1、打开前面创建的项目“BigData-Etl-KongGuan”,创建一些数据库访问的工具类和辅助类。
1)打开SpringBoot项目:BigData-Etl-KongGuan

2)创建数据库访问的工具类和辅助类:
| com.qrsoft.etl.dao.IBaseDao | 数据库访问的通用类,包括创建连接、执行更新等通用操作 |
| com.qrsoft.etl.common.db.ConnectionPoolManager | 连接管理类 |
| com.qrsoft.etl.common.db.IConnectionPool | 连接池管理类接口 |
| com.qrsoft.etl.common.db.ConnectionPool | 连接池管理类接口实现类 |
| com.qrsoft.etl.common.db.DBbean | 这是外部可以配置的连接池属性 可以允许外部配置,拥有默认值 |
| com.qrsoft.etl.common.db.DBInitInfo | 初始化,模拟加载所有的配置文件 |
| com.qrsoft.etl.common.Constants | 全局常量类 |
| com.qrsoft.etl.util.ConfigUtil | 加载配置文件的工具类 |
| com.qrsoft.etl.util.ConfigManager | 配置文件管理的工具类 |
| com.qrsoft.etl.util.MapManager | 地图管理的工具类,例如:是否在矩形区域内 |
- 创建com.qrsoft.etl.util.ConfigUtil类,该类是一个通用工具类,用于加载myconfig.properties配置文件,并提供了一个根据键来读取配置文件中属性值的方法readProperty(key)。
package com.qrsoft.etl.util;import org.springframework.core.io.support.PropertiesLoaderUtils;import java.io.IOException;
import java.util.Properties;public class ConfigUtil {public static String readProperty(String key){Properties properties = new Properties();try {properties = PropertiesLoaderUtils.loadAllProperties("myconfig.properties");} catch (IOException e) {e.printStackTrace();}return properties.get(key).toString();}
}- 创建com.qrsoft.etl.util.ConfigManager类,该类是一个通用工具类,用于配置文件管理,在该类的构造函数中加载config.properties配置文件,并提供了一个根据键来读取配置文件中属性值的方法getValue(key)。
package com.qrsoft.etl.util;import java.io.IOException;
import java.io.InputStream;
import java.util.Properties;public class ConfigManager {private static ConfigManager configManager; // 声明工具类的一个私有的对象private static Properties properties; //声明对象private ConfigManager() { //私有无参构造方法String configFile = "config.properties";properties = new Properties();InputStream in = ConfigManager.class.getClassLoader().getResourceAsStream(configFile);try {properties.load(in);in.close();} catch (IOException e) {e.printStackTrace();}}public static ConfigManager getInstance() {if (configManager == null) {configManager = new ConfigManager();}return configManager;}public String getValue(String key) {return properties.getProperty(key);}
}- 创建com.qrsoft.etl.util.MapManager类,该类是地图管理的工具类,提供了地图操作的相关工具方法,例如:地图上某个经纬度的点是否在矩形区域内、判断是否在经纬度范围内等。
package com.qrsoft.etl.util;public class MapManager {/*** 是否在矩形区域内* @Title: isInArea* @Description: TODO()* @param lat 测试点经度* @param lng 测试点纬度* @param minLat 纬度范围限制1* @param maxLat 纬度范围限制2* @param minLng 经度限制范围1* @param maxLng 经度范围限制2* @return boolean*/public boolean isInRectangleArea(double lat,double lng,double minLat,double maxLat,double minLng,double maxLng){if(this.isInRange(lat, minLat, maxLat)){//如果在纬度的范围内if(minLng*maxLng>0){if(this.isInRange(lng, minLng, maxLng)){return true;}else {return false;}}else {if(Math.abs(minLng)+Math.abs(maxLng)<180){if(this.isInRange(lng, minLng, maxLng)){return true;}else {return false;}}else{double left = Math.max(minLng, maxLng);double right = Math.min(minLng, maxLng);if(this.isInRange(lng, left, 180)||this.isInRange(lng, right,-180)){return true;}else {return false;}}}}else{return false;}}/*** 判断是否在经纬度范围内*/public boolean isInRange(double point, double left,double right){if(point>=Math.min(left, right)&&point<=Math.max(left, right)){return true;}else {return false;}}
}- 创建com.qrsoft.etl.common.db.DBbean类,该类中定义了外部可以配置的连接池属性 可以允许外部配置,拥有默认值。
package com.qrsoft.etl.common.db;public class DBbean {// 连接池属性private String driverName;private String url;private String userName;private String password;// 连接池名字private String poolName;private int minConnections = 10; // 空闲池,最小连接数private int maxConnections = 300; // 空闲池,最大连接数private int initConnections = 20;// 初始化连接数private long connTimeOut = 1000;// 重复获得连接的频率private int maxActiveConnections = 500;// 最大允许的连接数,和数据库对应private long connectionTimeOut = 0;// 连接超时时间,默认20分钟private boolean isCurrentConnection = true; // 是否获得当前连接,默认trueprivate boolean isCheakPool = true; // 是否定时检查连接池private long lazyCheck = 1000 * 60 * 60;// 延迟多少时间后开始 检查private long periodCheck = 1000 * 60 * 60;// 检查频率public DBbean(String driverName, String url, String userName,String password, String poolName) {super();this.driverName = driverName;this.url = url;this.userName = userName;this.password = password;this.poolName = poolName;}public DBbean() {}public String getDriverName() {if (driverName == null) {driverName = this.getDriverName() + "_" + this.getUrl();}return driverName;}public void setDriverName(String driverName) {this.driverName = driverName;}public