【AI】创建自己的基于会话的自定义模型的ChatGPT
目录
- 【AI】创建自己的基于会话的自定义模型的ChatGPT
- 开篇
- 功能设计
- 步骤详解
- 1. 爬取Web数据
- 2. 拆分文档
- 3. 创建向量嵌入
- 4. 将向量嵌入存储在Chroma中
- 5. 用户提出问题
- 6. 创建提问的向量嵌入
- 7. 语义搜索向量数据库
- 8. 生成提示
- 9. 提交提示到LLM
- 10. LLM生成答案
- 11. 在MongoDB中保存查询和响应的聊天历史记录
- 12. 将答案发送回用户
- 实现
- 1. 配置
- 2. HTTP API
- 3. ChatBot模型
- 运行应用程序
- 1. 安装依赖项
- 2. 运行 MongoDB
- 3. 运行ChatBot
- 4. 提问题
- 参考
推荐超级课程:
- Docker快速入门到精通
- Kubernetes入门到大师通关课
- AWS云服务快速入门实战

开篇
在我的上一篇文章中,我介绍了一款定制化ChatGPT的开发过程,利用了OpenAI GPT-3.5 LLM、Langchain和LlamaIndex,特别强调了整合独特数据集的过程。
本文探讨了基于会话的自定义ChatGPT模型(ChatBot)的创建,利用了OpenAI GPT-4 LLM和Langchain的ConversationalRetrievalChain更高级的功能。
ConversationalRetrievalChain结合了语言模型和外部信息检索系统(例如文档、数据库数据、网站数据等)的能力。
其目的是通过最新的外部信息增强语言模型的回复。
它通过首先使用信息检索系统来获取来自外部来源的相关信息,然后将这些信息传递给语言模型,并将其融入回复中。
利用ConversationalRetrievalChain功能,Chatbot整合了一个定制数据集,该数据集通过Langchain的RecursiveUrlLoader从在线网站动态获取。用户可以通过由OpenAI的GPT-4 LLM驱动的Chatbot与网站数据进行交互。为演示目的,我选择了Open5GS文档网站(Open5GS是5G核心的C语言实现)。
使用Langchain的RecursiveUrlLoader从Open5GS文档中获取的数据被拆分,然后存储在Chroma向量数据库中作为向量嵌入。
因此,用户可以通过使用GPT-4 LLM构建的Chatbot无缝地与Open5GS文档的内容交互。GPT-4 LLM根据Open5GS文档中的内容为用户提供答案。
此API的一个关键功能是同时处理来自多个用户的请求,并有效地管理它们各自的会话。
这一功能主要依赖于将MongoDB集成到聊天会话内存管理中。
这种设置确保所有用户聊天历史都持久存储在MongoDB中,方便检索过去的互动。这样的记忆系统对于保持丰富、上下文感知的对话历史至关重要,增强了ChatBot进行更有意义和相关性的讨论的能力,这些讨论受过往互动知识的启发。
功能设计
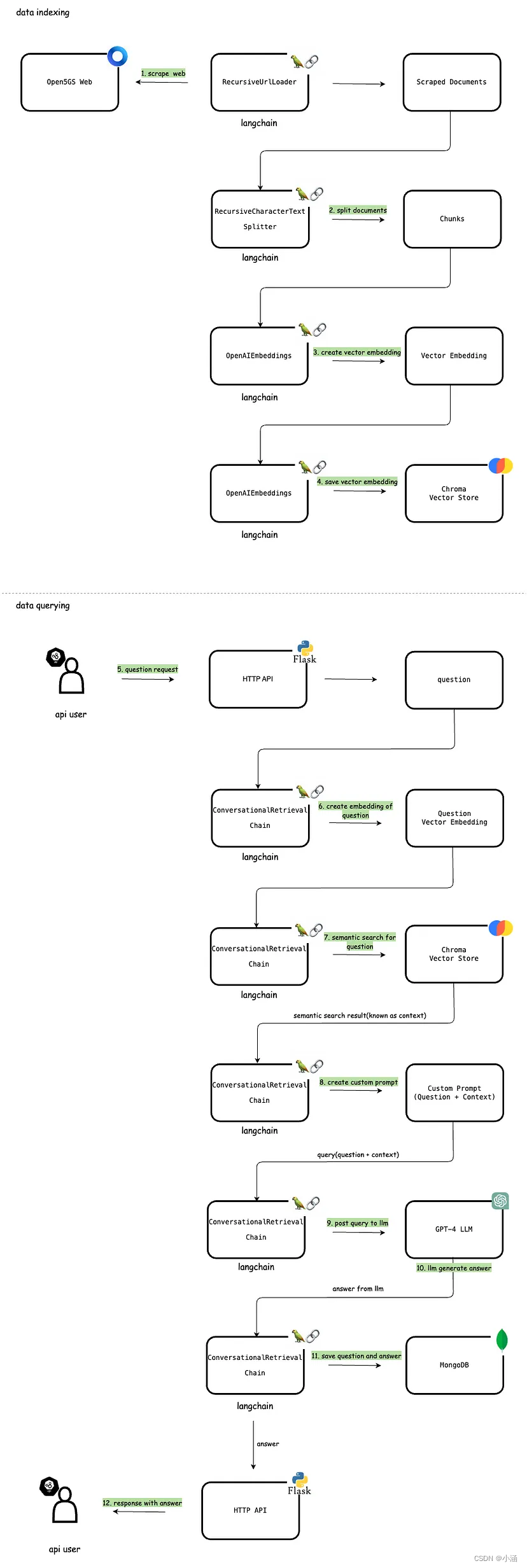
以下部分讨论了Chatbot的主要功能。涵盖这些不同组件的综合功能架构在下面的图中有详细说明。
步骤详解
1. 爬取Web数据
