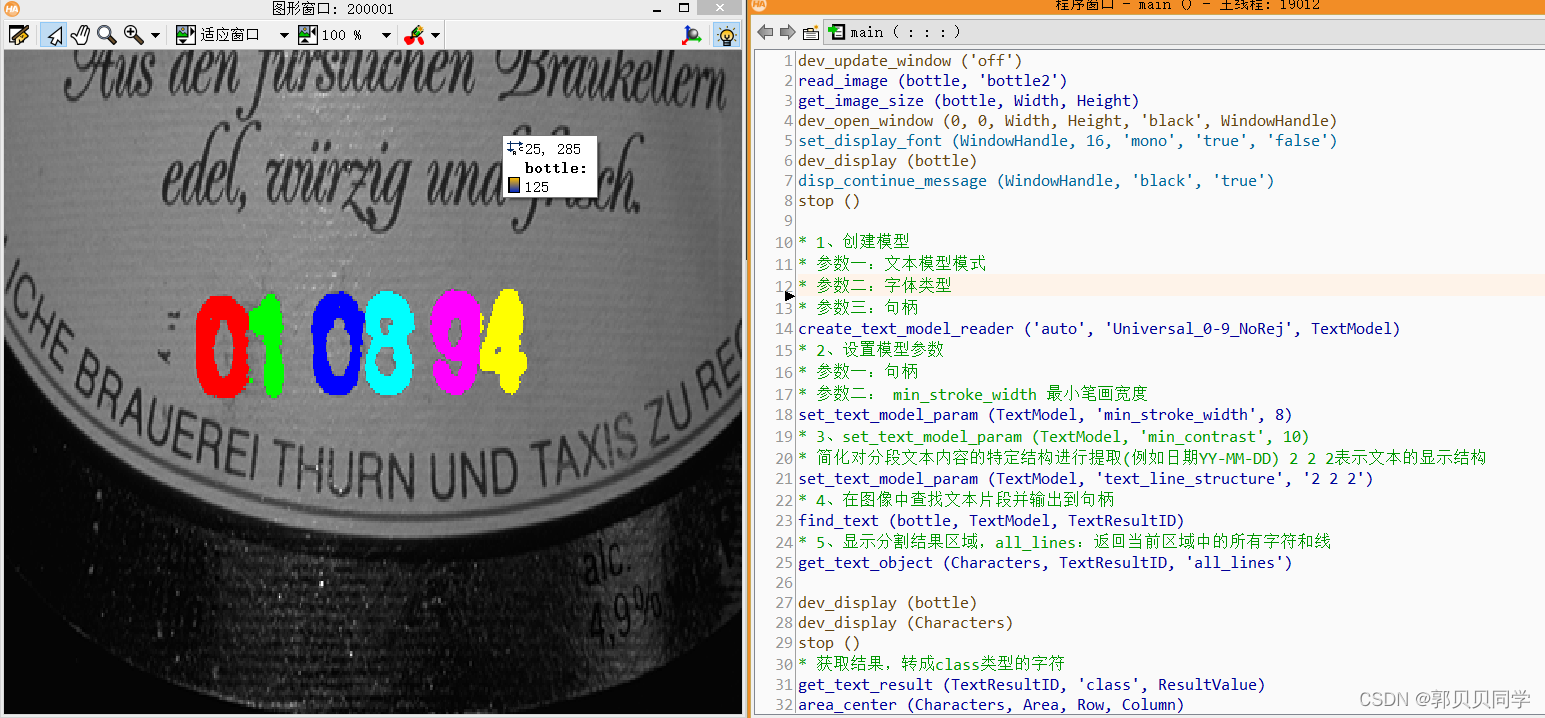
find_text (bottle, TextModel, TextResultID)* 4.从文本识别结果中获取所有字符信息,all_lines返回当前区域中的所有字符和线
get_text_object (Characters, TextResultID, 'all_lines')
* 5.在显示窗口中显示图像 和 识别出的字符信息。
dev_display (bottle)
dev_display (Characters)
stop ()
* 6.获取结果,转成class类型的字符
get_text_result (TextResultID, 'class', ResultValue)
area_center (Characters, Area, Row, Column)
2、训练分类器
read_image (Image, 'bottle2')
get_image_size (Image, Width, Height)
dev_close_window ()
dev_open_window (0, 0, Width, Height, 'black', WindowHandle)
* 设置字体样式和大小
set_display_font (WindowHandle, 25, 'mono', 'true', 'false')
* 二值化操作
threshold (Image, Region, 0, 90)* 对区域进行形状填充,输入最小面积和最大面积
* 参数一:要进行形状填充的输入区域。
* 参数二:用于存储填充后的区域的变量。
* 参数三:填充的准则,这里是根据区域的面积进行填充。
* 参数四:最小区域面积
* 参数五:指定的连接性,表示填充时考虑的相邻像素的连接性。
fill_up_shape (Region, RegionFillUp, 'area', 1, 5)
* 填充所有的孔洞
* fill_up (RegionFillUp, RegionFillUp1)*开运算
*先腐蚀后膨胀,可以有效的断开,减少像素。
*相当于把整体变暗
opening_circle (RegionFillUp, RegionOpening, 2.5)
fill_up (RegionOpening, RegionFillUp1)
*使用矩形进行开运算