String getUrl() {return url;}public void setUrl(String url) {this.url = url;}public String getUserName() {return userName;}public void setUserName(String userName) {this.userName = userName;}public String getPassword() {return password;}public void setPassword(String password) {this.password = password;}public String getPoolName() {return poolName;}public void setPoolName(String poolName) {this.poolName = poolName;}public int getMinConnections() {return minConnections;}public void setMinConnections(int minConnections) {this.minConnections = minConnections;}public int getMaxConnections() {return maxConnections;}public void setMaxConnections(int maxConnections) {this.maxConnections = maxConnections;}public int getInitConnections() {return initConnections;}public void setInitConnections(int initConnections) {this.initConnections = initConnections;}public int getMaxActiveConnections() {return maxActiveConnections;}public void setMaxActiveConnections(int maxActiveConnections) {this.maxActiveConnections = maxActiveConnections;}public long getConnTimeOut() {return connTimeOut;}public void setConnTimeOut(long connTimeOut) {this.connTimeOut = connTimeOut;}public long getConnectionTimeOut() {return connectionTimeOut;}public void setConnectionTimeOut(long connectionTimeOut) {this.connectionTimeOut = connectionTimeOut;}public boolean isCurrentConnection() {return isCurrentConnection;}public void setCurrentConnection(boolean isCurrentConnection) {this.isCurrentConnection = isCurrentConnection;}public long getLazyCheck() {return lazyCheck;}public void setLazyCheck(long lazyCheck) {this.lazyCheck = lazyCheck;}public long getPeriodCheck() {return periodCheck;}public void setPeriodCheck(long periodCheck) {this.periodCheck = periodCheck;}public boolean isCheakPool() {return isCheakPool;}public void setCheakPool(boolean isCheakPool) {this.isCheakPool = isCheakPool;}
}- 创建com.qrsoft.etl.common.db.DBInitInfo类,该类主要用于加载配置文件中所有的有关数据库的配置信息,初始化数据库连接对象。
package com.qrsoft.etl.common.db;import com.qrsoft.etl.util.ConfigManager;import java.util.ArrayList;
import java.util.List;public class DBInitInfo {// 设置注册属性public static String DRIVER = ConfigManager.getInstance().getValue("jdbc.driver");public static String URL = ConfigManager.getInstance().getValue("jdbc.url");public static String USERNAME = ConfigManager.getInstance().getValue("jdbc.username");public static String PASSWORD = ConfigManager.getInstance().getValue("jdbc.password");public static String MinConnections = ConfigManager.getInstance().getValue("jdbc.min");public static String MaxConnections = ConfigManager.getInstance().getValue("jdbc.max");public static List<DBbean> beans = null;static {beans = new ArrayList<DBbean>();// 这里数据 可以从xml 等配置文件进行获取,为了测试,这里直接写死了DBbean beanMysql = new DBbean();beanMysql.setDriverName(DRIVER);beanMysql.setUrl(URL);beanMysql.setUserName(USERNAME);beanMysql.setPassword(PASSWORD);beanMysql.setMinConnections(Integer.parseInt(MinConnections));beanMysql.setMaxConnections(Integer.parseInt(MaxConnections));beanMysql.setPoolName("pool");beans.add(beanMysql);}
}- 创建com.qrsoft.etl.common.db.IConnectionPool接口,该接口中定义了连接池操作类的接口方法,如:获得连接、回收连接、销毁清空、查看连接池活动状态、定时检查连接池等接口方法。
package com.qrsoft.etl.common.db;import java.sql.Connection;
import java.sql.SQLException;public interface IConnectionPool {// 获得连接public Connection getConnection();// 获得当前连接public Connection getCurrentConnecton();// 回收连接public void releaseConn(Connection conn) throws SQLException;// 销毁清空public void destroy();// 连接池是活动状态public boolean isActive();// 定时器,检查连接池public void cheackPool();
}- 创建com.qrsoft.etl.common.db.ConnectionPool类,该类实现了IConnectionPool接口,并实现了接口中定义的方法。
package com.qrsoft.etl.common.db;import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.util.List;
import java.util.Timer;
import java.util.TimerTask;