Langchain提供不同类型的文档加载器来从不同来源加载数据作为Document。RecursiveUrlLoader是这样一种文档加载器,可以用来将web url中的数据加载到文档中。这一步利用Langchain的RecursiveUrlLoader从web中爬取数据作为文档。RecursiveUrlLoader会递归地爬取给定的url到指定的max_depth,读取web上的数据。这些数据用于创建向量嵌入并回答用户的问题。
2. 拆分文档
处理长文本时,将文本分割成较小的段落至关重要。虽然这项任务看似简单,但实际上可能包含相当大的复杂性。目标是确保语义相关的文本段保持在一起。Langchain文本拆分器有效地完成了这项任务。它将文本分成小的、语义上有意义的单元(通常是句子)。然后这些较小的段落被组合成更大的块,直到达到特定函数确定的一定大小。达到这个大小后,该块被标记为单独的文本片段,然后过程重复开始,有一定的重叠。在这种特定情况下,我使用了RecursiveCharacterTextSplitter将爬取的文档拆分成可管理的块。
3. 创建向量嵌入
一旦数据收集完毕并拆分,下一步涉及将这些文本信息转换为向量嵌入。然后从拆分的数据创建这些嵌入。文本嵌入对LLM操作至关重要。尽管使用自然语言处理语言模型技术是可以的,但存储和检索这样的数据效率非常低。为了增强效率,必须将文本数据转换为向量形式。有专门的机器学习模型专门设计用于从文本创建嵌入。在这种情况下,我使用OpenAIEmbeddings生成向量嵌入。因此,文本被转换成多维向量,从根本上是捕捉语义含义和上下文细微差别的高维数值表示。一旦嵌入,这些数据可以分组、排序、搜索等。我们可以计算两个句子之间的距离,以确定它们的相关程度。重要的是,这些操作超越了传统依赖关键字的数据库搜索,而是捕捉了句子之间的语义接近度。
4. 将向量嵌入存储在Chroma中
生成的向量嵌入然后存储在Chroma向量数据库中。Chroma(通常称为ChromaDB)是一个开源嵌入数据库,通过存储和检索嵌入及其元数据、文档和查询,使构建LLM应用变得容易。Chroma高效地处理这些嵌入,允许快速检索和比较基于文本的数据。传统数据库可用于准确查询,但在理解人类语言的细微差别方面表现不佳。引入向量数据库,是处理语义搜索的一个重要改变。与传统文本匹配依赖精确词语或短语不同,像Postgres with pgvector这样的向量数据库会语义化地处理信息。该数据库是系统匹配用户查询与来自爬取内容中最相关信息之间的能力的基石,实现快速准确的响应。
5. 用户提出问题
系统提供一个API,用户可以通过该API提交问题。在这个用例中,用户可以提出与Open5GS文档内容相关的任何问题。该API作为用户与ChatBot之间的主要交互界面。API接受一个名称为user_id的参数,用于标识不同的用户会话。这个user_id仅用于演示目的。在实际情况下,它可以在HTTP请求中通过授权头(例如JWT承载令牌)进行管理。API设计直观且易于访问,使用户能够轻松输入他们的查询并接收响应。
6. 创建提问的向量嵌入
当用户通过API提交问题时,系统会将这个问题转换成一个向量嵌入。这个嵌入的生成由ConversationalRetrievalChain自动处理。这有助于在向量数据库中语义搜索与问题相关的文档。
7. 语义搜索向量数据库