opening_rectangle1 (RegionFillUp1, RegionOpening1, 1, 7)
*连通性
connection (RegionOpening1, ConnectedRegions)
*求交集 当前区域与开运算之后的区域
intersection (ConnectedRegions, RegionOpening, RegionIntersection)
*特征提取
select_shape (RegionIntersection, SelectedRegions, 'area', 'and', 300, 9999)sort_region (SelectedRegions, SortedRegions, 'first_point', 'true', 'column')
dev_display (Image)
dev_set_color ('green')
dev_set_line_width (2)
dev_set_shape ('rectangle1')
dev_set_draw ('margin')
dev_display (SortedRegions)*训练字体
TrainingNames:=['0','1','0','8','9','4']
*字体名称
FontName:='bottle'
TrainingFileName:=FontName+'.trf'
*排序
sort_region (SortedRegions, SortedRegions1, 'first_point', 'true', 'column')
*变换区域的形状
*rectangle1:平行于坐标轴的最大内接矩形
shape_trans (SortedRegions1, RegionTrans, 'rectangle1')
area_center (RegionTrans, Area, Row, Column)
*求平均的行坐标
MeanRow:=mean(Row)
*如果发现错误,则把当前.trf文件删除
dev_set_check ('~give_error')
delete_file (TrainingFileName)