import java.util.Vector;public class ConnectionPool implements IConnectionPool {// 连接池配置属性private DBbean dbBean;private boolean isActive = false; // 连接池活动状态private int contActive = 0;// 记录创建的总的连接数// 空闲连接private List<Connection> freeConnection = new Vector<Connection>();// 活动连接private List<Connection> activeConnection = new Vector<Connection>();// 将线程和连接绑定,保证事务能统一执行private static ThreadLocal<Connection> threadLocal = new ThreadLocal<Connection>();public ConnectionPool(DBbean dbBean) {super();this.dbBean = dbBean;init();cheackPool();}// 初始化public void init() {try {Class.forName(dbBean.getDriverName());for (int i = 0; i < dbBean.getInitConnections(); i++) {Connection conn;conn = newConnection();// 初始化最小连接数if (conn != null) {freeConnection.add(conn);contActive++;}}isActive = true;} catch (ClassNotFoundException e) {e.printStackTrace();} catch (SQLException e) {e.printStackTrace();}}// 获得当前连接public Connection getCurrentConnecton() {// 默认线程里面取Connection conn = threadLocal.get();if (!isValid(conn)) {conn = getConnection();}return conn;}// 获得连接public synchronized Connection getConnection() {Connection conn = null;try {// 判断是否超过最大连接数限制if (contActive < this.dbBean.getMaxActiveConnections()) {if (freeConnection.size() > 0) {conn = freeConnection.get(0);if (conn != null) {threadLocal.set(conn);}freeConnection.remove(0);} else {conn = newConnection();}} else {// 继续获得连接,直到从新获得连接wait(this.dbBean.getConnTimeOut());conn = getConnection();}if (isValid(conn)) {activeConnection.add(conn);contActive++;}} catch (SQLException e) {e.printStackTrace();} catch (ClassNotFoundException e) {e.printStackTrace();} catch (InterruptedException e) {e.printStackTrace();}return conn;}// 获得新连接private synchronized Connection newConnection() throws ClassNotFoundException, SQLException {Connection conn = null;if (dbBean != null) {Class.forName(dbBean.getDriverName());conn = DriverManager.getConnection(dbBean.getUrl(), dbBean.getUserName(), dbBean.getPassword());}return conn;}// 释放连接public synchronized void releaseConn(Connection conn) throws SQLException {if (isValid(conn)&& !(freeConnection.size() > dbBean.getMaxConnections())) {freeConnection.add(conn);activeConnection.remove(conn);contActive--;threadLocal.remove();// 唤醒所有正待等待的线程,去抢连接notifyAll();}}// 判断连接是否可用private boolean isValid(Connection conn) {try {if (conn == null || conn.isClosed()) {return false;}} catch (SQLException e) {e.printStackTrace();}return true;}// 销毁连接池public synchronized void destroy() {for (Connection conn : freeConnection) {try {if (isValid(conn)) {conn.close();}} catch (SQLException e) {e.printStackTrace();}}for (Connection conn : activeConnection) {try {if (isValid(conn)) {conn.close();}} catch (SQLException e) {e.printStackTrace();}}isActive = false;contActive = 0;}// 连接池状态public boolean isActive() {return isActive;}// 定时检查连接池情况public void cheackPool() {if (dbBean.isCheakPool()) {new Timer().schedule(new TimerTask() {@Overridepublic void run() {// 1.对线程里面的连接状态// 2.连接池最小 最大连接数// 3.其他状态进行检查,因为这里还需要写几个线程管理的类,暂时就不添加了System.out.println("空线池连接数:" + freeConnection.size());System.out.println("活动连接数::" + activeConnection.size());System.out.println("总的连接数:" + contActive);}}, dbBean.getLazyCheck(), dbBean.getPeriodCheck());}}
}- 创建com.qrsoft.etl.common.db.ConnectionPoolManager类,该类为数据库的连接管理类,是一个通用的固定写法,通过连接池管理数据库连接,提供了获取单例模式连接的实现,还提供了根据连接池名字获得连接的方法,以及关闭连接、清空连接池等方法。
package com.qrsoft.etl.common.db;import java.sql.Connection;
import java.sql.SQLException;
import java.util.Hashtable;
/*** 连接管理类*/
public class ConnectionPoolManager {// 连接池存放public Hashtable<String, IConnectionPool> pools = new Hashtable<String, IConnectionPool>();// 初始化private ConnectionPoolManager() {init();}// 单例实现public static ConnectionPoolManager getInstance() {return Singtonle.instance;}private static class Singtonle {private static ConnectionPoolManager instance = new ConnectionPoolManager();}// 初始化所有的连接池public void init() {for (int i = 0; i < DBInitInfo.beans.size(); i++) {DBbean bean = DBInitInfo.beans.get(i);ConnectionPool pool = new ConnectionPool(bean);if (pool != null) {pools.put(bean.getPoolName(), pool);System.out.println("Info:Init connection successed ->"+ bean.getPoolName());}}}// 获得连接,根据连接池名字 获得连接public Connection getConnection(String poolName) {Connection conn = null;if (pools.size() > 0 && pools.containsKey(poolName)) {conn = getPool(poolName).getConnection();try {conn.setAutoCommit(false);} catch (SQLException e) {e.printStackTrace();}} else {System.out.println("Error:Can't find this connecion pool ->" + poolName);}return conn;}// 关闭,回收连接public void close(String poolName, Connection conn) {IConnectionPool pool = getPool(poolName);try {if (pool != null) {pool.releaseConn(conn);}} catch (SQLException e) {System.out.println("连接池已经销毁");e.printStackTrace();}}// 清空连接池public void destroy(String poolName) {IConnectionPool pool = getPool(poolName);if (pool != null) {pool.destroy();}}// 获得连接池public IConnectionPool getPool(String poolName) {IConnectionPool pool = null;if (pools.size() > 0) {pool = pools.get(poolName);}return pool;}