一旦为问题创建了向量嵌入,系统使用语义搜索扫描向量数据库,识别与用户查询最相关的内容。通过将问题的向量嵌入与存储数据的向量嵌入进行比较,系统可以准确地找到与查询的语境相似或相关的信息。在这种情况下,我使用ConversationalRetrievalChain,该工具会自动处理基于输入查询的语义搜索。语义搜索的结果然后被确定为LLM的“上下文”。
8. 生成提示
接下来,ConversationalRetrievalChain根据用户的问题和语义搜索结果(上下文)生成一个自定义提示。对于语言模型来说,提示是用户提供的一组指示或输入,用于引导模型的响应。这有助于模型理解上下文并生成相关和连贯的基于语言的输出,如回答问题、完成句子或参与对话。
9. 提交提示到LLM
生成提示后,将其发布到LLM(在我们的情况下是OpenAI GPT-4 LLM)。LLM然后根据提供的上下文找到问题的答案。ConversationalRetrievalChain处理将查询提交给LLM的功能(在幕后,它使用OpenAI API提交问题)。
10. LLM生成答案
LLM利用OpenAI GPT-4的先进功能,在提供的内容的上下文中处理问题。然后生成一个响应并将其发送回去。
11. 在MongoDB中保存查询和响应的聊天历史记录
Langchain提供各种组件来管理对话记忆。在这个ChatBot中,已经采用了MongoDB来管理对话记忆。在这个阶段,用户的问题和ChatBot的回应都被记录在MongoDB存储中作为聊天历史的一部分。这种方法确保了所有用户的聊天历史都被持久地存储在MongoDB中,从而能够检索以前的互动。数据以每个用户会话为基础存储在MongoDB中。为了区分用户会话,API利用了之前提到的user_id参数。这些历史数据对塑造未来的互动至关重要。当同一用户提出后续问题时,聊天历史以及新的语义搜索结果(上下文)被传递到LLM。这个过程确保了ChatBot在对话中能够保持上下文,从而产生更加精确和定制的回应。
12. 将答案发送回用户
最后,从LLM收到的答案通过HTTP API转发给用户。用户可以通过提供相同的user_id在后续请求中继续提出不同的问题。然后系统识别用户的聊天历史并将其包含在发送给LLM的信息中,同时还包括了新的语义搜索结果。这个过程确保了一次无缝且具有上下文意识的对话,通过每一次互动丰富用户体验。
实现
下面详细介绍了这个ChatBot的完整实现。
1. 配置
在config.py文件中,我定义了ChatBot中使用的各种配置。这些配置是通过环境变量读取的,遵循12因素应用程序的原则。
import os# openai api key
OPENAI_API_KEY = os.getenv('OPENAI_API_KEY', '')# define init index
INIT_INDEX = os.getenv('INIT_INDEX', 'false').lower() == 'true'# vector index persist directory
INDEX_PERSIST_DIRECTORY = os.getenv('INDEX_PERSIST_DIRECTORY', "./data/chromadb")# target url to scrape
TARGET_URL = os.getenv('TARGET_URL', "https://open5gs.org/open5g