for I := 0 to |TrainingNames|-1 by 1*选择对应的i区域,进行赋值select_obj (SortedRegions1, ObjectSelected, I+1)*追加文本append_ocr_trainf (ObjectSelected, Image, TrainingNames[I], TrainingFileName)disp_message (WindowHandle, TrainingNames[I], 'image', MeanRow-40, Column[I]-15, 'black', 'true')
endfor*sort排序[0,0,1,4,8,9],uniq删除重复[0,1,4,8,9]*
CharNames:=uniq(sort(TrainingNames))
*mlp训练器,
*参数1:WidthCharacter>>>输入被分割的字符缩放的指定宽度 默认是8 范围4~20
*参数2:HeightCharacter>>>输入被分割的字符缩放的指定高度 默认是10 范围4~20
*参数3:Interpolation>>> 插值算法,默认是不变
*参数4:Features>>>分类特征,默认是default
*参数5:Characters>>>设置要匹配的字符集合
*参数6:NumHidden>>>MLP隐藏单元数量
*参数7:Preprocessing>>>矢量特征转换,默认是none代表没有,normalization正常
*参数8:NumComponents>>>预处理参数,交换的要素的数量
*参数9:RandSeed>>>随机数生成器的种子值 用于使用随机值初始化 MLP
*参数10:OCRHandle>>>句柄
create_ocr_class_mlp (8, 10, 'constant', 'default', CharNames, 10, 'none', 10, 42, OCRHandle)*训练mlp分类器
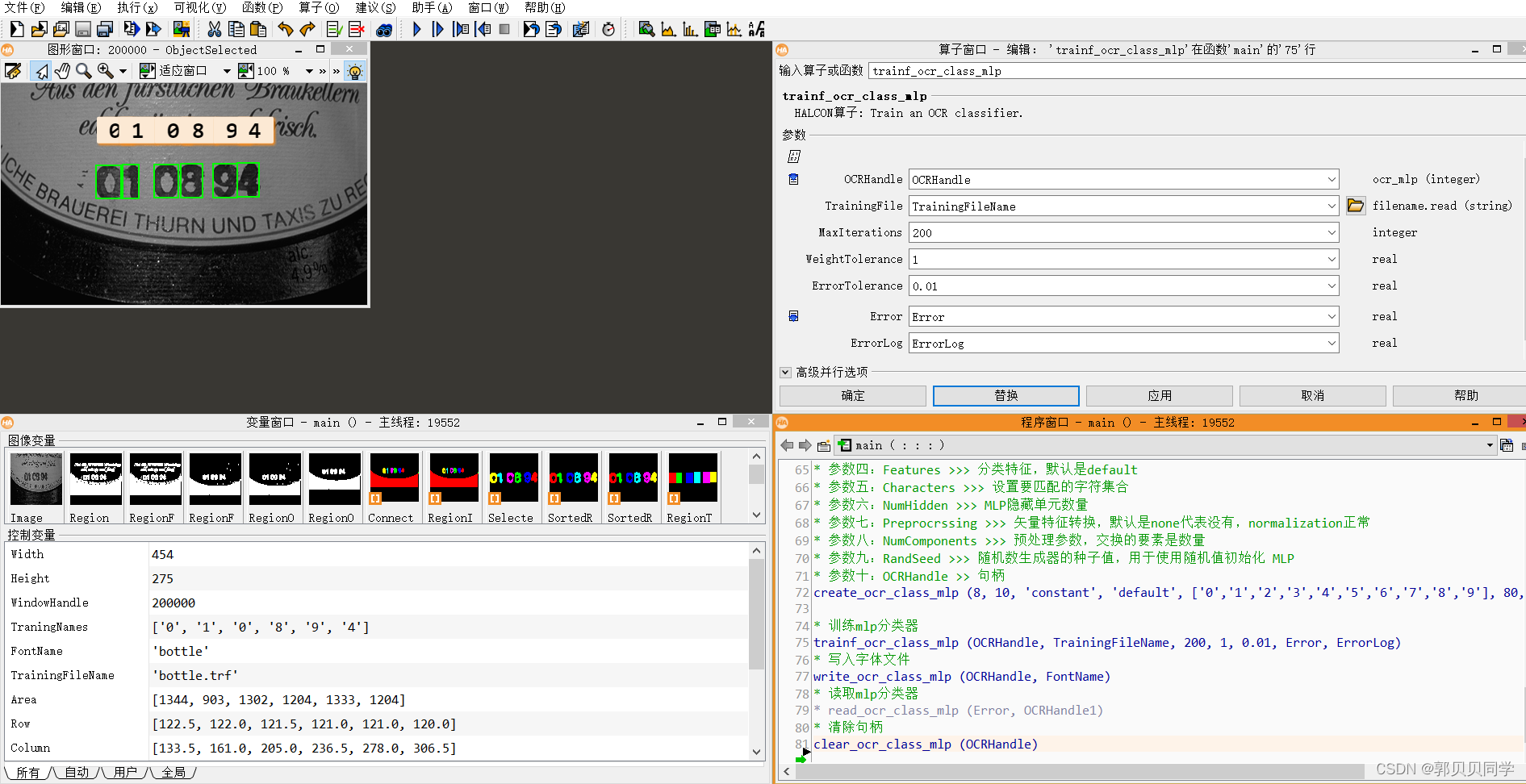
trainf_ocr_class_mlp (OCRHandle, TrainingFileName, 200, 1, 0.01, Error, ErrorLog)
*写入字体文件
write_ocr_class_mlp (OCRHandle, FontName)*读取mlp分类器
*read_ocr_class_mlp (Error, OCRHandle1)
*清除句柄
clear_ocr_class_mlp (OCRHandle)