}- 创建com.qrsoft.etl.dao.IBaseDao类,该类主要用于数据库的通用操作,如创建连接、执行更新等操作。
package com.qrsoft.etl.dao;import com.qrsoft.etl.common.db.ConnectionPoolManager;
import com.qrsoft.etl.common.db.IConnectionPool;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;import java.sql.*;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;public class IBaseDao {private final static Logger logger = LoggerFactory.getLogger(IBaseDao.class);public ResultSet rs = null;private IConnectionPool pool= ConnectionPoolManager.getInstance().getPool("pool");private Connection conn = getConnection();// 定义sql语句的执行对象private PreparedStatement pstmt;public Connection getConnection(){Connection conn = null;if(pool != null && pool.isActive()){conn = pool.getConnection();}return conn;}public Connection getCurrentConnection(){Connection conn = null;if(pool != null && pool.isActive()){conn = pool.getCurrentConnecton();}return conn;}/*** 查询*/public ResultSet execute(String sql, Object params[]) {try {conn.setAutoCommit(false);pstmt = conn.prepareStatement(sql);for (int i = 0; i < params.length; i++) {pstmt.setObject(i + 1, params[i]);}rs = pstmt.executeQuery();pool.releaseConn(conn);} catch (SQLException e) {e.printStackTrace();logger.info("查询失败!", e.getMessage());}return rs;}/*** 更新*/public boolean update(String sql, Object params[]) throws SQLException {boolean flag = false;try {conn.setAutoCommit(false);pstmt = conn.prepareStatement(sql);for (int i = 0; i < params.length; i++) {pstmt.setObject(i + 1, params[i]);}int i = pstmt.executeUpdate();if (i > 0){flag = true;}else{flag = false;}pool.releaseConn(conn);conn.commit();} catch (SQLException e) {conn.rollback();e.printStackTrace();logger.info("更新失败!", e.getMessage());}return flag;}/*** 更新一个*/public boolean updateOne(String sql) throws SQLException {boolean flag = false;try {pstmt = conn.prepareStatement(sql);int i = pstmt.executeUpdate();if (i > 0){flag = true;} else{flag = false;}pool.releaseConn(conn);conn.commit();} catch (SQLException e) {conn.rollback();e.printStackTrace();logger.info("更新失败!", e.getMessage());}return flag;}/*** 执行查询操作*/public List<Map<String, Object>> findResult(String sql, List<?> params) throws SQLException {List<Map<String, Object>> list = new ArrayList<Map<String, Object>>();int index = 1;pstmt = conn.prepareStatement(sql);if (params != null && !params.isEmpty()) {for (int i = 0; i < params.size(); i++) {pstmt.setObject(index++, params.get(i));}}rs = pstmt.executeQuery();ResultSetMetaData metaData = rs.getMetaData();int cols_len = metaData.getColumnCount();while (rs.next()) {Map<String, Object> map = new HashMap<String, Object>();for (int i = 0; i < cols_len; i++) {String cols_name = metaData.getColumnName(i + 1);Object cols_value = rs.getObject(cols_name);if (cols_value == null) {cols_value = "";}map.put(cols_name, cols_value);}list.add(map);}return list;}public Boolean getBool(ResultSet airRs){boolean bool = false;Integer no = 0;try {while (airRs.next()) {no = airRs.getInt(1);if (no>0) {bool = true;}}} catch (SQLException e) {bool = false;e.printStackTrace();}return bool;}
}- 创建com.qrsoft.etl.common.Constants类,该类为全局常量类,定义了相关的常量,使用的时候直接通过Constants类调用,即方便修改,又可以避免手写时写错。
package com.qrsoft.etl.common;public class Constants {//间隔时间(10分钟)public final static int INTERVAL_TIME_10MIN = 10*60*1000;//间隔时间(5分钟)public final static int INTERVAL_TIME_5MIN = 5*60*1000;//间隔时间(1分钟)public final static int INTERVAL_TIME_1MIN = 60*1000;//间隔时间(30秒)public final static int INTERVAL_TIME_30SEC = 30*1000;//间隔时间(10秒)public final static int INTERVAL_TIME_10SEC = 10*1000;//间隔时间(10秒)public final static int INTERVAL_TIME_5SEC = 5*1000;//每分钟读取条数public final static int READ_COUNT = 10;//kg_airportpublic final static String TABLE_AIRPORT = "kg_airport";//kg_airlinecompanypublic final static String TABLE_AIRLINECOMPANY = "kg_airlinecompany";//kg_PlanData计划数据public final static String TASK_PlANDATA = "task_PlanData";public final static String TABLE_PlANDATA = "Kg_PlanData";public final static String FAMILY_PlANDATA = "ReportHome";public final static String COLUMN_PlANDATA = "EXECUTE_DATE";//kg_MultiRadarData综合航迹数据public final static String TASK_RADAR = "task_Radar";public final static String TABLE_RADAR = "Kg_MultiRadarData";public final static String FAMILY_RADAR = "RadarHome";public final static String COLUMN_RADAR = "SEND_RADAR_TIME";//kg_AFTN报文数据public final static String TASK_AFTN = "task_Aftn";public final static String TABLE_AFTN = "Kg_AFTN";public final static String FAMILY_AFTN = "AFTNHome";public final static String COLUMN_AFTN = "EXECUTE_DATE";//Kg_ATCDutyInfo管制值班人员数据public final static String TASK_ATCDUTY = "task_ATCDuty";public final static String TABLE_ATCDUTY = "Kg_ATCDutyInfo";public final static String FAMILY_ATCDUTY = "ATCDutyHome";public final static String COLUMN_ATCDUTY = "SEND_TIME";//Kg_WarnFlightHistory航班指令告警数据public final static String TASK_WARNFLIGHT = "task_WarnFlight";public final static String TABLE_WARNFLIGHT = "Kg_WarnFlightHistory";public final static String FAMILY_WARNFLIGHT = "WarnFlightHome";public final static String COLUMN_WARNFLIGHT = "GJ_DATE";//Kg_WarnSimilarHistory相似航班号告警数据public final static String TASK_WARNSIMILAR = "task_WarnSimilar";public final static String TABLE_WARNSIMILAR = "Kg_WarnSimilarHistory";public final static String FAMILY_WARNSIMILAR = "WarnSimilarHome";public final static String COLUMN_WARNSIMILAR = "GJ_DATE";//Kg_ATC扇区信息public final static String TASK_ATC = "task_ATC";public final static String TABLE_ATC = "Kg_ATC";public final static String FAMILY_ATC = "ATCHome";public final static String COLUMN_ATC = "EXECUTE_DATE";//Kg_CallSaturation 扇区通话饱和度信息public final static String TASK_CALLSATURATION = "task_CallSaturation";public final static String TABLE_CALLSATURATION = "Kg_CallSaturation";public final static String FAMILY_CALLSATURATION = "SaturationHome";public final static String COLUMN_CALLSATURATION = "SEND_TIME";
}2、创建com/qrsoft/etl/spark/SparkStreamingApplication.java类,在该类中配置Kafka和Spark的执行参数,然后使用Spark进行业务数据处理,在代码中会根据不同的Topic进入不同的分支,进行数据的处理。
- 创建SparkStreamingApplication.java类,设置Zookeeper的brokers和zkServers,设置需要监听的Topic List
package com.qrsoft.etl.spark;import com.qrsoft.etl.common.Constants;
import com.qrsoft.etl.util.ConfigUtil;
import net.sf.json.JSONObject;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import org.apache.spark.streaming.kafka010.ConsumerStrategies;
import org.apache.spark.streaming.kafka010.KafkaUtils;
import org.apache.spark.streaming.kafka010.LocationStrategies;
import org.springframework.stereotype.Component;import java.io.Serializable;
import java.util.Arrays;
import java.util.Collection;
import java.util.HashMap;
import java.util.Map;
import java.util.regex.Pattern;@Component
public class SparkStreamingApplication implements Serializable {static final Pattern SPACE = Pattern.compile(" ");// 多个以逗号隔开static String brokers = ConfigUtil.readProperty("brokers");static String zkserver = ConfigUtil.readProperty("zkserver");// 消费者组名称static String groupId = "spark_etl";// topic列表static String topicsStr = Constants.TASK_RADAR;static String[] topicsStrs = {Constants.TASK_PlANDATA,Constants.TASK_WARNFLIGHT,Constants.TASK_ATCDUTY,Constants.TASK_WARNSIMILAR,Constants.TASK_AFTN,Constants.TASK_ATC,Constants.TASK_CALLSATURATION,Constants.TASK_RADAR};/*** 启动Spark读取、清洗数据*/public void SparkEtlStart() {// ... 在此处添加代码 ...}
}- 在SparkEtlStart()方法内添加代码,配置Spark和Kafka参数,创建StreamingContext
创建StreamingContext,设置拉取流的时间,准备读取Kafka数据。本地开发时Spark配置使用local[*]方式,设置成本地运行模式,放到集群中运行时需要修改为Yarn模式。
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("qst-etl");
//反压机制
conf.set("spark.streaming.backpressure.enabled", "true");
conf.set("allowMultipleContexts", "true");
JavaSparkContext sc = new JavaSparkContext(conf);
// 获取jssc 以及设置获取流的时间
JavaStreamingContext jssc = new JavaStreamingContext(sc, Durations.seconds(10));
jssc.sparkContext().setLogLevel("WARN");
// Kafka 参数配置
Map<String, Object> kafkaParams = new HashMap<>();
kafkaParams.put("zookeeper.connect", zkserver);
kafkaParams.put("bootstrap.servers", brokers);
kafkaParams.put(ConsumerConfig.GROUP_ID_CONFIG, groupId); //指定了KafkaConsumershuyu 哪一个消费者群组
kafkaParams.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true);
kafkaParams.put("key.deserializer", StringDeserializer.class);
kafkaParams.put("value.deserializer", StringDeserializer.class);kafkaParams.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, 1000);kafkaParams.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest"); //读取Kafka最新的一条kafkaParams.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, 30000);Collection<String> topics = Arrays.asList(topicsStrs);- 拉取Kafka数据流
// 获取流
JavaInputDStream<ConsumerRecord<String, String>> stream = KafkaUtils.createDirectStream(jssc,LocationStrategies.PreferConsistent(),ConsumerStrategies.Subscribe(topics, kafkaParams));- 解析Kafka数据流:解析流,对流进行循环处理,首先把流区分Topic,解析流中的value,其次根据不同Topic进入不同的分支,进行处理
stream.foreachRDD(rdd -> {rdd.foreach(t -> {String topName = t.topic();JSONObject jsonObject = new JSONObject();String taskRadar = "";if(topName.equals(Constants.TASK_RADAR)){taskRadar = t.value();}else{jsonObject = JSONObject.parseObject(t.value());}SparkUtil sparkUtil = new SparkUtil();try {switch (topName) {case Constants.TASK_RADAR:
// sparkUtil.TaskRadar(taskRadar);sparkUtil.TaskRadarStr(taskRadar);break;case Constants.TASK_PlANDATA:sparkUtil.TaskPlanData(jsonObject);break;case Constants.TASK_WARNFLIGHT:sparkUtil.TaskWarnfLight(jsonObject);break;case Constants.TASK_ATCDUTY:sparkUtil.TaskAtcduty(jsonObject);break;case Constants.TASK_WARNSIMILAR:sparkUtil.TaskWarnsimilar(jsonObject);break;case Constants.TASK_AFTN:sparkUtil.TaskAftn(jsonObject);break;case Constants.TASK_ATC:sparkUtil.TaskAtc(jsonObject);break;case Constants.TASK_CALLSATURATION:sparkUtil.TaskCallsaturation(jsonObject);break;}} catch (Exception e) {System.out.println(e);}//return Arrays.asList(SPACE.split(t.value())).iterator();});});- 启动Spark,进行业务处理
// 打印结果
//warns.print();
try {// 启动jssc.start();jssc.awaitTermination();
} catch (InterruptedException e) {e.printStackTrace();
}3、将清洗后的数据保存到数据库中
- 在上一步的代码中,解析Kafka数据流时,首先把流区分Topic,解析流中的value,其次根据不同Topic进入不同的分支,进行处理。例如:
case Constants.TASK_PlANDATA:sparkUtil.TaskPlanData(jsonObject);break;该分支是处理机场起降数据,这里会用到一个类SparkUtil.java,该类中定义了处理不同Topic数据的方法,其中sparkUtil.TaskPlanData(jsonObject)就是处理机场起降数据对应的方法。
主要任务是:对起降信息进行统计和更新、对航线信息进行统计和更新:
1)首先判断是否有该机场航班起降的统计信息,如果数据库中没有该机场数据,则在数据库中插入;如果有则根据条件进行更新数据;
2)对于航线信息也是如此,如果数据库中没有相应的航线数据,则在数据库中插入;否则根据条件进行更新。
- 编写com.qrsoft.etl.spark.SparkUtil类,代码位置src/main/java/com/qrsoft/etl/spark/SparkUtil.java,在该类中添加一个方法TaskPlanData(jsonObject),用于处理“机场起降数据”对应的Topic中的数据。
package com.qrsoft.etl.spark;import com.alibaba.fastjson.JSONObject;
import com.qrsoft.etl.dao.PlanDataDao;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Component;import java.text.SimpleDateFormat;
import java.util.Date;@Component
public class SparkUtil {private final static Logger logger = LoggerFactory.getLogger(SparkUtil.class);// 初始化扇区private static Double[] sectionG = {38.716066,42.297914,114.648477,128.759203};private static Double[] sectionK = {35.519796,38.716066,114.648477,128.759203};private static Double[] sectionE = {32.519796,35.519796,114.648477,128.759203};/*** 业务处理* @param jsonObject 机场起降数据* @throws Exception*/public void TaskPlanData(JSONObject jsonObject) throws Exception {//起飞机场String adep = jsonObject.getString("ADEP");//降落机场String ades = jsonObject.getString("ADES");//操作数据库,统计和更新机场航班数operationDB(adep);operationDB(ades);//航班号String acid = jsonObject.getString("ACID");//操作数据库,统计和更新航线信息operationDBBOLT(adep, ades, acid);}/*** 操作数据库(对航班起降数进行统计或更新)* @param code “起飞机场”或“降落机场”*/public void operationDB(String code) {//根据机场代码获取目前数据库中已存在的航班数PlanDataDao pDao = new PlanDataDao();boolean bool;try {bool = pDao.isExistThisAir(code);if (bool) {//存在,在原来基础上+1,修改数据库中该机场的航班数pDao.updateAnAirMsg(code);} else {//不存在,在统计表中创建该机场的航班数(默认为1)pDao.createAnAirMsg(code);}} catch (Exception e) {e.printStackTrace();}}/*** 操作数据库(对航线进行统计或更新)* @param adep 起飞机场* @param ades 降落机场* @param acid 航班号*/public void operationDBBOLT(String adep, String ades, String acid) {boolean bool;PlanDataDao pDao = new PlanDataDao();if (pDao.isDomesticThisLine(adep) && pDao.isDomesticThisLine(ades)) {bool = pDao.isExistThisLine(acid);if (bool) {pDao.updateAnLineMsg(acid);} else {pDao.createAnLineMsg(acid, adep, ades);}}}// ... ...// ... 其他方法。因为当前要实现的是“机场起降数据”,所以其他可以只有方法体,没有方法实现及返回值。 ...// ... ...public void TaskRadarStr(String taskRadar) { }public void TaskWarnfLight(JSONObject jsonObject) { }public void TaskAtcduty(JSONObject jsonObject) { }public void TaskWarnsimilar(JSONObject jsonObject) { }public void TaskAftn(JSONObject jsonObject) { }public void TaskAtc(JSONObject jsonObject) { }public void TaskCallsaturation(JSONObject jsonObject) { }// ... ...
}- 在上面的代码中会用到一个com.qrsoft.etl.dao.PlanDataDao类,代码位置src/main/java/com/qrsoft/etl/dao/PlanDataDao.java。该类是一个数据库操作类,会根据业务逻辑进行实际的数据库的操作,如增、删、改、查等。
package com.qrsoft.etl.dao;import org.slf4j.Logger;
import org.slf4j.LoggerFactory;import java.sql.ResultSet;
import java.sql.SQLException;public class PlanDataDao extends IBaseDao {private final static Logger logger = LoggerFactory.getLogger(PlanDataDao.class);// ... ...// ... 添加方法实现 ... // ... ...
}- 对于“处理机场起降数据”会涉及到以下的方法:
查询该机场是否在国内:
public boolean isDomesticThisLine(String code4){String sql = " SELECT COUNT(*) from airport_longlat where code4 ='"+code4+"';";Object[] params = {};ResultSet comRs = this.execute(sql, params);return getBool(comRs);
}根据机场代码查询是否有该机场的统计信息:
public boolean isExistThisAir(String code) {String sql = " SELECT COUNT(*) from airport_number where flightcode='"+code+"';";Object[] params = {};ResultSet airRs = this.execute(sql, params);return getBool(airRs);
}如果根据机场代码查询,有该机场的统计信息,则在数据库中更新机场的起降航班数:
public void updateAnAirMsg(String code) {String sql = "update airport_number set count=count+'1' where flightcode='"+code+"'; ";Object[] params = {};try {this.update(sql, params);} catch (SQLException e) {logger.info("修改指定机场的统计信息(统计数在原来基础上+1)失败! " + code);e.printStackTrace();}
}如果根据机场代码查询,有该机场的统计信息,则在统计表中创建该机场的航班数(默认为1):
public void createAnAirMsg(String code) {String sql = "insert into airport_number (flightcode,cname,count) values ('"+code+"',(select airport_cname from kg_airport where AIRPORT_CODE4 = '"+code+"'),'1');";Object[] params = {};try {this.update(sql, params);} catch (SQLException e) {logger.info("创建新机场的统计信息失败! " + code);e.printStackTrace();}
}根据航班号查询是否有该航线存在:
public boolean isExistThisLine(String acid){String sql = " SELECT COUNT(*) from airline_number where acid ='"+acid+"';";Object[] params = {};ResultSet comRs = this.execute(sql, params);return getBool(comRs);
}根据航班号查询,有该航线统计信息,则在统计表中修改指定航线的统计信息(统计数在原来的基础上+1):
public void updateAnLineMsg(String acid) {String sql = "update airline_number set count=count+1 where acid='"+acid+"';";Object[] params = {};try {this.update(sql, params);} catch (SQLException e) {logger.info("修改指定航线统计信息(统计数在原来基础上+1)失败! 航班号:" + acid);e.printStackTrace();}
}根据航班号查询,没该航线统计信息,则创建新航线的统计信息:
public void createAnLineMsg(String acid,String aDEP,String aDES) {String sql = "insert into airline_number (acid,adepcode,adescode,adepname,adesname,adeplong,adeplat,adeslong,adeslat,count) values ('"+acid+"','"+aDEP+"','"+aDES+"',(select airport_cname from kg_airport where airport_code4 = '"+aDEP+"'),(select airport_cname from kg_airport where airport_code4 = '"+aDES+"'),(select longitude from airport_longlat where code4 = '"+aDEP+"'),(select latitude from airport_longlat where code4 = '"+aDEP+"'),(select longitude from airport_longlat where code4 = '"+aDES+"'),(select latitude from airport_longlat where code4 = '"+aDES+"'),'1') ;";Object[] params = {};try {this.update(sql, params);} catch (SQLException e) {logger.info("创建新航线的统计信息失败! 航班号:" + acid);e.printStackTrace();}
}该PlanDataDao.java类是一个普通的数据库操作类,非常简单,主要是根据我们的业务需求对数据进行相应的操作。这里会涉及到前面我们创建的一些数据库访问的工具类和辅助类:
| com.qrsoft.etl.dao.IBaseDao | 数据库访问的通用类,包括创建连接、执行更新等通用操作 |
| com.qrsoft.etl.common.db.ConnectionPoolManager | 连接管理类 |
| com.qrsoft.etl.common.db.IConnectionPool | 连接池管理类接口 |
| com.qrsoft.etl.common.db.ConnectionPool | 连接池管理类接口实现类 |
| com.qrsoft.etl.common.db.DBbean | 这是外部可以配置的连接池属性 可以允许外部配置,拥有默认值 |
| com.qrsoft.etl.common.db.DBInitInfo | 初始化,模拟加载所有的配置文件 |
| com.qrsoft.etl.common.Constants | 全局常量类 |
| com.qrsoft.etl.util.ConfigUtil | 加载配置文件的工具类 |
| com.qrsoft.etl.util.ConfigManager | 配置文件管理的工具类 |
| com.qrsoft.etl.util.MapManager | 地图管理的工具类,例如:是否在矩形区域内 |
- 添加或修改如下配置文件:
1)application.yml,服务器相关配置
server:port: 8849spring:datasource:driver-class-name: com.mysql.jdbc.Driverusername: rootpassword: 123456url: jdbc:mysql://node3:3306/kongguan?serverTimezone=UTCredis:host: node3port: 6379database: 15mybatis-plus:configuration:log-impl: org.apache.ibatis.logging.stdout.StdOutImplmapper-locations: classpath:/mapper/*.xml2)config.properties,MySQL数据库相关配置
jdbc.driver=com.mysql.jdbc.Driver
jdbc.url=jdbc:mysql://node3:3306/kongguan?useSSL=false&characterEncoding=utf8&serverTimezone=Asia/Shanghai
jdbc.username=root
jdbc.password=123456
jdbc.min=20
jdbc.max=5003)log4j.properties,日志文件相关配置
#定义LOG输出级别
#log4j.rootLogger=INFO,Console,File,stdout
log4j.rootLogger=Console
log4j.rootCategory = ERROR,Console
#定义日志输出目的地为控制台
log4j.appender.Console=org.apache.log4j.ConsoleAppender
log4j.appender.Console.Target=System.out
#可以灵活地指定日志输出格式,下面一行是指定具体的格式
log4j.appender.Console.layout = org.apache.log4j.PatternLayout
log4j.appender.Console.layout.ConversionPattern=[%c] - %m%n#文件大小到达指定尺寸的时候产生一个新的文件
# log4j.appender.File = org.apache.log4j.RollingFileAppender
log4j.appender.File.Append=true
log4j.appender.File = org.apache.log4j.DailyRollingFileAppender
#指定输出目录
log4j.appender.File.File = /home/tmp/hbase
log4j.appender.File.DatePattern = '_'yyyy-MM-dd'.log'
#定义文件最大大小
log4j.appender.File.MaxFileSize = 10MB
# 输出所以日志,如果换成DEBUG表示输出DEBUG以上级别日志
log4j.appender.File.Threshold = ERROR
log4j.appender.File.layout = org.apache.log4j.PatternLayout
log4j.appender.File.layout.ConversionPattern =[%p] [%d{yyyy-MM-dd HH\:mm\:ss}][%c]%m%n# mybatis日志输出
log4j.logger.com.sarnath.ind.dao.IRoleDao.addPermission=TRACE
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%5p [%t] - %m%n4)myconfig.properties,Zookeeper和Kafka相关配置
brokers: node1:9092,node2:9092,node3:9092
zkserver: node1:2181,node2:2181,node3:2181注意,在上面的步骤中只处理了一个Topic分支的数据,其余Topic分支,参考TASK_PlANDATA方式处理,自行实现其他XXX统计(请参考源代码)。
4、修改项目启动文件BigDataEtlKongGuanApplication.java,内容如下:
package com.qrsoft;import com.qrsoft.etl.spark.SparkStreamingApplication;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.ConfigurableApplicationContext;
import org.springframework.scheduling.annotation.EnableScheduling;@SpringBootApplication
@EnableScheduling
public class BigDataEtlKongGuanApplication {public static void main(String[] args) {ConfigurableApplicationContext run = SpringApplication.run(BigDataEtlKongGuanApplication.class, args);SparkStreamingApplication bean = run.getBean(SparkStreamingApplication.class);bean.SparkEtlStart();}
}5、测试
- 确保Hadoop、Spark、Kafka、MySQL等环境均已经启动,如果没有启动,可参考前面的安装部署任务,自行启动。
- 启动BigData-KongGuan项目(如果没有启动)
- 启动BigData-Etl-KongGuan项目
- 在node3节点,进入MySQL数据库,查询 airline*相关的表是否有数据
[root@node3 ~]# mysql -uroot -p123456mysql> show databases;mysql> use kongguan;mysql> select * from airline_number limit 20;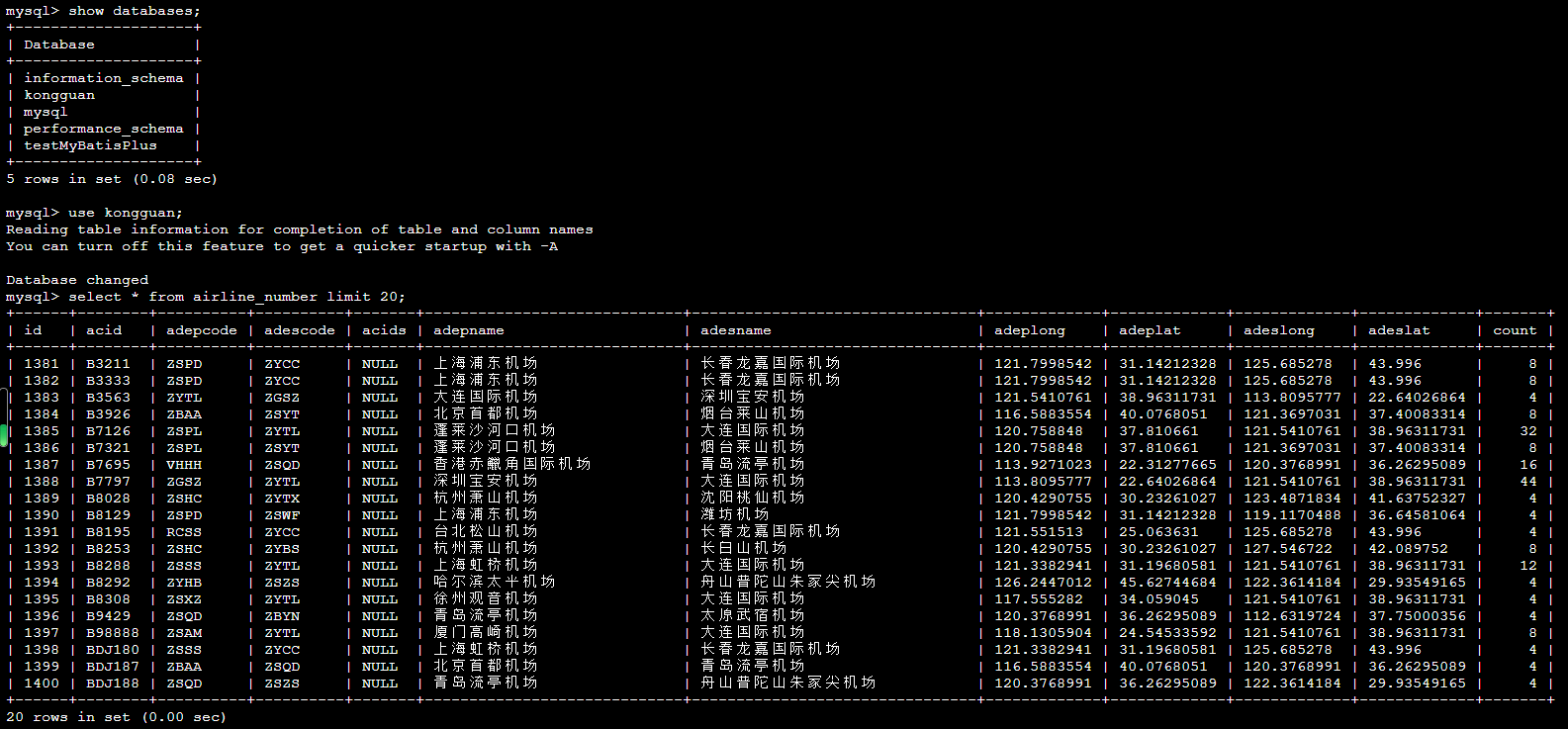
例如:统计airline_number表,记录数是递增的。
mysql> select count(*) from airline_number;